

本文主要对monodepth2的理论和源码部分进行一定的总结,实战部分可以参考我的另一篇博客深度估计自监督模型monodepth2在自己数据集的实战——单卡/多卡训练、推理、Onnx转换和量化指标评估
一、论文理解:


本论文主要是基于单目视频流的方法,也可加入双目立体图像训练,
主体上继承Unsupervised Learning of Depth and Ego-Motion from Video(CVPR 2017)的视频无监督方案,加入三点提升。图像重构的基础原理如下:
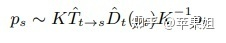
上面公式相当于两个相机坐标系下的转换,即原图像先用内参的逆转换到它的相机坐标系,再用旋转平移矩阵转到另一个相机坐标系,再用内参转到另一个相机的图像坐标系,注意这里用的是反向warping,可以保证source图和重构target图像中的像素一一对应,而深度Z是数乘,可以变换位置。网络中使用depth网络预测深度,也就是D,输入是第0帧图像,,再用pose网络预测位姿变换,也就是T,输入是-1和0,0和1两对图像,然后用D,T和已知的K,用第-1帧和第1帧分别来重构第0帧(target图像),分别计算原始图像和重构图像之间的损失,最后对损失逐像素取最小值。
损失函数包括两部分,主要包括光度重建损失和L1损失的加权、边缘平滑损失:
重建损失Lp:
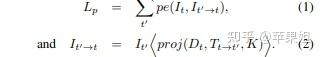
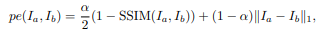
平滑损失Ls:

主要提升:
- 一个最小重投影误差,用来提升算法处理遮挡场景的鲁棒性、
- 一种全分辨率多尺度采样方法,可以减少视觉伪影
- 一种auto-masking loss,用来忽略训练像素中违反相机运动假设的像素点
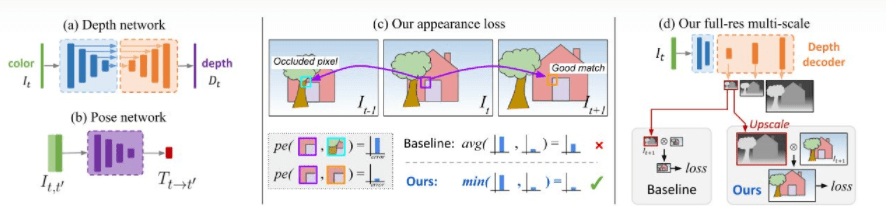
第一点意思是其他方法是采用多个输入图片投影误差的均值,这样由于有些像素存在遮挡,找不到对应的像素,导致损失函数惩罚较大,会引起结果边缘不准,本文采用的是多张输入图片中最小的冲投影损失所谓损失函数,可以使深度边缘更清晰,准确性更高。
第二点意思是其他方法是在CNN每一层输出的深度图上直接计算损失,导致低分辨率的深度图可能出现空洞和视觉伪影(texture-copy artifacts.),本文把每一个中间层输出的深度图都用双线性插值上采样到与输入一致的分辨率,减少了视觉伪影。

其他问题:
1、 本算法失效的情况:违反朗伯假设的,如畸变的,反光的,饱和度高的区域,和边缘模糊、形状复杂的目标
2、 提到full eigen数据集里面有一些相机静止的序列,依然表现较好,还有一个KITTI补全的数据集评测效果也较好,后面可以看看如何补全。
3、 用了reflection padding代替zero padding,解码器中对于超出边界之外的点用最近的边界像素代替。位姿网络中用轴角表示法,旋转平移矩阵乘以0.01,预测6个自由度的位姿。最后的尺度恢复采用中值缩放的方式,把输出和真值缩放到同样的尺度。真值采用整个测试集的真值尺度。
4、 实验部分围绕三个改进点分别测试。
二、代码阅读:
1.输入部分:
数据输入部分随机地做颜色增强和翻转的augmentation,输入网络的部分是做了augmentation的部分。如果选share的encoder,全部frame都要输进去,否则只输第0帧得到depth。输入网络的数据做了四种尺度变化,最开始保留了5种,原始,设定,设定/2、4、8,然后删掉了原始。内参矩阵也做了四种尺度变化(这个为了图像重建的计算)只把设定分辨率的输入输入了encoder和depth_decoder中,使用不用的输入输出通道数得到了四个分辨率的disp图。 如果有depth_gt的话也输入了网络作为监督信号加速loss收敛。
2.depth网络:
depth网络把得到的四种尺度图像输入encoder,得到futures再输入depth_decoder。整个网络类似于U-NET结构。
3.pose网络:
Pose网络有三种可选:共享encoder、单独的resnetencoder(默认)、单独的pose网络。如果使用共享模式,直接把encoder对应的frame_id的特征输入decoder,用单独的encoder情况把输入数据中原始大小的每一对frame拼接在一起输入encoder, Posedecoder输出两个特征,R和T, cam_T_cam这个矩阵是结合R和T的。
4.计算重建图像:
generate_images_pred函数,就是利用depth网络输出的disp(可得到depth)和pose网络输出的RT,重建图像。首先把每一层的disp图都双线性插值上采样到原始分辨率,再把每个深度图转成点云,用meshgrid函数画坐标轴,再把点云通过RT转到另一个相机坐标系,再用内参转到另一个图像的坐标。转完得到了sample,最后两维代表0帧到1或-1帧的坐标对应关系,然后用F.grid_sample函数从1或-1帧图中按照sample的坐标点取值(非整数坐标插值),重建0帧图像,可以和原始0帧图像计算损失。这就是反向warp的操作,这样可以保证坐标点一一对应(虽然会有重复像素),正向warp是重建1或-1帧,不能保证一一对应。
5.计算损失:
compute_losses函数计算损失,包括重建损失和平滑损失。重建损失分别计算了每一层深度图(已上采样到原始分辨率)每一组前后帧输入的重建损失reprojection_losses,指标采用SSIM和L1加权平均,这个操作对应了主要贡献的第二条。然后又计算了identity_reprojection_losses,也就是前后帧之间的相似度,然后全拼接在一起按channel取最小值,这样就同时实现了主要贡献中的第一、三条,即把多个图像相应像素损失的最小值而不是平均值纳入loss,可以更好地处理遮挡场景,使得边缘清晰,同时实现了auto-mask, 忽略了前后帧像素没怎么变化的区域(运动区域),保留了有变化的区域。代码中还提供了其他mask形式的对照。如果是预输入的mask,则直接乘以mask矩阵。平滑损失用到了inputs中其它分辨率的输入图像,和相应的深度图联合计算。最后还计算了总损失。
6.由于第一次看pytorch代码,记录一些小收获:
a.nn.Sequential和nn.ModuleList的区别,见详解PyTorch中的ModuleList和Sequential – 知乎 (zhihu.com)
b.pytorch把所有的参数分类都写在options.py里面,用self.parser.add_argument读取,非常清晰。里面还包括了作者做对照试验用到的参数,很多都是可配置的。
c.网络里用到了nn.init.kaiming_normal_这个初始化函数(一看就是大神的),专门针对relu做初始化,见https://blog.csdn.net/dss_dssssd/article/details/83959474,还有 nn.ELU激活函数,可输出负数,再就是SSIM网络利用了反射padding:nn.ReflectionPad2d
d.model.model_dict()和optimizer.state_dict()存储了模型参数和优化器参数字典。
e. SummaryWriter可以做可视化,包括loss、模型等
f .SSIM计算用到了方差=平方的均值-均值的平方,且用平均池化做了局部均值方差的计算。
g.checkpoints的意思https://www.cnblogs.com/jiangkejie/p/13049684.html
h. len(self)和__getitem__(self, index)这种格式用来自定义一些属性,这两个代表len()和直接取索引
Original: https://blog.csdn.net/weixin_43148897/article/details/122453979
Author: 苹果姐
Title: 深度估计自监督模型monodepth2论文总结和源码分析【理论部分】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/701520/
转载文章受原作者版权保护。转载请注明原作者出处!