

关注公众号,发现CV技术之美
本文分享论文 『Multi-Modality Cross Attention Network for Image and Sentence Matching』 ,由中科大&快手联合提出多模态交叉注意力,《MMCA》,促进图像-文本多模态匹配!
详细信息如下:


- 论文链接:https://openaccess.thecvf.com/content_CVPR_2020/papers/Wei_Multi-Modality_Cross_Attention_Network_for_Image_and_Sentence_Matching_CVPR_2020_paper.pdf
- 项目链接:未开源
导言:

图像和句子匹配的关键是准确测量图像和句子之间的视觉语义相似性。但是,大多数现有方法仅利用每个模态的模态内关系或图像区域与句子词之间的模态间关系来进行跨模态匹配任务。
与他们不同的是,在这项工作中,作者通过在统一的深度模型中联合建模图像区域和句子单词的模态内和模态间关系,提出了一种新的图像和句子匹配的多模态交叉注意 (MMCA) 网络 。
在提出的MMCA中,作者设计了一种交叉注意机制,该机制不仅能够利用每个模态的模态内关系,而且能够利用图像区域与句子单词之间的模态间关系,以相互补充和增强图像和句子的匹配。在包括Flickr30K和ms-coco在内的两个标准基准上进行的广泛实验结果表明,所提出的模型在图像-句子匹配模型中达到了SOTA的性能。
01
Motivation
图像和句子匹配是视觉和语言领域的基本任务之一。这种跨模态匹配任务的目标是如何准确地测量图像和句子之间的视觉语义相似性,并且与许多视觉语言任务有关,包括图像-句子跨模态检索,视觉字幕,视觉grounding和视觉问答。这项任务引起了极大的关注,并被广泛应用于各种应用,例如,通过图像查询查找类似的句子以进行图像标注,通过句子查询检索匹配的图像以进行图像搜索。尽管近年来取得了重大进展,但它仍然是一个具有挑战性的问题,因为它需要理解语言语义、视觉内容以及跨模态关系和对齐。
由于视觉和语言之间存在巨大的视觉语义差异,匹配图像和句子仍然远未解决。最近,针对这一问题提出了各种方法,可分为两类,包括一对一匹配 和多对多匹配 。一对一匹配方法通常提取图像和句子的全局表示,然后利用视觉语义嵌入将它们关联起来。以往的大多数方法将图像和句子独立地嵌入到同一嵌入空间中,然后通过联合空间中的特征距离来衡量它们的相似性。在深度学习取得成功的推动下,主流的深度特征学习已转向模态特定的特征学习,如用CNN学习图像特征;用RNN学习句子特征。
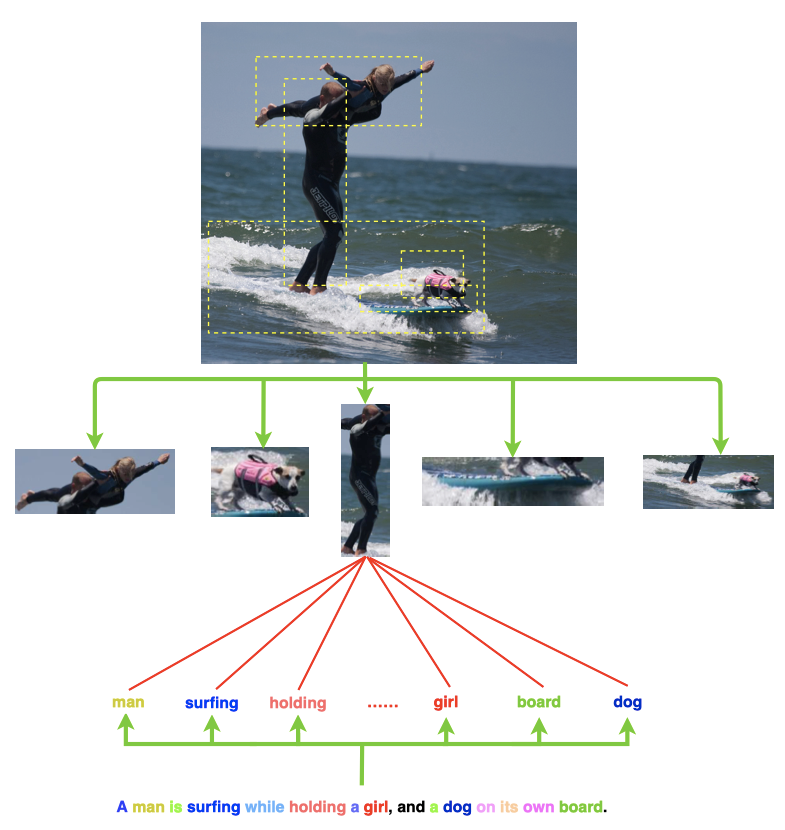
对于视觉内容理解,已经开发了几个深层主干模型,包括VGG、ResNet、GoogleNet,并在大型视觉数据集上证明了它们的有效性。在语言理解方面,已经提出了几种方法,用于构建具有大规模上下文化语言模型预训练的通用主干模型,从而显著提高了各种任务的性能。
对于跨模态关联,最简单的方法是学习投影函数,将视觉和文本数据映射到相同的嵌入空间。然而,这种独立的嵌入方法忽略了这样一个事实,即全局相似性通常来自图像-句子片段之间的局部相似性的复杂交互 。因此,现有的大多数方法可能会导致图像句子匹配的次优特征。
为了解决上述问题,已经提出了多对多匹配方法,以考虑图像区域与句子单词之间的关系。大多数现有方法比较许多对图像区域和句子单词,并汇总它们的局部相似性。通常,结合图像区域和句子单词之间的关系可以在捕获用于图像和句子匹配的细粒度交叉模态提示方面有所帮助。
为了实现这一目标,已经提出了各种方法,这些方法可以大致分为两类,包括基于模态间的方法 和基于模态内的方法 。基于模态间的方法主要侧重于发现图像区域与句子单词之间可能的关系,这些方法在考虑区域与单词之间的相互作用方面取得了很大进展。
如上图所示,如果单词”man”与图像中的相应区域共享模态间信息,则更容易捕获这两个异构数据之间的相关性。然而,现有的方法大多忽略了视觉元素或语言元素之间的联系。基于模态内的方法强调图像区域或句子词的每个模态内的关系,这忽略了不同模态之间的模态间关系。
如上图所示,如果单词 “man” 与句子中的单词 “surfing”,”holding”,”girl” 紧密连接,则它将具有更好的表示形式,以帮助获得整个句子的全局特征。基于上述讨论,在解决图像和句子匹配问题的统一框架中,没有联合研究模态间和模态内的关系。如上图所示,每个模态内的模态内关系以及图像区域和句子单词之间的模态间关系可以补充和补充,从而促进图像和句子的匹配。
基于上述讨论,作者提出了一种新的多模态交叉注意网络 ,通过在单一深度模型中联合建模图像区域和句子单词的模态间关系和模态内关系,实现图像和句子匹配。为了实现稳健的交叉模态匹配,作者设计了两个有效的注意模块,包括自注意模块和交叉注意模块,它们在建模模态内和模态间的关系中起着重要作用。
在自注意模块中,作者采用自下而上的模型来提取显着图像区域的特征。同时,作者使用单词token嵌入作为语言元素。然后,独立地将图像区域输入到Transformer单元,并将单词token输入BERT模型,以建模模态内的关系。然后,可以通过聚合这些片段特征来获得全局表示。
在交叉注意模块中,作者堆叠来图像区域和句子单词的表示,然后将它们传递到另一个Transformer单元中,然后是1d-CNN和池化操作,以融合模态间和模态内信息。然后,基于视觉和文本数据的更新特征,我们可以预测输入图像和句子的相似性分数。
02
方法
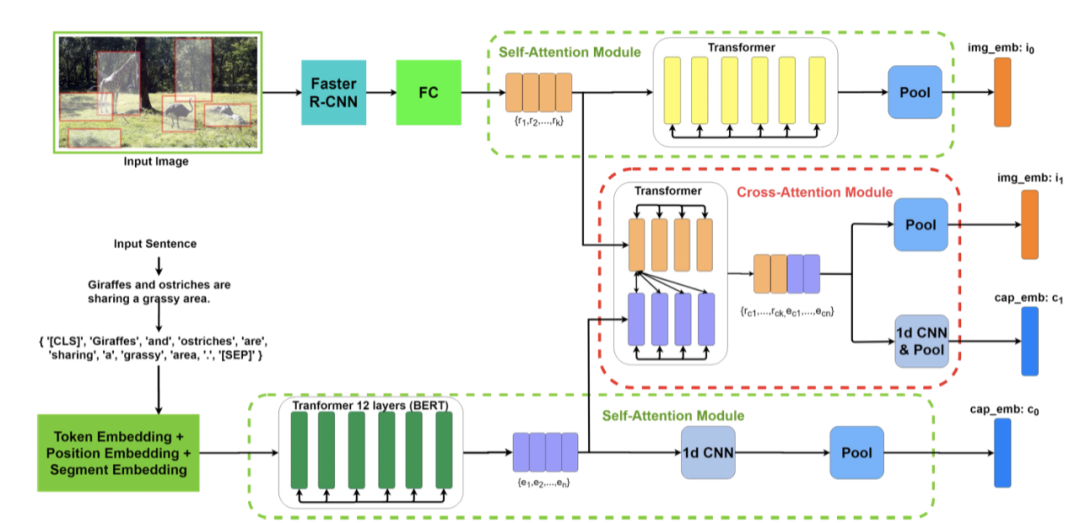
2.1. Overview
如上图所示,本文的多模态交叉注意网络主要由两个模块组成,即自注意模块 和 交叉注意模块,分别在图中的绿色虚线块和红色虚线块中进行了展示。给定一对图像和句子,首先用bottom-up attention模型提取region特征,同时,使用每个句子的WordPiece作为文本模态中的片段。
基于这些提取的图像区域和句子词的粒度表示,使用自注意模块对模态内关系进行建模,并采用交叉注意模块对图像区域和句子词的模态内关系进行建模。通过同时考虑模态内和模态间的关系,可以提高图像和句子片段的特征识别能力。然后使用1d-CNN和池化操作来聚合这些片段表示。
如上图所示,我们得到了给定图像-句子对和的两对嵌入,它们用于图像和句子的匹配。在训练阶段,使用难负例挖掘构造双向triplet loss,以优化模型中的参数。
2.2. Instance Candidate Extraction
Image Instance Candidates
给定图像I,作者使用在Visual Genome上预训练的bottom-up attention模型来提取区域特征。输出是一组区域特征,其中每个被定义为第i个区域的平均池化卷积特征。预训练的模型在训练过程中被固定。并且添加到一个全连接层来转换区域特征以实现检索任务。作者将变换后的特征表示为,其中对应于的变换特征。
Sentence Instance Candidates
作者使用句子T的Word-Piece token作为文本形式的片段。每个单词的最终嵌入是其标记嵌入、位置嵌入和段嵌入的组合,表示为。这些图像区域特征和单词嵌入被进一步送到多模态交叉注意网络中,以融合模态内和模态间信息。
2.3. Self-Attention Module
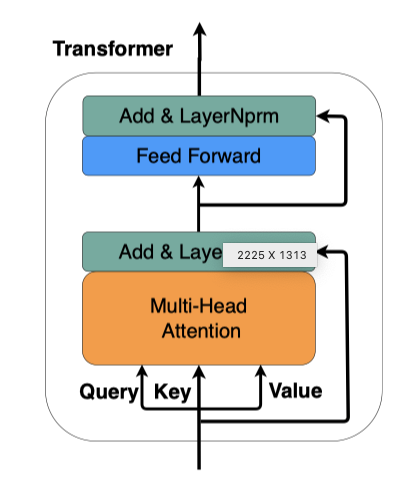
注意力模块可以描述为将query和一组key-value对映射到输出。注意力函数的输出是value的加权和,其中权重矩阵由query及其对应的key确定。具体而言,对于Self-Attention机制而言,query、key和value是相同的。
作者应用Transformer来实现注意力。如上图所示,Transformer由两个子层组成,即多头自注意子层和feed-forward层。在多头自注意子层中,注意力被计算h次,使其成为多头。这是通过使用不同的可学习线性投影将查询(Q)、键(K)和值(V)投影h次来实现的。
具体来说,给定一组片段,作者首先计算输入的查询、键和值:,其中。然后,可以通过”Scaled Dot-Product Attention”获得权重矩阵。通过以下等式计算value的加权和:
之后,计算所有head的值,并将它们concat在一起:
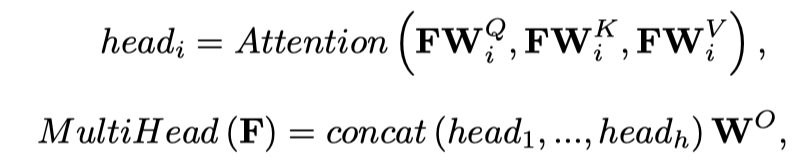
式中,h是head数。
为了进一步调整片段表示,feed-forward子层将每个片段分别且相同地转换为两个完全连接的层。并且可以描述为:
通过上述自注意力单元,每个图像区域或句子词都可以关注同一模态中其他片段的特征。如上图中绿色虚线块所示,对于具有细粒度表示的图像I,作者使用上述Transformer单元,并生成包含区域关系的特征。接下来,作者通过简单但有效的平均池化操作聚合图像区域的表示:
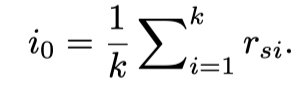
同时,l2标准化也适用于调整最终全局表示。当聚合中的片段特征时,图像i的表示包含模态内关系。
对于文本数据建模,作者将句子T的token送到预训练的BERT模型中。BERT由多个Transformer单元组成,其输出包括了模态内信息。然后使用一维卷积神经网络提取局部上下文信息。作者使用三种窗口大小(uni-gram、bi-gram和tri-gram)来捕获短语级信息。第k个单词使用窗口大小为l的卷积输出为:
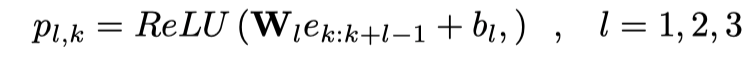
其中,是卷积滤波器矩阵,是偏差。接下来,对所有单词位置执行最大池化操作: 。然后将q1、q2、q3连接起来,并将其传递到一个全连接层,然后进行l2标准化以获得最终的句子嵌入:
其中和。类似地,对文本数据的模态内关系进行建模。
2.4. Cross-Attention Module
尽管上述自注意模块可以有效地利用模态内的关系,但模态间的关系,例如,图像区域和句子单词的关系没有被探索。在本节中,作者将介绍如何使用交叉注意模块在单一模型中建模模态间和模态内的关系。
如图中的红色虚线块所示,cross attention模块将图像区域和句子单词的堆叠特征
作为输入,其中。query, key 和 value表示如下:
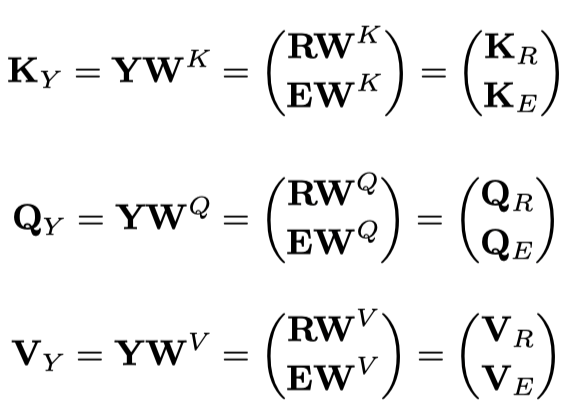
然后采用Scaled Dot-Product Attention,计算如下:
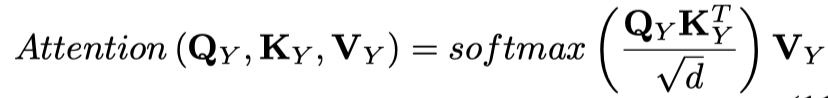
为了使推导简单易懂,作者去除了上面等式中的softmax和scaled函数,这并不影响注意力机制的核心思想。可以扩展如下:
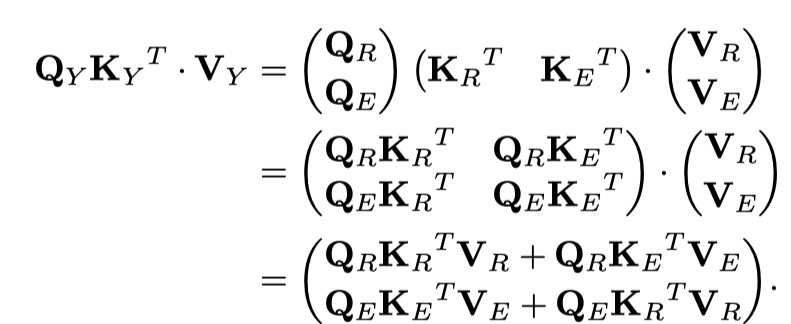
由于
,视觉和文本片段的更新特征为:
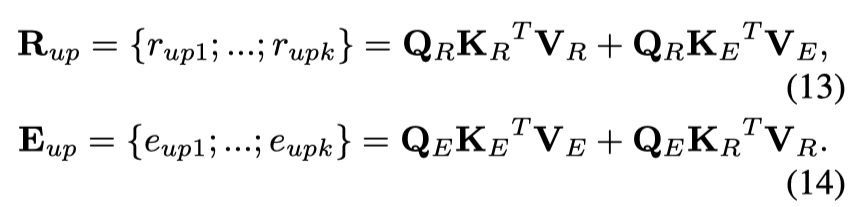
该结果表明,该Transformer单元中多头子层的输出同步考虑了模态间和模态内关系。然后
可以送到feed-forward子层。最后,在交叉注意模块中得到Transformer单元的输出,表示为:
。为了获得整个图像和句子的最终表示,作者将分为和,再次将它们传递到平均池化层(对于图像区域)或1d CNN层和最大池化层(对于句子中的单词),这与自注意模块中的最后几个操作非常相似。最终,就获得了图像和句子的表示。
03
实验
3.1. Performance Comparison
Results on Flickr30K
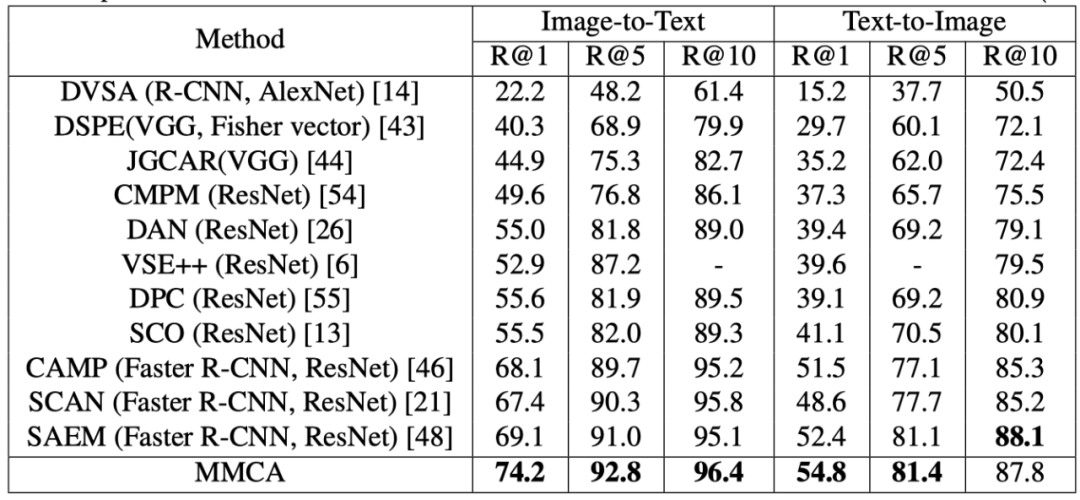
上表展示了Flickr30K上和SOTA模型的实验对比结果。
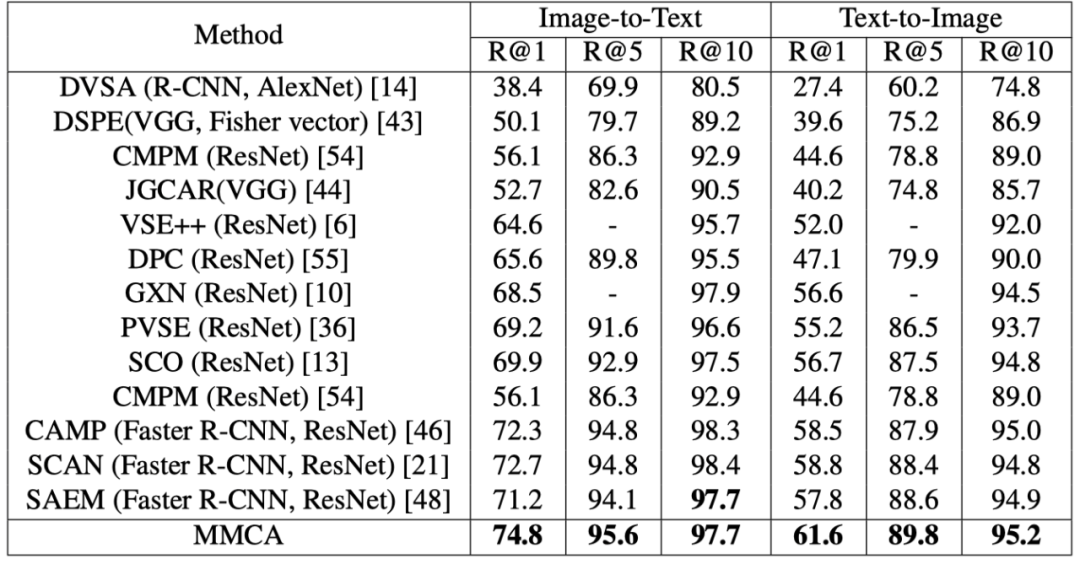
上表展示了MS-COCO 1K上和SOTA模型的实验对比结果。
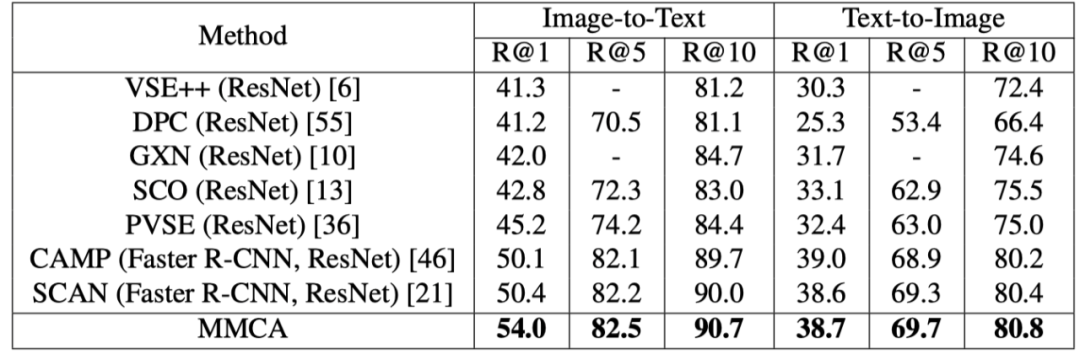
上表展示了MS-COCO 5K上和SOTA模型的实验对比结果。
3.2. Ablation Studies and Analysis
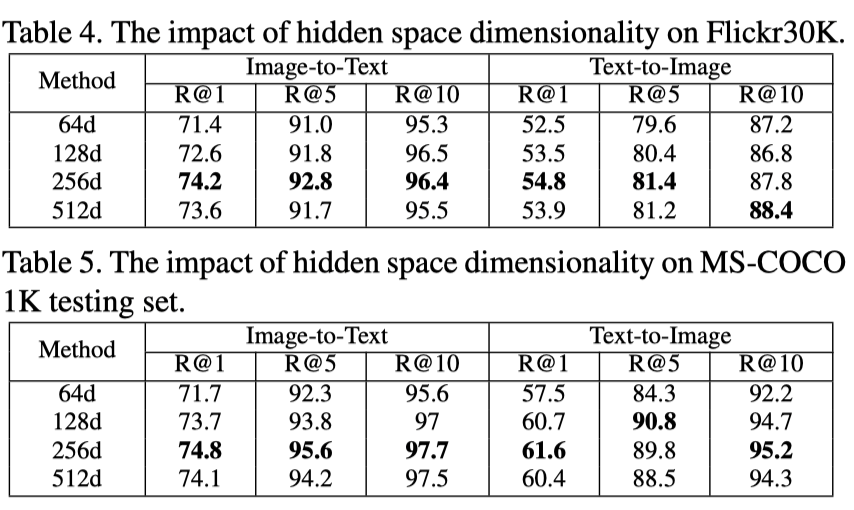
上表展示了Flickr30K和MS-COCO 1K上不同hidden dimension的实验结果。
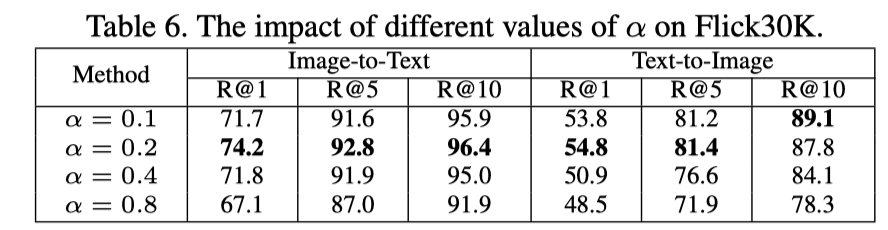
上表展示了不同值的实验结果。


上图展示了本文方法进行图文检索的定性实验结果。
04
总结
本文解决的是图文检索的问题,总体思路还是比较简单的,以前的方法大多只考虑了模态内的交互,而本文的作者采用了模态间的交互,因此对于视频和文本分别可以获得2个特征(即模态内交互得到的特征和模态间交互得到的特征),作者发现通过联合比较模态内交互的视频-文本特征和模态间交互的视频-文本特征可以获得更好的检索结果。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「图像检索 」 交流群👇备注: 检索

Original: https://blog.csdn.net/moxibingdao/article/details/122138531
Author: 我爱计算机视觉
Title: 中科大&快手提出多模态交叉注意力模型:MMCA,促进图像-文本多模态匹配!
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/528092/
转载文章受原作者版权保护。转载请注明原作者出处!