

YOLOV5 中文Github网址:
https://github.com/wudashuo/yolov5
YOLOV5相关文件百度网盘连接:
链接: https://pan.baidu.com/s/19Mo5bnLEGXiegc3f2KOnyg 密码: 5av1
–来自百度网盘超级会员V3的分享
首先要确保自己安装了显卡驱动,cuda和cudnn
可以参考这位博主的文章
https://blog.csdn.net/qq_34496399/article/details/105770053
贴一下我这里的版本


当安装好后要安装OPENCV
先打开Ubuntu商店搜索Cmake安装
将下载好的OpenCV-4.5.1源码解压到主目录下,并在OpenCV-4.5.1中新建build文件夹
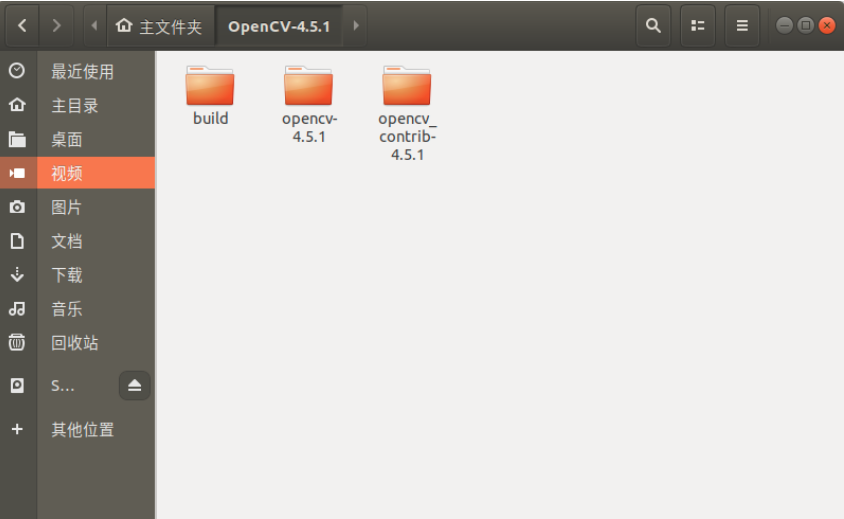
打开CMake,选择源码路径以及编译路径,并勾选Grouped和Advanced
点击Configure,选择Unix Makefiles ,勾选Use default native compilers
点击Configure
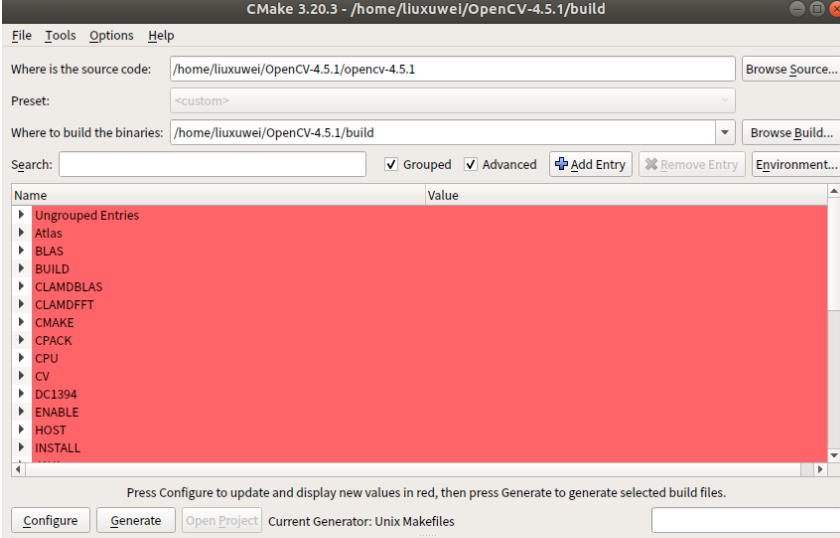
搜索OPENCV_EXTRA_MODULES_PATH,路径选择OpenCV4.5.1/opencv_contrib-4.5.1/modules
搜索cuda,勾选WITH_CUDA和OPENCV_DNN_CUDA
搜索NONFREE ,勾选OPENCV_ENABLE_NONFREE
点击Configure,会有自动下载一些文件。
但是由于网络原因,会下载失败,需要手动下载,打开/OpenCV-4.5.1/build/CMakeDownloadLog.txt,搜索文件内的cmake_download,找到要下载的文件的链接,复制链接,使用迅雷下载。
将下载好的文件复制到/OpenCV-4.5.1/opencv-4.5.1/.cache/下的对应文件夹内。
重新执行Configure,没有下载失败的报错后点击Generate。
然后终端进入OpenCV4.5.1/build
make -j8
sudo make install
接下来安装anaconda
可以参考下文博主的文章
https://blog.csdn.net/KIK9973/article/details/118772450
安装完成后
conda create -n YOLO5 python=3.7
打开终端,进入创建的anaconda环境
conda activate YOLO5
pip3 install -r requirement.txt
这里会自动下载需要的库
如果下载速度过慢或下载失败,可以选择其他源下载,比如指定清华源:
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
通过以上步骤,Yolo v5运行所需的环境就已经配置好了,接下来就可以进行简单的测试。在yolov5-master文件夹下打开终端,然后运行以下命令:
python3 detect.py --source 0
file.jpg
file.mp4
path/
path/*.jpg
rtsp://
http://
这里的含义是把0换成下面的这些指令就可以去检测别的,比如换成图片路径即为检测图片。
如果没有指定权重,则会自动下载默认的COCO预训练权重模型yolov5s.pt,最终检测结果会保存在./runs/detect/文件夹中。
当然我们还可以指定权重文件,权重文件下载链接为,将下载好的权重文件放在yolov5-master/weights/文件夹中,下述命令使用yolov5m.pt去检测./data/image文件夹中的所有图片和视频,并设置置信度为0.5:
python3 detect.py --source ./data/images/ --weights ./weights/yolov5m.pt --conf 0.5
detect命令中可使用的参数及其含义如下:
--source 指定检测来源
--weights 指定权重,不指定的话会使用yolov5s.pt预训练权重
--img-size 指定推理图片分辨率,默认640,也可使用--img
--conf-thres 指定置信度阈值,默认0.4,也可使用--conf
--iou-thres 指定NMS(非极大值抑制)的IOU阈值,默认0.5
--device 指定设备,如--device 0 --device 0,1,2,3 --device cpu
--classes 只检测特定的类,如--classes 0 2 4 6 8
--project 指定结果存放路径,默认./runs/detect/
--name 指定结果存放名,默认exp
--view-img 以图片形式显示结果
--save-txt 输出标签结果(yolo格式)
--save-conf 在输出标签结果txt中同样写入每个目标的置信度
--agnostic-nms 使用agnostic NMS
--augment 增强识别
--update 更新所有模型
--exist-ok 若重名不覆盖
以上的步骤都是使用官方训练好的权重模型进行检测,如果我们想训练自己的数据集,就需要经过采集图片,标注图片和训练模型这三步。下面将会对这些步骤一一介绍。
这里采用VOC数据集训练,用自己的数据集也是一样,下面的代码都可以通用,只要文件结构一样即可。
如果要制作自己的数据集
pip3 install labelImg
labelImg
打开labelImg的界面选择打开目录,选择你数据集图片的目录,选择创建区块选择目标检测的位置
首先是下载VOC数据集
在网盘中有
下载下来之后
在如图所示的位置创建split_train_val.py
在这里input xml label path改为Annotations的路径
output txt label path改为ImagSet下的Main文件夹,下面会贴上我的示例
import os
import random
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
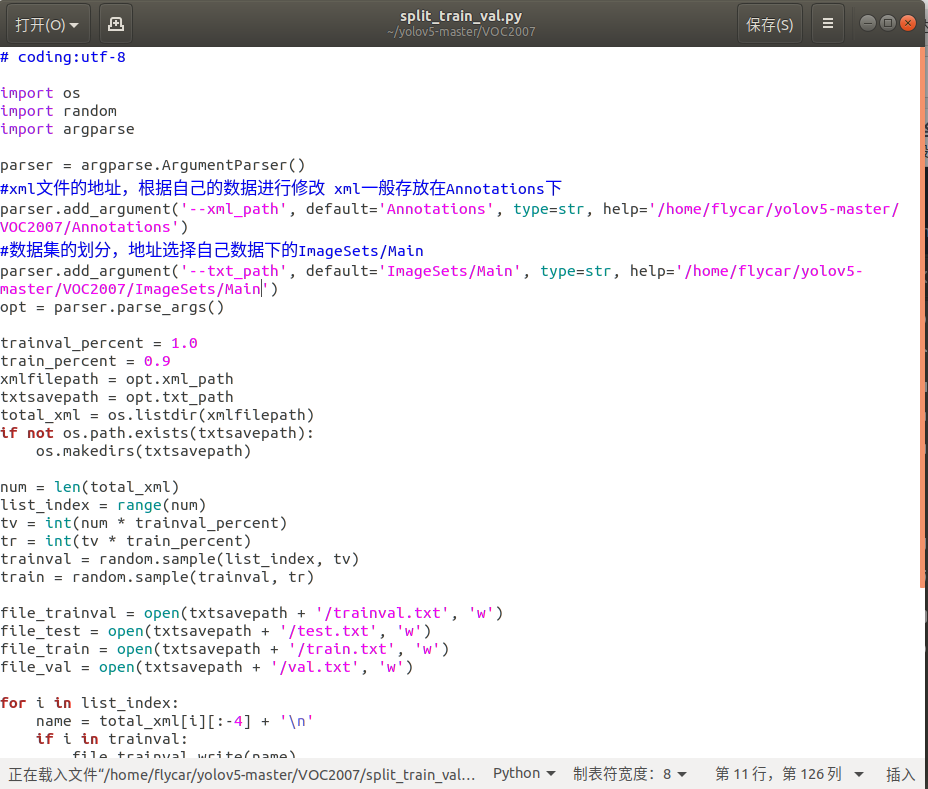
会在Main文件夹中生成四个文件
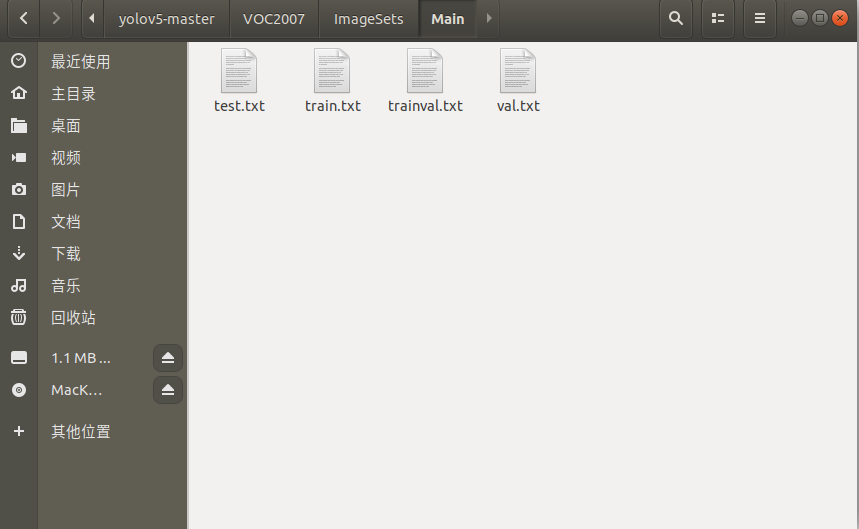
接下来在yolov5-master文件夹中创建voc_label.py
内容如下
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('/home/flycar/yolov5-master/VOC2007/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('/home/flycar/yolov5-master/VOC2007/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('/home/flycar/yolov5-master/VOC2007/labels/'):
os.makedirs('/home/flycar/yolov5-master/VOC2007/labels/')
image_ids = open('/home/flycar/yolov5-master/VOC2007/ImageSets/Main/%s.txt' %(image_set)).read().strip().split()
list_file = open('VOC2007/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/VOC2007/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
python3 voc_label.py
运行结果如下没有报错接下来就可以准备训练了
接下来配置data文件夹中的yaml文件,创建voc_my.yaml文件内容如下,train和val后面换成自己的地址
train: /home/flycar/yolov5-master/VOC2007/train.txt
val: /home/flycar/yolov5-master/VOC2007/val.txt
nc: 20
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
然后更改models 下的yolov5s.yaml文件
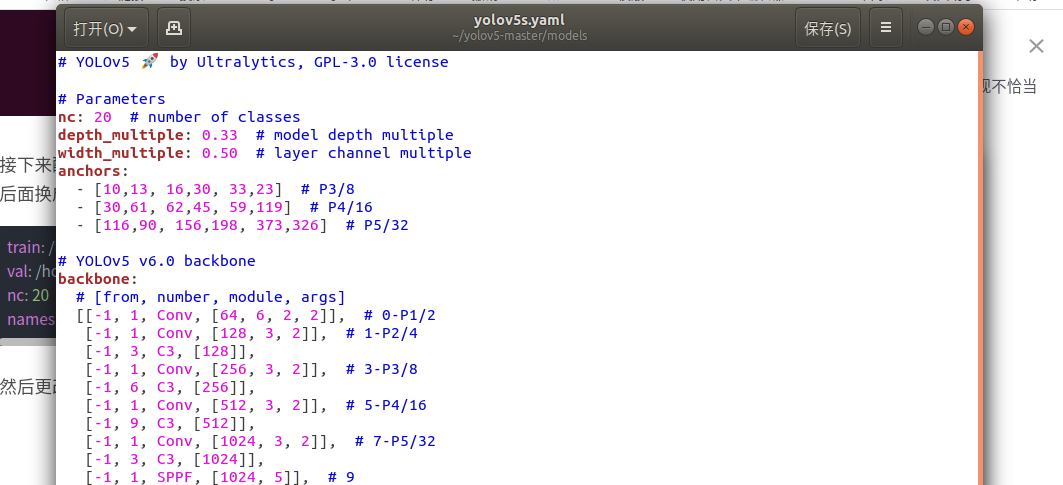
将nc改为自己的种类数,VOC为20
接下来执行:
python3 train.py --weights yolov5s.pt --img 640 --batch 20 --epoch 100 --data data/voc_my.yaml --cfg models/yolov5s.yaml
train命令中可使用的参数及其含义如下:
--weights 指定权重,如果不加此参数会默认使用官方预训练的yolov5s.pt
--cfg 指定模型文件
--data 指定数据文件
--hyp 指定超参数文件
--epochs 指训练完整数据的次数,默认300
--batch-size 指一次迭代训练的数据大小,默认16,官方推荐越大越好,用你GPU
能承受最大的。可简写为--batch
--img-size 指定训练图片大小,默认640,可简写为--img
--name 指定结果文件名,默认result.txt
--device 指定训练设备,如--device 0,1,2,3
--local_rank 分布式训练参数,不要自己修改!
--log-imgs W&B的图片数量,默认16,最大100
--workers 指定dataloader的workers数量,默认8
--project 训练结果存放目录,默认./runs/train/
--name 训练结果存放名,默认exp
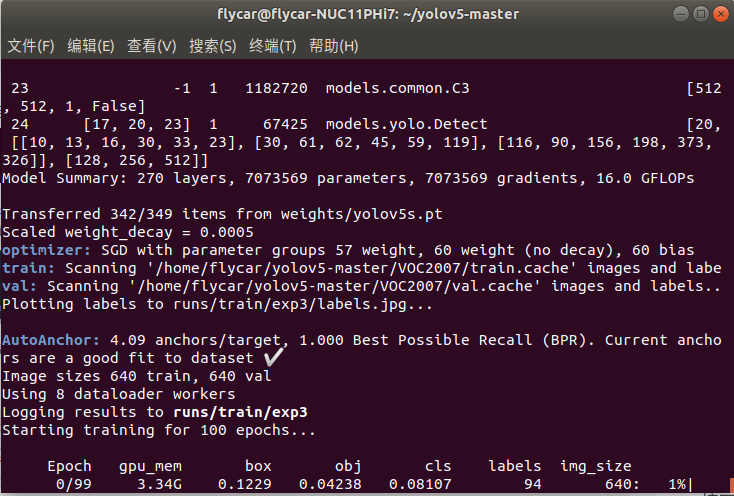
训练结果会保存在/yolov5-master/runs/train/exp里,权重在/yolov5-master/runs/train/exp/weights里,想要使用自己训练的权重进行检测可以
python3 detect.py --source (你的图片路径) --weights ./runs/train/exp/weights/best.pt
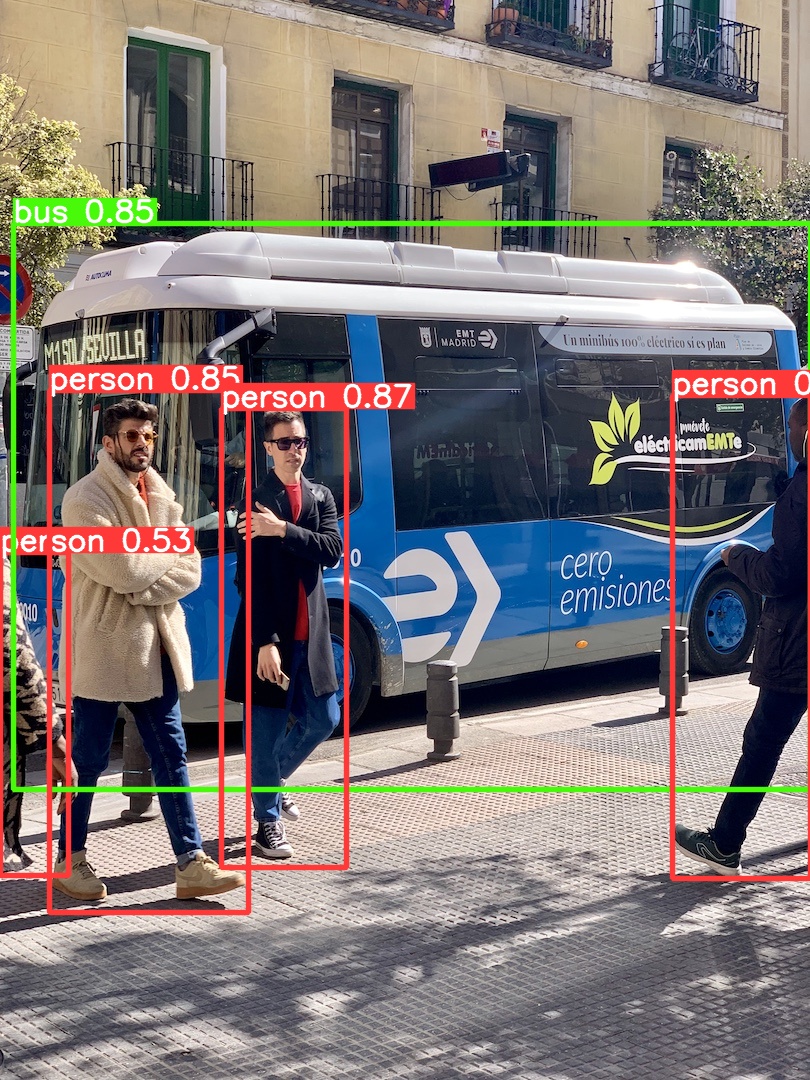
参考文章:
https://blog.csdn.net/weixin_43563233/article/details/114385130?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164553073716781685397702%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=164553073716781685397702&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-2-114385130.first_rank_v2_pc_rank_v29&utm_term=ros+yolov5&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_36756866/article/details/109111065Original: https://blog.csdn.net/weixin_51543864/article/details/123269015
Author: day_day_up !
Title: ubuntu18.04(LINUX)运行YOLOV5+训练VOC数据集/自己的数据集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558936/
转载文章受原作者版权保护。转载请注明原作者出处!