

1、前言
在上个学习笔记中学习warpaffine,并且在opencv下面实现了图像的预处理,而warpaffine可以很好的利用cuda加速来实现,于是基于手写AI的项目,又学习了warpaffien在cuda上的加速。
欢迎正在学习或者想学的CV的同学进群一起讨论与学习,v:Rex1586662742,q群:468712665
2、学习内容
2.1、双线性插值
在缩放后的原图恢复到原图或者模型得到的结果需要恢复的原尺寸需要用到双线性差值,双向性差值的基本原理是靠近谁,谁的权重就大,可由下图表示
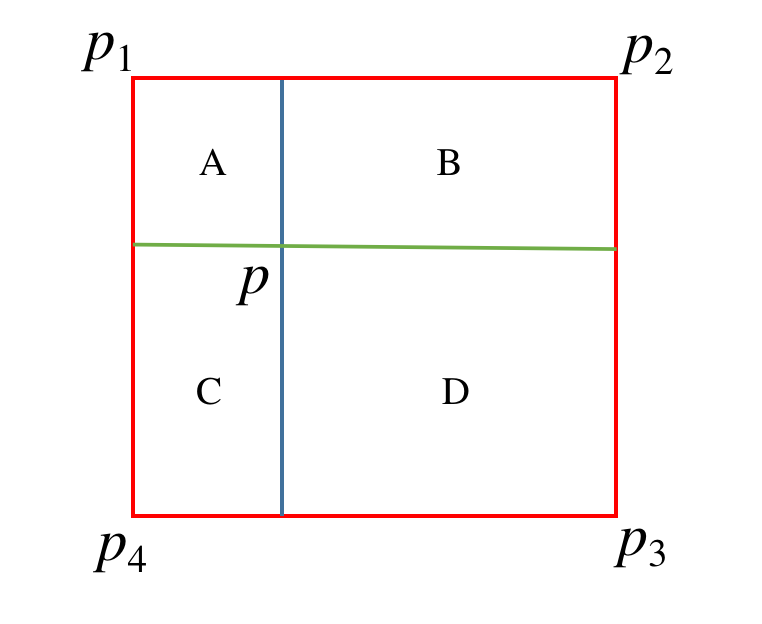

; 图中点 p 的值由起周围的 p 1 ~ p 4 四个值的确定, p 1 的权重为正方形D的面积占总面试的比例, p 2的权重为正方形C占总面积的比例。代码如下:
p1 = 1
p2 = 2
p3 = 8
p4 = 12
p = 0.6,0.8
p1_w = (1 - p[0]) * (1 - p[1])
p2_w = p[0] * (1 - p[1])
p3_w = (1 - p[0]) * p[1]
p4_w = p[0] * p[1]
res = p1 * p1_w + p2 * p2_w + p3 * p3_w + p4 * p4_w
print(res)
下面将利用双线性差值来实现warpaffine
import cv2
import numpy as np
import matplotlib.pyplot as plt
def myWarpaffine(img,M,d_size,constant=(0, 0, 0)):
M_inv = cv2.invertAffineTransform(M)
constant = np.array(constant)
o_h, o_w = img.shape[:2]
d_h, d_w = d_size
dst_img = np.full((d_h, d_w, 3), constant, dtype=np.uint8)
o_range = lambda p: p[0] >= 0 and p[0] < o_w and p[1] >= 0 and p[1] < o_h
for y in range(d_h):
for x in range(d_w):
homogeneous = np.array([[x, y, 1]]).T
ox, oy = M_inv @ homogeneous
low_ox = int(np.floor(ox))
low_oy = int(np.floor(oy))
high_ox = low_ox + 1
high_oy = low_oy + 1
p = ox - low_ox, oy - low_oy
p1_w = (1 - p[0]) * (1 - p[1])
p2_w = p[0] * (1 - p[1])
p3_w = (1 - p[0]) * p[1]
p4_w = p[0] * p[1]
p1 = low_ox, low_oy
p2 = high_ox, low_oy
p3 = low_ox, high_oy
p4 = high_ox, high_oy
p1_value = img[p1[1], p1[0]] if o_range(p1) else constant
p2_value = img[p2[1], p2[0]] if o_range(p2) else constant
p3_value = img[p3[1], p3[0]] if o_range(p3) else constant
p4_value = img[p4[1], p4[0]] if o_range(p4) else constant
dst_img[y, x] = p1_w * p1_value + p2_w * p2_value + p3_w * p3_value + p4_w * p4_value
return dst_img
if __name__ == "__main__"
img_o = cv2.imread("/home/rex/Desktop/rex_extra/notebook/warpaffine/keji2.jpeg")
M = cv2.getRotationMatrix2D((0, 0), -30, 0.6)
or_test = cv2.warpAffine(img_o, M, (640, 640))
my_test = myWarpaffine(img_o,M,(640, 640))
plt.figure(figsize=(10, 10))
plt.subplot(1, 2, 1)
plt.title("opencv")
plt.imshow(or_test[...,::-1])
plt.subplot(1, 2, 2)
plt.title("pyWarpaffine")
plt.imshow(my_test[...,::-1])
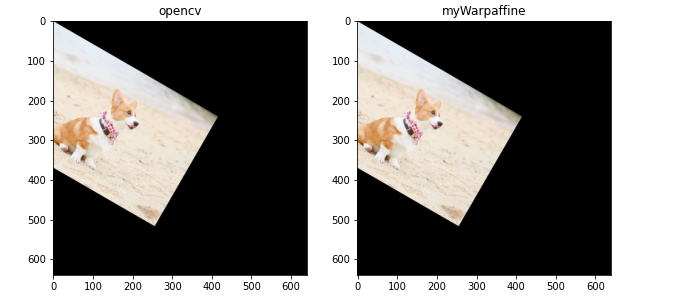
可以得到如下结果,左图为opencv实现的效果,右图为自定义实现的结果,发现结果一致,说明自己实现的双线性差值的warpaffine是正确的。
; 有了上述的铺垫之后,接下来正式进入warpaffine在cuda上的加速
2.3、warpaffine-cuda加速
将warpaffine在cuda上进行加速,其核函数如下
__global__ void warp_affine_bilinear_kernel(
uint8_t* src, int src_line_size, int src_width, int src_height,
uint8_t* dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value, AffineMatrix matrix
){
// 线程ID的全局索引
int dx = blockDim.x * blockIdx.x + threadIdx.x;
int dy = blockDim.y * blockIdx.y + threadIdx.y;
// 线程ID 超过图像大小时 return
if (dx >= dst_width || dy >= dst_height) return;
// 目标图像为640*640*3 用fill_value填充
float c0 = fill_value, c1 = fill_value, c2 = fill_value;
float src_x = 0; float src_y = 0;
//将目标图上一点映射回原图大小
affine_project(matrix.d2i, dx, dy, &src_x, &src_y);
if(src_x < -1 || src_x >= src_width || src_y < -1 || src_y >= src_height){
// out of range
// src_x < -1,high_x < 0,超出范围
// src_x >= -1,high_x >= 0,存在取值
}else{
// p1 p2
// p
// p3 p4
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
uint8_t const_values[] = {fill_value, fill_value, fill_value};
//双线性差值,和python版一致
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
uint8_t* v1 = const_values;
uint8_t* v2 = const_values;
uint8_t* v3 = const_values;
uint8_t* v4 = const_values;
if(y_low >= 0){
if (x_low >= 0)
v1 = src + y_low * src_line_size + x_low * 3;
if (x_high < src_width)
v2 = src + y_low * src_line_size + x_high * 3;
}
if(y_high < src_height){
if (x_low >= 0)
v3 = src + y_high * src_line_size + x_low * 3;
if (x_high < src_width)
v4 = src + y_high * src_line_size + x_high * 3;
}
// 该点的像素值
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);
}
uint8_t* pdst = dst + dy * dst_line_size + dx * 3;
pdst[0] = c0; pdst[1] = c1; pdst[2] = c2;
//BGR -> RGB
// pdst[2] = c0; pdst[1] = c1; pdst[2] = c0;
// (p - mean) / std
// pdst[0] = (c0 - mean) / std; pdst[1] = (c1 - mean) / std; pdst[2] = (c2 - mean) / std;
}
2.4 warpaffine-cuda 加速测试
通过配置CMakeLists.txt中的 tensorrt以及其他路径即可,测试结果如下

; 通过一个核函数可以实现 图像的预处理 、标准化、BGR -> RGB,由此可以利用cuda实现warpaffine是十分高效的,其测试代码也可以在个人gitee中找到
3、总结
本次学习内容学习了双线性差值,并利用python实现了cpu版本,利用cuda实现了gpu版本,对于图像预处理而言,极大的加速了图像预处理的速度
Original: https://blog.csdn.net/weixin_42108183/article/details/124199939
Author: RexLK
Title: 【CV学习笔记】图像预处理warpaffine-cuda加速
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/529979/
转载文章受原作者版权保护。转载请注明原作者出处!