

ACL2021论文收录列表:ACL-IJCNLP 2021
中文文本纠错paper&code列表:CTCResources/README_ZH.md (github.com)
中文处理文章集合:Special Interest Group on Chinese Language Processing (SIGHAN) – ACL Anthology
论文一:ACL2021
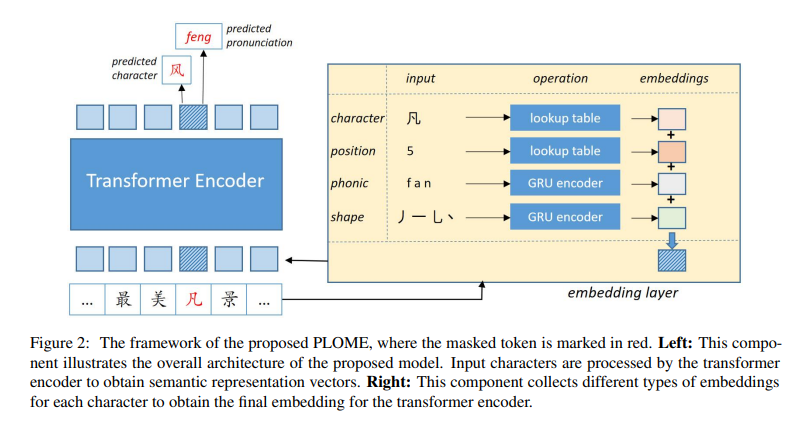
PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction
论文地址:https://aclanthology.org/2021.acl-long.233.pdf
仓库地址:https://github.com/liushulinle/PLOME
- 预训练过程中使用 混淆集(近音、近形)中相似单词MASK选择的单词
- 通过使用拼音、笔画作为输入来预测单词
- 使用GRU网络根据字符的语音和笔画知识进行建模
中文错误(近音字、近形字)
词嵌入模块中,使用字符嵌入(character embedding)、位置嵌入(position embedding)、语音嵌入(phonic embedding)、字形嵌入(shape embedding)。
字符嵌入与位置嵌入与BERT的输入一致
使用语音嵌入以及字形嵌入预训练模型,并且应用于下游任务中
语音嵌入(Unihan数据库):Unihan Database Lookup
字形嵌入(Chaizi数据库):https://en.wikipedia.org/wiki/Stroke_order
预训练与微调过程中:使用的损失函数是 语音嵌入损失 与 字形嵌入损失的 联合预测
数据集:
预训练数据集:wiki2019zh数据集(100w中文wiki语料)和300w篇新闻文章
fine-tuning数据集:2013、2014、2015年的SIGHAN数据集构成
中文混淆集(近音字、近形字)
在预训练过程中,使用困惑集中的单词来对mask的单词进行替换
Chinese Spelling Check Evaluation at SIGHAN Bake-off 2013
论文地址:https://aclanthology.org/W13-4406.pdf

对比方法:
Spelling Error Correction with Soft-Masked BERT
https://aclanthology.org/2020.acl-main.82.pdf
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
https://aclanthology.org/2020.acl-main.81.pdf
- 使用混淆集来进行模型的预训练
实验部分:
- 模型参数初始化策略有效性
- 语音、字形特征可视化
- 不同模型训练速度、收敛速度
论文二:ACL2021
PHMOSpell: Phonological and Morphological Knowledge Guided Chinese Spelling Check
论文地址:https://aclanthology.org/2021.acl-long.464.pdf
- 从多模态信息中获取汉字的语音知识和形态知识
- 设计一个新奇的自适应通道机制, 有效的结合多模态信息于预训练模型中
先前工作的不足:
- 语音和字形知识作为额外的知识,没有应用于端到端的框架中
- SpellGCN进行了预训练模型的训练,但是应用混淆集使得替换的单词信息受限,不能扩展到所有单词
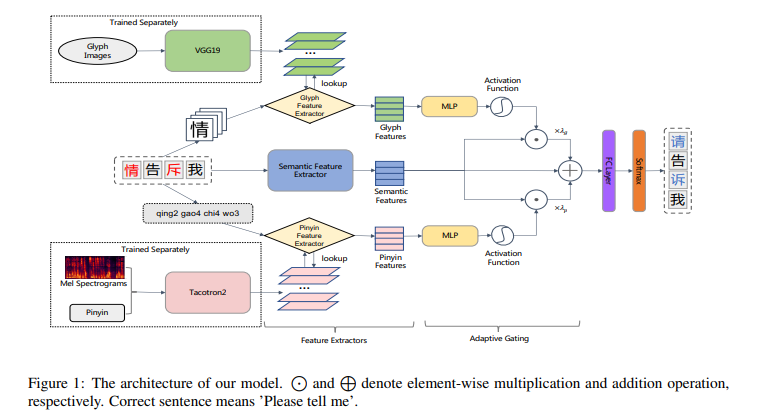
利用拼音特征、字形特征、语音特征做信息融合、预测最终错别字结果
拼音特征抽取器:
-
Natural tts synthesis by conditioning wavenet on mel spectrogram predictions.
- a recurrent sequenceto-sequence mel spectrograms prediction network, to help modeling the phonological representations since its location-sensitive attention can create effective time alignment between the character sequence and the acoustic sequence.
字形特征抽取器:
- VGG19:GitHub – pytorch/vision: Datasets, Transforms and Models specific to Computer Vision
- 参考论文:Glyce: Glyph-vectors for chinese character representations.
数据集:
训练数据集:2013、2014、2015年的SIGHAN数据集、271K训练样例自动生成使用(OCR、ASR)
自动生成训练数据集paper:
- A hybrid approach to automatic corpus generation for chinese spelling check.
测试数据集:2013、2014、2015年的SIGHAN数据集
中文繁体简体字转换工具:
OPENCC:GitHub – BYVoid/OpenCC: Conversion between Traditional and Simplified Chinese
对比方法:
Adaptable filtering using hierarchical embeddings for chinese spell check.
http://export.arxiv.org/pdf/2008.12281
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
https://aclanthology.org/2020.acl-main.81.pdf
- 使用混淆集来进行模型的预训练
实验部分:
- 验证超参数的有效性
- 特征可视化
- 错误样例分析
特征维度大小分析(论文解读):
On the Dimensionality of Word Embedding
https://arxiv.org/pdf/1812.04224.pdf
论文三:ACL2021(findings)
Correcting Chinese Spelling Errors with Phonetic Pre-training
论文四:ACL2021(findings)
Global Attention Decoder for Chinese Spelling Error Correction
论文五:ACL2021(findings)
Dynamic Connected Networks for Chinese Spelling Check
论文六:ACL2021(short)
Exploration and Exploitation: Two Ways to Improve Chinese Spelling Correction Models
论文七:ACL2021(short)
Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking
(一)文本纠错相关资料
中文文本纠错论文集
https://github.com/destwang/CTCResources
中文文本纠错论文整理
英文语法纠错
Grammatical Error Correction | NLP-progress
数据集
SIGHAN 13、14、15 训练测试集
最新文本纠错训练集benchmark (40k标注数据、2000k伪数据)CSCD-IME: 新一代中文拼写纠错benchmark! – 知乎
(二)文本纠错方法
预训练阶段:
语义、语音、字符多模态进行预训练
例如:PLOME
序列标注方式(文本编辑方式):
中文拼写纠错(Chinese Spelling Check, CSC)
中文拼写纠错任务对中文文本中的拼写纠错(别字、别词)进行检测和纠正。
语法纠错(Grammatical Error Correction, GEC)
语法纠错任务纠正文本中不同类型的错误, 包括拼写、标点、语法等类型错误。
例如:GECToR
纠错种类
CSC任务 – 替换
CGEC – 删除、添加
错误类型
同音字错误
形近字错误
字词序列颠倒
多字 – 冗余
少字 – 缺失
主流方法
- 从预训练阶段以及文本编辑角度两个方向进行训练
- 使用近音或者近形困惑集构建数据进行训练
- 使用多模态信息进行训练以纠正
(三)文本编辑中文拼写纠错基线模型
Lasertagger VS Gector (文本改写任务 vs 文本纠错任务 )
(一)代码整合
论文代码资源集合
https://github.com/destwang/CTCResources
中文Gector_chinese代码【基线模型】
https://github.com/taishan1994/Gector_chinese
中文REALISE模型仓库代码
https://github.com/DaDaMrX/ReaLiSe
中文法律文本纠错Gector基线模型
https://github.com/china-ai-law-challenge/CAIL2022/tree/main/wsjd/baseline
中文处理论文(极旧)
Special Interest Group on Chinese Language Processing (SIGHAN) – ACL Anthology
CSCD-IME: Correcting Spelling Errors Generated by Pinyin IME
String Editing Based Chinese Grammatical Error Diagnosis
MDCSpell: A Multi-task Detector-Corrector Framework for Chinese Spelling Correction
CRASpell: A Contextual Typo Robust Approach to Improve Chinese Spelling Correction
The Past Mistake is the Future Wisdom: Error-driven Contrastive Probability Optimization for Chinese Spell Checking
Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking
A Simple Recipe for Multilingual Grammatical Error Correction
PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction
PHMOSpell: Phonological and Morphological Knowledge Guided Chinese Spelling Check
case分析
- 短文本,无过多实际语义信息纠错易误召回。
- 短句进行纠错缺失上下文易出现误召回。
- 语序语义表达不明,无法根据上下文进行文本纠错。
- 重复问题严重影响纠错效果。
- 词组出现错误纠正较为困难
解决方法
- 去除重复现象和表达不明现象再进行错误纠正。
- 会议类场景相关数据进行训练。
- 使用滑动窗口的方式进行偏长文本错误纠正。
- 增加单字的情况较为容易解决。
- 词组错误问题纠正困难(考虑切词词组判断的方法)
一、原理
Attention cache
Transformer解码加速,可以利用两种cache进行解码加速
cross attention
对于encoder-decoder cross-attention而言, 对应的K,V来自encoder的outputs, 故将其使用cache保存即可,无需每步重新计算
self attention
对于self-attention而言,对于时刻t, 上一时刻的attention score为t-1维度的下三角矩阵, 此时的K, V为K, V的前t时刻信息, 而此刻的Q为第t时刻的信息,K \in R^{t, hidden_size}, V \in R^{t, hidden_size}, V \in R^{1, hidden_size}
faster-decoder之 decoder解码加速 | 小蛋子
EL-Attention
微软实现的text generation 加速的仓库:GitHub – microsoft/fastseq: An efficient implementation of the popular sequence models for text generation, summarization, and translation tasks. https://arxiv.org/pdf/2106.04718.pdf
论文:
无损实现解码加速:EL-Attention: Memory Efficient Lossless Attention for Generation
解码加速的库:FastSeq: Make Sequence Generation Faster
文本生成解码加速
三、问题
batch_size 16
EL-Attention 0.381GB, 12.68GB
EL-Attention (no del) 0.438GB, 12.74GB
batch_size 32
EL-Attention 0.438GB, 11.360GB
Tensor存储结构:tensor分为头信息区(Tensor)和存储区(Storage), 头信息区主要保存着tensor的形状(size), 步长(stride), 数据类型(type), 而真正的数据则保存成连续数组。【实际上很可能多个信息区对应于同一个存储区】(初始化或者普通索引会有该种情况) 高级检索出的结果坐标不方便这样修改,需要开辟新的内存进行存储
pytorch中, 少数几个操作不改变tensor的内容本身, 重新定义下标与元素的对应关系, 不会改变底层数组的存储(经过上述的操作后, 在语义上相邻,但是在内存上不相邻,即不连续)
- narrow() 切片操作
- view()
- expand()
- transpose()
- permute()
经过上述操作后得到的tensor, 其内部数据的布局方式和从头开始创建一个常规的tensor的布局方式不相同, contiguous()函数应用于此(当调用contiguous()时, 会强制拷贝一份tensor, 使得其布局和从头创建的一模一样)
维度扩展函数: squeeze(), unsequeeze()【输入输出共享内存】
更改维度位置函数:transpose(), permute()
改变tensor维度数值:expand(), repeat()
改变tensor的形状函数:view(), reshape() 【类似于tensor.contiguous().view(*args)】
矩阵运算操作中, 语义和内存顺序一致性是缓存友好的
Pytorch中的contiguous理解_gdymind的博客-CSDN博客_pytorch conti
“What is a “cache-friendly” code ? https://stackoverflow.com/questions/16699247/what-is-a-cache-friendly-code/16699282#16699282
计算机缓存Cache以及Cache Line详解 https://zhuanlan.zhihu.com/p/37749443
Pytorch中的矩阵乘法
随笔1: PyTorch中矩阵乘法总结 - 知乎
torch.mm()
torch.bmm()
torch.matmul() [可以认为该matmul()乘法使用参数后两维来进行计算]
torch.mul() 矩阵逐元素乘法
@矩阵乘法操作, *矩阵逐元素乘法
p
args.use_decoding_cache = True #新添加代码
args.decoding_strategy = "random_sample"
args.random_sample_topp = None
args.random_sample_topk = 5
args.random_sample_size = 5
print(args.decoding_strategy)
print(args.random_sample_size)
print(us)
past_key_value
第一处
key_layer = torch.cat([past_key_value[0], hidden_states], dim=1)
value_layer = torch.cat([past_key_value[0], hidden_states], dim=1)
batch_size, seq_length, hidden_size = key_layer.size()
query_layer_ = query_layer.squeeze(-2).contiguous().transpose(0, 1)
q_w = torch.bmm(query_layer_, self.k_proj_weight)
q_b = torch.bmm(query_layer_, self.k_proj_bias)
q_w = q_w.view(self.num_attention_heads, batch_size, -1, hidden_size). \
transpose(0, 1).contiguous().view(batch_size, -1, hidden_size)
q_b = q_b.view(self.num_attention_heads, batch_size, -1, 1).transpose(0, 1). \
reshape(batch_size, -1, 1)
attention_scores = torch.bmm(q_w, key_layer.transpose(-1, -2)) + q_b
attention_scores = attention_scores.view(batch_size, self.num_attention_heads, -1, seq_length)
耗时的bug版本代码
batch_size, seq_length, hidden_size = key_layer.size()
key_weight = self.key.weight.view(self.num_attention_heads, -1, self.hidden_size)
key_bias = self.key.bias.view(self.num_attention_heads, -1).unsqueeze(0).unsqueeze(2) \
.repeat(1, 1, seq_length, 1).permute(0, 1, 3, 2)
key_layer_el = key_layer.permute(0, 2, 1).unsqueeze(1)
attention_scores_1 = torch.matmul(query_layer, self.k_proj_weight)
attention_scores_1 = torch.matmul(attention_scores_1, key_layer_el)
attention_scores_2 = torch.matmul(query_layer, key_bias)
attention_scores = attention_scores_1 + attention_scores_2
第二处
key_layer = hidden_states
value_layer = hidden_states
batch_size, seq_length, hidden_size = key_layer.size()
query_layer_ = query_layer.transpose(0, 1).contiguous().view(self.num_attention_heads, -1,
self.attention_head_size)
q_w = torch.bmm(query_layer_, self.k_proj_weight)
q_b = torch.bmm(query_layer_, self.k_proj_bias)
q_w = q_w.view(self.num_attention_heads, batch_size, -1, hidden_size). \
transpose(0, 1).contiguous().view(batch_size, -1, hidden_size)
q_b = q_b.view(self.num_attention_heads, batch_size, -1, 1).transpose(0, 1). \
reshape(batch_size, -1, 1)
attention_scores = torch.bmm(q_w, key_layer.transpose(-1, -2)) + q_b
attention_scores = attention_scores.view(batch_size, self.num_attention_heads, -1, seq_length)
耗时的bug版本代码
# key_weight = self.key.weight.view(self.num_attention_heads, -1, self.hidden_size)
key_bias = self.key.bias.view(self.num_attention_heads, -1).unsqueeze(0).unsqueeze(2)\
.repeat(1, 1, seq_length, 1).permute(0, 1, 3, 2)
key_layer_el = key_layer.permute(0, 2, 1).unsqueeze(1)
attention_scores_1 = torch.matmul(query_layer, self.k_proj_weight) # 51 - 127
attention_scores_1 = torch.matmul(attention_scores_1, key_layer_el) # 127 - 185
#
attention_scores_2 = torch.matmul(query_layer, key_bias)
attention_scores = attention_scores_1 + attention_scores_2
第三处:
batch_size, seq_length, hidden_size = value_layer.size()
attention_probs_ = attention_probs.view(batch_size, -1, seq_length)
context_layer = torch.bmm(attention_probs_, value_layer)
context_layer = context_layer.view(batch_size, self.num_attention_heads, -1, hidden_size).transpose(0, 1) \
.contiguous().view(self.num_attention_heads, -1, hidden_size)
context_layer = torch.bmm(context_layer,
self.v_proj_weight.transpose(-1, -2)) # ([heads, seq_length* head_dim, hidden])
context_layer = context_layer.view(self.num_attention_heads, batch_size, -1, self.attention_head_size)
context_layer = context_layer + self.v_proj_bias
context_layer = context_layer.transpose(0, 1).contiguous().view(batch_size, self.num_attention_heads, -1,
self.attention_head_size)
#耗时的bug版本代码
batch_size, heads, seq_length, hidden_size = query_layer.size()
context_layer = torch.matmul(attention_probs, value_layer.unsqueeze(1))
value_weight = self.value.weight.view(self.num_attention_heads, -1, self.hidden_size).permute(0, 2, 1)
context_layer = torch.matmul(context_layer, value_weight)
value_bias = self.value.bias.view(self.num_attention_heads, -1).unsqueeze(0).unsqueeze(2).repeat(1, 1, seq_length, 1)
context_layer = context_layer + value_bias
文本生成任务
文本生成任务存储知识
Can Generative Pre-trained Language Models Serve as Knowledge Bases for Closed-book QA?
T5:https://arxiv.org/abs/1910.10683
博客:T5: Text-to-Text Transfer Transformer 阅读笔记 – 知乎
Transformer位置编码:让研究人员绞尽脑汁的Transformer位置编码 – 科学空间|Scientific Spaces
Transformer相对位置编码的缺陷:https://kexue.fm/archives/9105
位置编码
- 将位置信息融入到输入中, 构成绝对位置编码的做法
- 微调Attention结构,使得有能力分辨不同位置的Token, 构成相对位置编码的方法
绝对位置编码(绝对位置向量加入到语义信息向量中)
训练式:BERT、GPT使用的训练式位置编码, 缺点:无外推性, 通过层次分解的方式层次分解位置编码,让BERT可以处理超长文本 – 科学空间|Scientific Spaces, 可以使得绝对位置编码外推到足够长的范围。
三角式:三角函数式位置编码,Sinusoidal位置编码, transformer提出的显示解
递归式:RNN模型不需要位置编码,倘若在输入后面先接一层RNN, 再接Transformer,理论上不需要加位置编码。递归模型的位置编码具有很好的外推性以及灵活性, 递归形式位置编码牺牲一定的并行性, 可能会带来速度瓶颈。ICML2020的论文:https://arxiv.org/abs/2003.09229 使用微分方程(ODE)来建模位置编码,提出FLOATER的方案
相乘式:按元素逐位相乘的方法(提供一种思路)
相对位置编码(计算Attention时候考虑当前位置与被Attention的位置的相对距离, 灵活性更大)
经典式:是将本来依赖于二元坐标(i, j)的向量改为只依赖于相对距离i – j(二元位置向量坐标,替换由均有参数计算出来值)【此时k, v的相对位置距离表示为两个】, 并且通常来说会截断,以适应不同任意的距离。因此只需要有限个位置编码就可以表达出任意长度的相对位置
XLNET式:XLNET式位置编码源自于Transfomer-XL论文, 将绝对位置编码公式展开,将位置向量pi, pj进行了替换成相对位置编码和可训练向量。【从该工作后,v的相对位置编码偏置加到Attention矩阵上】
T5式:通过展开attention矩阵的计算公式, 仅仅是在Attention矩阵的基础上添加一个可训练的偏置项(ICLR2021上,一篇提出TUPE位置编码的文章https://arxiv.org/abs/2006.15595), T5相对位置进行了一个”分桶处理”, 即i – j位置对应的是f(i – j)位置
DeBERTa式:通过展开attention矩阵的计算公式, 将全由参数计算得到的结果舍弃, 将位置转换为相对位置编码
RoFormer中的RoPE(Rotary Position Embedding)位置编码【通过绝对位置编码的方式实现相对位置编码】(?)
Model
Training
Vocabulary
Unsupervised objective
Vocabulary
- WordPiece token:使用贪心算法来最大化语言模型概率, 即选取新的n-gram时都是选择使perplexity减少最多的n-gram。
- SentencePiece model:将词间的空白当成一种标记,可以直接处理sentence, 而不需要将其pre-tokenize成单词, 并带来更短的句子长度。
- Subword, Byte Pair Encoding(BPE):基本单元介于字符与单词之间, 利用n-gram频率来更新词汇库。
SentencePiece:https://arxiv.org/abs/1808.06226
SubWord:CS224N笔记(十二):Subword模型 – 知乎
NLP SubWord:https://zhuanlan.zhihu.com/p/86965595
Model structures
Encoder-Decoder
Language model
Prefix LM:分类器简单地集成到prefix LM中的transformer解码器的输出层中
Compare:
(存在参数量不同,但计算量几乎相同的情况)?
L + L编解码器 与 仅具有L层的语言模型大约相同的计算成本
L + L编解码器 与 具有2L层的语言模型大约相同数量的参数
编码器 – 解码器架构的效果更佳【尽管编码器/解码器模型使用的参数是”仅编码器”(例如BERT)或”仅解码器”(语言模型)体系结构的两倍,但其计算成本却相似。 我们还表明,在编码器和解码器中共享参数不会导致性能下降,并且使得总参数数量减半。】
- L + L层,具有2P个参数和M FLOP的计算成本
- L + L层,(参数在编码器和解码器之间共享), P个参数, M/2 FLOP的计算成本
- L/2 + L/2层, P个参数, M/2 FLOP的计算成本
- 具有L层, P参数的纯解码器语言模型, M FLOP计算成本
- 具有相同架构,但是对于输入具有完全可见的自注意力的解码器的前缀LM
adapter layers 可能是一种在较少参数上进行微调的有前途的技术,只要将维度适当地缩放到任务大小即可
尽管在微调过程中确实提供了一定的加速,但全局解冻会在所有任务中造成轻微的性能下降。通过更仔细地调整解冻时间表,可以获得更好的结果。
多任务训练:
我们可能会针对多个任务训练一个模型,但是在报告性能时,我们可以为每个任务选择不同的检查点
“多任务学习”仅对应于将数据集混合在一起。相比之下,大多数将多任务学习应用于NLP的应用都会添加特定于任务的分类网络,或者为每个任务使用不同的损失函数。
在多任务学习中一个非常重要的因素是模型应该在每个任务的 多少数据进行训练
通过在较少的步骤上训练更大的模型通常比在较小的模型上训练更多的数据要好
如何准确设置每个任务的数据比例取决于各种因素,包括 数据集大小, 学习任务的”难度”(即模型在有效执行任务之前必须看到多少数据), 正则化等
另一个问题是潜在的”任务干扰”或”负向转移”,在一个任务上实现良好的性能会阻碍在另一任务上的性能。鉴于这些问题,我们先探索各种设置每个任务的数据比例的策略。 Can You Tell Me How to Get Past Sesame Street? Sentence-Level Pretraining Beyond Language Modeling – ACL Anthology
模型规模
提高模型容量, 增加模型训练时间(额外的预训练可以提供帮助,增加批次大小和增加训练步骤均有提升),均有收益
使用大规模模型具有更好的性能
将迁移学习应用于影响最大的地方。这些方面目前的一些工作包括 distillation 蒸馏,parameter sharing 参数共享和 conditional computation 条件计算。
软硬件操作
Accelerate库的使用
操作指南:🤗Accelerate库的使用指南和案例 – 知乎
Huggingface Accelerate 学习笔记_元气少女wuqh的博客-CSDN博客_accelerate launch
- 使用进行accelerate脚本配置 accelerate config
- 运行accelerate test测试脚本是否能够正常工作
- 运行脚本 accelerate launch path_to_script.py –args_for_the_script 同时运行第二个脚本需要设置运行端口(accelerate launch –config_file config.yaml –main_process_port 端口号 main.py)config.yaml作为可选择参数,默认保存在~/.cache/huggingface/accelerate,也可以指定yaml
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch –nproc_per_node=2 –master_port 29501 main.py 使用DDP多卡训练设置端口号(DDP训练方式)
保存模型:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
accelerator.save(unwrapped_model.state_dict(), path)
加载模型:
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.load_state_dict(torch.load(path))
Original: https://blog.csdn.net/jiangchao98/article/details/124084692
Author: jiangchao98
Title: 中文文本纠错论文
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530318/
转载文章受原作者版权保护。转载请注明原作者出处!