

IMDB电影数据分析实践
根据IMDB5000部电影数据集进行下列数据分析:
- 数据准备:读取数据并查看数据的基本信息
- 数据清洗:缺失值处理,重复值处理,处理后”干净”数据的基本信息。
-
数据分析及可视化展示:
-
电影出品国及地区和演员票房的情况分析:
绘制电影出品数量排名前10位的国家及地区的条形图;绘制票房前十的电影中喜爱男 1 号,男 2 号,男 3 号的人数的分组条形图。 - 电影数量的分析:
按年份统计每年电影总数量、彩色影片数量和黑白影片数量并绘制折线图(在同一个坐标系中绘制)。 - 电影类型的分析:
绘制不同类型的电影数量条形图和饼图。 - 电影评分统计及电影评分相关因素分析:
找出评分排名前 20 位电影的片名和评分;绘制所有影片评分与受欢迎程度的关系散点图。
文章目录
- 一、数据准备:
*
– - 二、数据清洗
* - 1. 缺失数据处理
- 2. 重复值处理
- 3. 处理后的数据
- 三、数据分析及可视化展示
* - 1. 电影出品国及地区和演员票房的情况分析:
– - 2. 电影数量的分析:
- 3. 电影类型的分析:
- 4. 电影评分统计及电影评分相关因素分析:
–
一、数据准备:
读取数据并查看数据的基本信息
1. 导入numpy 包和 pandas 包,使用 read_csv 方法读取本地 csv 数据;
import pandas as pd
import numpy as np
movies = pd.read_csv('D:\\gaojie\\movie_metadata.csv',encoding='utf—8')
2. 查看数据的基本内容、结构
- 打印前五行观察
movies.head (5)
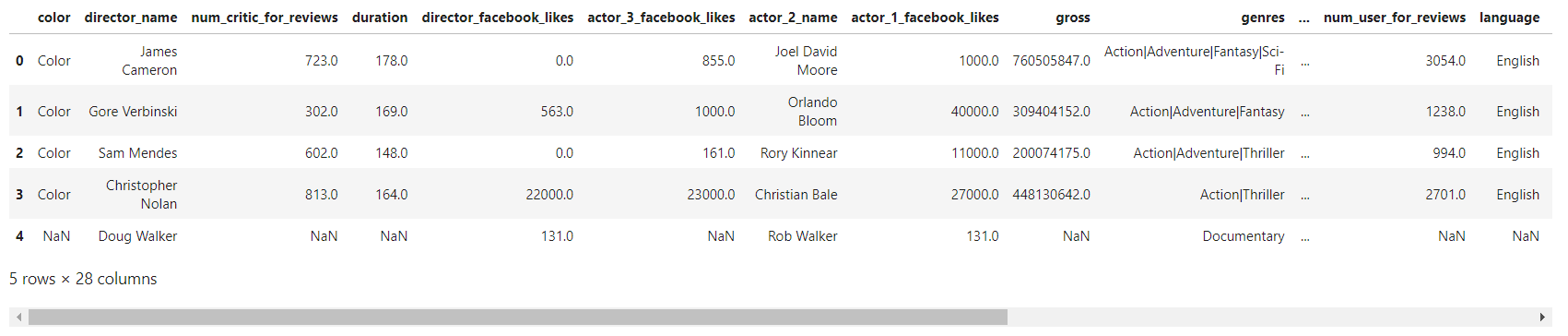

2. 输入 .shape 看看有多少行多少列
movies.shape

3. 查看列的数据类型
movies.dtypes

二、数据清洗
数据清洗也叫数据预处理,因为大多时候获取的数据并不符合我们的数据分析的标准这时候我们就需要对数据进行预处理,使之数据更加规整有序方便我们下一步的分析。数据清洗通常需要数据分析大部分时间,但是我觉得也是有一定的步骤的,我将它大致分为六部曲: 选择子集→列名重命名→缺失数据处理→数据类型转换→数据排序→异常值处理
1. 缺失数据处理
- 先通过isnull函数看一下是否有空值,结果是有空值的地方显示为True,没有的显示为False
print(movies.isnull())
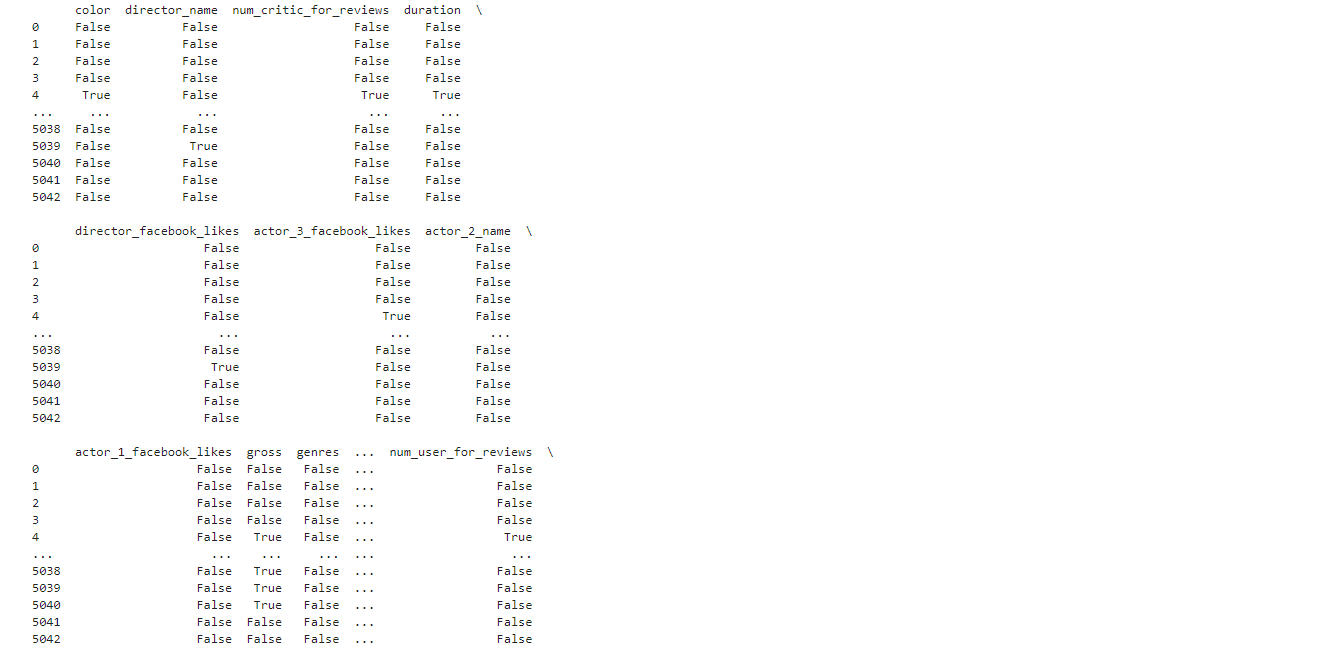
2. 再通 过 isnull().sum() 直接看每一列有多少空值
print(movies.isnull().sum())

3. 为了方便我们这里选择直接删除有缺失值的行
print ('删除缺失值前数据集大小 ',movies.shape )
movies = movies.dropna(how ='any' )
print ('删除缺失值后大小 ',movies.shape )

4. 这里我们选择删除电影名重复的行:
movies.drop_duplicates(subset=["movie_title"],keep='first',inplace=True)
print(movies.duplicated().value_counts())

2. 重复值处理
- 先用 duplicated() 方法进行逻辑判断,确定是否有重复值,统计重复值的数量
print(movies.duplicated().value_counts())

2. 再用 duplicates(subset,keep,inplace) 方法对某几列下面的重复行删除
– subset: 以哪几列作为基准列,判断是否重复,如果不写则默认所有列都要重复才算
– keep: 保留哪一个,fist-保留首次出现的,last-保留最后出现的,False-重复的一个都不保留,默认为first
– inplace: 是否进行替换,最好选择 False,保留原始数据,默认也是 False 这里我们选择删除所有电影名重复的行
movies.drop_duplicates(subset=['director_name'],keep='first',inplace=True)
print(movies.duplicated().value_counts())

3. 处理后的数据
使用 info 查看处理后”干净”数据的基本信息:
movies.info

可以看到,处理后数据为3655行,保留了所有的列。我们将在此数据集上做数据分析及可视化展示。
三、数据分析及可视化展示
1. 电影出品国及地区和演员票房的情况分析:
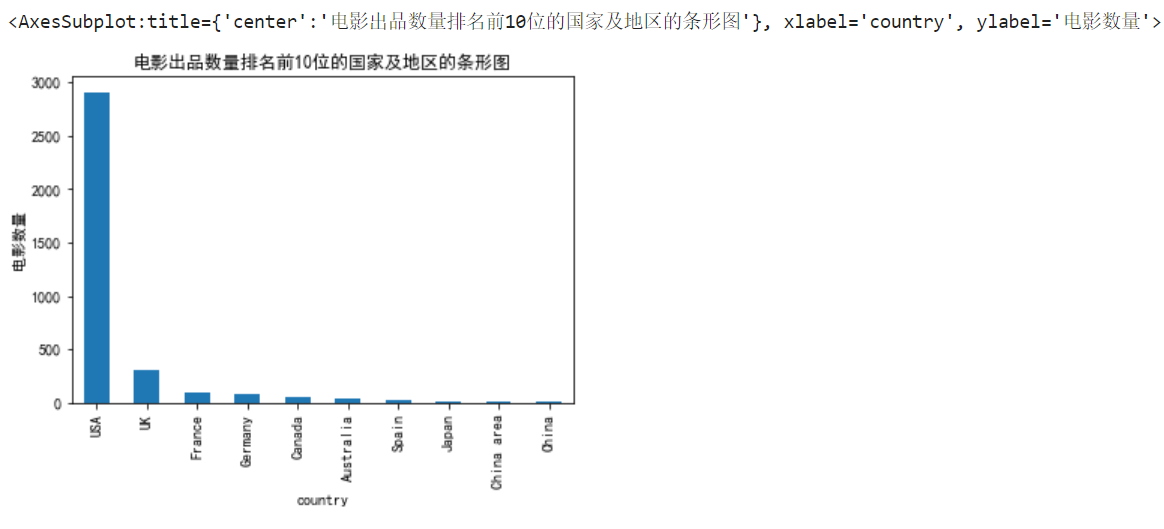
1.1 绘制电影出品数量排名前10位的国家及地区的条形图;
- 按country分组,统计所有国家的电影数量
country_group = movies.groupby('country').size()
country_group

2. 电影出品数量排名前10位的国家
group_head_10=country_group.sort_values(ascending=False).head(10)
group_head_10

3. 绘制电影出品数量排名前 10 位的柱形图的国家及地区的条形图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family']='SimHei'
plt.ylabel('电影数量')
plt.title('电影出品数量排名前10位的国家及地区的条形图')
group_head_10.plot(kind = 'bar')
1.2 绘制票房前十的电影中喜爱男1号,男2号,男3号的人数的分组条形图。
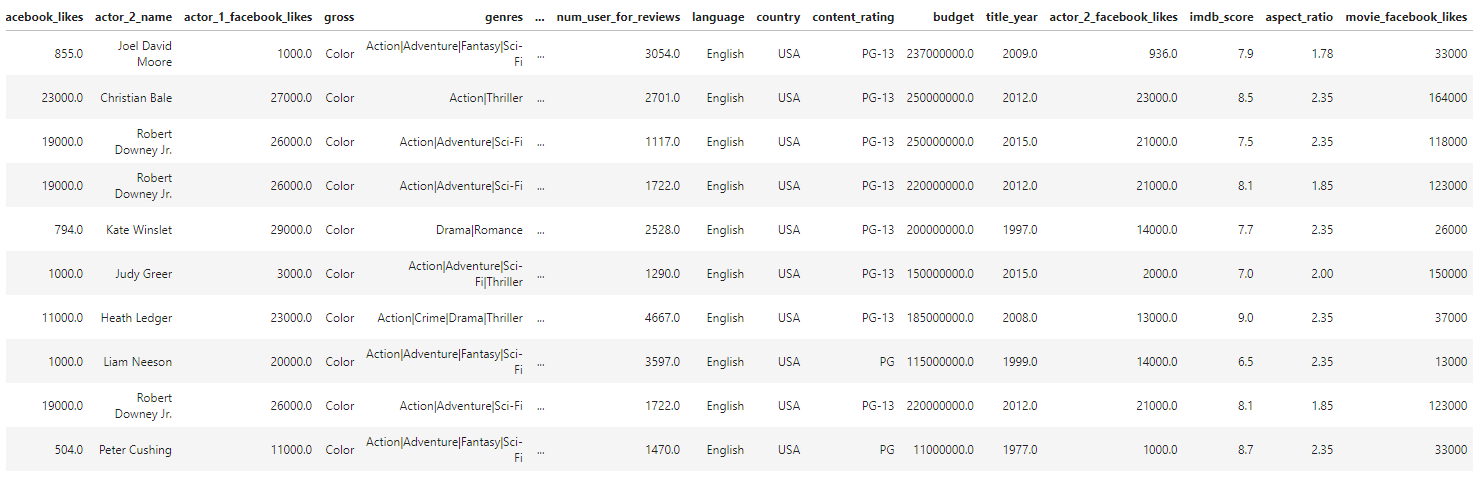
- 将电影按票房数降序排序,切取前10的电影信息
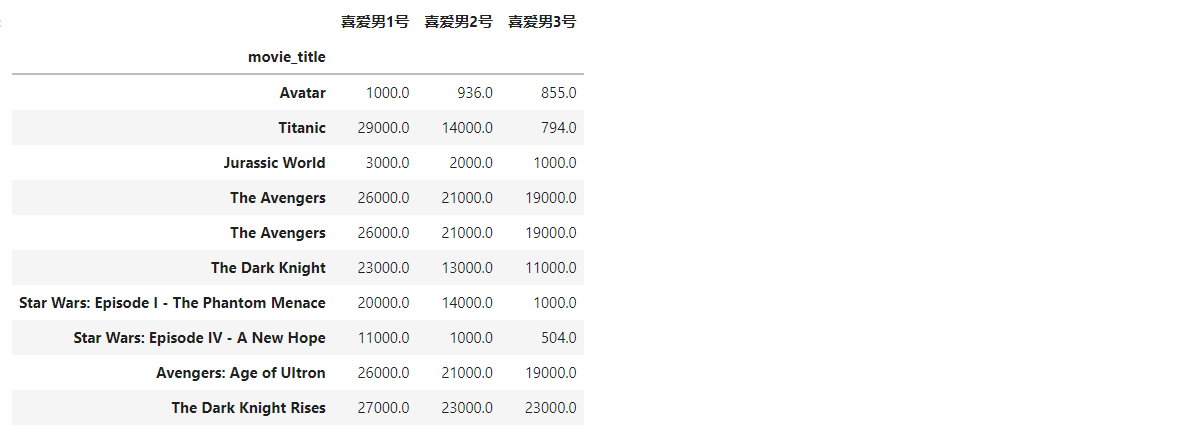
movies_max=movies.sort_values(['gross'],ascending=False).head(10)
movies_max1=movies_max[['actor_1_facebook_likes','actor_2_facebook_likes','actor_3_facebook_likes']]
movies_max1
2. 创建 DataFrame,作为分组条形图的数据集
df = pd.DataFrame({'喜爱男1号':movies_max1['actor_1_facebook_likes'].values,
'喜爱男2号':movies_max1['actor_2_facebook_likes'].values,
'喜爱男3号':movies_max1['actor_3_facebook_likes'].values},
index=movies_max['movie_title'].str.strip())
df
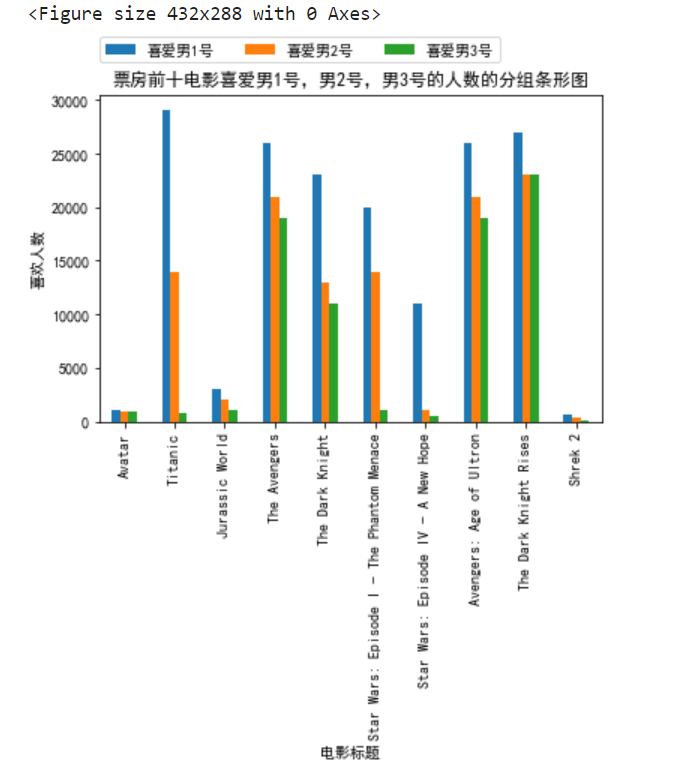
3. 绘制分组条形图
plt.figure()
df.plot.bar()
plt.title("票房前十电影喜爱男1号,男2号,男3号的人数的分组条形图")
plt.legend(ncol=3,loc=(0,1.1))
plt.xlabel('电影标题')
plt.ylabel('喜欢人数')
plt.show()
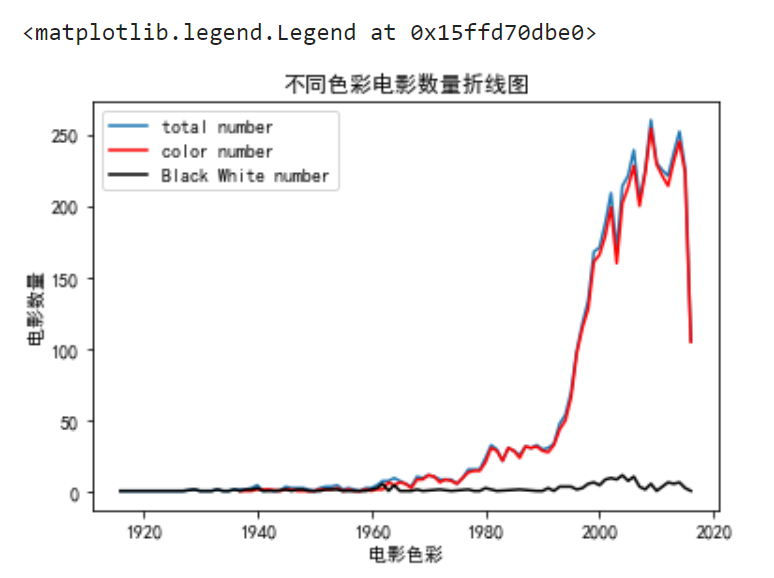
2. 电影数量的分析:
- 按年份统计每年电影总数量、彩色影片数量和黑白影片数量并绘制折线图(在同一个坐标系中绘制)。
movies['title_year'].value_counts().sort_index().plot(kind='line',label='total number')
movies[movies['color']=='Color']['title_year'].value_counts().sort_index().plot(kind='line',c='red',label='color number')
movies[movies['color']!='Color']['title_year'].value_counts().sort_index().plot(kind='line',c='black',label='Black White number')
plt.legend(loc='upper left')
plt.xlabel('电影色彩')
plt.ylabel('电影数量')
plt.title('不同色彩电影数量折线图')
plt.legend(loc='upper left')
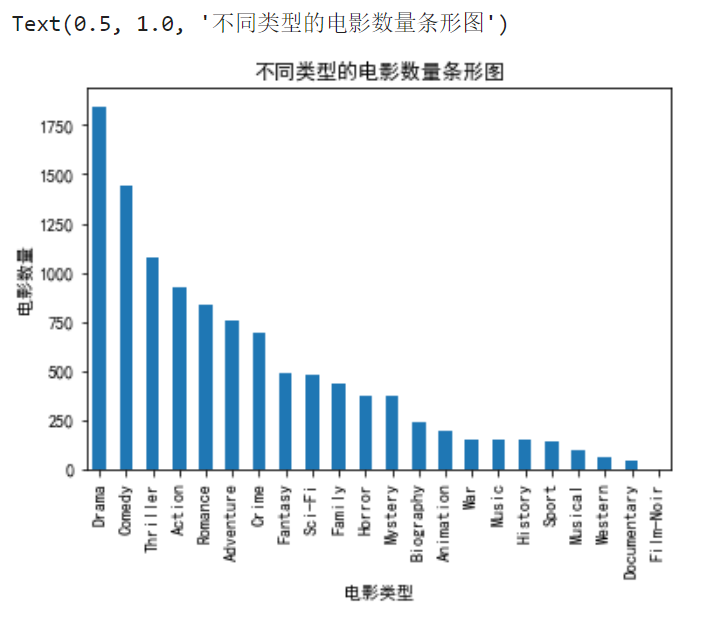
3. 电影类型的分析:
绘制不同类型的电影数量条形图和饼图。
- 提取 genres 列所有的电影类型,放入一个数组中;
types = []
for tp in movies['genres']:
sp = tp.split('|')
for x in sp:
types.append(x)
types_df = pd.DataFrame({'genres':types})

2. 统计字典中各种类型的数量
types_df_counts = types_df['genres'].value_counts()
types_df_counts

3. 绘制不同类型的电影数量条形图
types_df_counts.plot(kind='bar')
plt.xlabel('电影类型')
plt.ylabel('电影数量')
plt.title('不同类型的电影数量条形图')
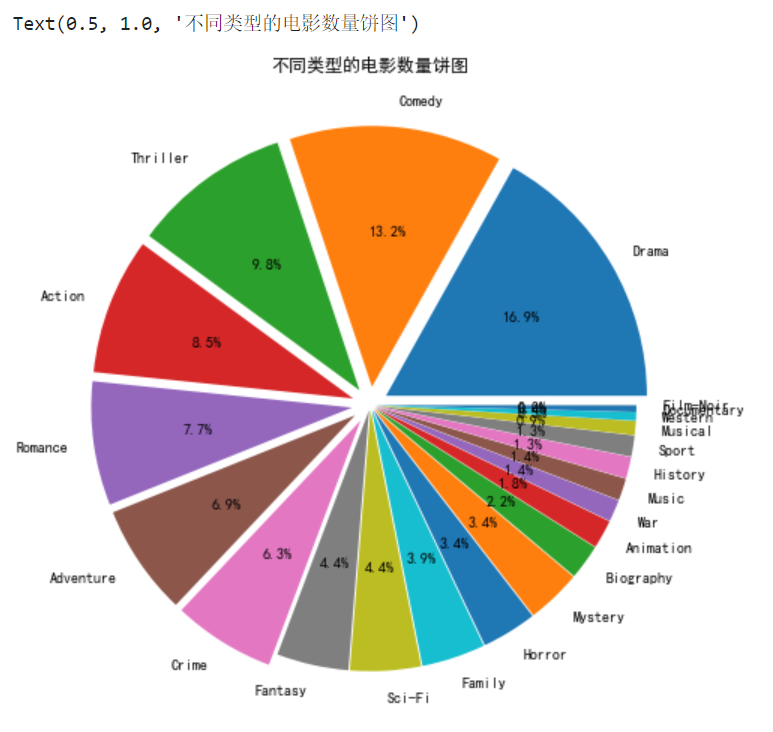
4. 绘制不同类型的电影数量饼图
b1 = types_df_counts/types_df_counts.sum()
explode = (b1>=0.06)/20+0.02
types_df_counts.plot.pie(autopct='%1.1f%%',figsize=(8,8),\
label='',explode=explode)
plt.title('不同类型的电影数量饼图')
4. 电影评分统计及电影评分相关因素分析:
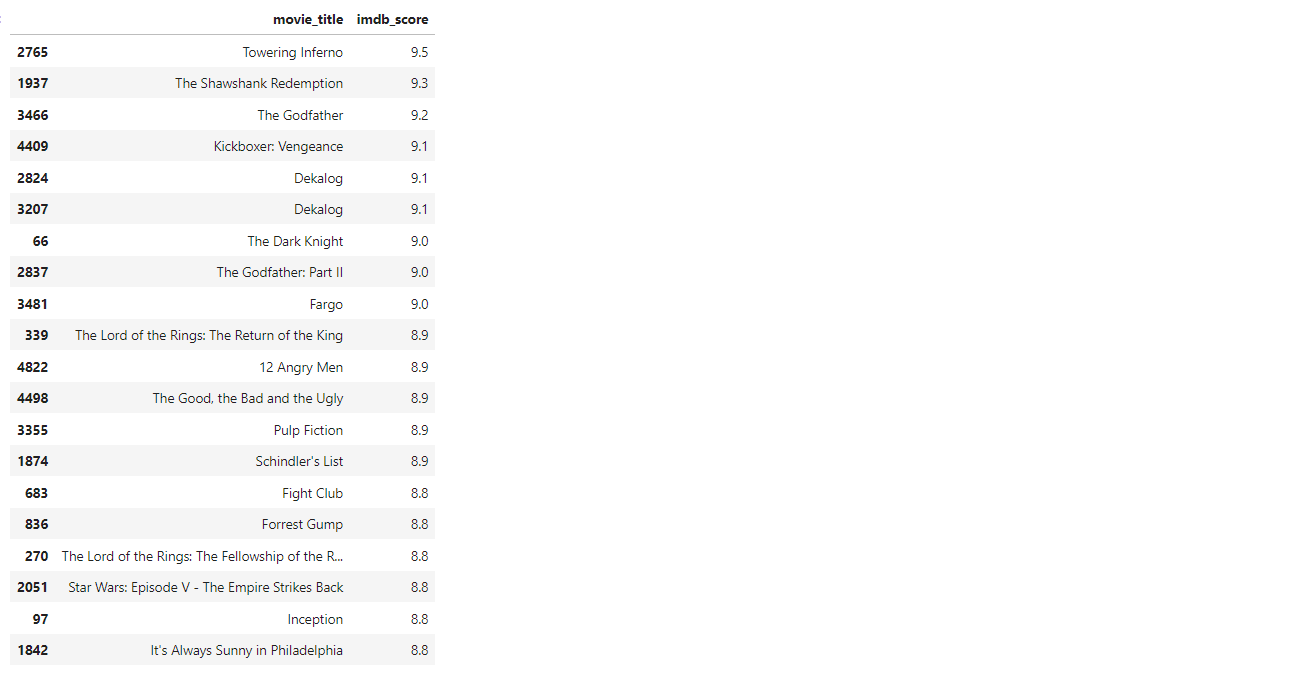
4.1 找出评分排名前20位电影的片名和评分;
movie_score_20 = movies.sort_values(['imdb_score'],ascending=False).head(20)
movie_score_20[['movie_title','imdb_score']]
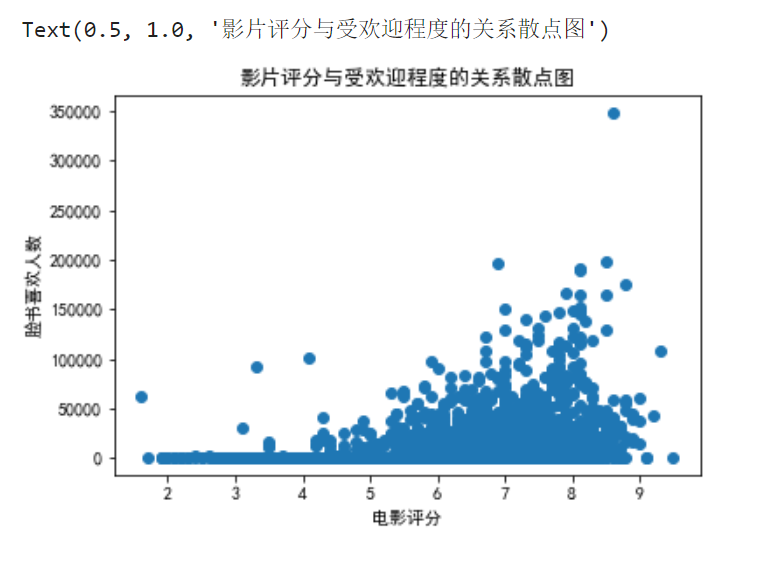
4.2 绘制所有影片评分与受欢迎程度的关系散点图。
plt.scatter(x= movies.imdb_score,y=movies.movie_facebook_likes)
plt.xlabel('电影评分')
plt.ylabel('脸书喜欢人数')
plt.title('影片评分与受欢迎程度的关系散点图')
Over
😃分享不易,点赞关注不迷路!
Original: https://blog.csdn.net/qq_48494305/article/details/121847870
Author: 猿小白→_→
Title: IMDB电影数据分析实践
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/696236/
转载文章受原作者版权保护。转载请注明原作者出处!