

文章目录
train_test_split()用法
python机器学习中常用 train_test_split()函数划分训练集和测试集,其用法语法如下:
- X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state, shuffle)
变量描述X_train划分的训练集数据X_test划分的测试集数据y_train划分的训练集标签y_test划分的测试集标签 参数描述train_data还未划分的数据集train_target还未划分的标签test_size分割比例,默认为
0.25
,即测试集占完整数据集的比例random_state随机数种子,应用于分割前对数据的洗牌。可以是int,RandomState实例或None,默认值=None。设成定值意味着,对于同一个数据集,只有第一次运行是随机的,随后多次分割只要rondom_state相同,则划分结果也相同。shuffle是否在分割前对完整数据进行洗牌(打乱),默认为True,打乱
以sklearn库内置的iris数据集(鸢尾数据集)为例,首先获取数据:
获取数据
from sklearn.model_selection import train_test_split
dataset = load_iris()
这里的dataset数据是 sklearn.utils.Bunch类型的数据,比较像字典
将其打印出~
print(dataset)
如下所示
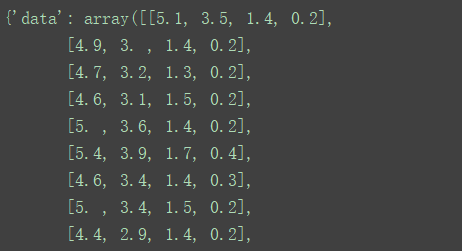

从中取出其data属性和target属性, X是特征数组(也称数据集),y表示类别数组(也称标签)
X = dataset.data
y = dataset.target
此例中,有四个特征(即data的4列表示4个特征),分别是鸢尾植物的萼片的长,萼片的宽,花瓣的长,花瓣的宽。
X中共150行,即150个样本,类别数据总共有150个数据(对应150个样本的类别)。
print(y)

y的150个数据如上图,其中,有0,1,2三个取值,表示三种花:
012Iris Setosa(山鸢尾)Iris Versicolour(变色鸢尾)Iris Virginica(维吉尼亚鸢尾)
使用最简单的离散化算法,以均值为阈值,使大于阈值的特征值为1,小于阈值的特征值为0.
attribute_means = X.mean(axis=0)
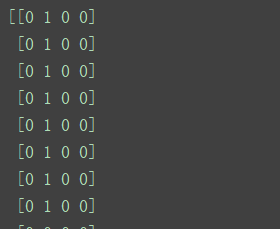
X_d = np.array(X >= attribute_means, dtype='int')
print(X_d)
运行结果(成功将X的数据转换为bool类型):
划分训练集和测试集
然后就是使用train_test_split()函数将数据划分训练集和测试集了。
random_state = 10
X_train, X_test, y_train, y_test = train_test_split(X_d, y, random_state=random_state)
print("There are {} training samples".format(y_train.shape[0]))
print("There are {} testing samples".format(y_test.shape[0]))

如图得到的数据中112/38接近3:1。分割成功!
完整代码脚手架
(将上述分步的代码写在一块儿方便复制使用):
from sklearn.model_selection import train_test_split
dataset = load_iris()
X = dataset.data
y = dataset.target
attribute_means = X.mean(axis=0)
X_d = np.array(X >= attribute_means, dtype='int')
random_state = 10
X_train, X_test, y_train, y_test = train_test_split(X_d, y, random_state=random_state)
Original: https://blog.csdn.net/weixin_48964486/article/details/122866347
Author: 侯小啾
Title: python机器学习 train_test_split()函数用法解析及示例 划分训练集和测试集 以鸢尾数据为例 入门级讲解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/672176/
转载文章受原作者版权保护。转载请注明原作者出处!