

1、什么是语义分割(semantic segmentation)?
图像语义分割,简而言之就是对一张图片上的所有像素点进行分类,将所有属于同一类的物体标记为同一像素点。


而今天要来介绍的则是第一个用卷积神经网络来做语义分割的方法——FCN。
; 2、FCN(Fully Convolutional Networks for Semantic Segmentation)
常见的卷积神经网络在多次卷积之后会接上若几个全连接层,将卷积和下采样产生的feature map映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率。常见的CNN网络如VGG、ResNet最后输出一个1000维的向量表示输入图像属于每一类的概率。
而FCN则将这些全连接层去掉,将其替换成常规的卷积层,然后上采样至原图的大小,输出预测结果。

对于开发者来说,最大的好处是改动小,从经典的分类网络改动至FCN,只需要替换全连接层就可以了。比如论文中的VGG16_FCN,只需要将最后的全连接层(4096, 1, 1), (4096, 1, 1)(1000, 1, 1)变为常规的卷积层(4096, 7, 7), (4096, 7, 7), (1000, 7, 7),然后再进行上采样至原图大小,这样通道数就代表了输出分类的个数,每个通道上对应的0则是不属于该类的像素点,1则是属于该类的像素点。

精度损失
当然这样也会精度的损失,FCN经过backbone压缩了32倍(经过5个stage)之后,如果直接上采样,势必在物体的边缘会出现不连续、不正确的问题。所以FCN的作者也提出了不同stage的输出进行特征融合,用浅层网络的输出补充位置信息,用深层网络的输出补充语义信息,这样就在一定程度上弥补了边缘的上的损失。
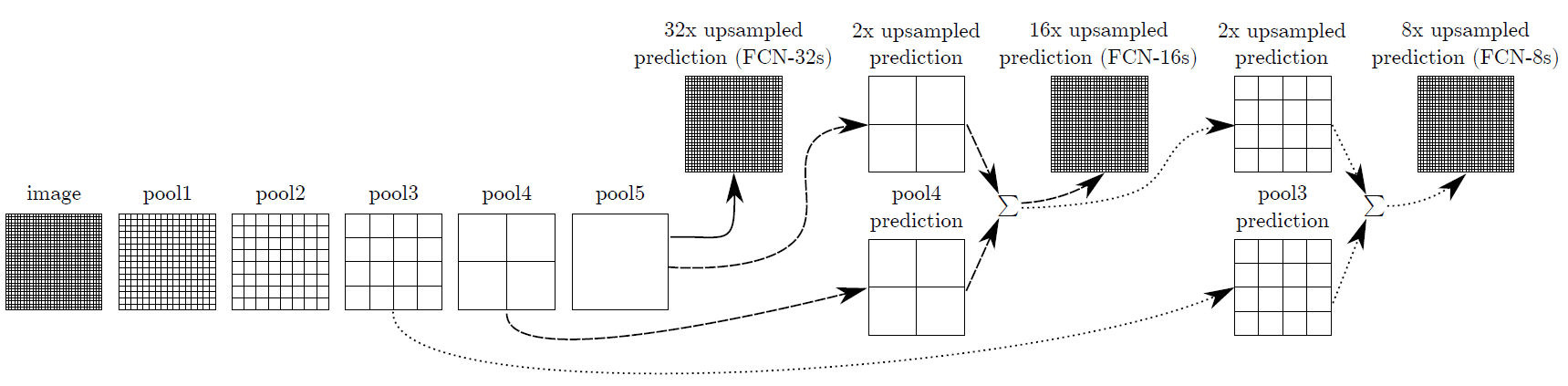
如上图所示,stage5的输出经过32倍upsample直接输出则是FCN32的结构,这种结构精度是最低的。FCN16则是stage5的输出经过2倍upsample与stage的输出直接求和,然后再经过16倍的upsample作为最后的输出,这个结构的精度会比FCN32要高。FCN8的精度则要更高一点。结果会在后面放上。
; 上采样的方式
目前上采样的方式有两种,一种是反卷积,另一种是双线性插值。据原作者公布的源码上来看,作者是用了双线性插值,并且他们自己也说了,经过他们的测试,准确度没有显著的差异性,双线性插值没有参数要学习,速度会更快一些。
损失函数
FCN是逐像素点预测的,因此对于每个像素点来说,Ground Truth不是0就是1,即使分割图像是单通道的(依据分类数给出索引),那也可以变成One-Hot的形式,例如VOC的label就是21通道的。
所以根据像素点的预测方式,使用交叉熵就可以了。当然,后人改进采用了dice loss、focal loss等,在这里就不展开论述了。
预测精度
FCN的预测精度如图所示:

; 3、总结
FCN是采用深度学习进行语义分割的第一人,对比现在很多新网络效果确实差了点。但是后面的网络多数是沿用了FCN的思想,在此基础上加一些trick或加一些新的组件。如果能把FCN搞懂,后面再看其他分割网络就轻车熟路了。
4、实现代码
- 原作者公布的代码shelhamer/fcn.berkeleyvision.org
- 个人的代码复现Runist/FCN-keras
- FCN的论文
Original: https://blog.csdn.net/weixin_42392454/article/details/118269765
Author: 热血厨师长
Title: FCN——语义分割的开山鼻祖(基于tf-Kersa复现代码)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/521631/
转载文章受原作者版权保护。转载请注明原作者出处!