

提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
SPFCN是一个偏工程性且实用的车库位检测算法,本人菜鸟一个,又看不到有关此论文的解读,所以在此写下关于自己的解读,希望能帮助大家,更是在写文章的过程中一边梳理和理清思路,文章中可能出现一些错误,请大佬们指正。
一、SPFCN的算法流程
SPFCN算法是用Stacked Hourglass Network作为基本结构,其具体网络结构和示意图下图所示,输入尺寸为224*224BEV(鸟瞰图),输出入口点,入口线,边界线的heatmap。


Hourglass的具体网络结构图

Hourglass的网络结构示意图
该模型的主要特点在于其SP模块(Select-Prune Module),SP模块分为Select模块和Prune模块两部分,Select模块主要用于选择拥有更合适的感受野的卷积核。Prune模块负责修剪卷积核中的通道。这两个模块我们到后面再进行详细说明:而这个网络模型主要进行三个阶段来进行训练,分别为 预训练阶段、 选择阶段和 修剪阶段,不同阶段使用不同的损失函数。所以我们主要从这三个阶段来进行解读。
; 二、训练阶段
1.预训练阶段
数据预处理
加载自己的数据集
该有关数据集的处理论文中并无详细说明,所以这里通过源码来进行理解和解释说明,该加载数据集并进行预处理的代码主体在SPFCN/dataset/dataset.py中。下面源码解读:
import numpy as np
from scipy.io import loadmat
from torch.utils.data import Dataset
import glob
给出二维高斯核的分布大于0.1,方便后面代码进行高斯膨胀
GAUSSIAN_VALUE = np.array([[0.0111, 0.0388, 0.0821, 0.1054, 0.0821, 0.0388, 0.0111],
[0.0388, 0.1353, 0.2865, 0.3679, 0.2865, 0.1353, 0.0388],
[0.0821, 0.2865, 0.6065, 0.7788, 0.6065, 0.2865, 0.0821],
[0.1054, 0.3679, 0.7788, 1.0000, 0.7788, 0.3679, 0.1054],
[0.0821, 0.2865, 0.6065, 0.7788, 0.6065, 0.2865, 0.0821],
[0.0388, 0.1353, 0.2865, 0.3679, 0.2865, 0.1353, 0.0388],
[0.0111, 0.0388, 0.0821, 0.1054, 0.0821, 0.0388, 0.0111]])
注:这是个7*7的高斯核,这在后面的高斯膨胀运算非常重要。
class VisionParkingSlotDataset(Dataset):
def __init__(self, image_path, label_path, data_size, resolution):
self.length = data_size
# 这是储存图片的列表
self.image_list = []
# 这是储存数据标签的列表
self.label_list = []
# 这是为了计数,防止数据的长度超过定义的需求
index = 0
# for item_name in os.listdir(image_path):
for item_name in glob.glob(os.path.join(image_path,'*.jpg')):
# item_label = loadmat("%s%s.mat" % (label_path, item_name[:-4]))
item_label = loadmat("%s.mat" % (item_name[:-4]))
slots = item_label['slots']
if len(slots) > 0:
item_image = cv2.resize(cv2.imread(image_path + item_name),(resolution,resolution))
item_image = np.transpose(item_image, (2, 0, 1))
self.image_list.append(item_image)
注:.mat里的内容的实例如下
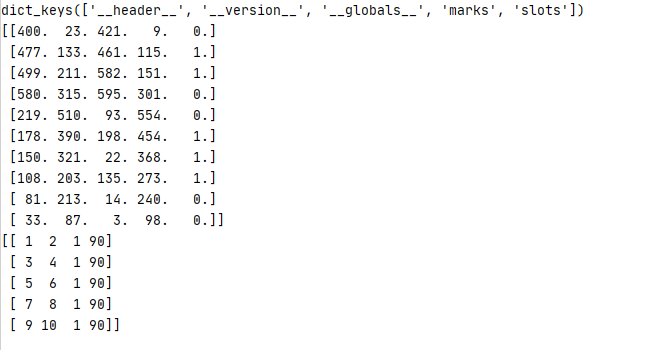
marks = item_label['marks']
# 获取到入口点和其向量的所对应的x,y,cos值,sin值所形成的列表
mark_label = self._get_mark_label(marks, slots, resolution)
# 初始化slot的标签值
slot_label = np.zeros([3, resolution, resolution])
for mark in mark_label:
# 去第一个通道的像素值作为灰度值,将点进行高斯膨胀,从点向外左边右边都是3个像素的后键入高斯模糊值
slot_label[0, mark[1] - 3:mark[1] + 4, mark[0] - 3:mark[0] + 4] += GAUSSIAN_VALUE
# 第二个加入cos值
slot_label[1, mark[1] - 3:mark[1] + 4, mark[0] - 3:mark[0] + 4] += mark[2]
# 第三个加入sin值
slot_label[2, mark[1] - 3:mark[1] + 4, mark[0] - 3:mark[0] + 4] += mark[3]
self.label_list.append(slot_label)
index += 1
if index == data_size:
break
注:slot_label[0, mark[1] – 3:mark[1] + 4, mark[0] – 3:mark[0] + 4] += GAUSSIAN_VALUE
这行为什么是mark[1] – 3, mark[1] + 4)解释了为什么是7*7的高斯核能进行矩阵相加。
@staticmethod
def _get_mark_label(marks, slots, resolution):
"""
:param marks: x, y
:param slots: pt1, pt2, _, rotate_angle
:param resolution: 224x224
:return:
"""
# temp_mark_label中的变量有,标签入口点的x值,y值,cos值,sin值
temp_mark_label = []
for mark in marks:
mark_x_re, mark_y_re = mark[0] * resolution / 600, mark[1] * resolution / 600
temp_mark_label.append([mark_x_re, mark_y_re, [], []])
for slot in slots:
# mark_vector是指两个入口点之间在图像坐标系中的向量。
mark_vector = marks[slot[1] - 1] - marks[slot[0] - 1]
# print(f"mark vector :{mark_vector}")
# mark_vector[0]即为入口点的x坐标, mark_vector[1]即为入口点的y坐标。
mark_vector_length = np.sqrt(mark_vector[0] ** 2 + mark_vector[1] ** 2)
# 当它的向量为正,即证明该向量的单位向量与图像坐标系成锐角,否则就问大于等于90度的角
if mark_vector[0] > 0:
mark_direction = np.arcsin(mark_vector[1] / mark_vector_length)
else:
mark_direction = np.pi - np.arcsin(mark_vector[1] / mark_vector_length)
slot_direction = mark_direction - slot[3] * np.pi / 180
slot_cos = np.cos(slot_direction)
slot_sin = np.sin(slot_direction)
temp_mark_label[slot[0] - 1][2].append(slot_cos)
temp_mark_label[slot[0] - 1][3].append(slot_sin)
temp_mark_label[slot[1] - 1][2].append(slot_cos)
temp_mark_label[slot[1] - 1][3].append(slot_sin)
mark_label = []
for mark in temp_mark_label:
if len(mark[2]) > 0:
mark_cos = np.mean(mark[2])
mark_sin = np.mean(mark[3])
# 求数据集中标记角度均值
mark_angle_base = np.sqrt(mark_cos ** 2 + mark_sin ** 2)
# 这里涉及到关于角度的均值,这个有关知识可以参考一下链接
# https://blog.csdn.net/liuchengzimozigreat/article/details/83068696?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164931064216782246446180%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164931064216782246446180&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-22-83068696.142^v5^pc_search_insert_es_download,157^v4^control&utm_term=%E6%B1%82%E6%95%B0%E6%8D%AE%E9%9B%86%E8%A7%92%E5%BA%A6%E7%9A%84%E5%9D%87%E5%80%BC&spm=1018.2226.3001.4187
mark_cos = mark_cos / mark_angle_base
mark_sin = mark_sin / mark_angle_base
mark_label.append([int(round(mark[0])), int(round(mark[1])), mark_cos, mark_sin])
return mark_label
def __getitem__(self, item):
return self.image_list[item], self.label_list[item]
def __len__(self):
return self.length
2. 训练阶段
在了解训练阶段的源码讲解前,必须要了解并且结合他的网络结构
网络结构
在讲SPFCN网络前,必须讲解Stacked Hourglass Network(SHN)
Backone:Stacked Hourglass Network(SHN)
SHN的主要贡献在于利用多尺度特征来识别姿态。以前估计姿态的网络结构,大多只使用最后一层的卷积特征,这样会造成信息的丢失。事实上,对于姿态估计这种关联型任务,全身不同的关节点,并不是在相同的feature map上具有最好的识别精度。举例来说,胳膊可能在第3层的feature map上容易识别,而头部在第5层上更容易识别,见下图。所以,需要设计一种可以同时使用多个feature map的网络结构。

而在SPFCN论文中阐述网络中是用和SHN网络结构相似的网络,即设计的架构相同,但是模块组成不同,接下来将会从局部到整体,来说明论文中的backone为什么会叫作Hourglass-like Network Structture, 而不是直接叫做SHN。
使用下面代码,通过tensorboard将网络结构显示出来。
from torch.utils.tensorboard import SummaryWriter
from SPFCN.model.network import SlotNetwork
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
writer = SummaryWriter("runs/models")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
writer.add_graph(SlotNetwork([32, 44, 64, 92, 128]).to(device),
input_to_model=torch.randn(1, 3, 224, 224).to(device),verbose=True)
在命令行运行:
tensorboard --logdir=./runs/model --host=服务器的IP地址
显示的网络模型是这样的

在将hourglass展开,即为下图所示:

如上图所示,这个hourglass的模块是有SP Module组合而成,而SP Module的结构是由Select Kernel所组成的,而Select Kernel是由Basic Module和 CEN模块组成的,而CEN网络是一个MLP模块称为贡献评估网络(CEN)。而论文说的不是太清晰,原文是这样说的:选择模块有几个具有不同膨胀值的候选卷积核,其任务是从中选择最佳的卷积核。输入特征被输入到每个内核中,贡献由一个称为贡献评估网络(CEN)的MLP块进行评估,但是源码中的核在训练时并没有用空洞卷积,所以应该结合源码来看。Select Kernel的网络结构图如下:

构成Select Kernel的组件源码如下图所示:
完成对最佳膨胀值的确定,一开始用的是普通卷积核看一看效果。这个模块只在训练上进行。测试时将会退化成真正的空洞卷积。
class SelectKernel(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
nn.Module.__init__(self)
self.conv3 = BasicModule(in_channels, out_channels, 3, stride=stride)
self.conv5 = BasicModule(in_channels, out_channels, 5, stride=stride)
self.cen = nn.Sequential(nn.Linear(8, 8), nn.ReLU(inplace=True), nn.Linear(8, 2), nn.Softmax(dim=0))
self.alpha = torch.Tensor([1., 0.])

class BasicModule(nn.Module):
def __init__(self, in_channels, out_channels, kernel=3, stride=1):
nn.Module.__init__(self)
# 标准的CBL模块
self.conv = nn.Conv2d(in_channels, out_channels, kernel, stride=stride, padding=(kernel - 1) // 2)
self.bn = nn.BatchNorm2d(out_channels)
self.activate = nn.ReLU(inplace=True)
# 前向传播
def forward(self, feature):
return self.activate(self.bn(self.conv(feature)))
可以看出Basic Module是一个典型的CBL模块。刚刚上面讲了关于Select Kernel中模块的信息,下面将详细地解释Select Kernel训练时的机制和原理(自己理解的,可能不太准确,请斧正)
def forward(self, feature):
# 这步是将basicblock中有关weight的变量全部提取出来,因为经过了BN层主要是计算他里面的weight的值的均值和均差。
vector = torch.cat(
[torch.mean(self.conv3.bn.running_mean).view(1), torch.std(self.conv3.bn.running_mean).view(1),
torch.mean(self.conv3.bn.running_var).view(1), torch.std(self.conv3.bn.running_var).view(1),
torch.mean(self.conv5.bn.running_mean).view(1), torch.std(self.conv5.bn.running_mean).view(1),
torch.mean(self.conv5.bn.running_var).view(1), torch.std(self.conv5.bn.running_var).view(1)], dim=0)
# 经过感知机,经过反馈后,在进行aplha值的反向传播和调整,返回alpha值
self.alpha = self.cen(vector)
return self.alpha[0] * self.conv3(feature) + self.alpha[1] * self.conv5(feature)



白化操作可以使输入的特征分布具有相同的均值和方差,固定了每一层的输入分布,从而加速网络的收敛。然而,白化操作虽然从一定程度上避免了梯度饱和,但也限制了网络中数据的表达能力,浅层学到的参数会被白化操作屏蔽掉,因此,BN层在白化操作后又增加了一个线性变换操作,让数据尽可能地恢复本身的表达能力,如下面的公式和上面的公式所示:


论文中提及到了可以新增一个卷积贡献分支,比如7*7的候选核,其公式也已经给予,如下:

为了突出显示最优核(为了看
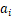 的大小,最终只留下最大的卷积核),我们需要获得不同核的稀疏权重。考虑到这一点由于是经过softmax,作者设计了以下正则项来实现这一点:
的大小,最终只留下最大的卷积核),我们需要获得不同核的稀疏权重。考虑到这一点由于是经过softmax,作者设计了以下正则项来实现这一点:
因为:
这个正则项是如何设计这权重稀疏的,以下是我的猜测。


所以这个损失函数就是:
相关源码如下:
经过感知机,经过反馈后,在进行aplha值的反向传播和调整,返回alpha值
self.alpha = self.cen(vector)
return self.alpha[0] * self.conv3(feature) + self.alpha[1] * self.conv5(feature)

# 完成对候选卷积核的筛选,当它的贡献值大于0.9时,选择大于0.9值的卷积核,否则就舍弃卷积核
def auto_select(self, threshold=0.9):
return self.conv3 if self.alpha[0] > threshold else self.conv5 if self.alpha[1] > threshold else None
# 完成对候选卷积核的筛选,当3*3卷积核贡献值大于5*5的卷积值,则选择3*3,反之,则亦然
def enforce_select(self):
return self.conv3 if self.alpha[0] > self.alpha[1] else self.conv5
上述代码就是选择贡献值大的卷积核,这里有两种选择方式,论文中也没有解释,所以这里结合源码来解释一下,解释的注释已经附上。
# 通过设定的正则化(损失函数)来得到score
def get_regularization(self):
# 如果需要链接的是Select Module,则其得到的正则化值为alpha值-torch.log(torch.sum(alpha**2)),乘10论文中的lamada值的
if isinstance(self.conv_module, SelectKernel):
return -10 * torch.log(self.conv_module.alpha[0] ** 2 + self.conv_module.alpha[1] ** 2)
上述源码就是解释了CEN的正则化项,公式且注释也赋予上面了。
总结
以上是训练时的内容,以后有时间在继续补充。
Original: https://blog.csdn.net/Jack003366/article/details/124100656
Author: Jack003366
Title: 关于基于SPFCN库位检测算法的解读与源码分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/597497/
转载文章受原作者版权保护。转载请注明原作者出处!