

RDB 文件使用二进制方式存储 Redis 内存中的数据,具有体积小、加载快的优点。本文主要介绍 RDB 文件的结构和编码方式,并借此探讨二进制编解码和文件处理方式,希望对您有所帮助。
本文基于 RDB version9 编写, 完整解析器源码在 github.com/HDT3213/rdb
RDB 文件的整体结构
如下图所示,我们可以将 RDB 文件划分为文件头、元属性区、数据区、结尾四个部分:
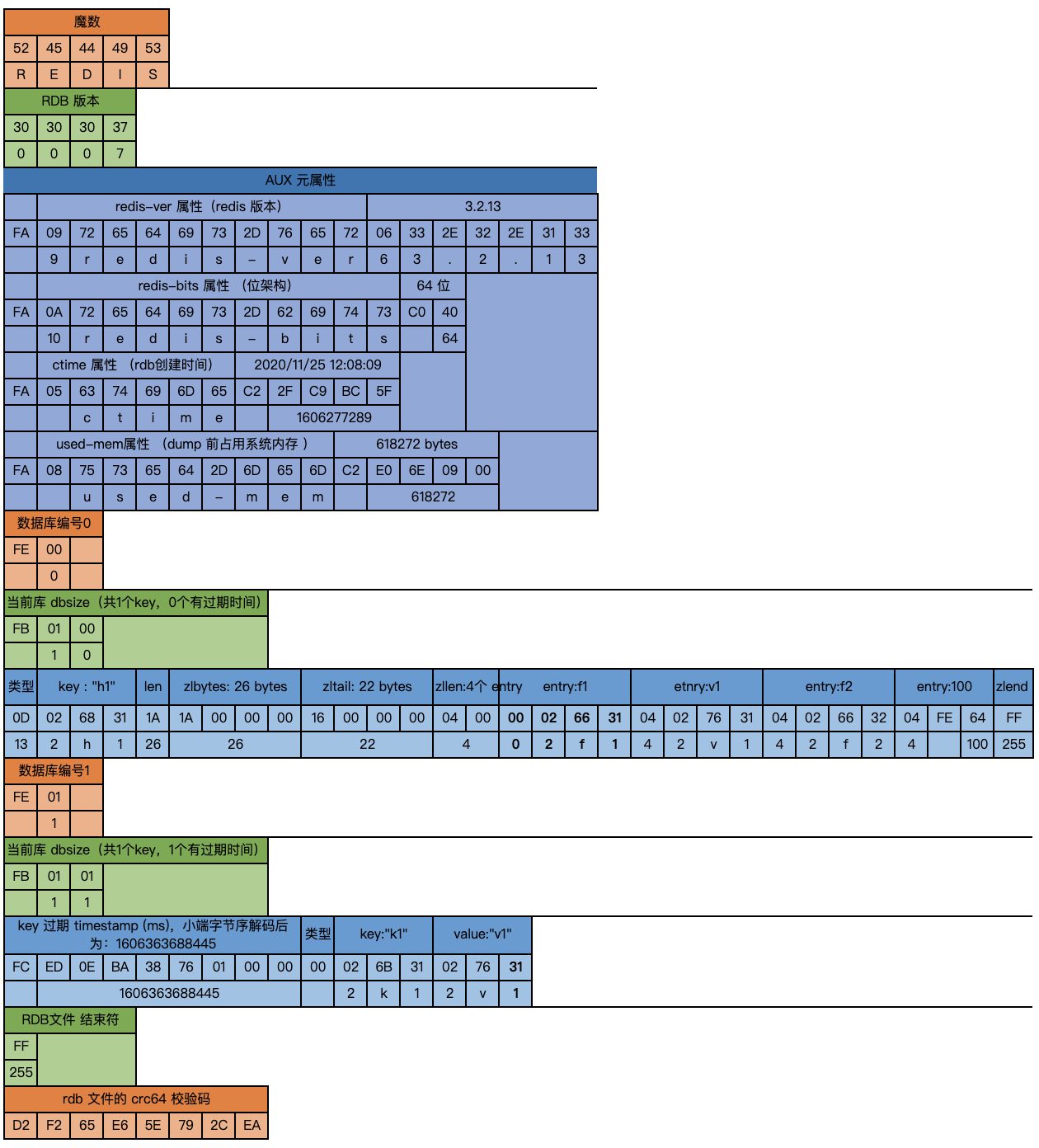

- 文件头包含 Magic Number 和版本号两部分
- RDB文件以 ASCII 编码的 ‘REDIS’ 开头作为魔数(File Magic Number)表示自身的文件类型
- 接下来的 4 个字节表示 RDB 文件的版本号,RDB 文件的版本历史可以参考:RDB_Version_History
- 元属性区保存诸如文件创建时间、创建它的 Redis 实例的版本号、文件中键的个数等信息
- 数据区按照数据库来组织,开头为当前数据库的编号和数据库中的键个数,随后是数据库中各键值对。
Redis 定义了一系列 RDB_OPCODE 来存储一些特殊信息,在下文中遇到各种 OPCODE 时再进行说明。
元属性区
元属性区数据格式为:RDB_OPCODE_AUX(0xFA) + key + value, 如下面的示例:
5245 4449 5330 3030 39fa 0972 6564 6973 REDIS0009..redis
2d76 6572 0536 2e30 2e36 fa0a 7265 6469 -ver.6.0.6..redi
您可以使用 xxd 命令来查看 rdb 文件的内容,或者使用 vim 打开然后在命令模式中输入:
:%!xxd开启二进制编辑
xxd 使用十六进制展示,两个十六进制数为一个字节,两个字节显示为一列
上图中第 10 个字节 0xFA 为 RDB_OPCODE_AUX,它表示接下来有一个元属性键值对。接下来为两个字符串 0972 6564 6973 2d76 6572、 0536 2e30 2e36,它们分别表示 “redis-ver”, “6.0.6”,这三部分组成了一个完整的元属性描述。
在 xxd 中可以看出字符串编码 0972 6564 6973 2d76 6572 由开头的长度编码 0x09 和后面 “redis-ver” 的 ascii 编码组成,我们将在下文字符串编码部分详细介绍它的编码规则。
数据区
数据区开头为数据库编号、数据库中键个数、有 TTL 的键个数,接下来为若干键值对:
65c0 00fe 00fb 0101 fcd3 569a a380 0100 e.........V.....
0000 0568 656c 6c6f 0577 6f72 6c64 ff10 ...hello.world..
d4ea 6453 5f49 3d0a ..dS_I=.
注意示例中的 fe 00fb 0701,0xFE 为 RDB_OPCODE_SELECTDB 表示接下来一个字节 0x00 是数据库编号。
0xFB 为 RDB_OPCODE_RESIZEDB 表示接下来两个长度编码(Length Encode): 0x01、0x01 分别为哈希表中键的数量和有 TTL 的键的数量。
在数据库开头部分就给出键的数量可以在加载 RDB 时提前准备好合适大小的哈希表,避免耗时费力的 ReHash 操作。
具体的键值对编码格式为: [RDB_OPCODE_EXPIRETIME expire_timestamp] type_code key object, 举例来说:
65c0 00fe 00fb 0101 fcd3 569a a380 0100 e.........V.....
0000 0568 656c 6c6f 0577 6f72 6c64 ff10 ...hello.world..
d4ea 6453 5f49 3d0a ..dS_I=.
0xFC 为 RDB_OPCODE_EXPIRETIME_MS 随后为一个 小端序的 uint64 表示 key 的过期时间(毫秒为单位的 unix 时间戳),这里过期时间的二进制串 d3569aa380010000 转换为整型是 1652012242643 即 2022-05-08 20:17:22。
小端序二进制转整型代码:binary.LittleEndian.Uint64([]byte{0xd3, 0x56, 0x9a, 0xa3, 0x80, 0x01, 0x00, 0x00})
后面的 0x00 是 RDB_TYPE_STRING, 一种 redis 数据类型可能有多个 type_code ,比如 list 数据结构可以使用的编码类型有:RDB_TYPE_LIST、RDB_TYPE_LIST_ZIPLIST、RDB_TYPE_LIST_QUICKLIST 等。
接下来的 0568 656c 6c6f 是字符串 “hello” 的编码, 0577 6f72 6c64 是字符串 “world” 的编码。
后面的 0xff 是 RDB_OPCODE_EOF 表示 RDB 文件结尾,剩下的部分是 RDB 的 CRC64 校验码。
RDB 中的各种编码
在上文中我们已经提到了长度编码、字符串编码等概念,接下来我们可以具体看一下 RDB 中怎么编码不同类型的对象的。
LengthEncoding
Length Encoding 是一种可变长度的无符号整型编码,因为通常被用来存储字符串长度、列表长度等长度数据所以被称为 Length Encoding.
- 如果前两位是 00 那么下面剩下的 6 位就表示具体长度
- 如果前两位是 01 那么会再读取一个字节的数据,加上前面剩下的6位,共14位用于表示具体长度
- 如果前两位是 10 如果剩下的 6 位都是 0 那么后面 32 个字节表示具体长度。如果剩下的 6 位为 000001, 那么后面的 64 个字节表示具体长度。(注意有些较老的文章没有提及 64 位的 Length Encoding)
- 如果前两位是 11 表示为使用字符串存储整数的特殊编码,我们在接下来的 String Encoding 部分来介绍。为了方便,下文中我们将 11 开头的Length Encoding 称为「特殊长度编码」,其它 3 种称为 「普通长度编码」。
采用变长编码可以显著的节约空间,0~63 只需要一个字节,64 ~ 16383 只需要两个字节。考虑到 Redis 中大多数数据结构的长度并不长,Length Ecnoding 的节约效果更加显著。
贴一下解析 Length Encoding 的源码readLength
func (dec *Decoder) readLength() (uint64, bool, error) {
firstByte, err := dec.readByte() // 先读一个字节
if err != nil {
return 0, false, fmt.Errorf("read length failed: %v", err)
}
lenType := (firstByte & 0xc0) >> 6 // 取前两位
var length uint64
special := false
switch lenType {
case len6Bit: /
length = uint64(firstByte) & 0x3f // 前两位是 00,读剩余 6 位
case len14Bit:
nextByte, err := dec.readByte()
if err != nil {
return 0, false, fmt.Errorf("read len14Bit failed: %v", err)
}
// 前两位是01,读第一个字节剩余 6 位作为整数高位,读第二个字节做整数低位
length = (uint64(firstByte)&0x3f)<
StringEncoding
RDB 的 StringEncoding 可以分为三种类型:
- 简单字符串编码
- 整数字符串
- LZF 压缩字符串
StringEncode 总是以 LengthEncoding 开头, 普通字符串编码由普通长度编码 + 字符串的 ASCII 序列组成, 整数字符串和 LZF 压缩字符串则以特殊长度编码开头。
上文中提到的 0568 656c 6c6f 就是简单字符串编码,它的第一个字节 0x05 是前两位为 00 的长度编码,表示字符串长度为 5 个字节,接下来的 5 个字节 0x68656c6c6f则是 “hello” 对应的 ASCII 序列。
若字符串开头为特殊长度编码(即第一个字节前两位为 11),则第一个字节剩下的 6 位会表示具体编码方式。我们直接贴代码: readString:
func (dec *Decoder) readString() ([]byte, error) {
length, special, err := dec.readLength()
if err != nil {
return nil, err
}
if special { // 前两位为 11 时 special = true
switch length { // 此时的 length 为第一个字节的后 6 位
case encodeInt8: // 第一个字节为 0xc0
// 第一个字节后 6 位为 000000,表示下一个字节为补码表示的整数
// 读取下一个字节并使用 Itoa 转换为字符串
b, err := dec.readByte() // readByte 其实就是 readInt8
return []byte(strconv.Itoa(int(b))), err
case encodeInt16:// 第一个字节为 0xc1
// 与 encodeInt8 类似,区别在于长度为接下来的两位
b, err := dec.readUint16() // 将 uint 转换为 int 过程实际上是把同一个二进制序列改为用补码来解释
return []byte(strconv.Itoa(int(b))), err
case encodeInt32: // // 第一个字节为 0xc2
b, err := dec.readUint32()
return []byte(strconv.Itoa(int(b))), err
case encodeLZF: // 第一个字节为 0xc3
// 读取 LZF 压缩字符串
return dec.readLZF()
default:
return []byte{}, errors.New("Unknown string encode type ")
}
}
res := make([]byte, length)
err = dec.readFull(res)
return res, err
}
这里举一个整数字符串的例子: c0fe, 第一个字节 0xc0 表示 encodeInt8 特殊长度编码, 接下来的 8 位 0xfe视作补码处理, 0xfe 转换为整数为 254, 通过 Itoa 输出最终结果:”254″。 使用简单字符串编码表示 “254” 为 03323534 占用 4 个字节比整数字符串多了一倍。
object encoding 命令显示编码类型为 int 的对象的实际存储方式就是整型字符串:
127.0.0.1:6379> set a -1
OK
127.0.0.1:6379> object encoding a
"int"
LZF 字符串由:表示压缩后长度的 Length Encoding + 表示压缩前长度的 Length Encoding + 压缩后的二进制数据 三部分组成,有兴趣的朋友可以阅读readLZF这里不再详细描述。
ListEncoding & SetEncoding & HashEncoding
ListEncoding 开头为一个普通长度编码块表示 List 的长度,随后是对应个数的 StringEncoding 块。具体可以看 readList
SetEncoding 与 ListEncoding 完全相同。具体可以看 readSet
HashEncoding 开头为一个普通长度编码块表示哈希表中的键值对个数,随后为对应个数的:Key StringEncoding + Value StringEncoding 组成的键值对。具体可以看 readHashMap.
ZSetEncoding & ZSet2Encoding
这两种表示有序集合方式非常类似,开头是一个普通长度编码块表示元素数,随后是对应个数的表示score的float值 + 表示 member 的 StringEncode。唯一的区别是,ZSet 的 score 采用字符串来存储浮点数,ZSet2 使用 IEEE 754 规定的二进制格式存储 float.
两种编码格式的处理函数都是 readZSet 通过 zset2 标志来区分。
ZSet2 的 float 值可以直接使用 math.Float64frombits 来读取,ZSet 的 float 字符串是第一个字节表示长度+ ASCII 序列组成,具体实现在readLiteralFloat, 这里不再详细介绍。
IntSetEncoding
当 Set 中的元素全部为整数时,Redis 可能使用 IntSet 编码进行存储。 IntSet 在逻辑上是升序排列的整数列表,它的前 4 字节表示其中整数编码格式,4-8 位表示元素数,其后为对应个数的整数。 接下来我们看一个 IntSet 的示例:
0200 0000 0400 0000 0100 0200 0300 0400
前 4 个字节 0200 0000 是一个小端序的 32 位整数 2, 表示使用 2 个字节表示一个整数,即元素类型为 int16。IntSet 中支持 int16、int32、int64 三种整数编码。
第 4 至 8 字节 0400 0000 是小端序的整数 4 表示 IntSet 中有 4 个元素。
接下来是 4 个小端序表示的整数 0100 0200 0300 0400 即 1、2、3、4。
RDB 文件中不会直接存储上述 IntSet 二进制格式,而是使用 StringEncoding 将其再次编码后存入 RDB 文件。
buf := make([]byte, 8, 8+int(intSize)*len(values))
binary.LittleEndian.PutUint32(buf[0:4], intSize) // 写入 intSize=2 表示使用 2 个字节表示一个整数
binary.LittleEndian.PutUint32(buf[4:8], uint32(len(values))) // 写入元素数
for _, value := range intList {
switch intSize {
case 2:
binary.LittleEndian.PutUint16(enc.buffer[0:2], uint16(value))
buf = append(buf, enc.buffer[0:2]...)
// 省略其它 intSize 的源码
}
}
// buf 中是原始的 int set,需要调用 writeString 将其编码为 StringEncoding 然后写入
err = enc.writeString(string(buf))
解码 IntSet 的函数为 readIntSet, 有兴趣的朋友可自行阅读。
zipList
ziplist 是一种非常紧凑的顺序结构,它将数据和编码信息存储在一段连续空间中。在 RDB 文件中除了 list 结构外,hash、sorted set 结构也会使用 ziplist 编码。由于 ziplist 存在写放大的问题,Redis 通常在数据量较小的时候使用 ziplist。
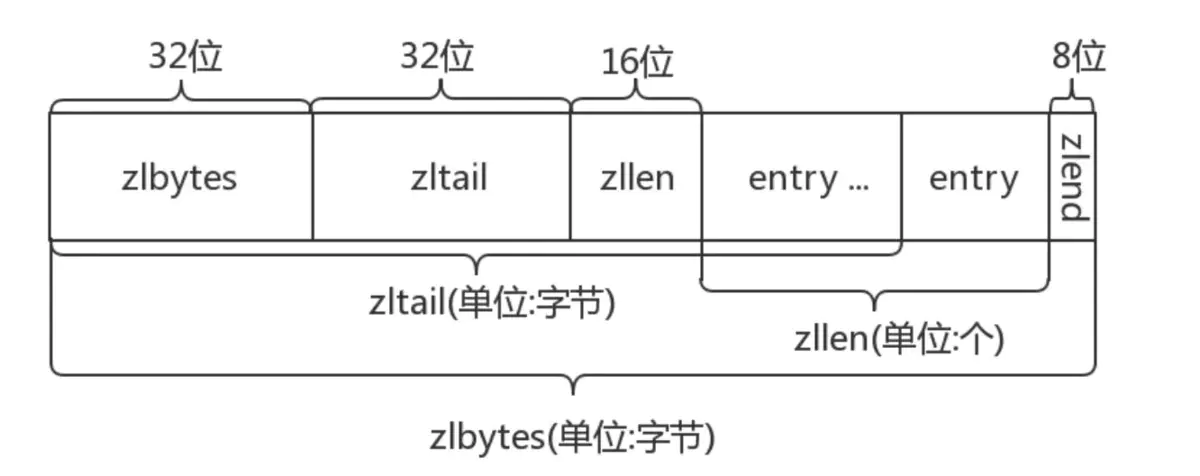
释义:
- zlbytes 是整个 ziplist 所占的字节数,包括自己所占的 4 个字节。
- zltail 表示从 ziplist 开头到最后一个 entry 开头的偏移量,从而可以在 O(1) 时间内访问尾节点
- zllen 表示 ziplist 中 entry 的个数
- entry 是 ziplist 中元素,在下文详细介绍
- zlend 表示 ziplist 的结束,固定为 255(0xff)
接下来我们来研究一下 entry 的编码:
prevlen 表示前一个 entry 的长度,用于从尾节点开始向前遍历.前节点长度小于254时,占用1字节用来表示前节点长度, 前节点长度大于等于254时,占用5字节。其中第1个字节为特殊值0xFE(254),后面4字节用来表示实际长度。
encoding 表示 entry-data 的类型,encoding 的第一个字节的前两位为 11 时表示 entry-data 为整数,其它情况表示 entry-data 为字符串。具体如下表:
encoding encoding字节数 说明 11000000 1 int16 11010000 1 int32 11100000 1 int64 11110000 1 24位有符号整数 11111110 1 int8 1111xxxx 1 xxxx 取值范围 [0001, 1101],用 encoding 剩余的 4 位表示整数 00xxxxxx 1 长度不超过 63 的字符串,encoding 剩下的 6 位存储字符串长度 01xxxxxx 2 长度不超过 16383 (2^14-1) 的字符串,用 encoding 第一个字符剩下的 6 位和第二个字符表示字符串长度(采用大端序) 10000000 5 长度不超过 2^32-1 的字符串,用接下来的 4 个字节表示字符串长度(大端序)
1111xxxx 用于表示范围在 [0, 12] 内的整数。它的低 4 位取值 0000 或 1111 会与 int24 encoding 或者 zlend 发生冲突,所以低 4 位只能在 [0001, 1101] 内取值。小整数会先加 1 然后再存入 encoding 的低 4 位中,比如整数 0 实际上存储为 0001、1 实际存储为 0010、 12 存储为 1101。
if header>>4 == zipInt04B { // encoding 为 1111xxxx
result = []byte(strconv.FormatInt(int64(header&0x0f)-1, 10)) // (header&0x0f) 取低 4 位,再 -1 才是实际的数字
return
}
那么 redis 会在何时使用 ziplist 呢?
- list: 字节数
list 还有还有一种编码方式 RDB_TYPE_LIST_QUICKLIST, 它的开头是一个 LengthEncoding 随后是对应数量的 ziplist, 它的详细实现在readQuickList:
func (dec *Decoder) readQuickList() ([][]byte, error) {
size, _, err := dec.readLength()
if err != nil {
return nil, err
}
entries := make([][]byte, 0)
for i := 0; i < int(size); i++ {
page, err := dec.readZipList()
if err != nil {
return nil, err
}
entries = append(entries, page...)
}
return entries, nil
}
与 IntSet 一样,ZipList 编码也需要使用 StringEncoding 将其再次编码后才会写入 RDB 文件。
hash 还有一种 RDB_TYPE_HASH_ZIPMAP 编码方式,它与 ziplist 类似,同样用于编码较小的结构。zipmap 在 Redis 2.6 之后就已被弃用,这里我们就不详细讲解了,可以参考readZipMapHash
更多关于 Redis 编码的内容可以阅读 Redis 内存压缩原理
Original: https://www.cnblogs.com/Finley/p/16251360.html
Author: -Finley-
Title: Golang 实现 Redis(11): RDB 文件格式
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/529380/
转载文章受原作者版权保护。转载请注明原作者出处!