

前言:
经典网红数分项目,本文仅为pandas实现数据分析提供思路,不实现数据可视化图表,也不对分析结果作结论,读者可自行根据数据分析出来的结果和分析整体思路做一个数据分析总结
原文摘要:
本数据集包含了 2017 年 11 月 25 日至 2017 年 12 月 3 日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。
数据集的每一行表示一条用户行为,由用户 ID、商品 ID、商品类目 ID、行为类型和时间戳组成,并以逗号分隔。
关于数据集的详细描述如下:
数据源链接:数据集-阿里云天池
数据特征:
User_id(用户ID):整数类型
item_id(商品ID):整数类型
cate_id(类目ID):整数类型
act_id(行为类型):字符串,枚举类型
包含’pv’(点击)、’buy’(购买),’cart’(加购),’fav’(收藏)
time(时间戳):行为发生的时间戳
分析思路:
- 基础设置(导入模块、格式设置、数据整理预览)
- 数据清洗(查重、缺失值、异常值)
- 数据整体情况分析
- 时间统计分析
- 用户行为分析
- 销售情况分析
- 用户价值分层
基础设置
文件名我改过, 因为数据量较大,为了加快运行效率,我只选用了10万条数据,待代码写好后再导入原数据
观察数据规模,展现形式
对特定字段进行格式转化
import pandas as pd
数据源
path = r'C:\Users\Administrator\Desktop\data.csv' # 文件地址
columns_name = ['user_id', 'product_id', 'tag', 'act_id', 'time'] # 列名
data = pd.read_csv(path, header=None, names=columns_name) # 导入数据
数据预处理
数据格式调整
data['time'] = pd.to_datetime(data['time'], unit='s')
data['date'] = pd.to_datetime(data['time'].dt.date)
data['month'] = data['time'].dt.month
data['weekday'] = data['time'].dt.weekday
data['day'] = data['time'].dt.day
data['hour'] = data['time'].dt.hour
print(data.shape)
print(data.isnull().sum())
print(data.describe)
print(data.info)
需要可视化就自行导入matplotlib、seaborn的模块
数据清洗
数据清洗一般涉及到删除重复数据,观察异常值,统计缺失值及其占比,删除指定列/行的空值等等
观察数据发现,源数据只有异常数据,其他无异
查重
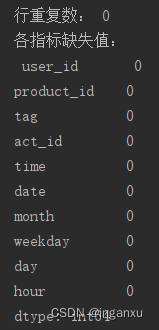
print('行重复数:', data.duplicated().sum())
缺失值处理
print('各指标缺失值:', '\n', data.isnull().sum())
异常数据处理
因为数据仅处于2017年11月25日至2017年12月3日之间,2017-11-24前的数据均为异常数据,按异常数据丢弃处理
data = data.query('date > "2017-11-24"')

数据整体情况分析
观察各指标去重后的数量
数据时间范围是否一致
数据总体了解
print('各指标去重数量:')
for i in list(data.columns.values)[:4]: #前四个为原先定义的指标
print('{}: 共 {} 个'.format(i, data[i].nunique()))
act_id_list = data['act_id'].unique() # 获取行为的分类
print('其中,行为的指标分别为:{}'.format(act_id_list))
print('用户记录开始时间:{}'.format(data['time'].min()))
print('用户记录结束时间:{}'.format(data['time'].max()))
print('数据记录时间差为:{}'.format(data['time'].max() - data['time'].min()))
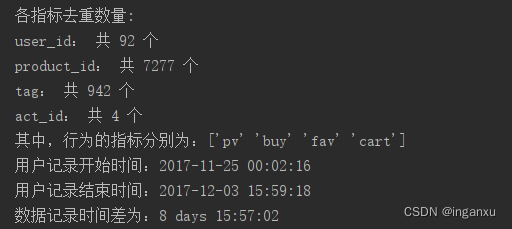
去掉异常数据后可以看到,数据的开始和结束时间跟原文一致,并且用户行为指标有且仅有原文规定的指标
时间统计分析
以各个时间段为区间,统计分析每个时间段上的销售情况,针对某几个黄金时间段刺激用户消费
时间统计情况
按日期统计数据
date_statistic = ['按日期统计:', '按月份统计:', '按星期统计:', '按天统计:', '按小时统计:', ]
for index, i in enumerate(list(data.columns.values)[5:]):
print('{}\n{}'.format(date_statistic[index], data[i].value_counts()), '\n')
可以观察到商品在月、周、天、小时等各个时间线上的TOP时间段
如果时间线跨越季度或者双11、双12,那么可以在这个时间段上进一步分析其用户行为和销售情况
用户行为分析
观察用户行为指标的数量,判断是否有异常行为指标
统计用户各行为占比率
用户行为路径我分为了两种:
用户行为路径一:pv-cart-buy
用户行为路径二:pv-fav-cart-buy
用户行为分析
item = {}
for i in act_id_list: # 统计每个行为的数量
item[i] = data[data['act_id'] == '{}'.format(i)]['act_id'].count()
print('{}的行为数量为: {}'.format(i, item[i]), '\n')
print('平均访问量:{} /人'.format(round(item['pv'] / data['user_id'].nunique())))
print('商品点加率:{} %'.format(round(item['cart'] / item['pv'] * 100)))
print('商品点藏率:{} %'.format(round(item['fav'] / item['pv'] * 100)))
print('商品点购率:{} %'.format(round(item['buy'] / item['pv'] * 100)))
行为路径一:p-c-b
pc = round(item['pv'] / item['cart'], 2)
cb = round(item['cart'] / item['buy'], 2)
print('用户行为路径p-c-b的转化率为:', '{}%, {}%'.format(pc, cb))
行为路径二:p-f-c-b
pf = round(item['pv'] / item['fav'], 2)
fc = round(item['fav'] / item['cart'], 2)
cb = round(item['cart'] / item['buy'], 2)
print('用户行为路径p-f-c-b的转化率为:', '{}%, {}%, {}%'.format(pf, fc, cb))
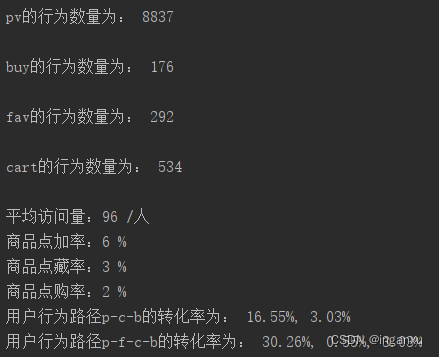
十分明显可以看到,点击数与其他行为数量差距过大
销售情况分析
统计整体的付费率、复购率
购买频数前五名的用户
购买频数前五项的商品
购买频数前五类的商品类目
产品数据分析
跳出率 = 只浏览过的用户数 / 总用户数 = 总用户数-不止浏览过的用户数 / 总用户数
only_pv = data['user_id'].nunique() - data[data['act_id'].isin(['fav','cart','buy'])]['user_id'].nunique()
jump_rate = round(only_pv / data['user_id'].nunique() *100 ,2)
print('跳出率:{} %'.format(jump_rate))
付费率 = 购买过的用户数 / 总用户数
pay_cnt = data[data['act_id'] == 'buy']['user_id'].nunique()
pay_rate = round(pay_cnt / data['user_id'].nunique() * 100,2)
print('付费率:{} %'.format(pay_rate))
复购率 = 购买2次及以上的用户数 / 购买过的总用户数
repurchase = data[data['act_id'] == 'buy'].groupby(by='user_id',as_index=False).agg({'act_id':'count'})
re_rate = round(repurchase[repurchase['act_id'] > 1]['act_id'].count() / data[data['act_id'] == 'buy']['act_id'].nunique(),2)
print('复购率:{} %'.format(re_rate))
print('购买频数前五名用户:', '\n', data['user_id'].value_counts().head(), '\n')
print('购买频数前五名商品:', '\n', data['product_id'].value_counts().head(), '\n')
print('购买频数前五名商品类目:', '\n', data['tag'].value_counts().head(), '\n')

观察到付费率和复购率的占比偏高,尤其是付费率的占比,可以拆分细化各个商品类目的付费率和复购率知道哪些商品类目更受用户的喜爱
用户价值分层
RFM用户价值模型,主要有三个核心指标,用户唯一ID,最近一次购买时间,购买金额
因为数据不涉及到金额方面,默认都为金额高的用户,因此,仅分析R和F两个层面,并对用户进行四个层次的分级
FRM用户价值分层模型
RFM = data[data['act_id'] == 'buy'].groupby('user_id',as_index=False).agg({'act_id':'count','date':'max'})
RFM['R'] = (pd.to_datetime('2017-12-03')-RFM['date']).dt.days
RFM.rename(columns={'act_id':'F'},inplace=True)
RFM.drop(columns=['date'],inplace=True)
RFM['R_label'] = pd.cut(RFM['R'],bins=2,right=False,labels=range(0,2)).astype('int')
RFM['F_label'] = pd.cut(RFM['F'],bins=2,right=False,labels=range(0,2)).astype('int')
用户分层
for i,j in RFM.iterrows():
if j['R_label'] == 1 and j['F_label'] == 1:
RFM.loc[i,'用户类别'] = '重要价值用户'
if j['R_label'] == 1 and j['F_label'] == 0:
RFM.loc[i,'用户类别'] = '重要发展用户'
if j['R_label'] == 0 and j['F_label'] == 1:
RFM.loc[i,'用户类别'] = '重要保持用户'
if j['R_label'] == 0 and j['F_label'] == 0:
RFM.loc[i,'用户类别'] = '重要挽留用户'
print(RFM)
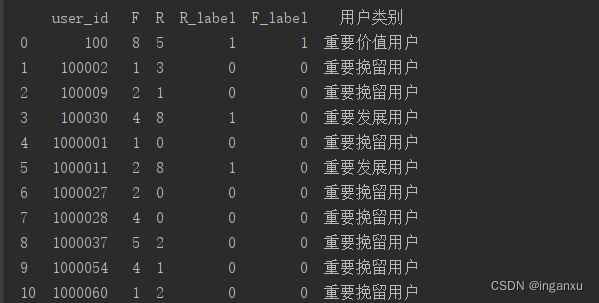
可以可视化观察对比下每个层级的用户数和占比或者细化商品类目观察其分层情况
完整代码
方便读者完善代码思路,奉上完成的代码,以供参考,建议以自己的分析思路用pandas实现数据处理
运行该代码时请修改文件地址
!/usr/bin/python3.7
-*- coding:utf-8 -*-
@author:inganxu
CSDN:inganxu.blog.csdn.net
@Date:2022年8月12日
import pandas as pd
数据源
path = r'C:\Users\Administrator\Desktop\data.csv' # 文件地址
columns_name = ['user_id', 'product_id', 'tag', 'act_id', 'time'] # 列名
data = pd.read_csv(path, header=None, names=columns_name) # 导入数据
数据预处理
数据格式调整
data['time'] = pd.to_datetime(data['time'], unit='s')
data['date'] = pd.to_datetime(data['time'].dt.date)
data['month'] = data['time'].dt.month
data['weekday'] = data['time'].dt.weekday
data['day'] = data['time'].dt.day
data['hour'] = data['time'].dt.hour
查重
print('行重复数:', data.duplicated().sum())
print('\n')
print('-' * 100)
print('\n')
缺失值处理
print('各指标缺失值:', '\n', data.isnull().sum())
print('\n')
print('-' * 100)
print('\n')
异常数据处理
因为数据仅处于2017年11月25日至2017年12月3日之间,2017-11-24前的数据均为异常数据,按异常数据丢弃处理
data = data.query('date > "2017-11-24"')
数据总体了解
print('各指标去重数量:')
for i in list(data.columns.values)[:4]: #前四个为原先定义的指标
print('{}: 共 {} 个'.format(i, data[i].nunique()))
act_id_list = data['act_id'].unique() # 获取行为的分类
print('其中,行为的指标分别为:{}'.format(act_id_list))
print('\n')
print('-' * 100)
print('\n')
print('用户记录开始时间:{}'.format(data['time'].min()))
print('用户记录结束时间:{}'.format(data['time'].max()))
print('数据记录时间差为:{}'.format(data['time'].max() - data['time'].min()))
print('\n')
print('-' * 100)
print('\n')
时间统计情况
按日期统计数据
date_statistic = ['按日期统计:', '按月份统计:', '按星期统计:', '按天统计:', '按小时统计:', ]
for index, i in enumerate(list(data.columns.values)[5:]):
print('{}\n{}'.format(date_statistic[index], data[i].value_counts()), '\n')
print('\n')
print('-' * 100)
print('\n')
用户行为分析
item = {}
for i in act_id_list: # 统计每个行为的数量
item[i] = data[data['act_id'] == '{}'.format(i)]['act_id'].count()
print('{}的行为数量为: {}'.format(i, item[i]), '\n')
print('-' * 100)
print('\n')
print('平均访问量:{} /人'.format(round(item['pv'] / data['user_id'].nunique())))
print('商品点加率:{} %'.format(round(item['cart'] / item['pv'] * 100)))
print('商品点藏率:{} %'.format(round(item['fav'] / item['pv'] * 100)))
print('商品点购率:{} %'.format(round(item['buy'] / item['pv'] * 100)))
print('\n')
print('-' * 100)
print('\n')
行为路径一:p-c-b
pc = round(item['pv'] / item['cart'], 2)
cb = round(item['cart'] / item['buy'], 2)
print('用户行为路径p-c-b的转化率为:', '{}%, {}%'.format(pc, cb))
行为路径二:p-f-c-b
pf = round(item['pv'] / item['fav'], 2)
fc = round(item['fav'] / item['cart'], 2)
cb = round(item['cart'] / item['buy'], 2)
print('用户行为路径p-f-c-b的转化率为:', '{}%, {}%, {}%'.format(pf, fc, cb))
print('\n')
print('-' * 100)
print('\n')
产品数据分析
跳出率 = 只浏览过的用户数 / 总用户数 = 总用户数-不止浏览过的用户数 / 总用户数
only_pv = data['user_id'].nunique() - data[data['act_id'].isin(['fav','cart','buy'])]['user_id'].nunique()
jump_rate = round(only_pv / data['user_id'].nunique() *100 ,2)
print('跳出率:{} %'.format(jump_rate))
付费率 = 购买过的用户数 / 总用户数
pay_cnt = data[data['act_id'] == 'buy']['user_id'].nunique()
pay_rate = round(pay_cnt / data['user_id'].nunique() * 100,2)
print('付费率:{} %'.format(pay_rate))
复购率 = 购买2次及以上的用户数 / 购买过的总用户数
repurchase = data[data['act_id'] == 'buy'].groupby(by='user_id',as_index=False).agg({'act_id':'count'})
re_rate = round(repurchase[repurchase['act_id'] > 1]['act_id'].count() / data[data['act_id'] == 'buy']['act_id'].nunique(),2)
print('复购率:{} %'.format(re_rate))
print('\n')
print('-' * 100)
print('\n')
print('购买频数前五名用户:', '\n', data['user_id'].value_counts().head(), '\n')
print('购买频数前五名商品:', '\n', data['product_id'].value_counts().head(), '\n')
print('购买频数前五名商品类目:', '\n', data['tag'].value_counts().head(), '\n')
print('-' * 100)
print('\n')
FRM用户价值分层模型
RFM = data[data['act_id'] == 'buy'].groupby('user_id',as_index=False).agg({'act_id':'count','date':'max'})
RFM['R'] = (pd.to_datetime('2017-12-03')-RFM['date']).dt.days
RFM.rename(columns={'act_id':'F'},inplace=True)
RFM.drop(columns=['date'],inplace=True)
方式一:等距分箱的形式划分
RFM['R_label'] = pd.cut(RFM['R'],bins=2,right=False,labels=range(0,2)).astype('int')
RFM['F_label'] = pd.cut(RFM['F'],bins=2,right=False,labels=range(0,2)).astype('int')
方式二:按平均分的形式划分
RFM['R_C'] = (RFM['R'] >= RFM['R'].mean()) * 1
RFM['F_C'] = (RFM['F'] >= RFM['F'].mean()) * 1
用户分层
for i,j in RFM.iterrows():
if j['R_label'] == 1 and j['F_label'] == 1:
RFM.loc[i,'用户类别'] = '重要价值用户'
if j['R_label'] == 1 and j['F_label'] == 0:
RFM.loc[i,'用户类别'] = '重要发展用户'
if j['R_label'] == 0 and j['F_label'] == 1:
RFM.loc[i,'用户类别'] = '重要保持用户'
if j['R_label'] == 0 and j['F_label'] == 0:
RFM.loc[i,'用户类别'] = '重要挽留用户'
print(RFM)
print('\n')
print('-' * 100)
print('\n')
print(data)
结语:
本文仅对数据作简单的整体分析,没对数据深度分析,感兴趣的读者可根据自身条件针对某个方面进一步分析,例如:
相关性分析(用户收藏是否与购买呈正相关性)
留存分析(用户活跃度、留存率、新增用户数)
同期群分析(商品类目或商品ID)
读者也可以针对分析处理后的数据以可视化的形式展现,例如: matplotlib、 seaborn
参考文章:
淘宝用户行为数据分析_valkyrja110的博客-CSDN博客
基于客观事实的 RFM 模型(Python 代码)_Python_xiaowu的博客-CSDN博客_rfm模型python代码
【matplotlib】浅谈python图形可视化练习经验分享_inganxu的博客-CSDN博客
【数据分析案例】pandas + matplotlib 人货场+RFM+用户复购分析 电商水果销售_inganxu的博客-CSDN博客
Original: https://blog.csdn.net/weixin_46159679/article/details/126298178
Author: inganxu
Title: 【数据分析案例】基于Pandas分析天池大赛 – 淘宝用户行为数据推荐
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/677593/
转载文章受原作者版权保护。转载请注明原作者出处!