

出自黑马架构师课程, 我自己整理了一下讲义和老师说的话,记录了下笔记
概述
任何体系的成型不是一蹴而就,随着访问量,数据量的增长,业务需求在推动技术架构的发展变革。下
面我们以淘宝的发展历程为例,来看系统架构的演进过程。
1)架构目标
高性能:提供快速的访问体验,高并发下的及时响应。
高可用:网站服务7×24正常访问,可用性达到几个9。
可伸缩:资源的扩容,应对突发和流量脉冲。
安全性:提供网站安全访问和数据加密、安全存储等策略。
扩展性:方便对现有模块做版本升级,新模块的上线,突发活动下的服务降级。
敏捷性:对系统突发情况的快速排查与应对。
2)演进概述
部署层面:单机到集群,集中式到分布式,物理部署到云化
业务层面:单一mvc到垂直拆分,服务治理到微服务
数据层面:db到集群,单一关系型数据到多样化nosql,搜索引擎,文件服务
单机器时代
小型网站,直接申请一台阿里云linux云服务器,然后一台小项目在上面部署,或者是公司内部的小项目,比如说我们公司的项目管理工具程序就是一台机器部署的,反正就几十个人使用,宕机了就宕机了,重启一下就好了.


1)方案
大型机:引发对单机性能的过度追求,推动高配机器的发展,成本高昂
调优:jvm单节点调优甚至接近于强迫症的地步
2)特点
部署简单:采用web包部署与发布,db同台机器连接,简单易操作。
资源争夺:在业务发展的初始阶段尚可支撑,随着访问量的上升,单机性能很快会成为系统瓶颈。
缺点: tomcat和MySQL都部署在一台机器上,可能会互相争夺机器上的资源
数据分离
稍微大一点的系统,dba出现,数据库追逐商业大型db如oracle,如(淘宝v1.1 , mysql→oracle)

1)方案
多台机器:tomcat与mysql各自独占机器资源
针对性扩容:tomcat应用机更注重cpu的运算和内存,mysql更注重io与磁盘性能,针对各自情况扩容
2)特点
数据维护:可以抽出单独的dba来维护数据库服务器
数据安全:需要跨机器访问数据库,链接密码需要注意防范泄漏
数据库瓶颈:数据库频繁读写,io很快成为瓶颈
数据缓存
2006-2007,淘宝V2.2架构,分布式缓存Tair引入。(08-09创业初期memcache+ssh1时代的故事)

1)方案
数据冷热划分:热点数据如类目、商品基础信息热加载,其他数据延迟加载
ehcache:非分布式,简单,易维护,可用性一般
memcache:性能可靠,纯内存,客户端需要自己实现,无持久化,如果宕机了,memcache里面的数据会全部丢失.
redis:性能可靠,纯内存,自带分片,集群,哨兵,支持持久化,几乎成为当前的标准方案
2)特点
缓存策略:缓存与db的边界需要架构师去把控,重度依赖可能引发问题
(memcache造成db高压案例,模拟请求解决 → squid;redis短信平台故障案例)
缓存陷阱:击穿,穿透,雪崩
数据一致性:删除、双写
应用集群
2004-2005,淘宝V2.0,EJB为核心(2011年间EJB3 pk spring3.x选型案例)。V2.1架构下,引入spring框架走向轻量化和集群

1)方案
apache:早期负载均衡方案,性能一般
nginx:7层代理,性能强悍,配置简洁,可以携带lua完成前端逻辑,当前不二之选
haproxy:性能没问题,可做7层或4层代理。
lvs:4层代理,性能最强,linux集成,配置麻烦
h5:硬件负载,财大气粗的不二选择
2)特点
session保持:集群环境下,用户登陆及session的保持成为问题,需要分布式session做支撑
分布式协同:分布式环境下对资源的加锁要超出线程锁的范畴,上升为分布式锁
调度问题:调度程序跑重复(比如说在A tomcat上跑,然后又在B tomcat上跑,这样就会跑重复了)
机器状态管理:多台应用机的状态检测与替换需要做到及时性
服务升级:滚动升级成为可能
日志管理:日志文件分散在各个机器,促进集中式日志平台的产生(elk)
读写分离
早在2003-2004淘宝V1.0就使用mysql就使用了读写分离,V1.1换成oracle,直到2007数据库重新往mysql回迁,新东方也是相同经历。
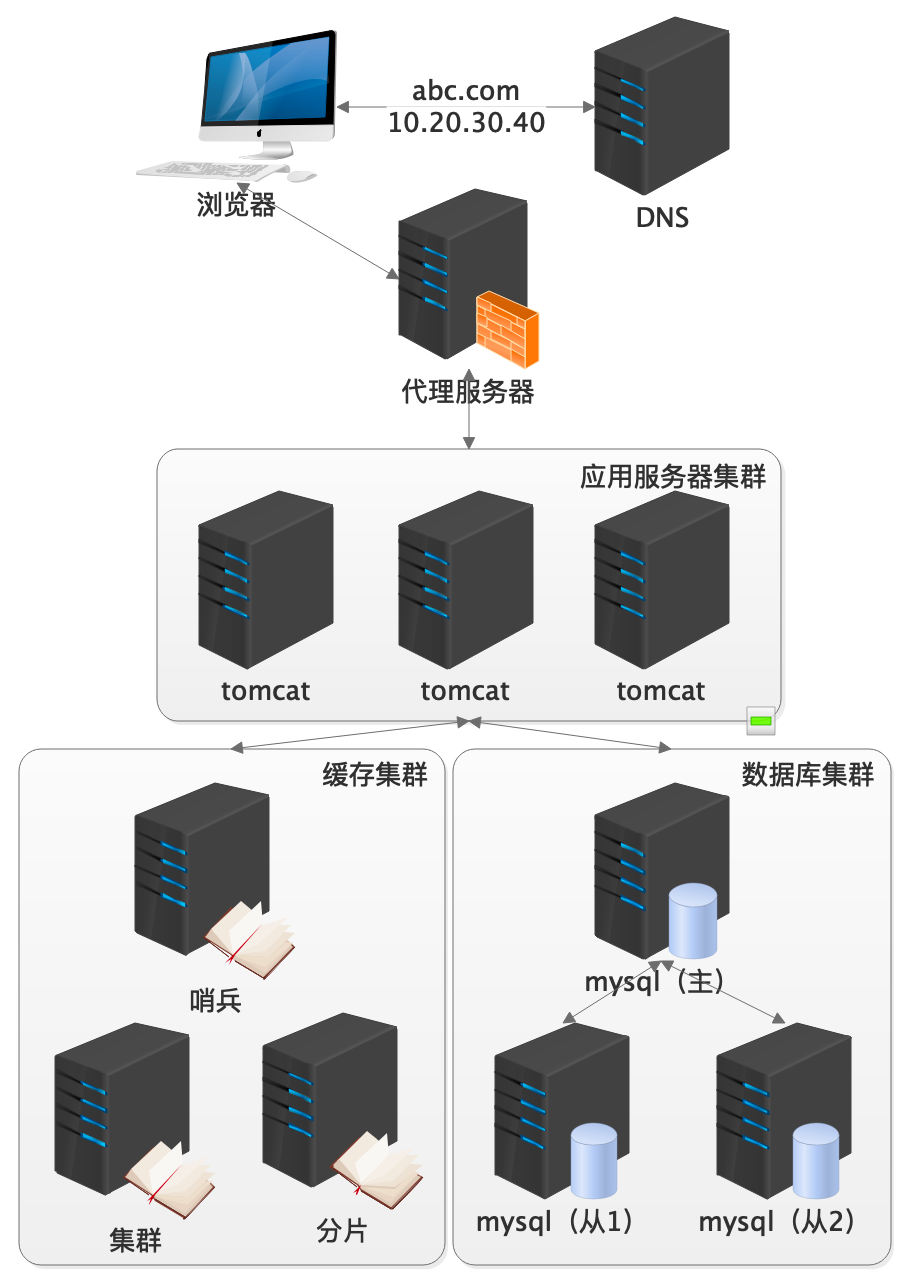
1)方案
缓存集群:redis哨兵,集群,分片,pre-sharding,memcache一致性hash
数据库集群:一主多从、双主单写、灾备 (供销灾备双主单写案例)
2)特点
数据延迟:准实时,单方法内的写入立即读取问题
开发层面:需要开发框架具备多数据源的支持,以及自动化的数据源切换
数据分片:memcache需要客户端处理,redis支持集群数据分片
单库瓶颈:业务越来越多,表数量越来越多。单库成为瓶颈
数据局限:依然无法解决单表大数据的问题,比如订单积累达到亿级,即使在从库,关联查询依然奇慢无比
分库分表
2004-2007,淘宝V2.1,支持分库,抛弃EJB。

1)方案
早期分区表:range,list,hash,key,对开发端透明,但分区数有限制,性能提升有天花板。
业务分库:订单库,产品库,活动库,会员库
横向分表:3个月内订单,半年内订单,更多订单
2)特点
(恒天集团基金系统从数据库分区表到Mycat)
分库:无法使用数据库事务保证完整性,而分布式事务的效果并不理想,多采用幂等和最终一致性方
案。
分表:数据聚合矛盾,以订单为例,下单时间维度的分表和用户维度的查询是一对矛盾。排序统计变得异常困难。
中间件:Sharding-JDBC,Mycat,Atlas
动静分离
早年间的Apache+tomcat,后被nginx几乎一统江山。(前后端开发模式的演进:mvc页面嵌套→接口化)

1)方案
静态响应:tomcat对静态文件响应一般,提取静态文件,直接由nginx响应
动态代理:后端api通过代理转发给tomcat应用机器
2)特点
开发层面调整:项目结构要同步调整,由原来的一体化mvc转换为后端api+前端形式。
前后协调:前后端的分工变得更明确,互相并行开发,独立部署,但也带来了接口协调与约定等沟通问题
单层局限:单个nginx代理在并发处理任务时,依然会有上限,静态文件节点需要面临扩容。
多层代理
2010-2012 ,新东方网络课堂项目架构,基于springMVC+Mybatis,war包集中式部署。资源不够,机器来凑的时代(30台tomcat)。

1)方案
多层代理:在nginx前再加一层lvs做代理,作为流量的统一入口,再分发给下层的多个nginx,静态服
务得到扩容
2)特点
机房受限:lvs依然是单一节点,即使keepalived做到高可用,流量仍然需要在唯一入口进入。
跨机房
淘宝V2.1时代 , 使用自己的TaobaoCDN。中国供销集团两地灾备,DNS轮询北京机房,西安机房

1)方案
dns轮询:通过配置多个ip将服务部署到多个机房,通过dns的策略轮询调用,可以实现机房层面的扩容
CDN:就近原则,使用户获得就近的机房访问相关资源,自己投资太大,购买他方需要付费。
2)特点
基本解决了机器部署的扩容问题,多个机房可以实现灾备,一个机房宕机了,可以给用户流量引入到另外一个机房,让这个机房暂时扛起来用户流量,随着业务的发展,数据呈现多样化发展,底层异构化数据成为新的瓶颈。
不同用户访问的是同一个地址,但是访问的ip地址不一样,但是看到的内容是一样的.
异构数据
2006-2007,淘宝V2.2,分布式存储TFS,分布式缓存Tair,V3.0 加入 nosql Cassandra,搜索引擎升
级
数据库查询调优极限(达到上限)→搜索引擎(全文检索代替关系型数据库查询)、本地上传+nfs→文件系统(fastDFS)的演进

1)方案
nosql:商品特殊化属性,mongodb,hbase
搜索引擎:商品信息库,lucene,solr,elasticsearch
分布式文件存储:商品图片,上传的文件等,hdfs,fastdfs
2)特点
开发框架支持:存储的数据多样化,要求开发框架架构层面要提供多样化的支撑,并确保访问易用性
数据运维:多种数据服务器对运维的要求提升,机器的数据维护与灾备工作量加大
数据安全:多种数据存储的权限,授权与访问隔离需要注意
业务线拆分
以上架构的演进,基础设施层面的优化几乎达到了天花板,接下来,需要从业务和应用层面进行架构上的升级

1)方案
业务分发:代理层设置不同的二级域名,如b2b.abc.com,b2c.abc.com,分发给不同的服务器
比如说淘宝和闲鱼,不同的业务独立发展去了.
消息互通:服务之间使用mq等异步消息提供通讯。
跨域问题:因为多个业务线占据不同的域名,出现多个主站,单点登录被推上前线
2)特点
粒度较粗:纯以业务为导向,往往形成业务团队各自为战,新业务线出现时疯狂扩张
重复开发:相同功能可能在不同业务的项目中被重复开发,比如促销、短信发送、收银台 , 每个业务维护的项目组都自己开发一套.
服务化
淘宝V3.0,HSF出现,服务化导向,架构师忙于SOA和系统关系的梳理。
(2015年冬金融项目业务线rest→dubbo2.4.11的引入过程)

1)方案
公共服务:重复开发的基础服务沉淀,形成服务中心,避免重复造轮子,降低成本,架构团队出现。
独立性:各自服务独立部署升级,粒度更细,低耦合,高内聚
SOA:服务治理的范畴,重在服务之间的拆分与统一接口
微服务:可以理解为服务治理的一种手段,趋向于小服务的独立运作与部署。
技术手段:springcloud,dubbo
2)特点
界限把控:服务的粒度、拆分和公共服务提炼需要架构师的全局把控。设计不好容易引发混乱
部署升级:服务数量增多,自动化部署面临挑战
服务可用性:抽调的微服务因需要被多个上层业务共享,可用性等级变高,比如说短信服务,所有的服务都用短信服务,如果短信服务一旦宕机就是灾难,因为所有的服务都不能用短信服务了.
熔断和限流:做好服务熔断和限流,提防服务单点瓶颈造成整个系统瘫痪。
中台化
阿里共享业务技术部的发展,中国供销集团,电商平台中台体系的架构模式。
技术沉积形成了公共服务平台,业务沉积逐步形成共享业务技术部,同时,业务烟囱的壁垒推动业务中台成型。同时组织结构同步升级,以技术共享为核心的技术中台,以数据为中心的数据中台同步建设得到实施。

1)方案
业务沉淀形成独立的中心,各个中心之间借助服务总线实现业务协作与服务重组。
2)特点
团队规模:团队规模扩张,人员增多,协调成本上升,组织机构要有配套调整
接口授权:各个中心的接口授权与开发需要把控
接口约束:系统增多,各个服务接口的规范化日益重要,要求有统一的服务接口规范,推动企业消息总线的建设
跨服务令牌:借助oauth2等手段,实现服务之间的权限认证
容器化
针对中台化的建设及微服务数量的飙升,部署和运维支撑同步进行着变革。面临微服务的快速部署,资源的弹性伸缩等挑战,容器化与云被推进。
案例:成百上千的服务数量庞大、大促期间某些微服务的临时扩容。

1)方案
虚拟化:vm方案,Openstack,Vmware,VirtualBox
容器化:docker
编排:swarm,k8s,k3s
云化:容器化解决了资源的快速伸缩,但仍需要企业自备大量预备资源。推动私有云到企业云进化
2)特点
资源预估:注意资源的回收,降低资源闲置和浪费,例如大促结束后要及时回收。
运维要求:需要运维层面的高度支撑,门槛比较高
预估风险:云瘫痪的故障造成的损失不可估量,(openstack垮掉的事故案例)
架构总结
- 知行合一,做之前,先考虑意义
- 原生优于定制,约定大于配置
- 什么都是(不要什么都抓,要有取舍),最后会沦落到什么都不是
- 控制技术欲,不要瞎折腾(你要能hold住)
- 留下扩展,但不要想到100年后(不要扩展的太超前了.)
- 没有最好的,只有最合适的
- 够用就好(贪多嚼不烂),玩的越花(不要耍酷,系统设计的太炫),风险越大
- 简约最美(用最简单的系统能完成你当前的事儿)
Original: https://blog.51cto.com/u_14861909/5440088
Author: wx5efd5423d18bb
Title: 互联网架构体系演进
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516786/
转载文章受原作者版权保护。转载请注明原作者出处!