

MapReduce之Eclipse本地运行
原创
文章标签 MapReduce 本地运行 hadoop apache mapreduce 文章分类 Hadoop 大数据
©著作权归作者所有:来自51CTO博客作者波波烤鸭的原创作品,请联系作者获取转载授权,否则将追究法律责任
前面我们介绍的wordcount案例是在Eclipse中写好代码,然后打成jar包,然后在Linux环境中执行的,这种方式在我们学习和调试的时候就显得非常的不方便,所以我们来介绍下直接在Eclipse运行的本地运行方式。
本地运行模式
本地运行模式的特点
- mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行。
- 而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上。
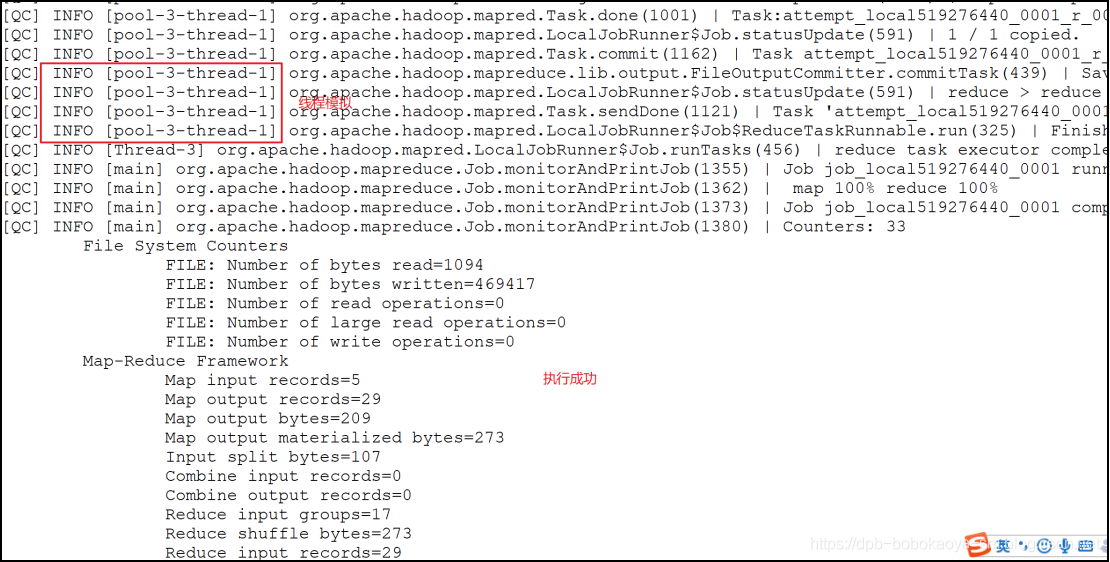
- 本地模式非常便于进行业务逻辑的debug,只要在eclipse中打断点即可
环境准备
- Windows系统中我们需要安装hadoop环境。

具体操作参考此文
- 配置环境变量信息

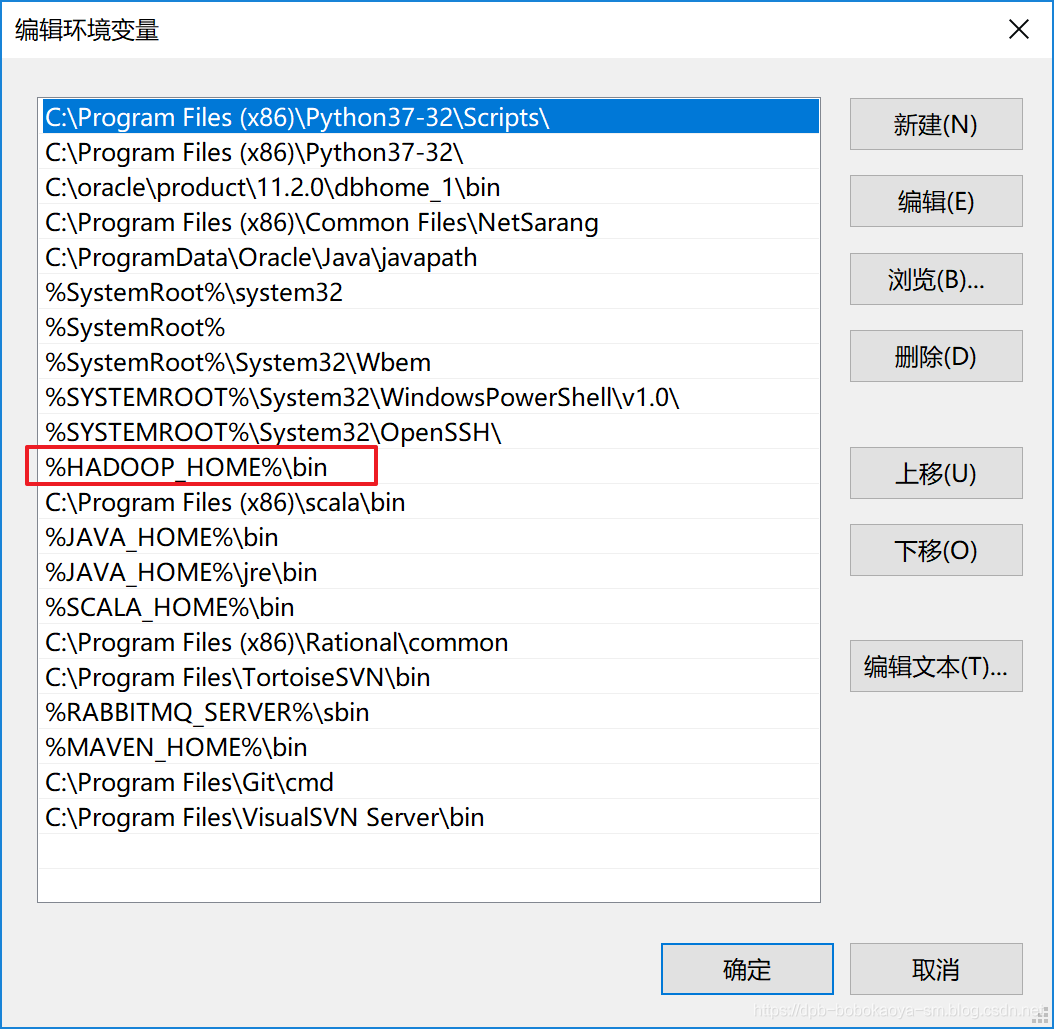
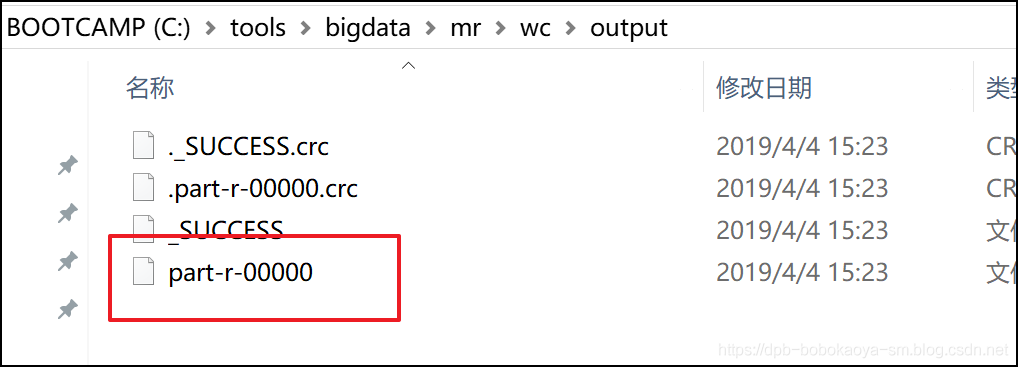
测试
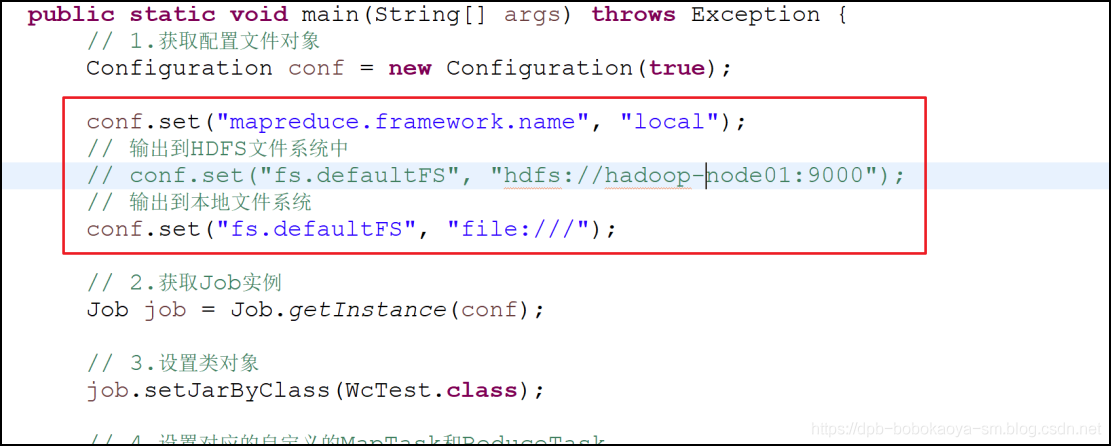
package com.sxt.mr.wc;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WcTest { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(true); conf.set("mapreduce.framework.name", "local"); conf.set("fs.defaultFS", "file:///"); Job job = Job.getInstance(conf); job.setJarByClass(WcTest.class); job.setMapperClass(MyMapperTask.class); job.setReducerClass(MyReduceTask.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path("c:/tools/bigdata/mr/wc/input/")); FileOutputFormat.setOutputPath(job, new Path("c:/tools/bigdata/mr/wc/output/")); job.waitForCompletion(true); }}
- 赞
- 收藏
- 评论
- *举报
上一篇:Hadoop之MapReduce04【客户端源码分析】
下一篇:MapReduce之流量汇总案例
Original: https://blog.51cto.com/u_15494758/5433348
Author: 波波烤鸭
Title: MapReduce之Eclipse本地运行
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516992/
转载文章受原作者版权保护。转载请注明原作者出处!