

Spark内核
RDD是基础,是spark中一个基础的抽象,是不可变的,比如我们加载进的数据RDD,如果想更改其中的内容是不允许的;分区的集合,可以并行来计算;RDD类中包含了很多基础的操作,例如map filter persist,RDD的数据是加载到内存中,使用persist可将内存中的数据持久化到磁盘中,也可以持久化到内存中。对RDD的一些算子操作放在PairRDDFunctions类中,比如groupByKey、join等
任何操作会通过隐式转换自动匹配任何类型的RDD
Resilient Distributed Dataset 弹性分布式数据集
每个RDD有五个主要的特性。RDD可以有副本,通过persist的方式持久化出副本。初始加载是没有副本的,初始加载到内存中只有一个。
五大特性(前3个特性每个RDD都有)
A list of partitions
每个RDD是由一组partition组成的
每个partition是在一个节点中连续的数据
在HDFS中存储的文件分为多个block块,每个block块对应一个partition
数据会遵循数据本地性,当spark使用HDFS中的数据文件时,文件的block在哪个节点,就会将该block加载到自身节点内存中,形成partition,供spark使用。
A function for computing each split
从数据的角度看一个partition对应一个split
并行计算如果对RDD进行map操作,会把map操作应用到每个partition上去
A list of dependencies on other RDDs
RDD会记着由谁产生,为了做容错,因为RDD是瞬时的转化,如果上个RDD存在,那么用上个RDD的数据接着计算,如果上个RDD不存在,那么再往前找
PairRDD依赖FilterRDD依赖HadoopRDD
RDD的生成在内存中,内存中的数据不稳定,如果宕机,数据就没了,spark会重算,spark是并行计算,partition:HadoopRDD-> FilterRDD ->PairRDD,如果计算过程中某条线出现了错误,那spark只会重新计算这条线,不会影响其他partition。
Optionally, a Partitioner for key-value RDDS
可对RDD重新进行分区,提高并行度,提高计算速度,分区多了,partition中的数据就少了,计算也就快了,有相应的算子。默认分区方式是对key取哈希取模,hash-partitioned,根据下游partition的数量,partition的数量是几就模几。
键值对的RDD可以自定义分区,所有RDD都可以进行分区
Optionally, a list of preferred locations to compute each split on
数据本地性
如果读HDFS中的block,一个block有三个副本,就有一个最优位置,但是如果读的是本地文件,就会随便放在某台spark节点,那么此选项就没用了
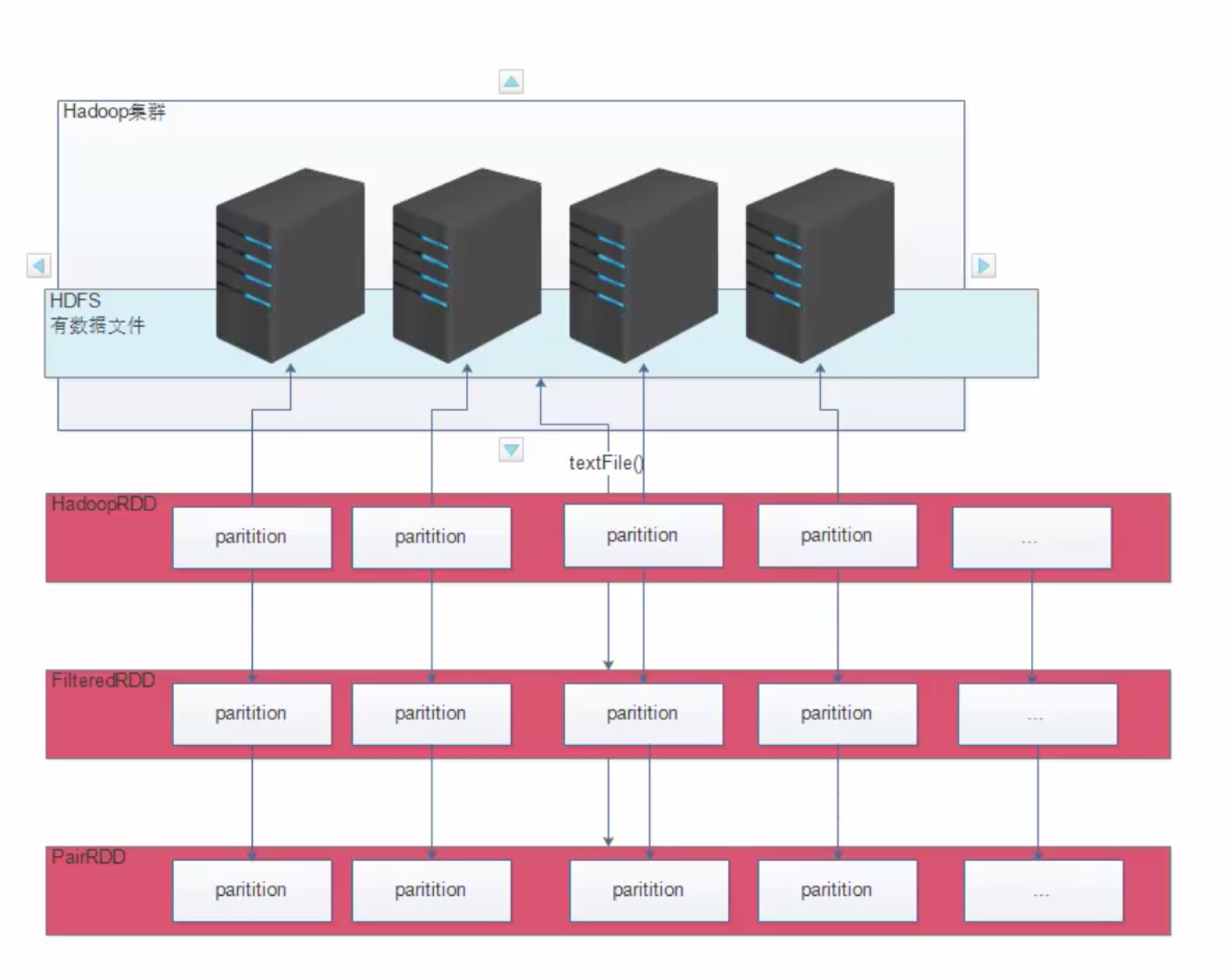

sc.textFile()将HDFS的数据封装到RDD,遵循数据本地性,HDFS中数据文件的block在哪台机器,就会加载到哪台机器的内存中。
partition是具体的概念,指在某个节点中连续的数据
RDD是抽象的概念
spark运行时

Driver:驱动程序,任务调度,发配当前的job任务,将任务切分为多个task,把task发到每个物理节点,task将每个物理节点的数据加载到对应机器的内存中,在内存中一条线的进行计算,将计算结果返回给驱动程序。不同的job,driver在不同机器上,这样才能做到分布式(mapreduce中的job)
流程示意
分布式文件系统(File system)–加载数据集
都是封装为RDD
transformations延迟执行—针对RDD的操作
所有操作都是针对RDD,每步转化成为算子操作
Action触发执行
碰到action就会将之前的代码封装为job,提交到集群中执行
代码示例

filter是transformation算子,延迟算子
count是action算子,立即执行。
碰到filter延迟算子,不先计算,碰到action算子会把前边的代码封装为job,提交到集群中进行运算。
errors.persist(); errors.cache();等价。
持久化在内存。如果RDD需要复用,需要持久化,以供后边代码使用。如果不持久化,那么计算http_errors时会重新计算之前的代码生成errors。
RDD是瞬时存在的状态,产生新的RDD,旧的RDD就没了。
Original: https://blog.51cto.com/u_15680746/5373939
Author: 蹦擦擦蹦
Title: SparkRDD内核
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/517480/
转载文章受原作者版权保护。转载请注明原作者出处!