

Unsupervised Keyphrase Extraction by Jointly Modeling Local and Global Context 阅读笔记
论文简单介绍
- 题目
Unsupervised Keyphrase Extraction by Jointly Modeling Local and Global Context - 作者
Xinnian Liang , Shuangzhi Wu , Mu Li and Zhoujun Li - 单位
北航 - 时间
2021 - 会议
EMNLP21
动机
- 以前的方法,例如
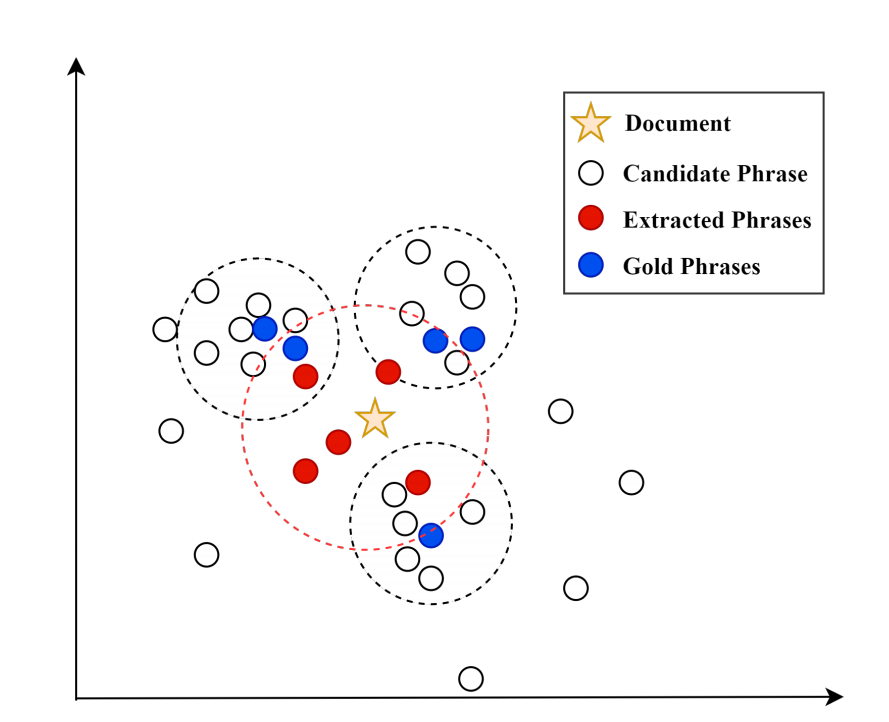
SIFRank和EmbedRank等只考虑了候选关键词与全文之间的向量相似度,这个不能捕获不同的上下文信息。 - 作者用下图展示了上下文嵌入的直观重要性
- 节点是候选术语的嵌入
- 星号是文档的嵌入
- 每个黑色圆圈代表一个本地上下文。也就是说在同一个黑色圈圈里面的候选词通常都是同一个主题相关的
- 红圈中的节点表示这些候选短语与文档语义相似 从这里可以看出来如果仅通过计算候选短语与文档之间的相似度来对全局上下文进行建模,该模型将倾向于选择红色节点,这将忽略三个集群中的局部显着信息。 因此作者提出了全局相似度(红色圆圈)和局部相似度(黑色圆圈)相结合的方法来抽取关键词

; 模型
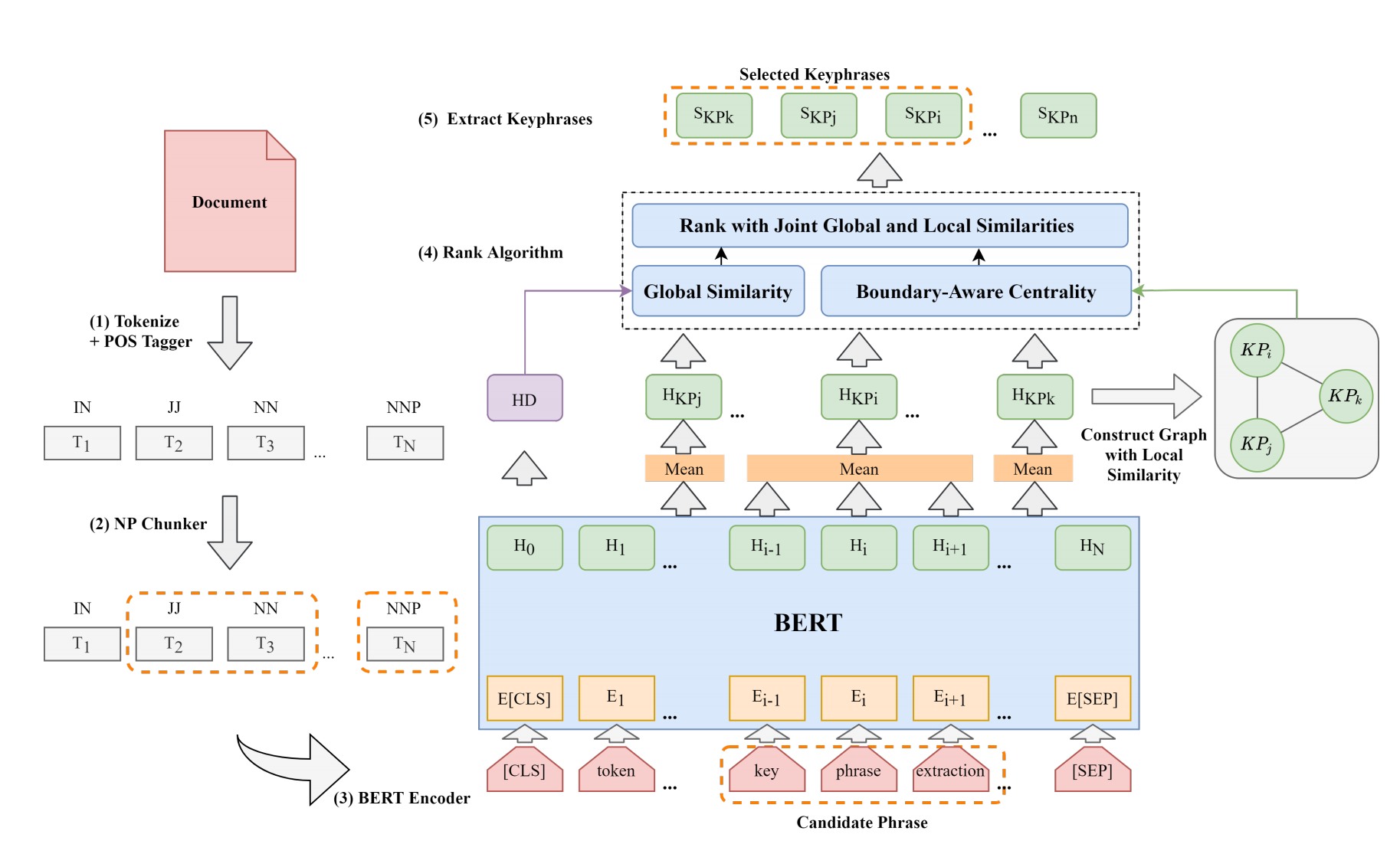
首先对文本进行预处理,包括分词,标注词性,然后将token送进bert进行嵌入,得到每一个token的向量嵌入(pooler_output)和文档的向量嵌入(cls),然后分别计算全局相似度和局部相似度,最后考虑了位置得分,这样综合计算后得到每一个候选术语的得分,再选取topK个即完成了关键词的抽取
- bert嵌入
- 在这里作者先将tokens标注词性之后送进去bert里面进行嵌入。对于每一个token,采用
pooler_output做为其向量表达。在最开始插入了一个CLS标记符,用其代表整个文档的嵌入 - 候选关键词生成
- 采用的是主流的词性抽取规则
(ADJECTIVE)*(NOUN)+。之前得到的都是一个个token的词向量,在这里,作者采取最大池化操作得到候选术语的词向量 - 全局相似度计算
- 采用曼哈顿距离计算每个候选术语与文档之间的相似度做为全局相似度
- 局部相似度计算


- 此外作者再一次显性考虑了一个位置信息,只选取每个词出现的第一个位置的倒数做为其位置得分,为了防止悬殊过大,又经过一个softmax函数
- 最终局部相似度和全局相似度得分如下
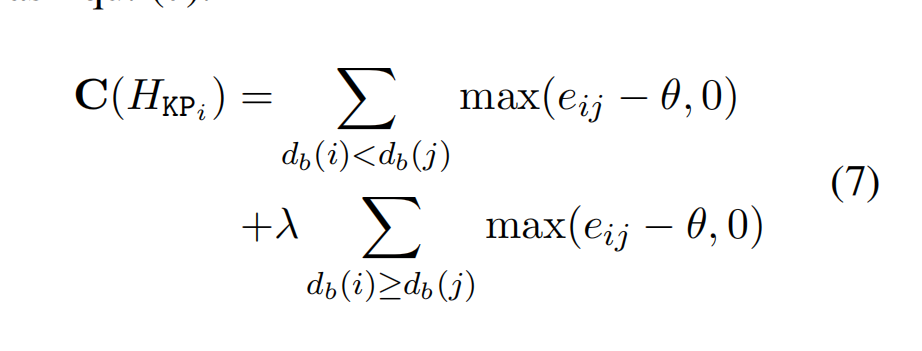


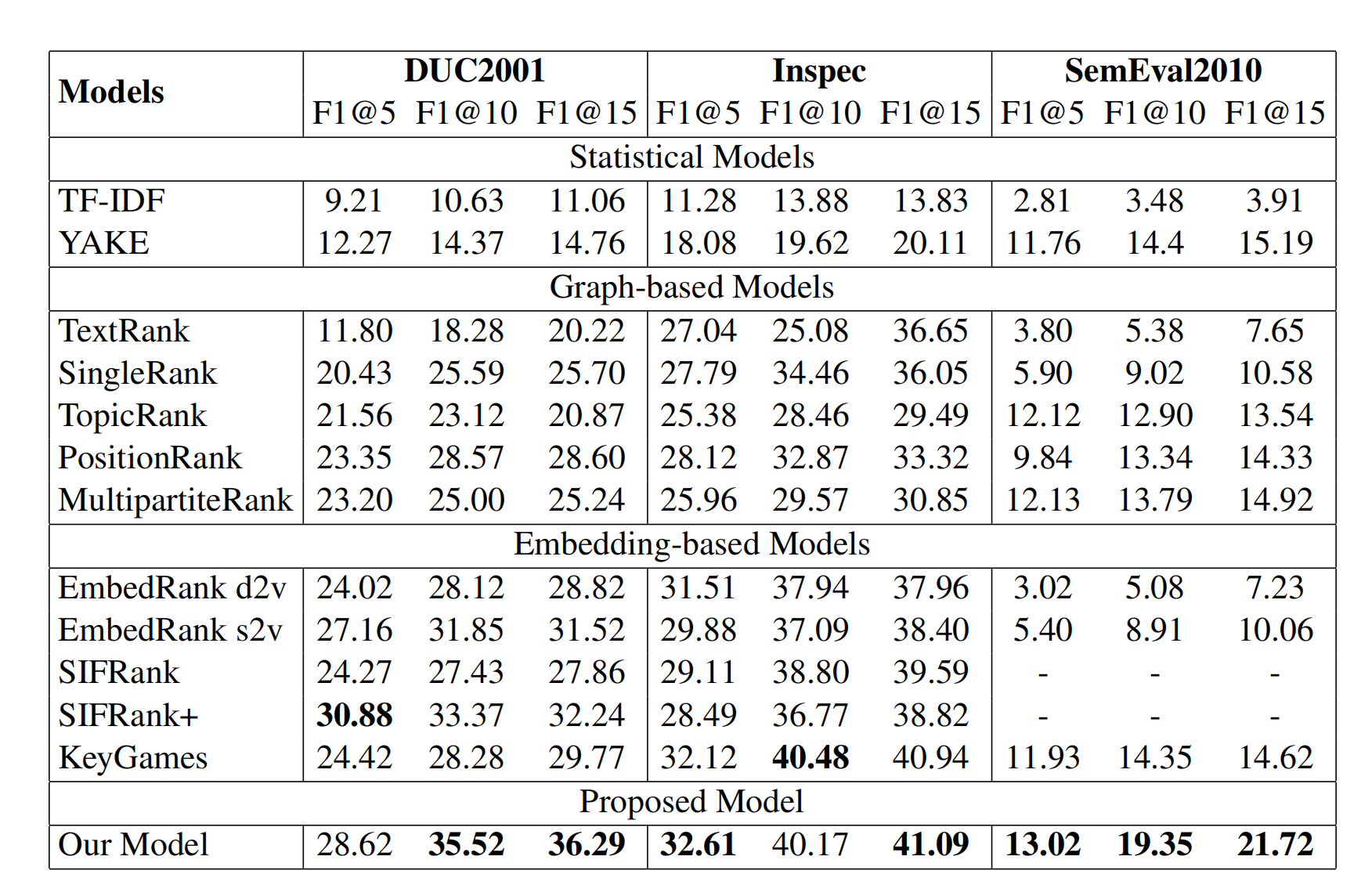
实验

; 我的思考
- 在候选术语生成时采用最大池化操作会导致整个术语由最核心的关键词主宰,这样会导致整个术语在计算局部相似度时分数很高,但是另一方面也就是会带来语义多样性问题。即大多数时候核心关键词和其组成的术语并存
- Bert最大编码是512个
token,通常有些单词很可能会分词成两个token。所以通常只能编码420个左右的单词,这在短文本数据集Inspec和DUC2001上面还行,但是在论文数据集SemEval2010上面显然是远远不够的,他只能编码到标题和摘要部分,显然没有包含充分的语义信息 - 分词最主要的就是最大长度匹配,这样会导致好多候选关键词得不到,也就是缺少了更多的可能性。作者使用的是
nltk自带的500多一点停用词表。其实解决分词问题的一个trick就是针对性添加停用词,但是这显然是作弊。 - 最重要的一点,作者的局部相似度思路和论文
Discourse-aware unsupervised summarization of long scientific documents.基本一样,感觉算是 抄袭
Original: https://blog.csdn.net/Fitz1318/article/details/124033575
Author: Fitz1318
Title: Unsupervised Keyphrase Extraction by Jointly Modeling Local and Global Context 阅读笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531051/
转载文章受原作者版权保护。转载请注明原作者出处!