

目录
第六章 网络传播模型与机器学习框架
第一节 引言
研究在线社交网络中的信息传播主要有两种方法,一种是使用数学建模进行分析和仿真,另一种是使用实际数据进行数据挖掘和机器学习方法进行预测。使用第一种模型方法来研究信息传播主要有两个原因:一是信息传播过程非常复杂,不使用模型进行抽象和简化就很难研究;二是在早期的信息传播研究中,经验数据的收集、获取和存储都很困难,成本很高,使用模型方法大大降低了对数据的需求。
[En]
There are mainly two methods to study the dissemination of information in online social networks, one is to use mathematical modeling for analysis and simulation, and the other is to use actual data for data mining and machine learning method for prediction. There are two main reasons for using the first model method to study information communication: first, the process of information dissemination is very complex, and it is very difficult to study without using the model for abstraction and simplification; second, in the early research of information dissemination, the collection, acquisition and storage of empirical data are difficult, and the cost is very high, and the use of model method greatly reduces the demand for data.
基于机器学习的信息传播研究范式可以提高网络信息传播预测的准确性,加深对信息传播各个环节及其影响因素的理解。
[En]
The research paradigm of information communication based on machine learning can improve the accuracy of the prediction of network information dissemination and deepen our understanding of each link of information dissemination and its influencing factors.
第二节 信息传播模型
互联网信息传播是人类在社交网站和社交媒体上的一种复杂行为,受多种因素的影响和制约。基于社会网络的拓扑结构,一些信息传播模型被用来研究网络上的信息传播,这是早期信息传播研究中常用的方法。
[En]
The dissemination of information on the Internet is a complex behavior of human beings on social networking sites and social media, which is affected and limited by many factors. Based on the topological structure of the social network, some information dissemination models are used to study the information dissemination on the network, which is a common method in the early research of information dissemination.
一、创新扩散模型
一项新技术在社会系统中的扩散需要四个必要条件:创新、传播渠道、时间和社会制度。扩散是一种社会交换行为,扩散必然发生在具有结构性和功能性的社会系统中,扩散的过程可以是有计划的,也可以是自发的。
[En]
The diffusion of a new technology in the social system requires four necessary conditions: innovation, communication channels, time and social system. Diffusion is a kind of social exchange behavior, so diffusion must occur in the social system with structural and functional characteristics, and the process can be planned or spontaneous.
根据创新实体采纳者的采用时间,采纳者分为创新者、先行者、先行者、后采者和后进者五类。
[En]
According to the adoption time of innovative entity adopters, adopters are divided into the following five categories: innovators, early adopters, early adopters, late adopters and backwards.


1969年Bass提出的”Bass扩散模型”:


二、传染病模型
在典型的传染病模型中,个体在群体中的状态可分为以下几类:
[En]
In a typical infectious disease model, the status of individuals in a population can be divided into the following categories:
(1)易染状态S:个体在感染之前是易感状态,即该个体很可能被其他邻居个体感染。
(2)感染状态I:感染上某种病毒的个体就被称为处于感染状态,该个体还会以一定的概率去感染其他邻居个体。
(3)移除状态R:也被称为免疫状态或者恢复状态。当个体经历过一个完整的感染周期后,该个体就对病毒具有了免疫力,不再被其感染,因此就可以不再考虑该个体。
在疾病传播的传统经典模型中,一个基本假设是种群中的所有个体都是完全混合的,即一个个体在单位时间内与种群中的任何一个个体有平等的接触机会。然而,在社交网络的背景下,个人只能联系他的朋友(邻居节点),因此受感染的个人只能将病毒直接传播到与其直接相连的节点。
[En]
In the traditional classical model of disease transmission, a basic assumption is that all individuals in the population are completely mixed, that is, an individual has an equal chance of contact with any individual in the population per unit time. However, in the context of social networks, the individual can only contact his friends (neighbor nodes), so the infected individual can only directly transmit the virus to the nodes directly connected to it.
基本的传染病模型包括SI、SIS和SIR三种。
1.SI模型
SI模型在疾病传播中是最简单的情形,就是一个个体一旦被感染就永远处于感染状态。


SI模型中个体一旦被感染,就不会再恢复成易染状态,因此感染个体的数量是单调递增的。
将该模型应用到信息扩散中,易染状态表示用户尚未知晓信息,感染状态表示永不已收到信息并将信息发给好友。需要注意的是,在现实世界中,病毒的感染个体一般不会可能永远处于易染状态并且永远传染给别人,信息传播也不会这样,因此SI模型是一个最简单的疾病传播模型,但是描述疾病或信息传播时对于有些应用来说过于简略了。
2.SIR模型
在SIR模型中,节点除了由上述两种状态外,还有第3中状态——免疫状态,即用户受到感染被治愈后具有了免疫性,不再被感染,也不会感染其他节点。在信息传播中,免疫状态则表示用户虽已收到信息,但认为该信息不具有价值或对该信息不感兴趣,因此不会发给好友,这些用户成为信息扩散树中的叶子节点。通过不同状态的节点间的相互作用,节点的状态会发生变化,信息从而在整个网络中扩散。





3.SIS模型





上述方程中的稳态值在流行病学中也称为流行状态。
[En]
The steady state value in the above equation is also called epidemic state in epidemiology.
4.信息传播模型与疾病传播模型的区别和联系
信息传播和疾病传播之间有很强的相似性。长期以来,人们普遍认为,信息在个人之间的传播类似于病原体,每次接触到知道信息的朋友,都会潜在地导致其他个人被感染(即知道信息),而个人对反复接触信息的反应比想象的要复杂得多。
[En]
There is a strong similarity between information transmission and disease transmission. For a long time, it is generally believed that the spread of information between individuals is similar to pathogens, each time exposed to friends who know the information, it will potentially cause other individuals to become infected (that is, knowing information), and the individual’s response to repeated exposure to information is more complex than imagined.
同时,信息的传播与疾病的传播也存在着显著的区别,根植于人们对信息处理的认知局限。在病原体的传播中,朋友越多的人感染疾病的可能性越大,而这样的人在信息传播中感染的可能性更小。这是因为信息量随着用户关注的朋友数量的增加而增加,高联系的用户不太可能注意到特定的消息,他们往往需要比低价值用户更强的社交信号来采取行动。在早期的信息传播研究中,有很多学者使用疾病传播模型。随着人们对信息传播机制认识的深入和传播模型研究的精细化,利用疾病传播模型来研究信息传播的研究越来越少。
[En]
At the same time, there is also a significant difference between the spread of information and the spread of disease, which is rooted in people’s cognitive limitations in processing information. In the transmission of pathogens, individuals with more friends are more likely to be infected with the disease, while such people are less likely to be infected in the spread of information. This is because the amount of information increases with the number of friends a user follows, and highly connected users are less likely to notice a particular message, and they tend to need stronger social signals to take action than low-value users. In the early information communication research, there are many scholars who use the disease transmission model. With the in-depth understanding of the mechanism of information transmission and the refinement of the study of transmission model, there are fewer and fewer studies on the use of disease transmission model to study information transmission.
三、阈值模型
门槛模型,也被称为门槛模型,假设每个人在决定参加一项活动时都会越过门槛。这个门槛的存在是由行动的成本和收益决定的。当行为的成本等于收益时,就达到了行为的门槛。
[En]
The threshold model, also known as the threshold model, assumes that everyone crosses a threshold when deciding to participate in an activity. The existence of this threshold is determined by the cost and benefit of the action. when the cost of the action is equal to the benefit, it reaches the threshold of the behavior.
阈值模型可以用来分析社会影响(或人际角色)在信息传播中的作用。社会影响力是指朋友之间的相互影响,这种行为的“传染”是基于社会学习或模仿。社会影响力在社交媒体的信息传播中发挥着重要作用。
[En]
The threshold model can be used to analyze the role of social influence (or interpersonal role) in information dissemination. Social influence refers to the mutual influence between friends, and the “contagion” of this behavior is based on social learning or imitation. Social influence plays an important role in the information dissemination of social media.

对于信息传播,对于每个消息转发器,当他转发消息时,我们还可以计算他的朋友转发消息的比例,这是节点的扩散阈值(或扩散阈值)。
[En]
For information dissemination, for each message forwarder, when he forwards the message, we can also calculate the proportion of his friends who have forwarded the message, which is the diffusion threshold (or diffusion threshold) of the node.
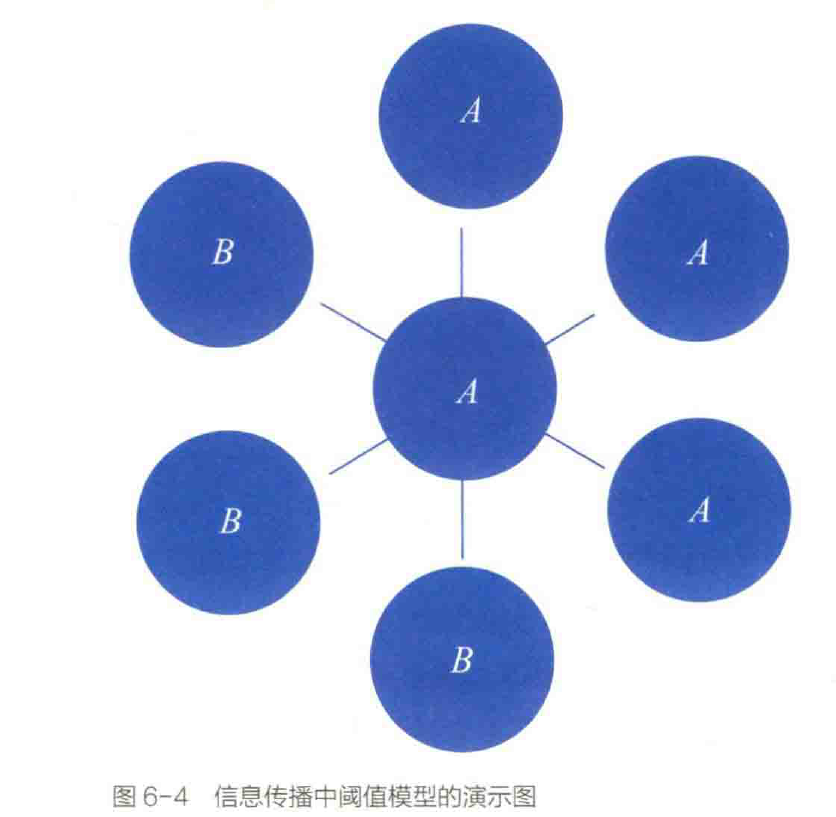
扩散阈值可以被定义为当消息转发器被转发时用户已经接触到消息的次数,即用户已经转发消息的朋友的数量。
[En]
The diffusion threshold can be defined as the number of times the user has been exposed to the message when the message forwarder is forwarded, that is, the number of friends of the user who have forwarded the message.


一个普遍的直觉是不同种类的信息在网上传播的模式不同。研究发现关于在政治上有争议的话题特别具有持续性,反复的暴露对于采纳持续性具有非常大的边缘效应。复杂的传播是原理假定,当一个思想在某些方面有争议时,反复暴露该思想对于其传播是至关重要的。相反,Twitter中跟习语和新词语相关的标签没有持续性,相对于第一次暴露,多重暴露所带来的的影响迅速衰减。
四、级联模型
在这个模型中,当一个个体变得活跃时,他邻居中每个不活跃的个体都会以一定的概率被激活。一个简单的例子是独立级联模型,在该模型中,每个初始活动节点产生自己的独立扩散级联,这些扩散级联彼此独立且不相互干扰。在该模型中,个体被最近的活动邻居激活的概率与过去试图激活它的邻居集的概率无关。
[En]
In this model, when an individual becomes active, every inactive individual in his neighbor will be activated with a certain probability. A simple example is the independent cascade model, in which each initial active node produces its own independent diffusion cascade, which is independent of each other and does not interfere with each other. In the model, the probability of an individual being activated by a nearest active neighbor is independent of the probability of the neighbor set that tried to activate it in the past.
网络上的传播动力学理论研究表明:存在一个传播阈值,在阈值一下传染病不会蔓延,而在阈值之上传染病会传播到网络中显著比例的个体。信息扩散相对于疾病传播的一个明显的区别是当信息传给某个体时,该个体是否要将信息传播出去设计个体的决策过程,而疾病传播中则不存在这样的过程。在信息扩散中,尽管在一个社群中感染机会可能有很多个,但是人们在这种重复暴露的情况下变成信息传播者的概率仍可能很低,对于强聚类网络这种效应变得更加明显,最终严重削减了信息在Digg中传播的规模。
五、分支过程模型
信息源将信息发送给朋友,而朋友又将信息发送给他们的朋友,继而继续下去,发送的朋友数量满足特定的分布。
[En]
An information source sends information to friends, who in turn send information to their friends, which in turn goes on, and the number of friends sent meets a specific distribution.

分支过程的基本属性之一是,如果一代人不再传播消息,消息将消失。因此,分支流程模型实际上只有两种可能的信息扩散:一种是没有人继续传播信息,所以有限的步骤之后信息就消失了;另一种是人们继续传播信息。这一过程在社交网络上无限期地继续下去。
[En]
One of the basic properties of the branching process is that if a generation of individuals no longer propagate the message, the message will disappear. Therefore, the branch process model actually has only two possibilities of information diffusion: one is that no one continues to spread information, so the information disappears after a limited number of steps; the other is that people continue to spread information. This process continues indefinitely on the social network.
从基本再生产数看,信息扩散至少与两个因素有关:一是网络的结果,二是人们传播信息的意愿。
[En]
From the basic reproduction number, information diffusion is at least related to two factors: one is the result of the network, and the other is people’s willingness to spread information.
信息的传播与人类行为的异质性有关,是由参与者的决策驱动的,因此其传播动力学将不同于传统的传染病模型。
[En]
The diffusion of information is related to the heterogeneous patterns of human behavior and is driven by the decisions of the participants, so their transmission dynamics will be different from the traditional infectious disease models.
第三节 信息传播的机器学习分析框架
要分析特征与信息传播的关系,传统的研究方法是进行回归分析,首先计算网络中的单个特征统计量,然后使用特征统计量来拟合网络中的信息传播指数。该方法没有考虑类内和类间特征统计量的相互关系和影响,不同网络之间的结果不具有可比性。基于机器学习的信息传播预测框架,首先计算经验网络的多类别和多特征统计量,即特征工程,然后计算各特征统计量的影响和相互关系,即特征选择。并对静态统计、加权统计和动态统计进行了系统、全面的分析,选出了最优的特征选择方法。最后,利用有监督的二分类或回归机器学习算法实现信息传播预测。
[En]
To analyze the relationship between features and information dissemination, the traditional research method is to carry out regression analysis, first calculate a single feature statistic in the network, and then use the feature statistics to fit the information dissemination index in the network. This approach does not take into account the interrelationship and influence of intra-class and inter-class feature statistics, and the results between different networks are not comparable. Based on the information dissemination prediction framework of machine learning, firstly, the multi-category and multi-feature statistics of the empirical network, namely feature engineering, are calculated, and then the influence and interrelation of each feature statistics, namely feature selection, are calculated. and the static, weighted and dynamic statistics are analyzed systematically and comprehensively, and the best feature selection method is selected. finally, the information dissemination prediction is realized by supervised two-classification or regression machine learning algorithm.
大数据背景下的信息传播预测研究包括四个步骤:数据采集与预处理、特征工程、特征选择和评价准则。对于数据获取,有两种主要的方法来分析主题的信息扩散。一种方法是描述包括一个主题在内的所有信息的扩散;另一种方法是只分析一条信息的完全扩散,并按时间顺序获得每个转发器的信息。以及在转发器之间转发报文,从而可以构建单个报文的扩散树。
[En]
The research on the prediction of information communication under the background of big data involves four steps: data acquisition and preprocessing, feature engineering, feature selection and evaluation criteria. For data acquisition, there are two main ways to analyze the information diffusion of a topic. One way is to describe the diffusion of all the information including a topic; the other is to analyze only the complete diffusion of a piece of information and get the information of each forwarder in chronological order. and the forwarding of messages between the forwarders, so that the diffusion tree of a single message can be constructed.

在许多研究中,主要集中在第二种方式来分析信息的传播,即描述单个信息传播的特征。除了描述一条消息的许多方面外,我们还可以分析影响信息传播的各种因素。
[En]
In many studies, it mainly focuses on the second way to analyze the dissemination of information, that is, to describe the characteristics of a single piece of information diffusion. In addition to describing many aspects of a single message, we can also analyze the various factors that affect the dissemination of information.
第四节 影响信息传播的其他因素
一、用户地理位置
随着智能手机的普及,在线社交网络中的空间信息变得越来越容易获得,本地信息对于定向营销和个性化服务变得越来越重要。新闻每天通过社交网络在城市之间传播,用户好友的空间位置将极大地影响信息将传播到的区域。因此,一些用户可以比其他用户更容易、更有效地传播到特定的地理区域。传统社会网络研究中的一些度量可以扩展到空间社会网络,如空间度、空间紧致度中心度、空间效率和局部聚集系数。这些衡量标准可以定量地描述社会关系对一个地区信息传播的影响。
[En]
With the popularity of smart phones, spatial information in online social networks has become more and more accessible, and local information is becoming more and more important for targeted marketing and personalized services. News spreads among cities every day through social networks, and the spatial location of users’ friends will greatly affect the area to which the information will be diffused. as a result, some users can spread to a particular geographical area more easily and more effectively than other users. Some metrics in traditional social network research can be extended to spatial social networks, such as spatial degree, spatial compactness centrality, spatial efficiency and local clustering coefficient. These measures can quantitatively describe the impact of social connections on the diffusion of information in a region.
在新浪微博上,我们也很容易发现不同地理位置的用户对不同的地域突发事件的关注程度有很大不同,不同地域的用户对于统一信息关注的内容也是不一样的。
二、信息自身属性
信息本身的属性会影响社会网络中的信息传播。不同种类的信息在网络上传播的模式不同。

我们发现政治类和运动的持续性指数值较高,而习语和音乐的则较低。一方面,这表明控制与政治类和运动相关标签的传播机制相对于均值更具有持续性,反复暴露于使用这些标签的用户之下会正面影响一位用户最终使用该标签的概率。另一方面,对于习语和音乐,反复暴露的影响与平均相比相对于峰值会迅速下降。
在没有直接的面对面互动和缺乏非语言信息的情况下,情绪仍可以在社交网站中进行传播。
虽然用户的活跃度和粉丝的数量对于趋势的创建和传播贡献不大,但是社会网络中的用户对主题内容的共鸣在引起趋势形成方卖弄担当了主要角色。也就是说,其他用户的转发对于引发趋势至关重要,这些转发更多的是跟分享的内容而不是用户的属性相关。
三、用户属性
用户自身的属性会影响社会网络中的信息传播。
不同类型的用户在信息扩散中扮演不同的角色。一方面,对于任何主要的主题,大众媒体在将消息传播给绝大多数受众方面扮演了极其重要的角色,它们有很多粉丝,它们的连接被很好地互惠,在收集其他用户各种各样的观点方面具有拓扑上的优势,它们的微博即使没有其他有影响力用户的帮助,也可以直接传播到大量的受众那里。另一方面,不同于传统媒体,Twitter中的大众媒体并不是第一个报告事件的,事实上在某些情况下往往是那些连通度不高的草根或传教士引发了新闻或谣言的扩散,即便是在没有大众媒体报告这些主题的情况下。
四、用户间趋同性
用户间的趋同性也会影响信息扩散。Twitter中用户属性之间的相似性可以显著地影响信息扩散速度,并且两者之间的关系与扩散信息的主题以及用以刻画扩散程度的参数密切相关。
在社会学中一个重要的观察结果是趋同性构成了个体的自我网络并影响了他们的交流行为,从而可能影响信息扩散的机制。属性趋同性的影响可以由那些可预测的特性在解释实际扩散和外部的时间变量方面的能力来定量刻画,在给定特定的度量和主题的情况下,趋同性属性可以影响信息扩散的可预测性。在大多数情况下相对于不考虑趋同性,属性趋同性可以在预测实际的扩散和外部趋势方面提高15%~25%的性能。借助于趋同性,在预测扩散特性方面相对于基线技术可以提高13%~50%的性能。
社会网络中同伴影响和趋同性均会对信息扩散产生影响,但二者的权重有所不同。随着时间变化,节点的属性和行为往往与社会网络结构密切相关,虽然连在一起的节点间的同配混合和行为的时间簇被用来支持网络中的同伴影响和社会扩散,趋同性也可能解释这些现象。

五、用户活跃时间
用户的转发行为具有特定的时间分布,因此,用户的活跃时间因素也是影响微博信息流行度的主要因素。对用户活跃时间的分析,有助于在线营销以及信息传播预测。
在社会网络中用户的活动模式,比如阵发式的活动模式,也会对信息扩散动力学产生影响。用户相应时间上高度的异质性是在集体层面信息传播缓慢的主要原因,也就是说用户活动的高异质性可控制信息传播。

人的交流活动具有阵发特性,且经常发生在群组对话中。人际交流的阵发特性和存在群组对话是理解社会网络中信息扩散的两个主要的动态组成部分,这两种竞争性的特性对于信息扩散会产生两种对立的影响:阵发特性阻碍了信息大范围的传播,而群组对话则有利于小范围的快速信息级联。
第五节 特征选择方法
特征选择是指从原始特征集中选择出能使某种评价指标最优的特征子集。其目的是剔除冗余特征,从而达到减少特征个数、缩短模型训练时间和提高模型精确度的作用,使分类或回归任务能够达到接近或优于特征选择之前的预测结果。
可采用最大信息系数和基于模型的特征排序这两种特征选择方法来对特征工程得到的特征进行筛选。其中,基于模型排序可以直观地看出各个特征在模型训练中的重要性;MIC可以得到特征之间的相互关系,从而剔除影响较小和相似性高的冗余特征。通过使用基于模型的特征排序方法和最大信息系数衡量特征之间的关系,不但可以降低维数,降低计算量,而且降维后得到了与特征选择之前接近的预测结果。
一、基于XGBoost模型的特征排序
特征选择方法大致可以分为过滤法和封装法,这两种方法的主要区别在于特征选择与机器学习分类算法的结合方式不同。过滤法是将所有的特征作为初始的特征子集,然后采用与类别相关的评价指标来衡量特征对类别的区分能力,由于特征选择过程独立于分类过程,过滤方法仅依靠数据的内在属性来评估特征的相关性。这种方法的关键就是找到一种能度量特征重要性的方法,如Pearson相关系数,信息论理论中的互信息等。封装法是将模型假设搜索加入到特征选择过程中,即搜索算法被”封装”到分类模型中,是以达到最大分类准确率为引导的一类特性选择方法。
在封装模型中,分类算法被当作一个黑盒用来评价特征子集的性能,其特征选择利用分类学习算法的性能来评价特征本身的优劣。因此,对于一个待评价的特征子集,封装法需要训练一个分类器,根据分类器的性能对该特征子集进行评价。
XGBoost是eXtreme Gradient Boosting的简称,它是Gradient Boosting Machine的一个C++实现。它不同于传统的GBDT,只利用了一阶导数的信息,而XGBoost对损失函数做了二阶泰勒展开,并在目标函数中加入了正则项,整体求最优解,用以权衡目标函数和模型的复杂程度,防止过拟合。除理论与传统GBDT存在差别外,XGBoost的设计理念主要有如下几个优点:速度快、可移植、少写代码、可容错。
基于模型的特征排序方法,主要是根据算法模型的预测性能来评价特征子集的优劣。借用XGBoost机器学习算法,可以在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性。在XGBoost算法中,特征评分可看成是被用来分离决策树的次数,特征的评分越高,则说明该特征越重要,对于算法性能的影响越大。
二、基于最大信息系数的特征相关性分析
Pearson相关系数已被广泛应用于基于向量空间模型的文本分类和用户喜好推荐系统中,其定义为:

最大信息系数定义如下:

MIC具有普适性、公平性和对称性的优点。
MIC度量具有均衡性。
MIC度量具有对称性。
第六节 信息传播的机器学习评价指标
一、分类问题的评价指标
1.混淆矩阵
混淆矩阵,又被称为错误矩阵,通过它可以直观地观察到算法的效果。

2.准确率
准确率,又叫阳性预测值,考察转发预测模型的准确性。在模型预测为正类的样本中,真正为正类的样本所占的比例。其数学公式为:

一般情况下,查准率越高,说明模型的效果越好。
3.召回率
召回率,又叫查全率,主要衡量的是在所有真实正样本中,分类器中能找到多少。

4.F1值
F1值是准确率和召回率的综合度量指标,其数学公式为:

5.精度


一般情况下,模型的精度越高,说明模型的效果越好。
二、回归问题的评价指标
一般来说, 回归分析是通过规定因变量和自变量来确定变量之间的因果关系,建立回归模型,并根据实测数据来求解模型的各个参数,然后评价回归模型是否能很好地拟合实测数据。如果能够很好地拟合,则可以根据自变量做进一步预测。
1.均方误差
均方误差是参数估计值和参数真实值之差平方的期望值,它可以说明预测模型和实验数据之间的温和程度。

2.均方根误差
均方根误差是均方误差的算术平方根,它能够更好地反映预测值误差的真实情况。

3.平均绝对误差
平均绝对误差是绝对误差的平均值,它也是反映预测误差实际情况的一个统计量。

4.平均绝对百分比误差

第七节 基于实证数据的信息流行度预测
一、实证数据的说明
一条微波发出去以后,只需要观察其在之后一小段时间内的转发情况,它的传播规模便可以被预测。
二、网络特征的分析
发微博节点的社会影响力对于微博信息的流行度具有很强的影响,社会影响力是一个用户影响他人的观点、情感和行为的现象,在社会网络上可以使用一些网络特征来进行刻画。

三、其他类别特征的分析

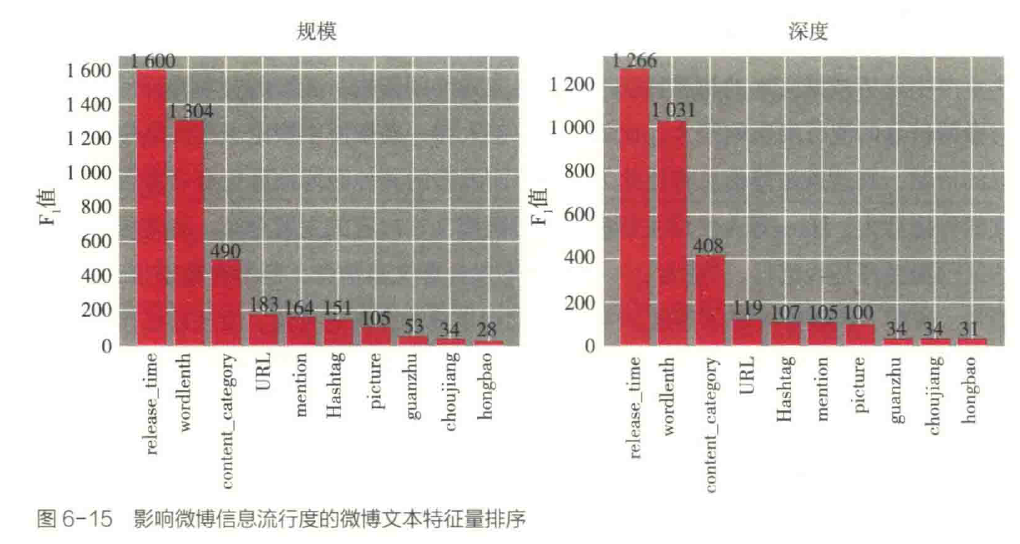

四、信息流行度的预测结果

本章小结
本章首先介绍了信息传播的几种经典模型,分别为创新扩散模型、传染病模型(SI、SIR、SIS)、阈值模型、级联模型与分支过程模型。上述介绍的模型虽然经典,但目前在研究中已很少直接应用,我们通常看到的都是它们的改进或扩展模型。此外,这几种模型都具有各自的特点,如分支过程模型侧重于信息扩散树、级联模型侧重于扩散过程中个体的激活状态与休眠态。没有一种模型是万能的,每种模型都有自己擅长的方面,同时也有自己的缺陷。因此要对信息传播进行建模时,必须根据自己的研究目的来选择合适的模型。
在模型中往往仅考虑影响信息传播的主要因素,而现实中影响信息传播的因素非常多。在社会科学领域,往往利用统计的方法来研究影响信息扩散的诸多因素,最常见的是使用回归模型。一般我们会挑选影响信息扩散的一些潜在因素,通过对回归模型的分析进而获得每种因素在影响扩散中的权重或重要性。而在自然科学领域,常用的方法是构建一套涉及特征工程、特征选择和评价标准的机器学习框架。
针对特征工程,本章介绍了在社会网络中可以对信息传播产生影响的因素。这些因素除了网络结构特征外,也包含了用户地理位置、信息自身属性、用户属性、用户间趋同性、用户活跃时间等多方面的特征。特征选择方法是要计算各个特征统计量的影响力和相互关系,并对静态、加权、动态统计量进行系统全面的分析,本文主要采用了基于XGBoost模型的特征排序和基于最大信息系数的特征相关性分析两种方式。前者看出各个特征在模型训练中的重要性,后者可以得到特征之间的相互关系,从而剔除影响较小和相似性高的冗余特征。在信息传播预测方法准确性方面,最终要通过评价标准来实现,因此本文将用户传播行为预测对应为分类问题、信息流行度预测对应为回归问题,基于机器学习框架和信息传播相结合提出一套指导性评价框架体系。最后,通过一个实例说明了如何基于该框架进行真实的信息传播预测。
本章提出的研究框架是通用的,不仅可以用在信息传播中,也可以用在其他计算社会科学的研究中。通过这一通用研究范式,相信未来会揭示出信息传播过程中同类别特征和不同类别特征间更多引人入胜的联系。我们的初步结果发现,在信息扩散中,社会网络结构提供了传播的平台,信息属性刻画了自身的吸引力,用户属性刻画了用户的偏好性、活动性和影响力,而用户行为则刻画了他们的行为模式。在这些因素中网络结构和用户行为模式往往较易刻画,但信息属性和用户属性不易计算,且二者都是多维度的属性。信息属性中不仅包含了主题类别,也包括了信息的感情色彩、蕴含的情绪和信息来源,用户属性中既包含了用户特征的多维度度量,也包括了用户间的关系类别。此外,信息与用户之间会产生相关性,最显著的是用户对信息的亲和性,每位用户都有自己特别感兴趣的信息,也要丝毫不感兴趣的信息。今后,对信息属性和用户属性的刻画和度量将是研究的重点和难点。
Original: https://blog.csdn.net/weixin_44850744/article/details/123908234
Author: feiwen110
Title: 《计算传播学导论》读书笔记:第六章 网络传播模型与机器学习框架
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/527777/
转载文章受原作者版权保护。转载请注明原作者出处!