

论文地址:https://arxiv.org/abs/2003.06761 或者 https://ieeexplore.ieee.org/document/9157457
代码地址:https://github.com/hqucv/siamban (作者源码) 或者 https://www.aliyundrive.com/s/e1oUifPzp5M (我自己的标注版代码,约483MB,包含代码+预训练好的模型+OTB50的basketball序列,用于调试测试代码)
目录
- 一、论文原文整理
- Abstract
- 1. Introduction
- 2. Related Works
* - 2.1 Siamese Network based visual trackers
- 2.2 Anchor-free object detectors
- 3. SiamBAN Framework
* - 3.1 孪生网络的backbone
- 3.2 Box Adaptive Head
- 3.3 Multi-level prediction
- 3.4 Ground-truth and Loss
- 3.5 Training and Inference
- 4. Experiments
* - 4.1 Implementation Details
- 4.2 Comparison with State-of-the-art Trackers
- 4.3 Ablation Study
- 二、代码细节
* - 1. 下载代码、预训练模型、数据集,安装相关库
- 2. 进行测试test.py
- 3. 第一帧的特征提取
- 4. 对后续帧进行检测的特征提取部分
- 5. 对后续帧进行检测的多层特征聚合和自适应预测head
- 6. 根据head聚合结果进行最终框的选取
- 7. 测试结果展示
一、论文原文整理
Abstract
动机: 已有的大部分追踪器要么依赖于多尺度搜索要么依赖于预设的anchor boxes,以精确估计目标的尺度和比例。但是,他们经常需要繁杂和启发式的配置。
做法:本文提出一个简单但有效的追踪框架SaimBAN,探索 全卷积网络(FCN)的表达能力。SaimBAN将视觉追踪问题看作是分类和回归的并行问题, 直接以一种统一的FCN方式分类前景和背景并回归目标框。这种无先验框的设计避免了与候选框相关的超参数,使得SiamBAN 更加灵活和通用。
实验:VOT2018, VOT2019, OTB100, NFS, UAV123, LaSOT
- Introduction
跟踪背景:视觉跟踪在计算机视觉中是一个基础但极具挑战性的任务。给定一个序列初始帧的目标位置,追踪器需要在接下来的每一帧中预测目标位置。尽管视觉跟踪在最近几年已经取得了巨大的成功,但由于遮挡, 尺度变化、背景杂波、快速运动、照明变化和外观变化等视觉跟踪仍面临着巨大的挑战。
研究现状分析:许多现存的追踪器忽略了由于目标/相机移动,目标尺度和纵横比已经发生了变化,他们还依赖于多目标搜索来估计目标尺寸。比如,基于相关滤波的追踪器依赖于其分类组件,目标尺度仅由多尺度搜索估计。最近,基于孪生网络的方法引入RPN以获得精准的目标框。然而,处理目标变化的尺度和纵横比,他们需要基于启发式知识仔细地设计anchor框,这个过程会引入许多超参数和计算复杂度。
动机介绍(从生理角度):神经科学家表明:生物初级视觉皮层可以快速有效地从复杂环境中提取观察对象的轮廓或边界。也就是说, 人类可以在不需要候选框的前提下识别目标位置和轮廓。所以,我们能否也设计一个不依赖于候选框的追踪器?受到anchor-free检测器的启发,这个问题是肯定的。
本文做法: 本文提出了一种视觉追踪器SiamBAN去精准估计目标的尺度和纵横比。SiamBAN包括一个孪生网络的backbone+多个框自适应头(box adaptive heads),不需要预设的候选框,可以进行端到端的训练。SiamBAN以一个统一的FCN分类和回归边界框。具体地, SiamBAN直接预测前景-背景分类分数+在相关特征图上表示空间位置的4D向量 (该4D向量描述了从边界框的四个边到搜索区域对应的特征位置中心点的相对偏移量)。在推理过程中,本文在目标上一位置的附近进行搜索。通过最佳得分位置对应的边界框,我们可以得到目标在帧间的位移和大小变化。
- Related Works
2.1 Siamese Network based visual trackers
- SiamFC:应用孪生网络作为特征提取器并首次引入互相关层来联合特征图;
- DSiam:学习特征转换以处理目标形变;
- RASNet:在孪生网络中嵌入多样性注意力机制;
但以上方法都需要一个多尺度测试以抵抗尺度变化,不能处理由于目标性能引起的纵横比变化问题。
为了得到更精准的目标边界框,以下算法被提出:
- SiamRPN:在SiamFC中引入RPN;
- SPM-Tracker:提出序列并行匹配框架去增强SiamRPN的鲁棒性和鉴别能力;
- SiamRPN++/SiamMask/SiamDW:移除了各种影响因素,比如padding,引入了现代深度网络(ResNet, ResNeXt, MobileNet等)。
尽管以上基于anchor的追踪器能处理尺度、纵横比变化等问题,他们还需要仔细设计并固定anchor框的参数。这些参数需要启发式调整和大量的技巧才能调整好。而本文提出的算法避免了和anchor框有关的参数,更灵活和通用。
2.2 Anchor-free object detectors
旧的anchor-free的目标检测方法:
- DenseBox:首次引入FCN框架联合进行面部识别和地标定位;
- UnitBox:通过仔细设计损失函数来提升性能;
- YOLOV1:将输入图像划分为网格,并在每个网格中预测边界框和分类概率;
近年来的anchor-free的目标检测方法(分为基于关键点检测,稠密检测方法):
- CornerNet:将检测边界框看作检测一对关键点;
- ExtremeNet: 检测4个极端点和一个目标中心点;
- RepPoints:引入了代表点用于对细粒度的定位信息进行建模,并识别对对象分类有重要意义的局部区域;
- FSAF:提出了特征选择性anchor-free模块来解决启发式特征选择对具有特征金字塔的检测器的限制。
- FCOS:直接预测物体存在的可能性和边界框坐标,无需anchor参考。
目标检测和目标跟踪的区别:相比于目标检测,目标跟踪面临2个严峻的挑战:类别未知(目标检测器假设目标的类别是预设好的,但跟踪的目标在跟踪之前是未知的)+不同目标的鉴别能力(跟踪中需要区别同一类中的不同目标)。因此,能够编码外观信息的模板分支是需要的,用于分别前景和背景。
- SiamBAN Framework
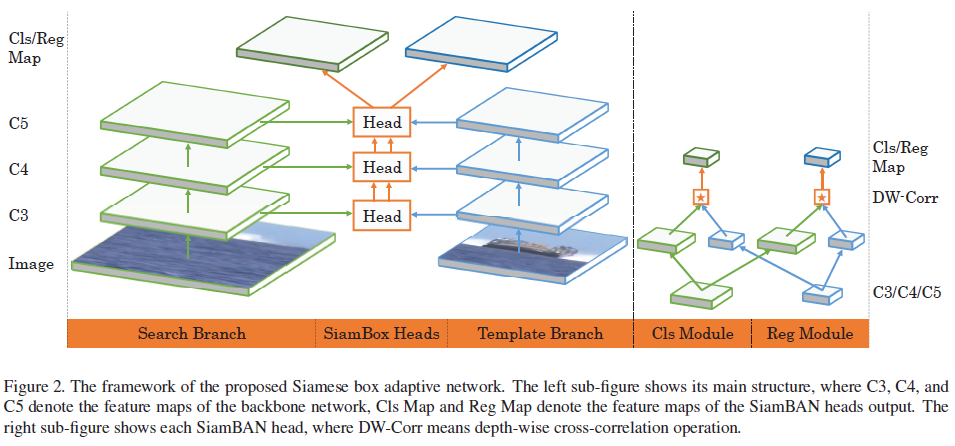

SiamBAN包括一个孪生网络的backbone+多个box adaptive heads。
- 孪生网络的backbone:用于计算目标patch和搜索patch的卷积特征图;
- box adaptive heads:包括分类模块(在相关层的每个点上执行前景背景分类)+回归模块(在对应位置执行边界框预测)。
; 3.1 孪生网络的backbone
采用ResNet-50作为backbone。并对ResNet-50做了以下3点改进,也就是在下图区域做出改进:
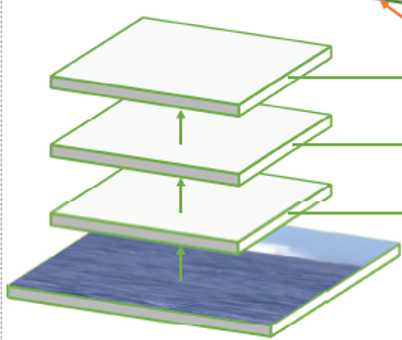
- 移除最后两个blocks的降采样操作——提升特征分辨率,跟踪问题需要细节的空间特征以执行稠密的预测;
- 使用带有不用astrous rates的atrous卷积(conv4和conv5 blocks的步幅改为1,conv4 blocks的astrous rate=2, conv5 blocks的astrous rate=4)——提升感受野;
- 在最后添加1×1卷积将输出特征通道数降为256,只用模板分支中心7×7区域的特征——减少模板分支和搜索分支的计算量。
3.2 Box Adaptive Head
1. head的具体操作:
将backbone的中间特征图进行深度互相关操作,分为2部分(分类模块和回归模块),深度互相关卷积操作的公式如下:

上边的公式输出 分类特征图,对分类特征图上的每个点应为2通道;
下边的公式输出 回归特征图,对回归特征图上的每个点应为4通道;
这里分类/回归特征图的输出量是SianRPN++等输出量的1/5,因为他们每个点的特征图要对5个anchor的分类和回归量做预测,而本文仅输出1组结果即可。
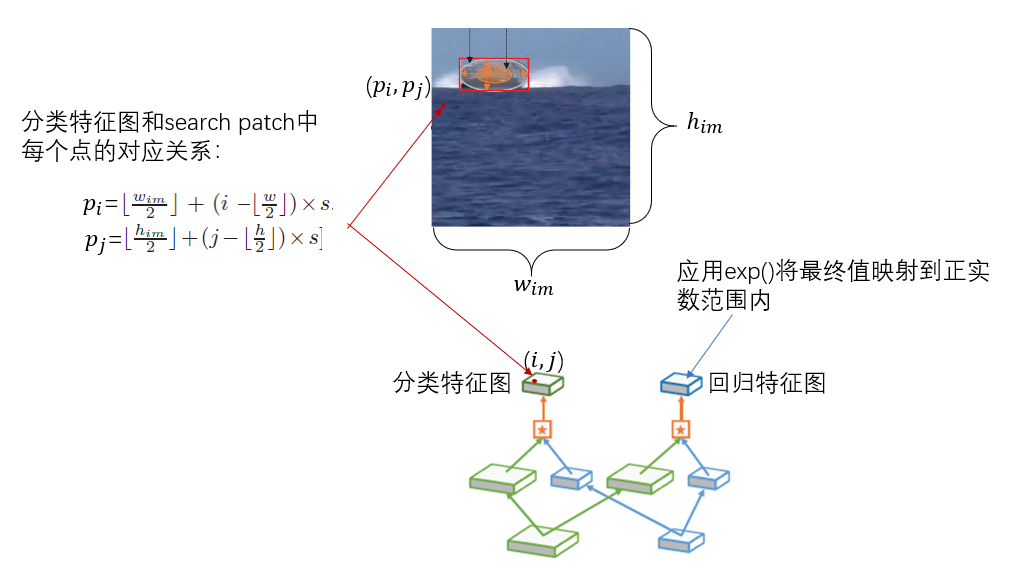
2. head输出结果和输入patch的映射关系:
如下图所示,分类特征图和search patch的映射关系为图上的公式,其中s代表网络的total步幅;对回归分支,因为基于anchor的方法中回归时调整了所有的偏移量而分支只在原始位置进行,这可能会导致分类和回归不一致,因此本文只在回归时计算对边界框的偏移量,并在最后添加exp()。
; 3.3 Multi-level prediction
动机:尽管Resnet50的conv3, conv4, conv5的空间分辨率是一样的,但他们的atrous卷积有不同的expansion rate,所以其感受野是不同的,捕获的信息也不同。(浅层特征能捕获细粒度信息,用于精准定位;深层特征能编码抽象语义信息,对模板外观变化是鲁棒的。)
做法:类似于SiamRPN++,将conv3, conv4, conv5的分类和回归特征图分别加权求和。
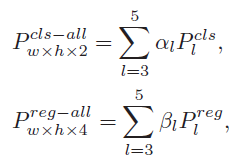
3.4 Ground-truth and Loss
先对分类和回归的标签进行定义,然后设置了损失函数。具体操作如下图:
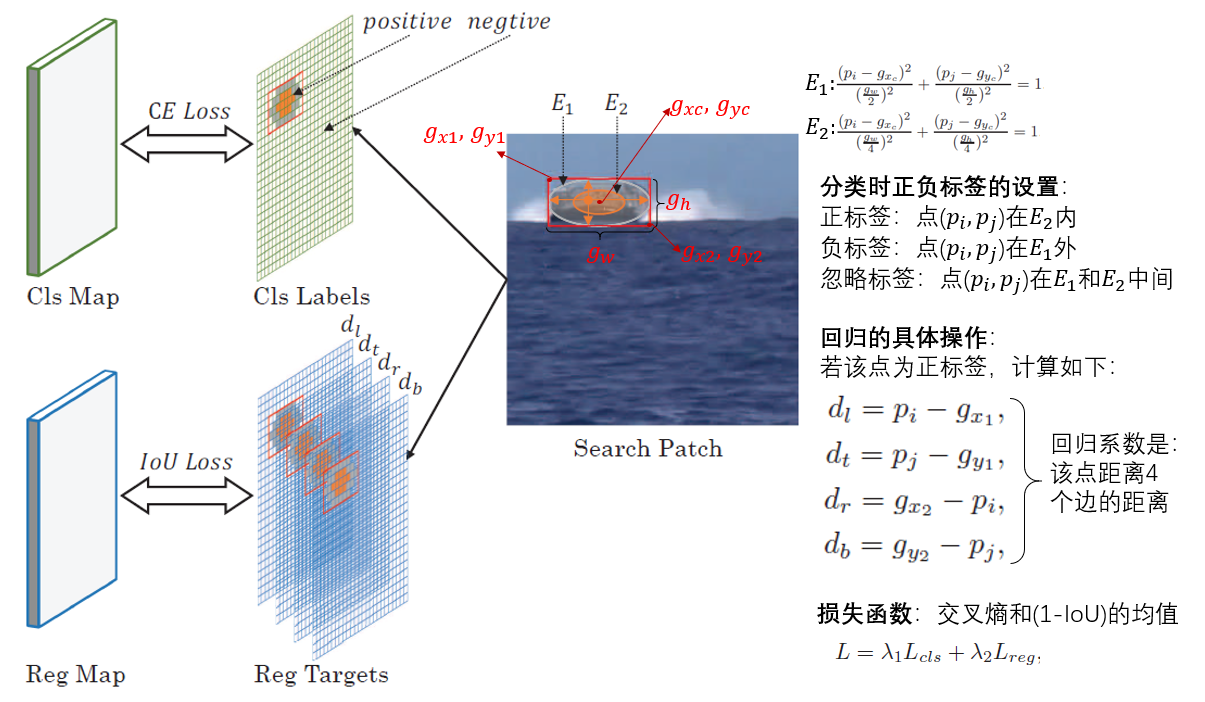
; 3.5 Training and Inference
训练数据集:ImageNetVID, YouTube-BoundingBoxes, COCO, ImageNet DET, GOT10k, LaSOT。从一对图像中收集最多16个正样本+48个负样本。
template patch的大小是127×127,search patch的大小是255X255。
推理从预测结果中还原预测框:
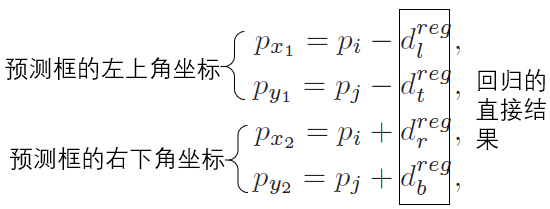
- Experiments
4.1 Implementation Details
用在ImageNet上预训练好的权重初始化Backbone, 并冻结前两层参数。
训练方法:SGD, batchsize=28 pairs, 20epochs, lr=0.001-0.005在前5个epoches,然后衰减至0.00005在最后5个epoches。
前10个epoches中只训练box adaptive heads, 最后10个epoches微调Backbone用当前学习率的1/10。weight decay=0.0001, momentum=0.9
设备:GTX1080Ti. 40FPS
4.2 Comparison with State-of-the-art Trackers
1. VOT2018
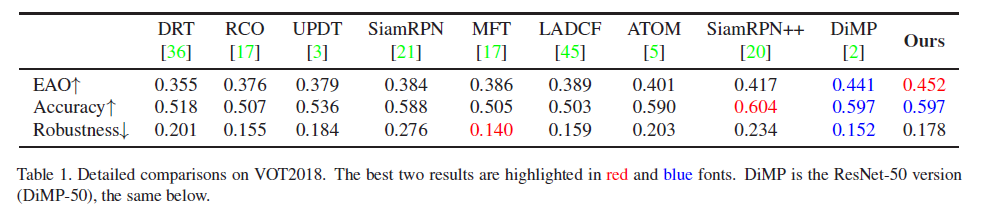
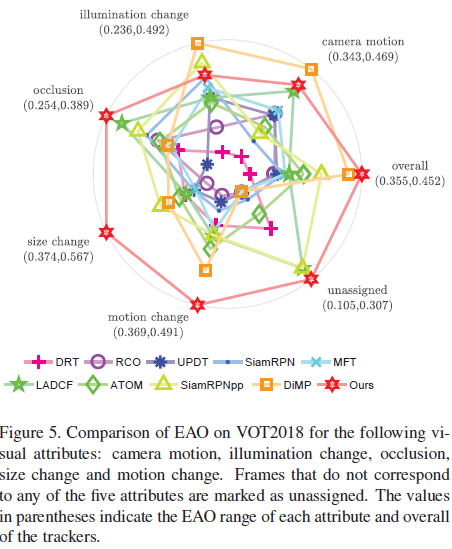
2. VOT2019:

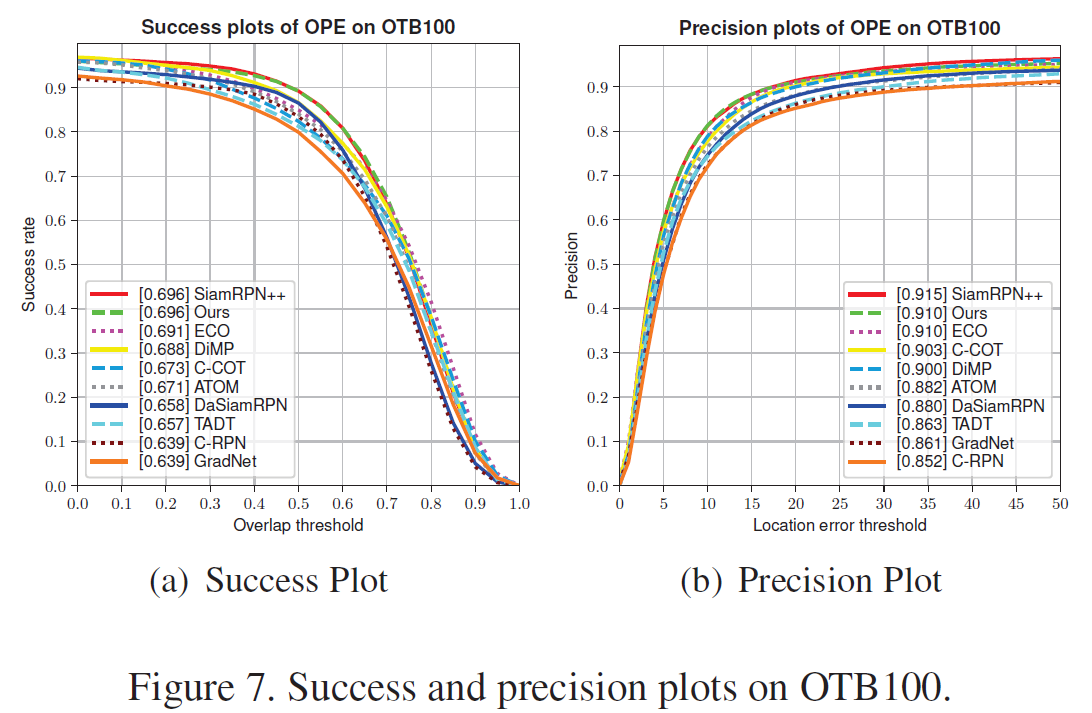
3. OTB100:
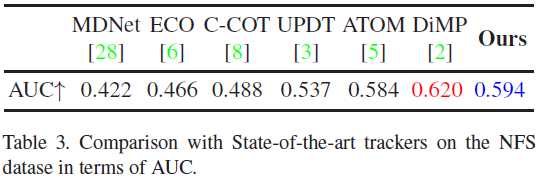
4. NFS:
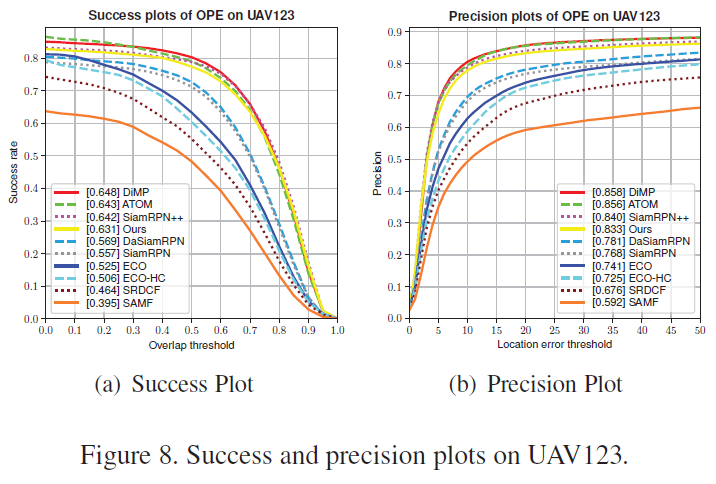
5. UAV123:
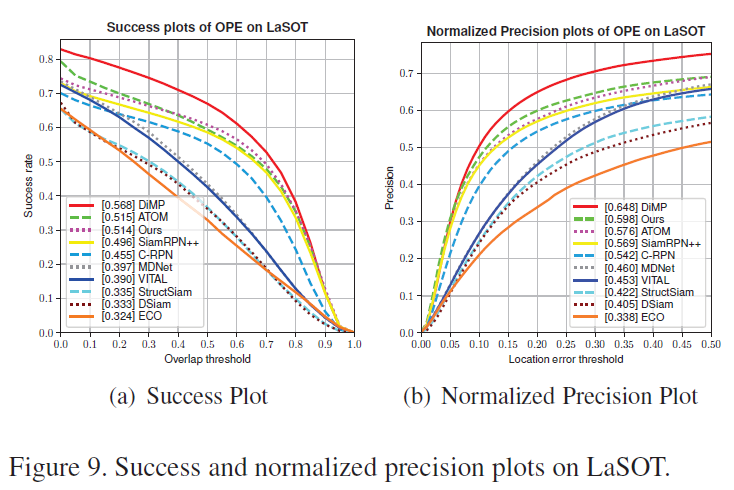
6. LaSOT:
; 4.3 Ablation Study
Discussion on Multi-level prediction
Discussion on Sample Label Assignment

二、代码细节
本博文仅以 测试部分以OTB数据集为例按测试时的代码跳转逻辑进行解释。
1. 下载代码、预训练模型、数据集,安装相关库
Step1: 下载代码,预训练模型,数据集
- 从https://github.com/hqucv/siamban 下载作者源代码和相关预训练好的模型及数据集,并根据该网页内的指导将预训练模型和数据集放至对应位置
- 或者直接下载我自己的注释版代码(代码,预训练模型和数据集已包含在其中): https://www.aliyundrive.com/s/e1oUifPzp5M
Step2: 安装相关库
- 在自己已有的pytorch环境/重新创建pytorch环境(在ubuntu系统中的环境安装可参考link)中还需安装以下库:pyyaml yacs tqdm colorama matplotlib cython tensorboard future mpi4py optuna opencv-python numpy
pip install pyyaml yacs tqdm colorama matplotlib cython tensorboard future mpi4py optuna opencv-python numpy
Step3: 安装扩展
在终端进入到siamban-master所在目录,进行扩展安装
cd siamban-master # 进入siamban-master所在目录
python setup.py build_ext --inplace
显示如下内容即为扩展安装成功:

2. 进行测试test.py
test.py是测试阶段的主文件,可直接在终端按以下语句执行测试:
cd experiments/siamban_r50_l234_otb
python -u ../../tools/test.py \
--snapshot model.pth \ # model path
--dataset OTB \ # dataset name
--config config.yaml # config file
但为了调试代码方便,我们直接在pycharm中test.py进行修改,将配置文件config file,数据集名称dataset name,预训练模型model path都调整为默认的。
config_path = os.path.join(os.path.abspath('..'),'experiments\\siamban_r50_l234_otb\\config.yaml')
snapshot_path = os.path.join(os.path.abspath('..'),'experiments\\siamban_r50_l234_otb\\model.pth')
parser = argparse.ArgumentParser(description='siamese tracking')
parser.add_argument('--dataset', default='OTB50', type=str,
help='datasets')
parser.add_argument('--config', default=config_path, type=str,
help='config file')
parser.add_argument('--snapshot', default=snapshot_path, type=str,
help='snapshot of models to eval')
parser.add_argument('--video', default='', type=str,
help='eval one special video')
parser.add_argument('--vis', action='store_true',
help='whether visualzie result')
parser.add_argument('--gpu_id', default='not_set', type=str,
help="gpu id")
直接运行test.py文件,进入main函数中执行:加载配置文件,创建SiamBAN模型架构,加载预训练好的模型,构建追踪器架构,加载数据集等操作。
# load config
cfg.merge_from_file(args.config) # 加载配置文件
cur_dir = os.path.dirname(os.path.realpath(__file__))
dataset_root = os.path.join(cur_dir, 'testing_dataset', args.dataset)
# create model
model = ModelBuilder() # 创建SiamBAN模型架构
# load model
model = load_pretrain(model, args.snapshot).cuda().eval() # 加载预训练好的模型
# build tracker
tracker = build_tracker(model) # 构建追踪器架构
# create dataset
dataset = DatasetFactory.create_dataset(name=args.dataset, # 创建加载数据集,会进入otb.py文件
dataset_root=dataset_root,
load_img=False)
这里可以将model打印出来,看看SiamBAN的具体架构(下图展示了部分截图,不完整):

在正式跟踪时,先对第一帧的目标进行特征提取,核心语句如下:
tracker.init(img, gt_bbox_)
其次,对剩下的所有框依次执行以下语句:
outputs = tracker.track(img) # 输出当前帧的追踪结果
pred_bbox = outputs['bbox'] # 记录当前帧的追踪目标框
pred_bboxes.append(pred_bbox)
scores.append(outputs['best_score']) # 记录当前帧得到的目标框的分数
当然在test.py中还有许多其他语句,比如追踪时间统计,可视化追踪结果,保存追踪结果等,由于其不是算法核心,本博文中不进行解释(可参考代码中的中文注释)。
3. 第一帧的特征提取
在test.py中有一句重要语句tracker.init(img, gt_bbox_)是对第一帧继续特征提取,会跳转至siamban_tracker.py文件,我们进入siamban_tracker.py文件查看具体细节。
这里先对原始图像进行裁剪,裁剪到目标框附近的区域作为template branch的输入图像。
这里论文没有明确指出和解释
# calculate z crop size 计算template branch的输入图像的大小(是原始图像在目标框附近的裁剪版)
w_z = self.size[0] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
h_z = self.size[1] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
s_z = round(np.sqrt(w_z * h_z))
# calculate channle average
self.channel_average = np.mean(img, axis=(0, 1))
# get crop 在目标框附近对图像进行裁剪,裁剪为127*127大小
z_crop = self.get_subwindow(img, self.center_pos,
cfg.TRACK.EXEMPLAR_SIZE,
s_z, self.channel_average)
然后将裁剪后的图像z_crop输入template branch的backbone中进行特征提取,即
对应论文的3.1节
self.model.template(z_crop) #会跳转至model_builder.py中,执行zf = self.backbone(z)
在特征提取时使用改进版本的ResNet50,即论文的3.1节中的内容,他的具体代码如下(每层的输出shape在注释中),需要注意的是因为后续需要进行多层特征聚合操作,所以 out = [out[i] for i in self.used_layers] 这句将第3,4,5个ResBlock的输出提取了出来用于一会的多层特征聚合:
对应论文的3.1节
x = self.conv1(x) # ResNet50的第一个卷积层, 输出shape为[1, 64, 61, 61]
x = self.bn1(x)
x_ = self.relu(x) # 输出shape为[1, 64, 61, 61]
x = self.maxpool(x_) # 经过最大池化后输出shape为[1, 64, 61, 61]
p1 = self.layer1(x) # 第2个ResBlock,输出shape为[1, 256, 31, 31]
p2 = self.layer2(p1) # 第3个ResBlock,输出shape为[1, 512, 15, 15]
p3 = self.layer3(p2) # 第4个ResBlock,输出shape为[1, 1024, 15, 15]
p4 = self.layer4(p3) # 第5个ResBlock,输出shape为[1, 2048, 15, 15]
out = [x_, p1, p2, p3, p4]
out = [out[i] for i in self.used_layers] # 仅需要第3,4,5个ResBlock的输出,用于一会的多层特征聚合操作(论文中3.3节的内容)
下面针对经过backbone的多层输出进行调整,以备后续进行多层特征聚合,也就是model_builder.py中zf = self.neck(zf)这句(输入zf就是上面的out),self.neck的操作是第3,4,5个ResBlock的输出分别调整至[1, 256, 7, 7]大小,具体代码对如下:
对应论文3.1节的第3点改进
x = self.downsample(x) #添加1x1卷积将输出特征通道数降为256
if x.size(3) < 20:# 只用模板分支中心7x7区域的特征
l = 4
r = l + 7
x = x[:, :, l:r, l:r] # 输出x的shape是[1, 256, 7, 7]
至此第一帧已经运行结束,得到了第一帧的多层特征的调整后结果。
下面对后续待检测帧进行具体操作。
4. 对后续帧进行检测的特征提取部分
对后续帧进行检测在test.py中的outputs = tracker.track(img)这句,会跳转至siamban_tracker.py中。
照例,对该帧图像进行裁剪,i.e., 在上一帧目标位置附近对当前图像进行裁剪,与template branch不同的时,搜索分支的裁剪结果是255*255大小
w_z = self.size[0] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
h_z = self.size[1] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
s_z = np.sqrt(w_z * h_z)
scale_z = cfg.TRACK.EXEMPLAR_SIZE / s_z
s_x = s_z * (cfg.TRACK.INSTANCE_SIZE / cfg.TRACK.EXEMPLAR_SIZE)
x_crop = self.get_subwindow(img, self.center_pos,
cfg.TRACK.INSTANCE_SIZE,
round(s_x), self.channel_average) # 在上一帧目标位置附近对当前图像进行裁剪
进入该帧的特征提取部分,也就是search branch部分,关键语句是outputs = self.model.track(x_crop),代码跳转至model_builder.py中。和第一帧的操作类似,输入backbone并进行self.neck的调整。
xf = self.backbone(x) # 搜索分支的输入图像shape是[1, 3, 255, 255]
if cfg.ADJUST.ADJUST:
xf = self.neck(xf) # 每一个中间层调整后的shape都是[1, 256, 31, 31]
至此,search branch和template branch的特征提取和中间层的调整都已经做完了,也就是论文的3.1部分结束。
5. 对后续帧进行检测的多层特征聚合和自适应预测head
总语句是model_builder.py的cls, loc = self.head(self.zf, xf):将第一帧和待检测帧的中间特征作为输入,输出分类和回归结果。这句会跳转至ban.py文件中。
先来总览一下分类模块和回归模块的网络架构:

然后我们看分类模块的具体操作,即得到分类特征图,注意这里输出的通道数是2,即论文里强调的直接输出每个像素点的前景/背景概率,而不是像SiamRPN等输出的通道数是2*5=10(每个像素点有5个anchor,需要5个anchor的前景/背景概率都进行预测):
对应论文3.2的等式(1)的上面的公式
kernel = self.conv_kernel(kernel) # template branch经过ResNET50的第3个block经过self.neck调整后的特征图作为输入,输出为[1, 256, 5, 5]
search = self.conv_search(search) # search branch经过ResNET50的第3个block经过self.neck调整后的特征图作为输入,输出为[1, 256, 29, 29]
feature = xcorr_depthwise(search, kernel) # 深度互相关卷积,输出为[1, 256, 25, 25]
out = self.head(feature) # 输出为[1, 2, 25, 25]
接下来是回归模块的具体操作,即得到回归特征图,注意这里输出的通道数是4.
# 对应论文3.2的等式(1)的下面的公式
kernel = self.conv_kernel(kernel) # template branch经过ResNET50的第3个block经过self.neck调整后的特征图作为输入,输出为[1, 256, 5, 5]
search = self.conv_search(search) # search branch经过ResNET50的第3个block经过self.neck调整后的特征图作为输入,输出为[1, 256, 29, 29]
feature = xcorr_depthwise(search, kernel) # 深度互相关卷积,输出为[1, 256, 25, 25]
out = self.head(feature) # 分类时输出为[1, 2, 25, 25],回归时输出为[1, 4, 25, 25]
至此,得到了分类特征图和回归特征图,也就是在25*25大小的特征图上,每个像素点对应的框的前景/背景概率和框的位置系数。
另外,还需要对回归特征图进行exp操作,对应论文里3.2的最后几句话。
torch.exp(l*self.loc_scale[idx-2]) # 保证偏移值为正实数
以上分类和回归操作需要循环3次,i.e.,对backbone的3个不同的中间特征图进行分类和回归操作。循环的语句如下:
cls = []
loc = []
for idx, (z_f, x_f) in enumerate(zip(z_fs, x_fs), start=2):
box = getattr(self, 'box'+str(idx))
c, l = box(z_f, x_f)
cls.append(c)
loc.append(torch.exp(l*self.loc_scale[idx-2])) # 保证偏移值为正实数
然后就是多层特征聚合的核心,对分类和回归结果进行加权求和,即论文的3.3的等式(2)
对应论文的3.3的等式(2)
weighted_avg(cls, cls_weight), weighted_avg(loc, loc_weight)
至此,算法核心部分就差不多,回到siamban_tracker.py的outputs = self.model.track(x_crop)中,outputs就是每个点预测框的分类和回归的加权求和结果。
6. 根据head聚合结果进行最终框的选取
得到了每个点预测框的分类和回归的加权求和结果,就对这些框(25*25=625个)进行排序了。
和SiamRPN, SiamRPN++相同,排序的过程是:尺度惩罚,比例惩罚, 窗口惩罚,重新计算得分,选择分数最高的作为该帧的最终预测结果。
# scale penalty
s_c = change(sz(pred_bbox[2, :], pred_bbox[3, :]) /
(sz(self.size[0]*scale_z, self.size[1]*scale_z)))
# aspect ratio penalty
r_c = change((self.size[0]/self.size[1]) /
(pred_bbox[2, :]/pred_bbox[3, :]))
penalty = np.exp(-(r_c * s_c - 1) * cfg.TRACK.PENALTY_K)
pscore = penalty * score
# window penalty
pscore = pscore * (1 - cfg.TRACK.WINDOW_INFLUENCE) + \
self.window * cfg.TRACK.WINDOW_INFLUENCE
best_idx = np.argmax(pscore)
bbox = pred_bbox[:, best_idx] / scale_z
lr = penalty[best_idx] * score[best_idx] * cfg.TRACK.LR
cx = bbox[0] + self.center_pos[0]
cy = bbox[1] + self.center_pos[1]
# smooth bbox
width = self.size[0] * (1 - lr) + bbox[2] * lr
height = self.size[1] * (1 - lr) + bbox[3] * lr
7. 测试结果展示
要想代码在测试时对每帧检测结果实时展示,只需要将test.py中改为
parser.add_argument('--vis', action='store_true', default=True,
help='whether visualzie result')
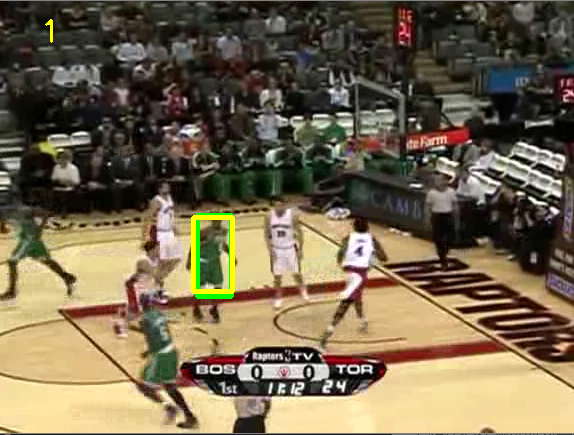
这里截取了几张测试结果进行展示,坐上角是当前图像的帧数,黄色是label,绿色是预测的框。
Original: https://blog.csdn.net/m0_37412775/article/details/123919500
Author: 三晚不过弦一郎
Title: VOT2SiamBAN: Siamese Box Adaptive Network for Visual Tracking
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527835/
转载文章受原作者版权保护。转载请注明原作者出处!