

问题描述:
我参考了Model Arts的例子
想要用MindSpore也实现语音识别,根据脚本迁移了网络。网络最后是调通了,但是Loss不收敛,训练得到的模型推理结果比预期长了一段。
有没有专家可以帮我们找出问题所在?
[En]
Is there any expert who can help us find out what the problem is?
一些额外的说明可能会更好地解决我遇到的问题。
[En]
Some additional instructions may better solve the problems I have encountered.
Model Arts上,是用两个网络组合完成语音识别的任务的:DFCNN+Transformer
首先构造了数据集get_data,可以把读取音频文件和标注的文本。
其思想是首先获取声音的时域信息,类似于下面的波形。
[En]
The idea is to get the time domain information of the sound first, which is like the following waveform.

然后compute_fbank做傅里叶变换,转换为语谱图。
数据可以用下面的代码可视化。我在附件中提供了代码,并将其注释掉。
[En]
The data can be visualized with this code. I provided the code in the attachment and commented it out.
frame_time = [i * 0.025 for i in range(x.shape[1])]
frequency_scale = [i *40 for i in range(200)]
print(frame_time)
print(frequency_scale)
plt.pcolormesh(frame_time, frequency_scale, x.squeeze().T)
plt.colorbar()
plt.show()
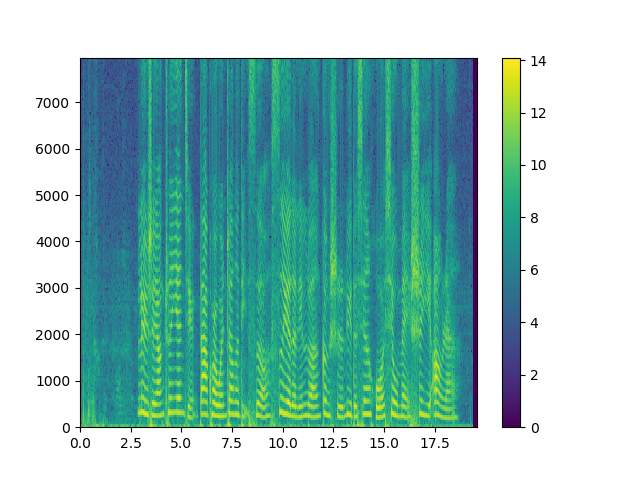
这样可以把ASR的任务转换成CV的任务。DFCNN的目的就是根据这个语谱图,识别其中的语音信息,得到拼音序列。
Transformer是NLP的网络,可以把拼音序列转成文字。
我主要是迁移了DFCNN的部分,本质还是CV类的网络,不过使用的损失函数是P.CTCLoss,是对整个序列求Loss值。可能问题出在这里,因为原来的脚本是keras写的,好像这个ctcloss的入参不一致。
问题现象:
训练我没有用全部的数据集,就拿了一个音频文件,想看看效果,但是Loss值到140左右就不动了。
loss值
177.98982,175.98216, 175.95705,……,146.96646,147.22882,147.1331
验证我也是用同样的那个音频,推理后还需要解码,我调用了P.CTCGreedyDecoder。这个推理得到的是拼音,我直接用匹配汉字的方法,输出的结果,前面对的上,后面跟了一段尾巴。
绿色是阳春烟幕的背景。四月,森林丘陵清新秀丽,诗意盎然(不止于此)。月亮、太阳和绿色的森林充满了风景。
[En]
Green is the background of the Yangchun smoke scene. In April, the forest hills are fresh, beautiful and poetic (this is more than that). The moon, the sun, and the green forest are full of scenery.
因为我使用keras的那个脚本,是可以训练收敛的,想知道是哪里对不上了。
使用的环境:
由于P.CTCGreedyDecoder只支持Ascend,脚本要在Ascend上执行。如果不推理只训练,可以用GPU。mindspore版本1.0以上好像都可以。
我还有几个建议
1.能不能提供一些供语音处理的算子,比如计算mfcc, spectrogram等,不然音频数据处理用python还是效率挺低的。
2.CTCGreedyDecoder,CTCLoss希望GPU,CPU都支持更好,比如我训练好,用自己电脑可以直接做推理。
3.mindspore是否可以提供读取音频文件的接口,像图片,文本都支持挺好,语音这块的能力希望也能补上。
脚本,训练数据见附件, 解压后有三个文件
- wav是音频文件,我就用一个试着训练
- dfcnn.py是我的脚本,里面一些路径设置,还要麻烦改一下
- data.txt是音频的标注文件。这个是从华为云上拿下来的,已经整理好的标注数据全集,不过如果只训练一个,只会读取一条,可以用head -n 1 data.txt看一下,第一句就是我希望得到的识别结果。
解决方案:
问题
看问题的现象,之前的领域是对的,说明培训应该有一定的效果,模式学到了一些东西。
[En]
The phenomenon of looking at the problem, the previous field is right, indicating that the training should have a certain effect, and the model has learned something.
这个模型本身我不是很熟,后续的尾巴猜测是不是需要设置一些blank标识,不代表任务结果,就是占位符。
因为Ascend上运行的大部分都还是固定shape的数据,这样必定长数据必然存在一些padding数据,对应结果也需要一个blank标识来对应padding占位。
改进
您的意见很好,我们会考虑逐步完善音频方面的支持,对应建议可以考虑反馈到Mindspore代码仓(
https://gitee.com/mindspore/mindspore)提一些Issue来反馈并记录。
Original: https://blog.csdn.net/weixin_45666880/article/details/126059739
Author: 小乐快乐
Title: MindSpore:【语音识别】DFCNN网络训练loss不收敛
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/525773/
转载文章受原作者版权保护。转载请注明原作者出处!