

源码来源
重要参考
抽取示例
- 示例文本
记者从云南北移亚洲象群安全防范工作省级指挥部了解到, 象群于6月17日21时48分进入玉溪市峨山彝族自治县辖区,向西偏北方向迁移13.5公里,在峨山县大龙潭乡附近活动。 独象离群13天,于6月17日22时7分进入安宁市辖区,位于象群正东方向,与象群直线距离24.7公里,在安宁市八街街道附近活动。 15头北移亚洲象均在监测范围内,人象平安。
- 方法1:基于ltp依存句法分析和语义角色标注的事件三元组抽取结果
[[‘记者’, ‘了解’, ‘象群进入玉溪市峨山彝族自治县辖区’],
[‘象群’, ‘进入’, ‘玉溪市峨山彝族自治县辖区’],
[‘西’, ‘偏’, ‘北’],
[‘独象’, ‘进入’, ‘安宁市辖区’]]
-
方法2:基于百度DDParser依存句法分析的事件三元组抽取结果
-
方法3:基于词性模板规则的事件三元组抽取结果
(‘记者从云南北移亚洲象群安全’, ‘防范工作’, ‘指挥部了解到’)
(‘象群于6月17日21时48’, ‘分进入’, ‘玉溪市峨山彝族自治县辖区’)
(‘向西偏向’, ‘迁移’, ‘13.5公里’)
(‘于6月17日22时7’, ‘分进入’, ‘安宁市辖区’)
(’15头北’, ‘移’, ‘亚洲象在监测范围内’)
(‘亚洲象’, ‘在监测’, ‘范围内’)
coding=utf-8
import re, os
import jieba.posseg as pseg
class ExtractEvent:
def __init__(self):
self.map_dict = self.load_mapdict()
self.minlen = 2
self.maxlen = 300
self.keywords_num = 20
self.limit_score = 10
self.IP = "(([NERMQ]*P*[ABDP]*)*([ABDV]{1,})*([NERMQ]*)*([VDAB]$)?([NERMQ]*)*([VDAB]$)?)*"
self.IP = "([NER]*([PMBQADP]*[NER]*)*([VPDA]{1,}[NEBRVMQDA]*)*)"
self.MQ = '[DP]*M{1,}[Q]*([VN]$)?'
self.VNP = 'V*N{1,}'
self.NP = '[NER]{1,}'
self.REN = 'R{2,}'
self.VP = 'P?(V|A$|D$){1,}'
self.PP = 'P?[NERMQ]{1,}'
self.SPO_n = "n{1,}"
self.SPO_v = "v{1,}"
self.stop_tags = {'u', 'wp', 'o', 'y', 'w', 'f', 'u', 'c', 'uj', 'nd', 't', 'x'}
self.combine_words = {"首先", "然后", "之前", "之后", "其次", "接着"}
"""构建映射字典"""
def load_mapdict(self):
tag_dict = {
'B': 'b'.split(), # 时间词
'A': 'a d'.split(), # 时间词
'D': "d".split(), # 限定词
'N': "n j s zg en l r".split(), #名词
"E": "nt nz ns an ng".split(), #实体词
"R": "nr".split(), #人物
'G': "g".split(), #语素
'V': "vd v va i vg vn g".split(), #动词
'P': "p f".split(), #介词
"M": "m t".split(), #数词
"Q": "q".split(), #量词
"v": "V".split(), #动词短语
"n": "N".split(), #名词介宾短语
}
map_dict = {}
for flag, tags in tag_dict.items():
for tag in tags:
map_dict[tag] = flag
return map_dict
"""根据定义的标签,对词性进行标签化"""
def transfer_tags(self, postags):
tags = [self.map_dict.get(tag[:2], 'W') for tag in postags]
return ''.join(tags)
"""抽取出指定长度的ngram"""
def extract_ngram(self, pos_seq, regex):
ss = self.transfer_tags(pos_seq)
def gen():
for s in range(len(ss)):
for n in range(self.minlen, 1 + min(self.maxlen, len(ss) - s)):
e = s + n
substr = ss[s:e]
if re.match(regex + "$", substr):
yield (s, e)
return list(gen())
'''抽取ngram'''
def extract_sentgram(self, pos_seq, regex):
ss = self.transfer_tags(pos_seq)
def gen():
for m in re.finditer(regex, ss):
yield (m.start(), m.end())
return list(gen())
"""指示代词替换,消解处理"""
def cite_resolution(self, words, postags, persons):
if not persons and 'r' not in set(postags):
return words, postags
elif persons and 'r' in set(postags):
cite_index = postags.index('r')
if words[cite_index] in {"其", "他", "她", "我"}:
words[cite_index] = persons[-1]
postags[cite_index] = 'nr'
elif 'r' in set(postags):
cite_index = postags.index('r')
if words[cite_index] in {"为何", "何", "如何"}:
postags[cite_index] = 'w'
return words, postags
"""抽取量词性短语"""
def extract_mqs(self, wds, postags):
phrase_tokspans = self.extract_sentgram(postags, self.MQ)
if not phrase_tokspans:
return []
phrases = [''.join(wds[i[0]:i[1]])for i in phrase_tokspans]
return phrases
'''抽取动词性短语'''
def get_ips(self, wds, postags):
ips = []
phrase_tokspans = self.extract_sentgram(postags, self.IP)
if not phrase_tokspans:
return []
phrases = [''.join(wds[i[0]:i[1]])for i in phrase_tokspans]
phrase_postags = [''.join(postags[i[0]:i[1]]) for i in phrase_tokspans]
for phrase, phrase_postag_ in zip(phrases, phrase_postags):
if not phrase:
continue
phrase_postags = ''.join(phrase_postag_).replace('m', '').replace('q','').replace('a', '').replace('t', '')
if phrase_postags.startswith('n') or phrase_postags.startswith('j'):
has_subj = 1
else:
has_subj = 0
ips.append((has_subj, phrase))
return ips
"""分短句处理"""
def split_short_sents(self, text):
return [i for i in re.split(r'[,,]', text) if len(i)>2]
"""分段落"""
def split_paras(self, text):
return [i for i in re.split(r'[\n\r]', text) if len(i) > 4]
"""分长句处理"""
def split_long_sents(self, text):
return [i for i in re.split(r'[;。:; :??!!【】▲丨|]', text) if len(i) > 4]
"""移出噪声数据"""
def remove_punc(self, text):
text = str(text).replace('\u3000', '').replace("'", '').replace('"', '').replace('"', '').replace('▲','').replace('" ', """)
tmps = re.findall('[\(|(][^\((\))]*[\)|)]', text)
for tmp in tmps:
text = text.replace(tmp, '')
return text
"""保持专有名词"""
def zhuanming(self, text):
books = re.findall('[]', text)
return books
"""对人物类词语进行修正"""
def modify_nr(self, wds, postags):
phrase_tokspans = self.extract_sentgram(postags, self.REN)
wds_seq = ' '.join(wds)
pos_seq = ' '.join(postags)
if not phrase_tokspans:
return wds, postags
else:
wd_phrases = [' '.join(wds[i[0]:i[1]]) for i in phrase_tokspans]
postag_phrases = [' '.join(postags[i[0]:i[1]]) for i in phrase_tokspans]
for wd_phrase in wd_phrases:
tmp = wd_phrase.replace(' ', '')
wds_seq = wds_seq.replace(wd_phrase, tmp)
for postag_phrase in postag_phrases:
pos_seq = pos_seq.replace(postag_phrase, 'nr')
words = [i for i in wds_seq.split(' ') if i]
postags = [i for i in pos_seq.split(' ') if i]
return words, postags
"""对人物类词语进行修正"""
def modify_duplicate(self, wds, postags, regex, tag):
phrase_tokspans = self.extract_sentgram(postags, regex)
wds_seq = ' '.join(wds)
pos_seq = ' '.join(postags)
if not phrase_tokspans:
return wds, postags
else:
wd_phrases = [' '.join(wds[i[0]:i[1]]) for i in phrase_tokspans]
postag_phrases = [' '.join(postags[i[0]:i[1]]) for i in phrase_tokspans]
for wd_phrase in wd_phrases:
tmp = wd_phrase.replace(' ', '')
wds_seq = wds_seq.replace(wd_phrase, tmp)
for postag_phrase in postag_phrases:
pos_seq = pos_seq.replace(postag_phrase, tag)
words = [i for i in wds_seq.split(' ') if i]
postags = [i for i in pos_seq.split(' ') if i]
return words, postags
'''对句子进行分词处理'''
def cut_wds(self, sent):
wds = list(pseg.cut(sent))
postags = [w.flag for w in wds]
words = [w.word for w in wds]
return self.modify_nr(words, postags)
"""移除噪声词语"""
def clean_wds(self, words, postags):
wds = []
poss =[]
for wd, postag in zip(words, postags):
if postag[0].lower() in self.stop_tags:
continue
wds.append(wd)
poss.append(postag[:2])
return wds, poss
"""检测是否成立, 肯定需要包括名词"""
def check_flag(self, postags):
if not {"v", 'a', 'i'}.intersection(postags):
return 0
return 1
"""识别出人名实体"""
def detect_person(self, words, postags):
persons = []
for wd, postag in zip(words, postags):
if postag == 'nr':
persons.append(wd)
return persons
"""识别出名词性短语"""
def get_nps(self, wds, postags):
phrase_tokspans = self.extract_sentgram(postags, self.NP)
if not phrase_tokspans:
return [],[]
phrases_np = [''.join(wds[i[0]:i[1]]) for i in phrase_tokspans]
return phrase_tokspans, phrases_np
"""识别出介宾短语"""
def get_pps(self, wds, postags):
phrase_tokspans = self.extract_sentgram(postags, self.PP)
if not phrase_tokspans:
return [],[]
phrases_pp = [''.join(wds[i[0]:i[1]]) for i in phrase_tokspans]
return phrase_tokspans, phrases_pp
"""识别出动词短语"""
def get_vps(self, wds, postags):
phrase_tokspans = self.extract_sentgram(postags, self.VP)
if not phrase_tokspans:
return [],[]
phrases_vp = [''.join(wds[i[0]:i[1]]) for i in phrase_tokspans]
return phrase_tokspans, phrases_vp
"""抽取名动词性短语"""
def get_vnps(self, s):
wds, postags = self.cut_wds(s)
if not postags:
return [], []
if not (postags[-1].endswith("n") or postags[-1].endswith("l") or postags[-1].endswith("i")):
return [], []
phrase_tokspans = self.extract_sentgram(postags, self.VNP)
if not phrase_tokspans:
return [], []
phrases_vnp = [''.join(wds[i[0]:i[1]]) for i in phrase_tokspans]
phrase_tokspans2 = self.extract_sentgram(postags, self.NP)
if not phrase_tokspans2:
return [], []
phrases_np = [''.join(wds[i[0]:i[1]]) for i in phrase_tokspans2]
return phrases_vnp, phrases_np
"""提取短语"""
def phrase_ip(self, content):
spos = []
events = []
content = self.remove_punc(content)
paras = self.split_paras(content)
for para in paras:
long_sents = self.split_long_sents(para)
for long_sent in long_sents:
persons = []
short_sents = self.split_short_sents(long_sent)
for sent in short_sents:
words, postags = self.cut_wds(sent)
person = self.detect_person(words, postags)
words, postags = self.cite_resolution(words, postags, persons)
words, postags = self.clean_wds(words, postags)
#print(words,postags)
ips = self.get_ips(words, postags)
persons += person
for ip in ips:
events.append(ip[1])
wds_tmp = []
postags_tmp = []
words, postags = self.cut_wds(ip[1])
verb_tokspans, verbs = self.get_vps(words, postags)
pp_tokspans, pps = self.get_pps(words, postags)
tmp_dict = {str(verb[0]) + str(verb[1]): ['V', verbs[idx]] for idx, verb in enumerate(verb_tokspans)}
pp_dict = {str(pp[0]) + str(pp[1]): ['N', pps[idx]] for idx, pp in enumerate(pp_tokspans)}
tmp_dict.update(pp_dict)
sort_keys = sorted([int(i) for i in tmp_dict.keys()])
print('sort_keys:',sort_keys)
for i in sort_keys:
if i < 10:
i = '0' + str(i)
else:
i = str(i)
wds_tmp.append(tmp_dict[str(i)][-1])
print('tmp_dict[str(i)][-1]):',tmp_dict[str(i)][-1])
postags_tmp.append(tmp_dict[str(i)][0])
wds_tmp, postags_tmp = self.modify_duplicate(wds_tmp, postags_tmp, self.SPO_v, 'V')
wds_tmp, postags_tmp = self.modify_duplicate(wds_tmp, postags_tmp, self.SPO_n, 'N')
if len(postags_tmp) < 2:
continue
seg_index = []
i = 0
for wd, postag in zip(wds_tmp, postags_tmp):
if postag == 'V':
seg_index.append(i)
i += 1
spo = []
for indx, seg_indx in enumerate(seg_index):
if indx == 0:
pre_indx = 0
else:
pre_indx = seg_index[indx-1]
if pre_indx < 0:
pre_indx = 0
if seg_indx == 0:
spo.append(('', wds_tmp[seg_indx], ''.join(wds_tmp[seg_indx+1:])))
elif seg_indx > 0 and indx < 1:
spo.append((''.join(wds_tmp[:seg_indx]), wds_tmp[seg_indx], ''.join(wds_tmp[seg_indx + 1:])))
else:
spo.append((''.join(wds_tmp[pre_indx+1:seg_indx]), wds_tmp[seg_indx], ''.join(wds_tmp[seg_indx + 1:])))
spos += spo
return events, spos
import time
handler = ExtractEvent()
start = time.time()
r = open("......\数据\部分result.txt", 'w')
with open("......\数据\部分.txt", 'r', encoding='utf-8') as tt:
content1 = tt.readlines()
events, spos = handler.phrase_ip(content1)
spos = [i for i in spos if i[0] and i[2]]
for spo in spos:
r.write(str(spo))
#print(spo)
- 源码二:针对火灾事件提取(代码路径:……代码\Event-Extraction-master\Event-Extraction-master\ML\EventExtractionTemplateMatch) *event_extraction.py
原作者: luohuagang
针对火灾事件抽取
import re
import settings
from stanfordcorenlp import StanfordCoreNLP
class EventExtraction:
def __init__(self, context):
# 初始化事件字典,包含触发词,事件类型
# 时间,地点,救援组织,事故原因,事故损失
self.event = {}
# 使用stanfordnlp工具分析事件
import logging # 查看运行日志
nlp = StanfordCoreNLP(r"D:\Web_download\stanford-corenlp-full-2018-01-31\stanford-corenlp-full-2018-01-31",
lang='zh', quiet=False, logging_level=logging.DEBUG)
nlp_result = nlp.ner(context)
self.having_event(nlp_result)
if self.event['events'] == '火灾':
# 提取时间、地点、救援组织
self.event['time'] = ",".join(self.taking_time(nlp_result))
self.event['location'] = self.taking_location(nlp_result)
self.event['organization'] = self.taking_organization(nlp_result)
# 定义事故原因模板
self.cause_patterns = self.pattern_cause()
# 定义事故损失模板
self.lose_patterns = self.pattern_lose()
# 匹配事故原因和事故损失
self.pattern_match(context)
self.event['cause'] = "".join(self.cause)
self.event['lose'] = self.lose
else:
self.event['trigger'] = None
self.event['events'] = None
nlp.close()
def having_event(self, nlp_result):
for item in nlp_result:
if item[1] == 'CAUSE_OF_DEATH':
if item[0] in settings.trigger_fire:
self.event['trigger'] = item[0]
self.event['events'] = '火灾'
def taking_time(self, nlp_result):
i = 0
state = False
only_date = False
time_fire = ""
result = []
while i < len(nlp_result):
if nlp_result[i][1] == 'DATE':
time_fire += nlp_result[i][0]
if state == False:
state = True
only_date = True
else:
if state == True:
if (nlp_result[i][1] == 'TIME'
or nlp_result[i][1] == 'NUMBER'
or nlp_result[i][1] == 'MISC'):
time_fire += nlp_result[i][0]
only_date = False
else:
if only_date == False:
result.append(time_fire)
time_fire = ""
state = False
i += 1
if state == True:
result.append(time_fire)
result = list(set(result))
return result
def taking_location(self, nlp_result):
i = 0
state = False
location = ""
result = []
while i < len(nlp_result):
if (nlp_result[i][1] == 'LOCATION' or
nlp_result[i][1] == 'FACILITY' or
nlp_result[i][1] == 'CITY'):
location += nlp_result[i][0]
if state == False:
state = True
else:
if state == True:
result.append(location)
location = ""
state = False
i += 1
if state == True:
result.append(location)
result = list(set(result))
return result
def taking_organization(self, nlp_result):
i = 0
state = False
organization = ""
result = []
while i < len(nlp_result):
if nlp_result[i][1] == 'ORGANIZATION':
organization += nlp_result[i][0]
if state == False:
state = True
else:
if state == True:
result.append(organization)
organization = ""
state = False
i += 1
if state == True:
result.append(organization)
result = list(set(result))
return result
def pattern_cause(self):
patterns = []
key_words = ['起火', '事故', '火灾']
pattern = re.compile('.*?(?:{0})原因(.*?)[,.?:;!,。?:;!]'.format('|'.join(key_words)))
patterns.append(pattern)
return patterns
def pattern_lose(self):
patterns = []
key_words = ['伤亡', '损失']
pattern = re.compile('.*?(未造成.*?(?:{0}))[,.?:;!,。?:;]'.format('|'.join(key_words)))
patterns.append(pattern)
patterns.append(re.compile('(\d+人死亡)'))
patterns.append(re.compile('(\d+人身亡)'))
patterns.append(re.compile('(\d+人受伤)'))
patterns.append(re.compile('(\d+人烧伤)'))
patterns.append(re.compile('(\d+人坠楼身亡)'))
patterns.append(re.compile('(\d+人遇难)'))
return patterns
def pattern_match(self, news):
self.cause = []
self.lose = []
for pattern in self.cause_patterns:
match_list = re.findall(pattern, news)
if match_list:
self.cause.append(match_list[0])
for pattern in self.lose_patterns:
match_list = re.findall(pattern, news)
if match_list:
self.lose.append(match_list[0])
with open("......\数据\\火灾.txt", 'r',encoding='utf-8') as f:
test_data = f.readlines()
news = str(test_data)
print(news)
events = EventExtraction(news)
print(events.event)
with open('......\数据\\火灾result.txt', 'a') as f:
# f.write(news) 写入原文
f.write(str(events.event))
f.write('\n')
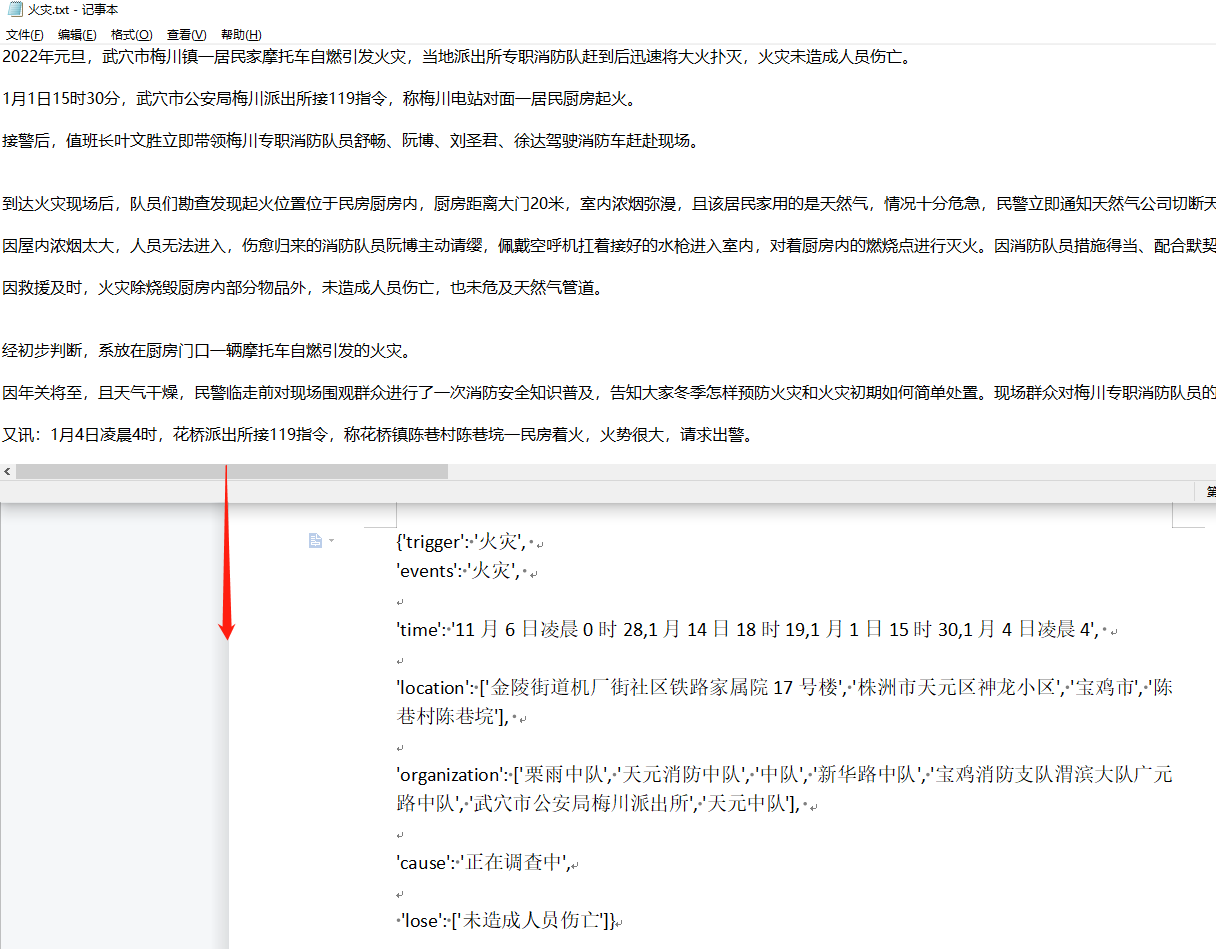

示例结果
- *源码二修改后:针对大象事件提取(event_extraction.py)
针对大象事件抽取
import time
import re
import settings
from stanfordcorenlp import StanfordCoreNLP
import logging # 查看运行日志
nlp = StanfordCoreNLP(r"D:\Web_download\stanford-corenlp-full-2018-01-31\stanford-corenlp-full-2018-01-31",
lang='zh', quiet=False, logging_level=logging.DEBUG)
class EventExtraction:
def __init__(self, context):
# 初始化事件字典,包含触发词,事件类型
# 时间,地点,组织,原因,损失
self.event = {}
nlp_result = nlp.ner(context)
print('nlp_result: ',nlp_result)
self.having_event(nlp_result)
print('self.having_event(nlp_result): ',self.having_event(nlp_result))
#if self.event['events'] == '大象':
if self.event['events'] in settings.trigger_fire:
# 提取时间、地点、组织
self.event['time'] = ",".join(self.taking_time(nlp_result))
self.event['location'] = self.taking_location(nlp_result)
self.event['organization'] = self.taking_organization(nlp_result)
# 定义原因模板
self.cause_patterns = self.pattern_cause()
# 定义损失模板
self.lose_patterns = self.pattern_lose()
# 匹配原因和损失
self.pattern_match(context)
self.event['cause'] = "".join(self.cause)
self.event['lose'] = self.lose
else:
self.event['trigger'] = None
self.event['events'] = None
nlp.close()
def having_event(self, nlp_result):
for item in nlp_result:
#if item[1] == 'CAUSE_OF_DEATH':
if item[0] in settings.trigger_fire:
self.event['trigger'] = item[0]
self.event['events'] = item[0]
def taking_time(self, nlp_result):
i = 0
state = False
only_date = False
time_fire = ""
result = []
while i < len(nlp_result):
if nlp_result[i][1] == 'DATE':
time_fire += nlp_result[i][0]
if state == False:
state = True
only_date = True
else:
if state == True:
if (nlp_result[i][1] == 'TIME'
or nlp_result[i][1] == 'NUMBER'
or nlp_result[i][1] == 'MISC'):
time_fire += nlp_result[i][0]
only_date = False
else:
if only_date == False:
result.append(time_fire)
time_fire = ""
state = False
i += 1
if state == True:
result.append(time_fire)
result = list(set(result))
return result
def taking_location(self, nlp_result):
i = 0
state = False
location = ""
result = []
while i < len(nlp_result):
if (nlp_result[i][1] == 'LOCATION' or
nlp_result[i][1] == 'FACILITY' or
nlp_result[i][1] == 'CITY'):
location += nlp_result[i][0]
if state == False:
state = True
else:
if state == True:
result.append(location)
location = ""
state = False
i += 1
if state == True:
result.append(location)
result = list(set(result))
return result
def taking_organization(self, nlp_result):
i = 0
state = False
organization = ""
result = []
while i < len(nlp_result):
if nlp_result[i][1] == 'ORGANIZATION':
organization += nlp_result[i][0]
if state == False:
state = True
else:
if state == True:
result.append(organization)
organization = ""
state = False
i += 1
if state == True:
result.append(organization)
result = list(set(result))
return result
#原因模板
def pattern_cause(self):
patterns = []
key_words = ['迁徙', '数量', '食物','栖息地','北','扩散','走']
pattern = re.compile('.*?(?:{0})原因(.*?)[,.?:;!,。?:;!]'.format('|'.join(key_words)))
patterns.append(pattern)
return patterns
# 损失模板
def pattern_lose(self):
patterns = []
key_words = ['伤亡', '损失','破坏','死亡']
pattern = re.compile('.*?(造成.*?(?:{0}))[,.?:;!,。?:;]'.format('|'.join(key_words)))
patterns.append(pattern)
'''
patterns.append(re.compile('(\d+人死亡)'))
patterns.append(re.compile('(\d+人身亡)'))
patterns.append(re.compile('(\d+人受伤)'))
patterns.append(re.compile('(\d+人遇难)'))
'''
return patterns
def pattern_match(self, news):
self.cause = []
self.lose = []
for pattern in self.cause_patterns:
match_list = re.findall(pattern, news)
if match_list:
self.cause.append(match_list[0])
for pattern in self.lose_patterns:
match_list = re.findall(pattern, news)
if match_list:
self.lose.append(match_list[0])
with open("......\数据\\野象.txt", 'r', encoding='utf-8') as f:
test_data = f.readlines()
news = str(test_data)
print(news)
events = EventExtraction(news)
print(events.event)
with open('......\数据\\野象result.txt', 'a') as f:
f.write(news)
f.write(str(events.event))
f.write('\n')
Original: https://blog.csdn.net/YWP_2016/article/details/122298085
Author: YWP_2016
Title: 【NLP_事件抽取】基于模板匹配
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528156/
转载文章受原作者版权保护。转载请注明原作者出处!