

一些参数说明
https://www.kancloud.cn/anychat-doc/anychat_handbook_video/526462
音频、音频,故名声音的频率,指人耳可以听到的声音频率在20HZ~20kHz之间的声波,称为音频,那频率就有采用率和大小,我们大自然的声音都是物理现象,称为模拟音频信号。为了方便数字化存储和传输,我们采用数字音频信号处理技术,音频采样率是指录音设备在一秒钟内对声音信号的采样次数,采样频率越高。声音的还原越真实越自然。在当今的主流采集卡上,采样频率一般共分为22.05KHz、44.1KHz、48KHz三个等级。
sample rate,取样频率:指每秒钟取得声音样本的次数。采样频率越高,声音的质量也就越好,声音的还原也就越真实,但同时它占的资源比较多。由于人耳的分辨率很有限,太高的频率并不能分辨出来。
sample size,采样值大小:它是用来衡量声音波动变化的一个参数,也可以说是声卡的分辨率。它的数值越大,分辨率也就越高,所发出声音的能力越强。
每个采样数据记录的是振幅, 采样精度取决于采样位数的大小:1 字节(也就是8bit) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
2 字节(也就是16bit) 可以细到 65536 个数, 这已是 CD 标准了;
4 字节(也就是32bit) 能把振幅细分到 4294967296 个等级, 实在是没必要了.
声道:指声音在录制或播放时在不同空间位置采集或回放的相互独立的音频信号。
声道数:声音录制时的音源数量或回放时相应的扬声器数量。
分为单声道、双声道、多声道。
1. 输入音频处理
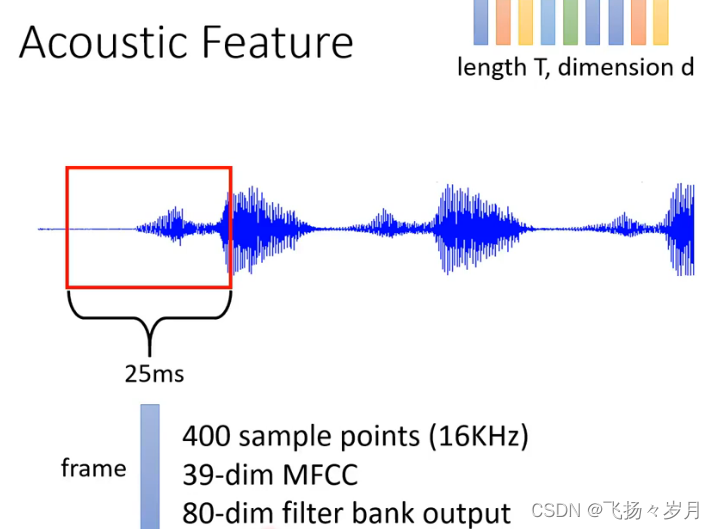

从waveform到MFCC逐步加深,log十分重要
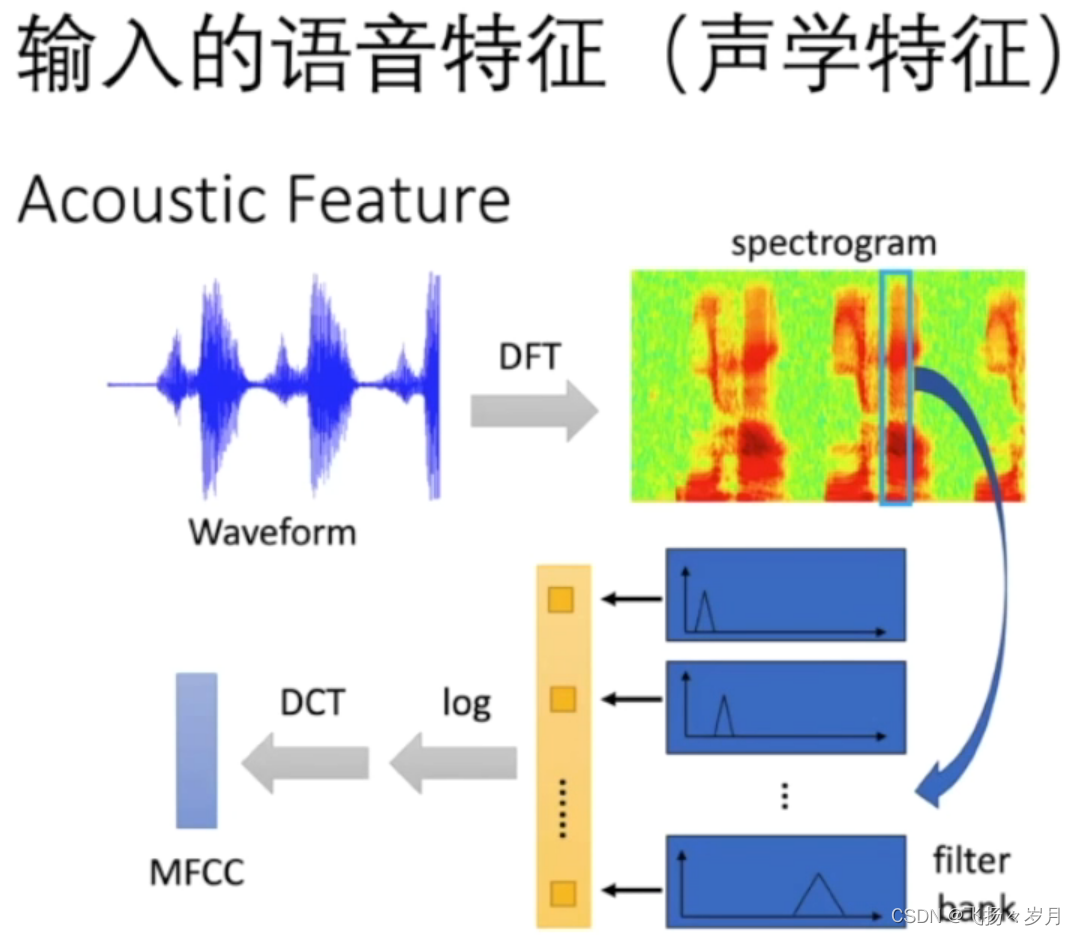
最终得到的MFCC特征,就是用24维特征系数来代表一帧的声音。
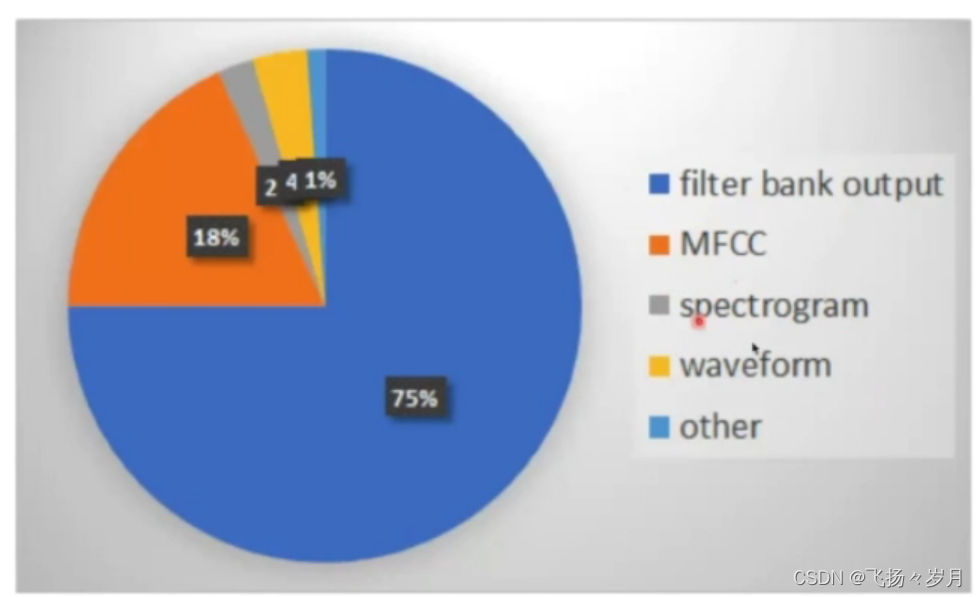
; 2. 输出token
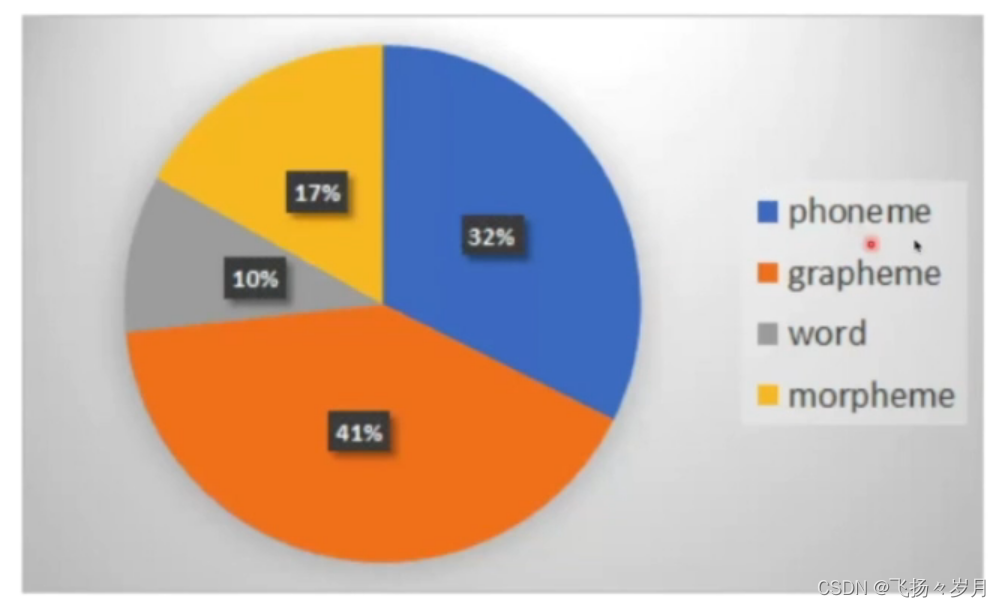
(1)Phoneme:最小的发音单元 https://en.wikipedia.org/wiki/Vowel
(2)Grapheme:最小的书写单元。中文=字,英文=字母
(3)word:中文=词,英文=word
(4)Morpheme:最小的有意义的单元。适用英文,例如:
unbreakable=un break able,类似于子词
(5)拼音
训练时英文按空格分词,中文复杂:

主流模型
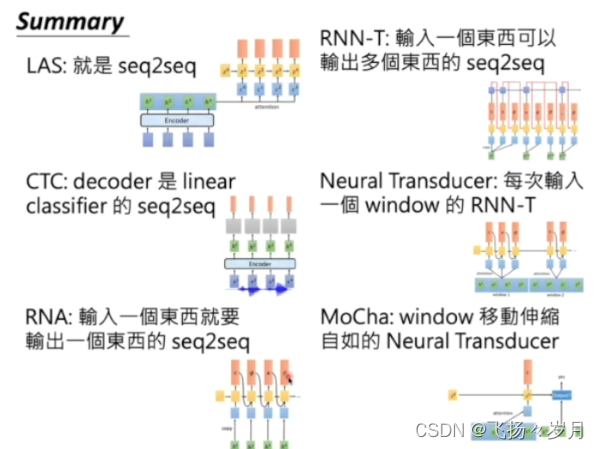
1、seq2seq+attention +beam search
例如:LAS模型(Listen, Attend, and Spell
)
缺点: not streaming
2、Sequence labeling
(1)CTC
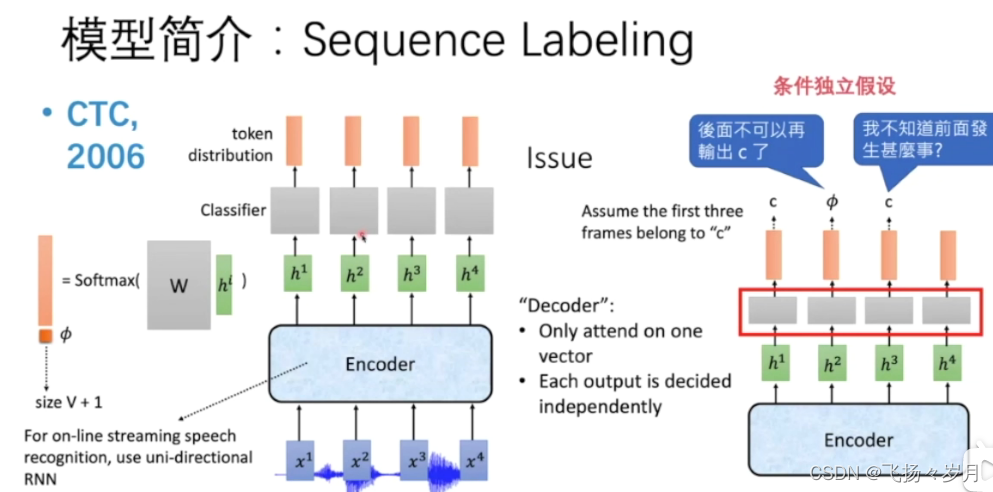
CTC模型就是先将一段声音信号x作为输入输入到encoder中,输出h,再经过一个classifier产生token distribution,最后经过一个softmax输出最后结果。但是如果只是以上这种模型,并不能有很好的结果,因为如果token只是一个大小为V的矩阵的话,不一定每一段x会有输出,于是就会有一个Ø(NULL)便可以有效处理这种情况。
详情参见:https://blog.csdn.net/qq_45866407/article/details/105975320
缺点:条件独立,会反复生成相同的词。生成的token不能超过sample数量。
优点,可以做streaming
(2)RNN Transducer
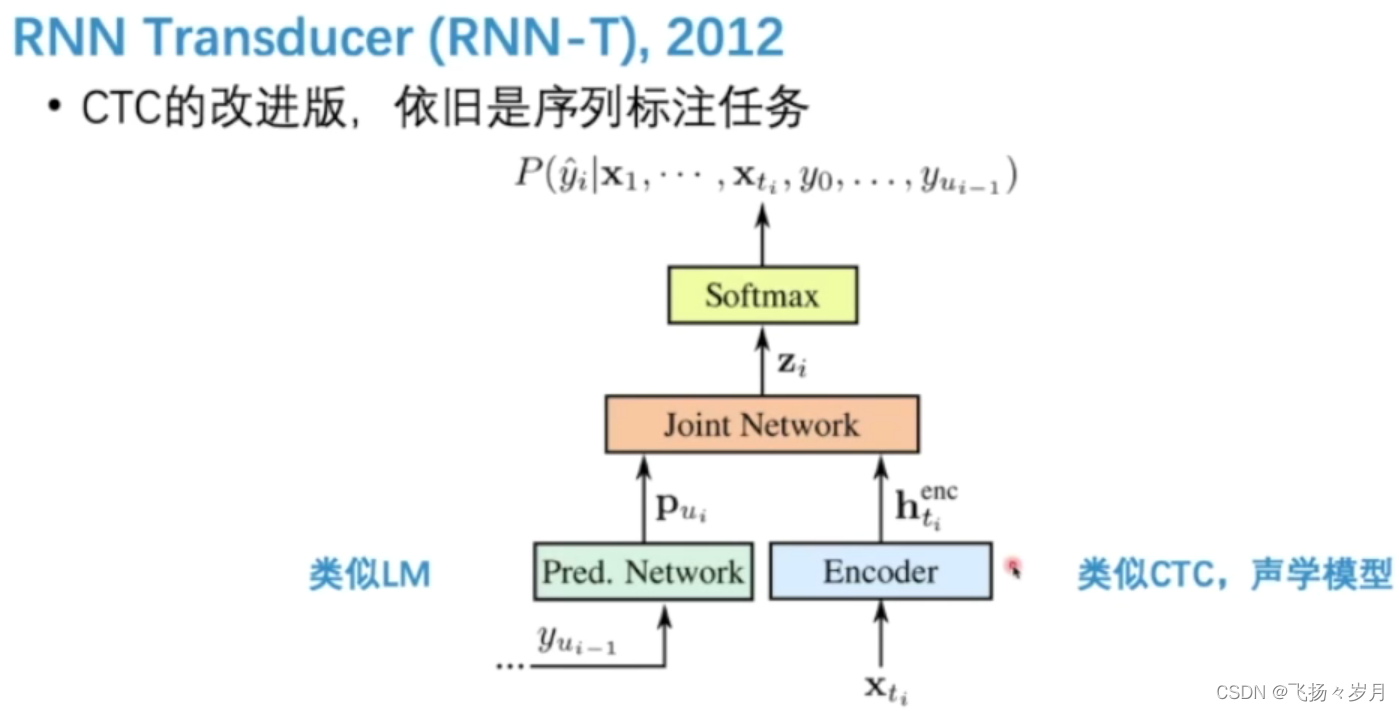
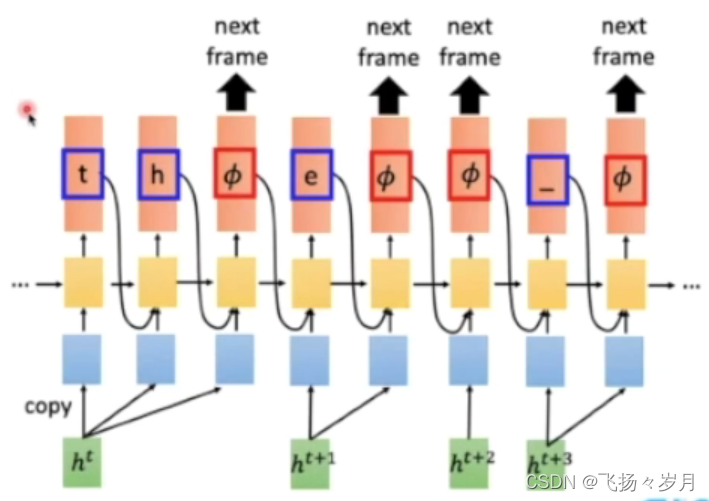
优点:在encoder改进了RNN,一个h0可以用多个step,使得模型能输出超过sample数量的token。考虑了LM,支持streaming。
缺点:训练困难。
(3)Neural Transducer
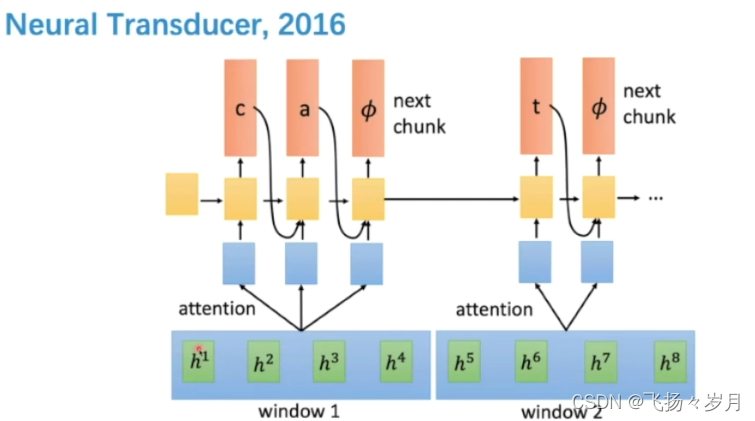
(4) Monotonic Chunkwise Attention

总结:
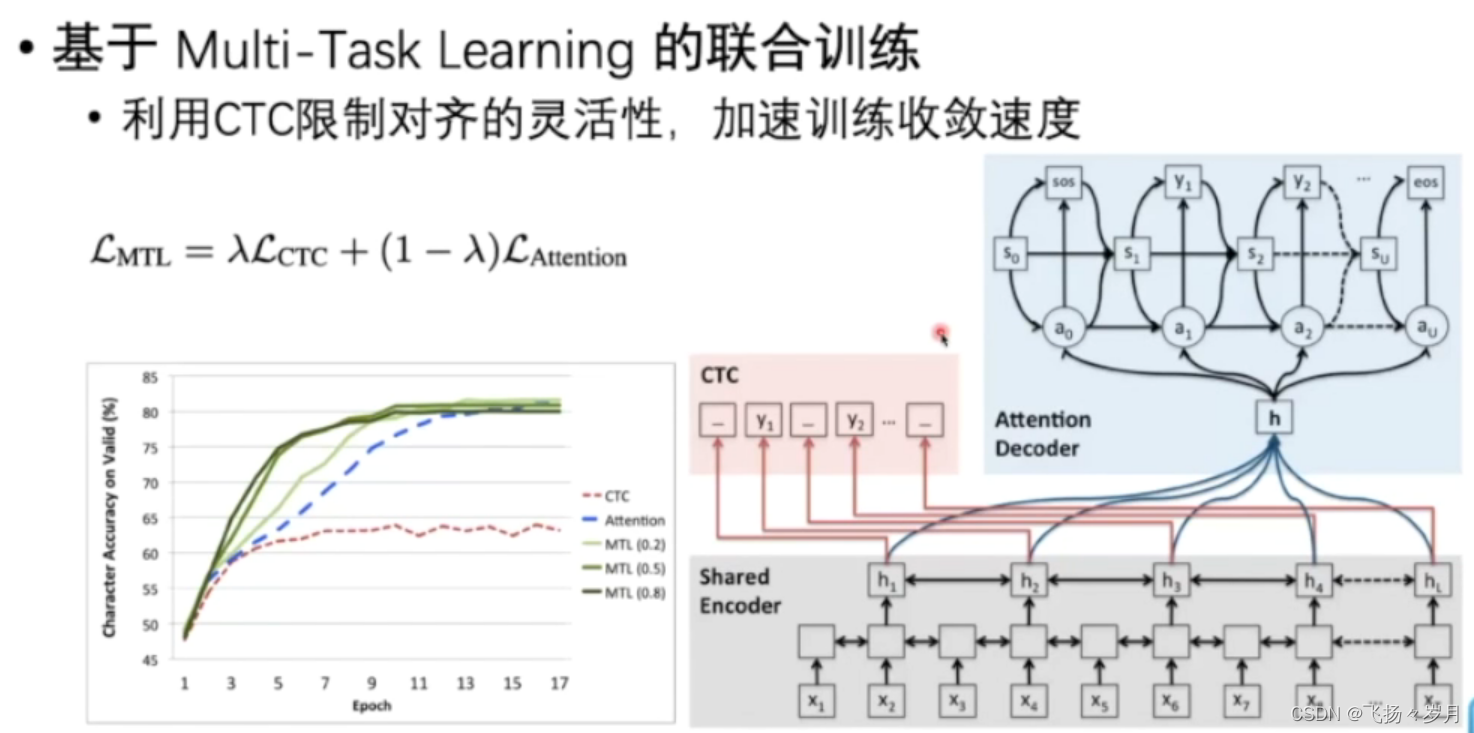
; 3、Multi-task learning
核心理念:
CTC模型训练快,但是有token长度对应得限制,并且容易结巴连续生成某个token。
SL模型,没有长度限制,不会结巴。但是速度慢。
因此,考虑两个任务联合起来,加快模型收敛速度。
Transformer系列
(1)Conformer Transducer
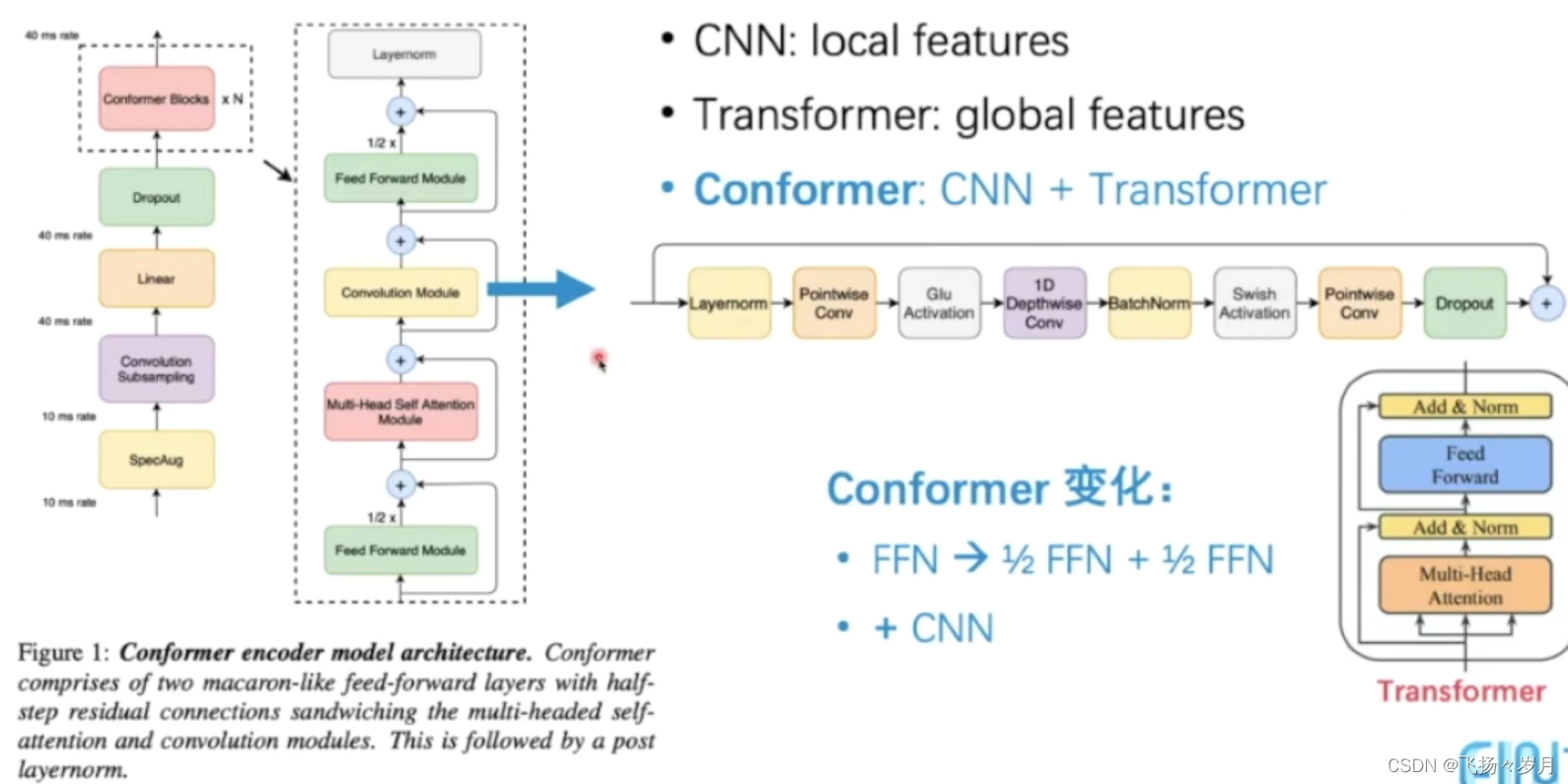
把FFN分为两个步骤,同时用CNN来捕获局部特征
; 关于Streaming
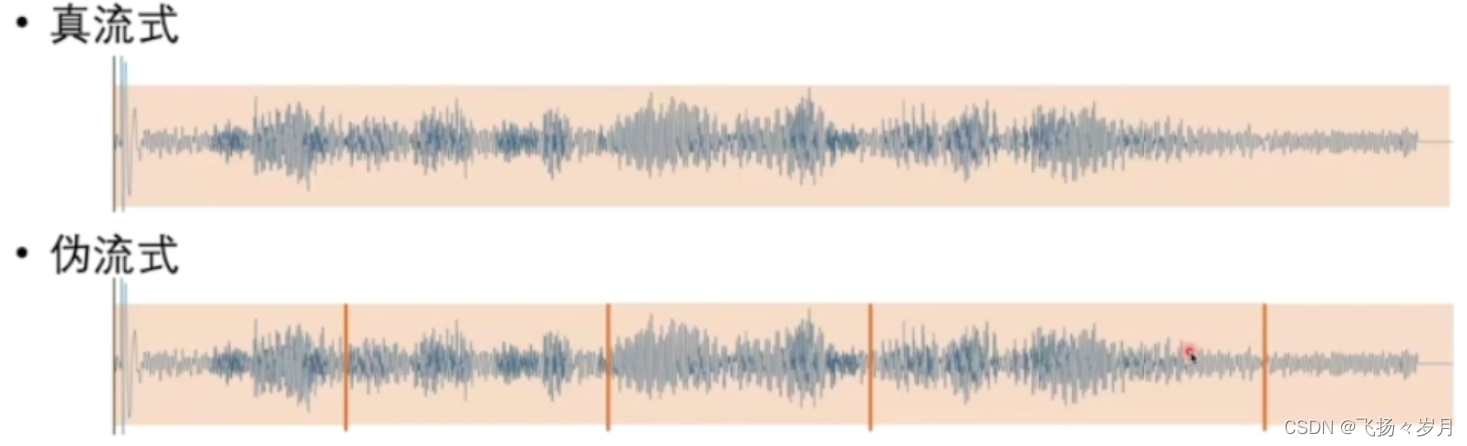
Transfoemer结构怎么实现Streaming
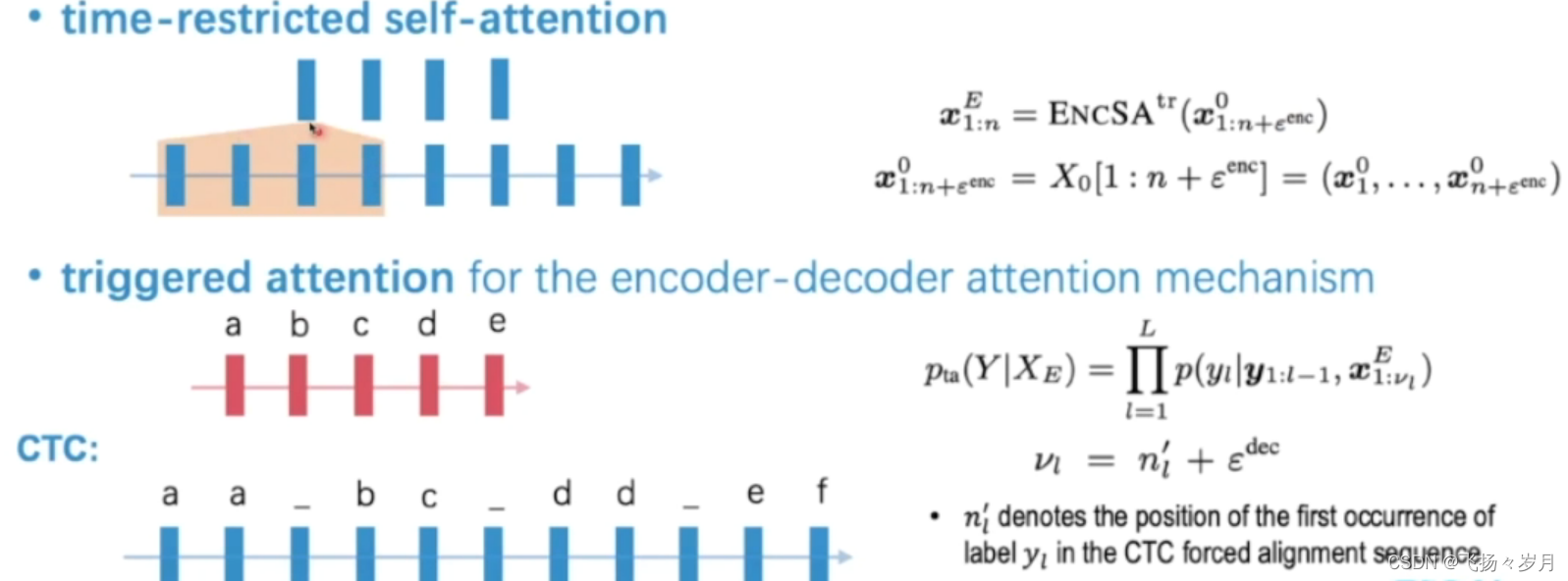
triggered attention:每个节点只看当前节点之前的节点。也可以往后看一定数量的节点,主要防止要预测’我们’,当前时间只听到’我’,所以向后多听一点。
在CTC模型中,每个字只关注这个字第一次出现前的序列
; ASR相关技术:EP__EndPointer.端点检测
VAD: Voice Activity Detector.
判断是否有人说话
EOQ: End of Query.
找到对话结束点
SD: Speaker Diarization
在多人对话中将对话按人划分。
常用工具

Original: https://blog.csdn.net/weixin_42264992/article/details/125319325
Author: 飞扬々岁月
Title: ASR入门笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515870/
转载文章受原作者版权保护。转载请注明原作者出处!