

Hadoop之MapReduce02【自定义wordcount案例】
原创
文章标签 Hadoop MapReduce wordcount hadoop mapreduce 文章分类 Hadoop 大数据
©著作权归作者所有:来自51CTO博客作者波波烤鸭的原创作品,请联系作者获取转载授权,否则将追究法律责任
创建MapperTask
创建一个java类继承Mapper父类


接口形参说明
参数
说明
K1
默认是一行一行读取的偏移量的类型
V1
默认读取的一行的类型
K2
用户处理完成后返回的数据的key的类型
V2
用户处理完成后返回的value的类型
注意数据经过网络传输,所以需要序列化
数据类型
序列化类型
Integer
IntWritable
Long
LongWritable
Double
DoubleWritable
Float
FloatWritable
String
Text
null
NullWritable
Boolean
BooleanWritable
…
public class MyMapperTask extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
创建ReduceTask
创建java类继承自Reducer父类。

参数
说明
KEYIN
对应的是map阶段的 KEYOUT
VALUEIN
对应的是map阶段的 VALUEOUT
KEYOUT
reduce逻辑处理的输出Key类型
VALUEOUT
reduce逻辑处理的输出Value类型
public class MyReducerTask extends Reducer<Text, IntWritable, Text, IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int count = 0 ;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
创建启动工具类
package com.bobo.mr.wc;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WcTest { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(true); Job job = Job.getInstance(conf); job.setJarByClass(WcTest.class); job.setMapperClass(MyMapperTask.class); job.setReducerClass(MyReducerTask.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); }}
打包部署
maven打包为jar包
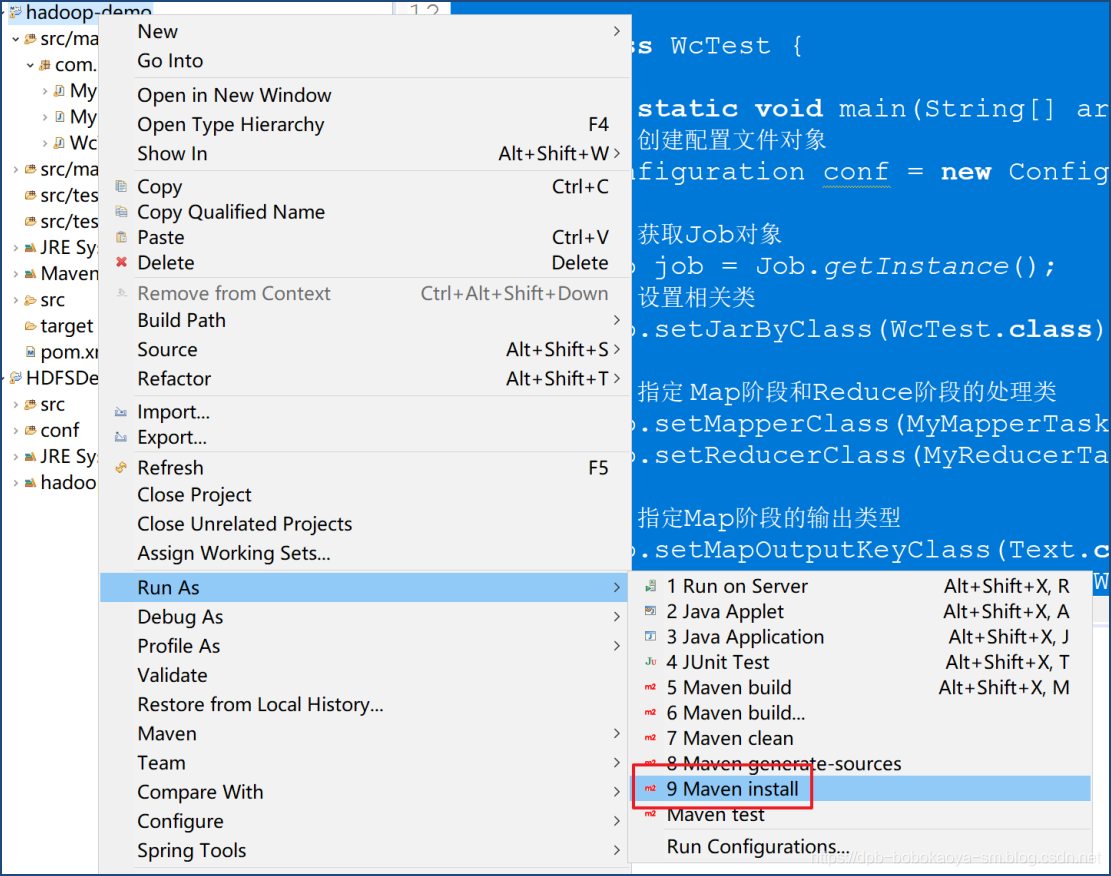
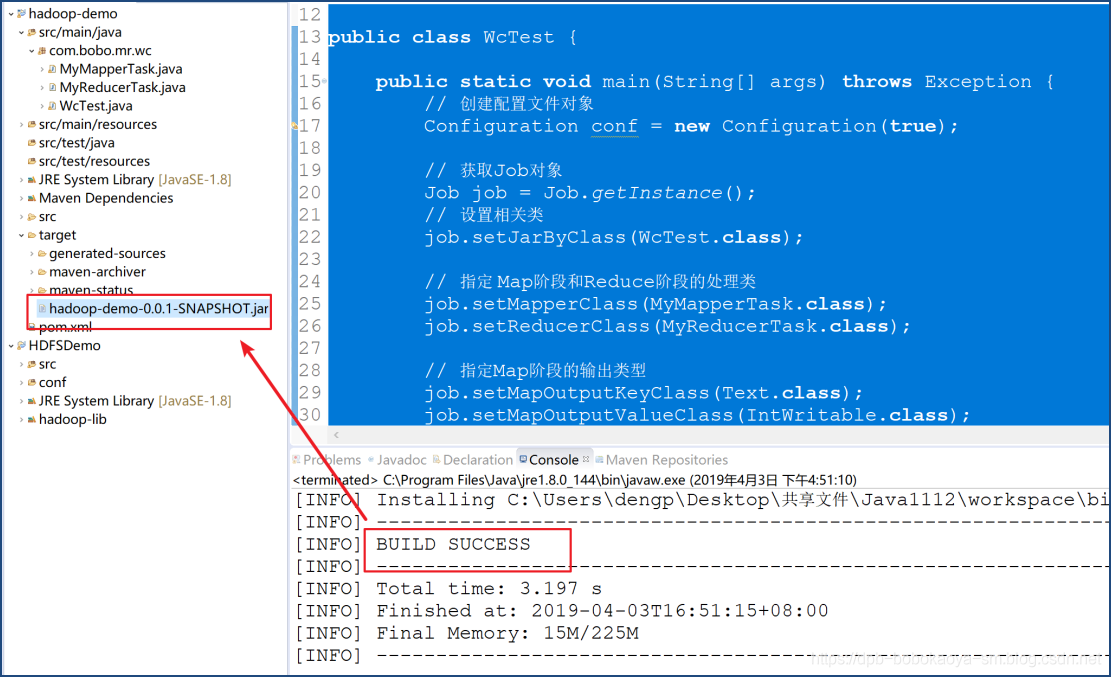
上传测试
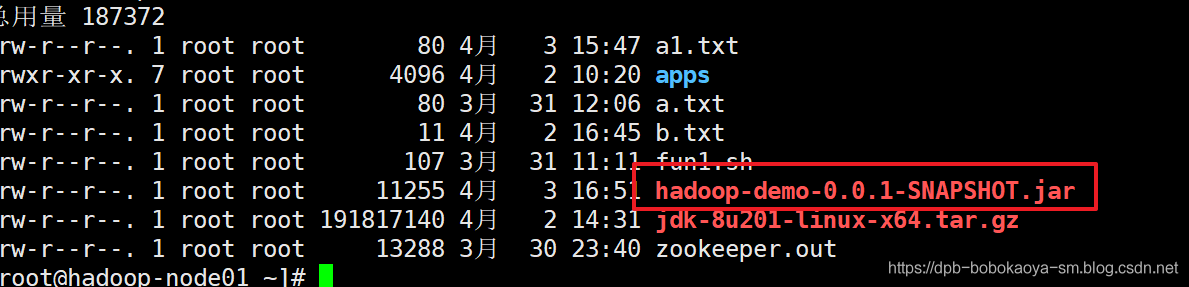
在HDFS系统中创建wordcount案例文件夹,并测试
hadoop fs -mkdir -p /hdfs/wordcount/inputhadoop fs -put a.txt b.txt /hdfs/wordcount/input/
执行程序测试
hadoop jar hadoop-demo-0.0.1-SNAPSHOT.jar com.bobo.mr.wc.WcTest /hdfs/wordcount/input /hdfs/wordcount/output/
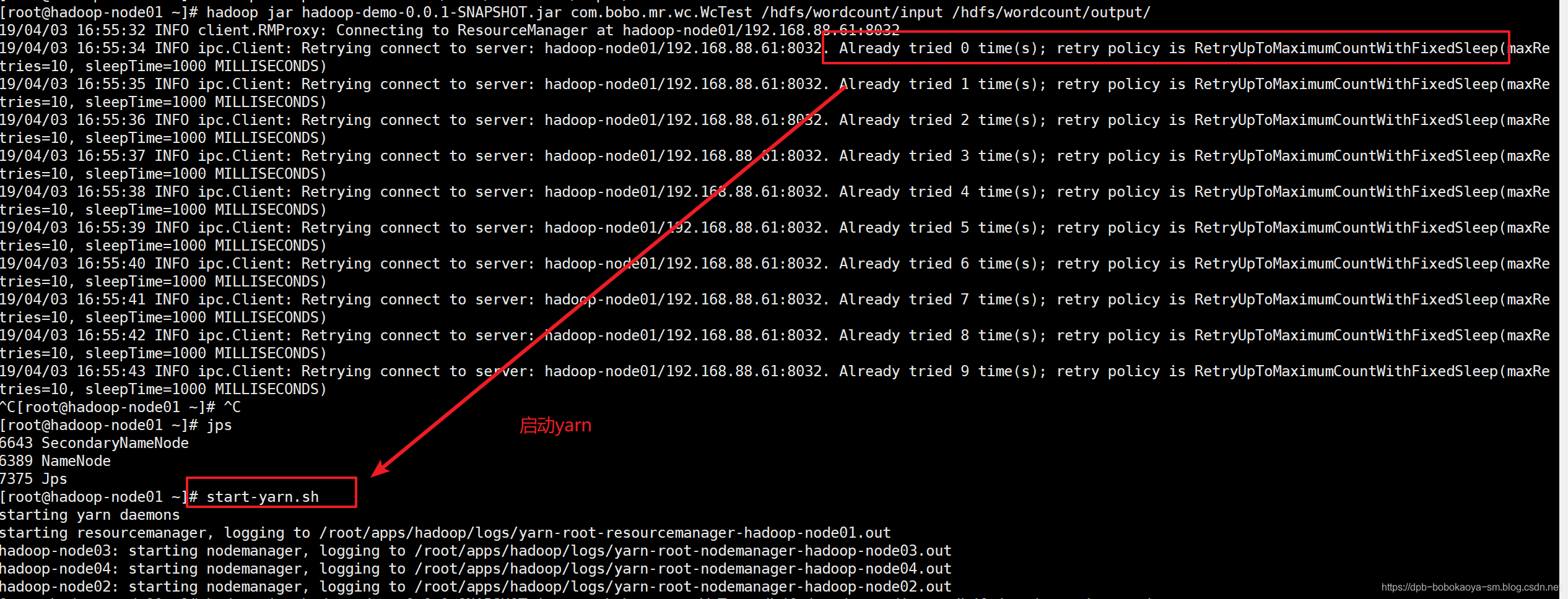
执行成功
[root@hadoop-node01 ~]# hadoop jar hadoop-demo-0.0.1-SNAPSHOT.jar com.bobo.mr.wc.WcTest /hdfs/wordcount/input /hdfs/wordcount/output/19/04/03 16:56:43 INFO client.RMProxy: Connecting to ResourceManager at hadoop-node01/192.168.88.61:803219/04/03 16:56:46 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.19/04/03 16:56:48 INFO input.FileInputFormat: Total input paths to process : 219/04/03 16:56:49 INFO mapreduce.JobSubmitter: number of splits:219/04/03 16:56:51 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1554281786018_000119/04/03 16:56:52 INFO impl.YarnClientImpl: Submitted application application_1554281786018_000119/04/03 16:56:53 INFO mapreduce.Job: The url to track the job: http://hadoop-node01:8088/proxy/application_1554281786018_0001/19/04/03 16:56:53 INFO mapreduce.Job: Running job: job_1554281786018_000119/04/03 16:57:14 INFO mapreduce.Job: Job job_1554281786018_0001 running in uber mode : false19/04/03 16:57:14 INFO mapreduce.Job: map 0% reduce 0%19/04/03 16:57:38 INFO mapreduce.Job: map 100% reduce 0%19/04/03 16:57:56 INFO mapreduce.Job: map 100% reduce 100%19/04/03 16:57:57 INFO mapreduce.Job: Job job_1554281786018_0001 completed successfully19/04/03 16:57:57 INFO mapreduce.Job: Counters: 50 File System Counters FILE: Number of bytes read=181 FILE: Number of bytes written=321388 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=325 HDFS: Number of bytes written=87 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=1 Rack-local map tasks=1 Total time spent by all maps in occupied slots (ms)=46511 Total time spent by all reduces in occupied slots (ms)=12763 Total time spent by all map tasks (ms)=46511 Total time spent by all reduce tasks (ms)=12763 Total vcore-milliseconds taken by all map tasks=46511 Total vcore-milliseconds taken by all reduce tasks=12763 Total megabyte-milliseconds taken by all map tasks=47627264 Total megabyte-milliseconds taken by all reduce tasks=13069312 Map-Reduce Framework Map input records=14 Map output records=14 Map output bytes=147 Map output materialized bytes=187 Input split bytes=234 Combine input records=0 Combine output records=0 Reduce input groups=10 Reduce shuffle bytes=187 Reduce input records=14 Reduce output records=10 Spilled Records=28 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=1049 CPU time spent (ms)=5040 Physical memory (bytes) snapshot=343056384 Virtual memory (bytes) snapshot=6182891520 Total committed heap usage (bytes)=251813888 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=91 File Output Format Counters Bytes Written=87

查看结果
[root@hadoop-node01 ~]# hadoop fs -cat /hdfs/wordcount/output/part-r-00000ajax 1bobo烤鸭 1hello 2java 2mybatis 1name 1php 1shell 2spring 2springmvc 1
OK~
- 赞
- 收藏
- 评论
- *举报
上一篇:Hadoop之MapReduce01【自带wordcount案例】
下一篇:Hadoop之MapReduce03【wc案例流程分析】
Original: https://blog.51cto.com/u_15494758/5433343
Author: 波波烤鸭
Title: Hadoop之MapReduce02【自定义wordcount案例】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516996/
转载文章受原作者版权保护。转载请注明原作者出处!