

文章目录
Kenlm的安装和训练方法见
KenLM使用教程
加载LM模型
import kenlm
LM = 'lm.apra'
model = kenlm.LanguageModel(LM)
print('{0}-gram model'.format(model.order))
model.score()
该api可以用于对一整句话进行打分,获取对应的分数。
sentence = '今 天 天 气 真 不 错'
print(sentence, model.score(sentence))
输出结果:


model.full_scores()
用于查看一句话中每个token的分数,但是这个api使用前提是你得先获取这一整句话。
words = [''] + sentence.split() + ['']
for i, (prob, length, oov) in enumerate(model.full_scores(sentence)):
print('{0} {1}: {2}'.format(prob, length, ' '.join(words[i + 2 - length:i + 2])))
if oov:
print('\t"{0}" is an OOV'.format(words[i + 1]))
for w in words:
if not w in model:
print('"{0}" is an OOV'.format(w))
输出结果:
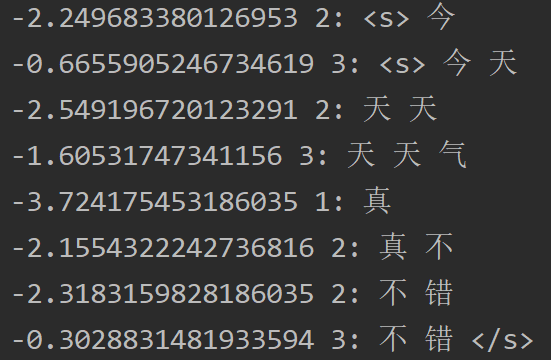
由于这里的分数都取log了,所以将每个字的分数相加就是整句话的分数,与model.score()得到的结果一致。
log P ( S ) = log ( P ( S 1 ∣ S 0 ) ∗ P ( S 2 ∣ S 0 S 1 ) ∗ P ( S 3 ∣ S 0 S 1 S 2 ) … P ( S n ∣ S 0 … S n − 1 ) ) = ∑ i = 1 n log P ( S i ∣ S 0 … S i − 1 ) \begin{aligned} \log P(S) &=\log (P(S_1|S_0)P(S_2|S_0S_1)P(S_3|S_0S_1S_2)\dots P(S_n|S_0\dots S_{n-1})) \ &=\sum_{i=1}^{n}\log P(S_i|S_0\dots S_{i-1}) \end{aligned}lo g P (S )=lo g (P (S 1 ∣S 0 )∗P (S 2 ∣S 0 S 1 )∗P (S 3 ∣S 0 S 1 S 2 )…P (S n ∣S 0 …S n −1 ))=i =1 ∑n lo g P (S i ∣S 0 …S i −1 )
model.BaseScore()
在实际解码过程中,一般使用自回归方法每个token依次出来,使用model.BaseScore()接口可以对预测的下一个token进行打分。
model.BaseScore(pre_state, token, cur_state)
- pre_state: 前一个token对应的state
- token: 当前要打分的token
- cur_state: 当前token对应的state
state_pre = kenlm.State()
model.BeginSentenceWrite(state_pre)
for ch in sentence.split(' '):
state = kenlm.State()
score = model.BaseScore(state_pre, ch, state)
print(ch, score)
state_pre = state
state = kenlm.State()
print('', model.BaseScore(state_pre, '', state))
输出结果:

参考代码
- https://github.com/kpu/kenlm/blob/master/python/example.py
Original: https://blog.csdn.net/qq_33424313/article/details/121054737
Author: 爱可乐的松鼠
Title: Kenlm python接口用法详细介绍
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/515242/
转载文章受原作者版权保护。转载请注明原作者出处!