

论文名字最后还有个recognition,受限于题目长度。
本文的作者是 Ruirui Li, Chelsea J.-T. Ju, Zeya Chen, Hongda Mao, Oguz Elibol, Andreas Stolcke,Amazon, USA
研究动机
本文做的是说话人识别(测试的时候用一句话测试,可以得到是那个人说的话,即说这句话的人),本文主要是将文本相关和文本不相关的说话人识别技术融合在一起。提出的模型叫做FOEnet。
INTRODUCTION
介绍了一下什么是说话人识别以及文本相关和文本不相关模型。TD(文本相关模型)将声学信号和说话人的相关语音片段计算一个分数,分数越高,相关性越强,越能证明要测试的语言是和说话人有关系。TI(说话不相关模型)也是将一句话或者没有弱音词的部分和说话人的语句对比产生匹配分数。这两个模型是用不同的数据集和不同的模型训练的。如果这2个模型都可以用,就可以去提高它们的精确度和。但是需要关注三个点:第一,给一定范围的融合方法,不能明确那个方法是最好的;第二,2个系统的输入,尤其是TD系统,有可能也不能用。第三,说话者的嗓音是不断变化的,反过来可能会影响2个系统融合之后的平衡。之后说了一些别人是怎么做的。
模型结构
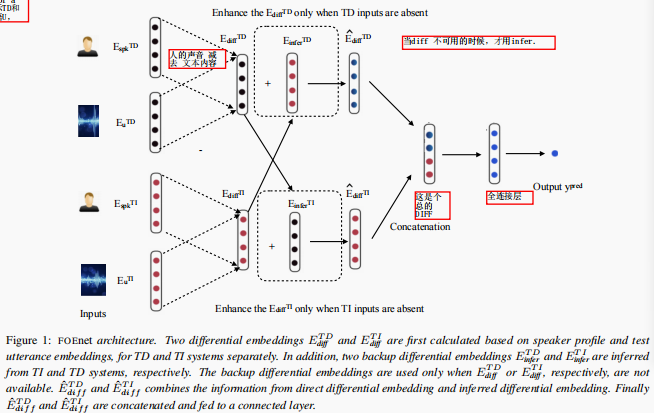

实验数据和操作
输入的是VAD后的40维的梅尔频谱,用的是现有的说话人识别模型,将5000小时的数据用到说话人识别模型中,和四个基本的模型做对比。
下图的结果不同的区别在于数据集不一样。
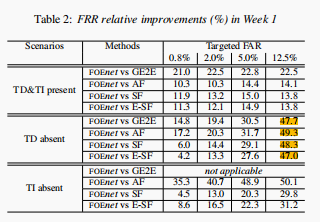
评价指标
false accept rate (FAR) 和false reject rate (FRR)

结论
提出了一种实现说话人识别的新结构。其效果要好于四种比较模型。
[En]
A new structure is proposed to realize speaker recognition. The effect is better than the four comparative models.
生词
voice assistants 语音助手
posit 假定
trade-off 权衡
Original: https://blog.csdn.net/qq_46079584/article/details/122586746
Author: qq_46079584
Title: 《Fusion of Embeddings Networks for Robust Combination of Text Dependent and Independent Speaker 》
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/526502/
转载文章受原作者版权保护。转载请注明原作者出处!