

1 背景

梯度下降算法是目前最流行的优化算法之一,并且被用来优化神经网络的模型。业界知名的深度学习框架TensorFlow、Caffe等均包含了各种关于梯度下降优化算法的实现。然而这些优化算法经常被用作黑盒优化器,造成对这些算法的优缺点以及适用场景没有一个全面而深刻的认知,可能造成无法在特定的场景使用最优解。
本文主要对各种梯度下降优化算法进行了全面系统的分析,以帮助相关算法开发者在模型开发过程中选择合适的算法。相对而言,本内容将分为几章,以下为章节,本章将介绍与模型训练相关的问题以及高级优化器的优化方向–冲量、自适应学习率。
[En]
This paper mainly makes a comprehensive and systematic analysis of various gradient descent optimization algorithms to help relevant algorithm developers to select appropriate algorithms in the process of model development. Relatively speaking, this content will be divided into several chapters, the following is the chapter, this chapter will introduce the problems related to model training and the optimization direction of the advanced optimizer-impulse, adaptive learning rate.
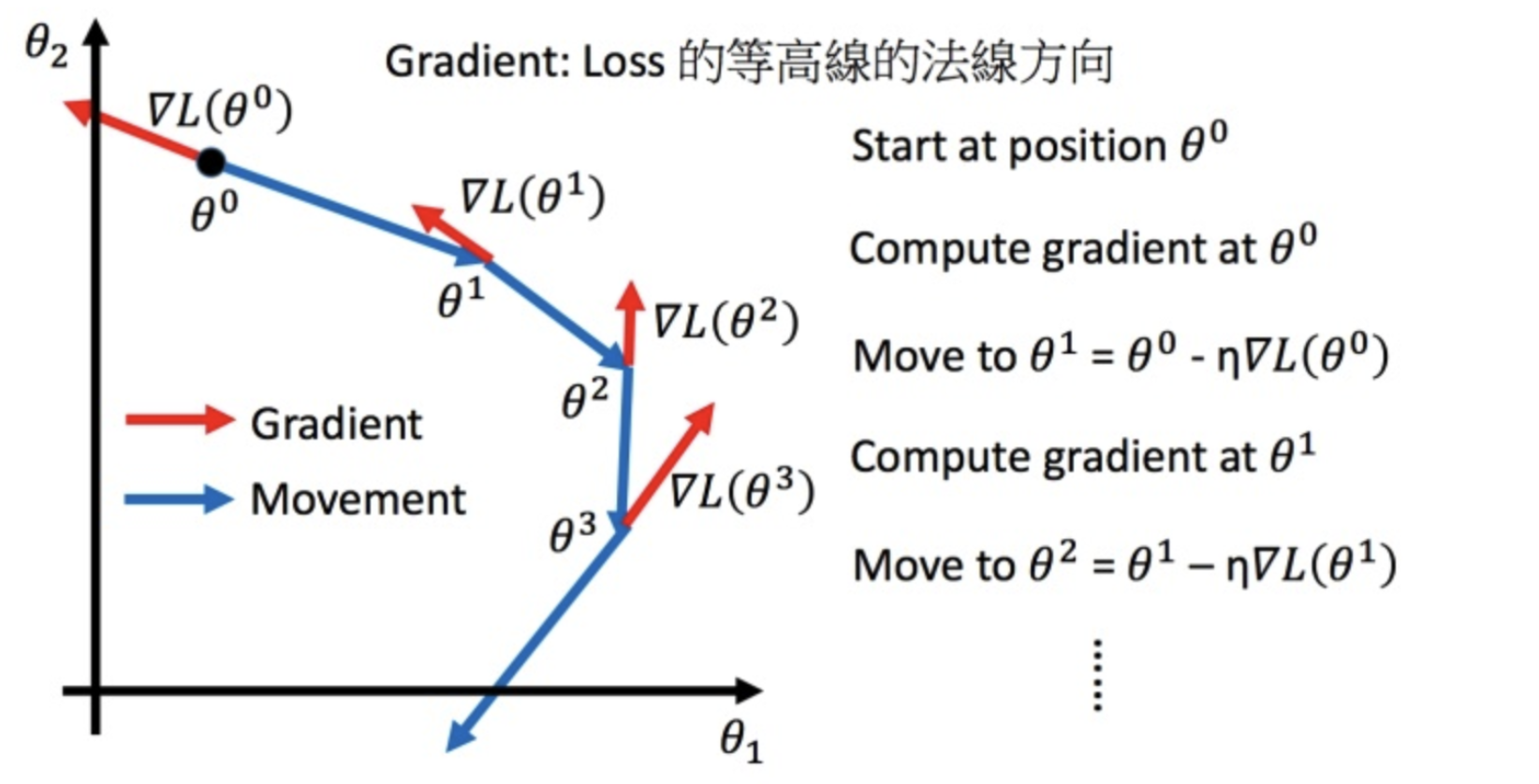
梯度下降法的目标是在与梯度相反的方向上更新模型参数。在几何上,由目标函数创建的曲面沿着坡度方向一直向下延伸到山谷(最快)。并通过合理的步长设置来加速和稳定算法模型的收敛,训练出更具通用性的模型。基本思路也可以理解为:我们从山上的某个点开始,走一步找最陡的坡(也就是找坡度的方向),然后找最陡的坡,然后再走一步,直到我们一直这样走。到最低点(最小成本函数的收敛点)。基于此,相关研究人员对该算法进行了广泛深入的研究。
[En]
The goal of the gradient descent method is to update the model parameters in the opposite direction of the gradient. Geometrically, the surface created by the objective function goes all the way down to the valley along the direction of the slope (the fastest). And through reasonable step size setting to accelerate and stabilize the convergence of the algorithm model, train a more generalized model. The basic idea can also be understood like this: we start from a certain point on the mountain, take a step to find the steepest slope (that is, to find the direction of the gradient), and then find the steepest slope, and then take another step, until we keep going like this. to the lowest point (the convergence point of the minimum cost function). Based on this, relevant researchers have carried out extensive and in-depth research on the algorithm.
相关符号:
- 模型的代价函数:J ( θ ) J(\theta)J (θ)
- 模型的相关参数:θ ∈ R d \theta \in R^d θ∈R d
- 参数的梯度:▽ θ J ( θ ) \bigtriangledown_{\theta}J(\theta)▽θJ (θ)
- 参数的梯度:η \eta η
本文继续上一个章节《深度学习框架TensorFlow系列之(五》优化器1》进行继续讲解,前面的章节描述了梯度下降及其衍生变体,并且提出了模型训练的挑战与难题,本章将进一步讲解。
; 2 模型训练遇到的挑战
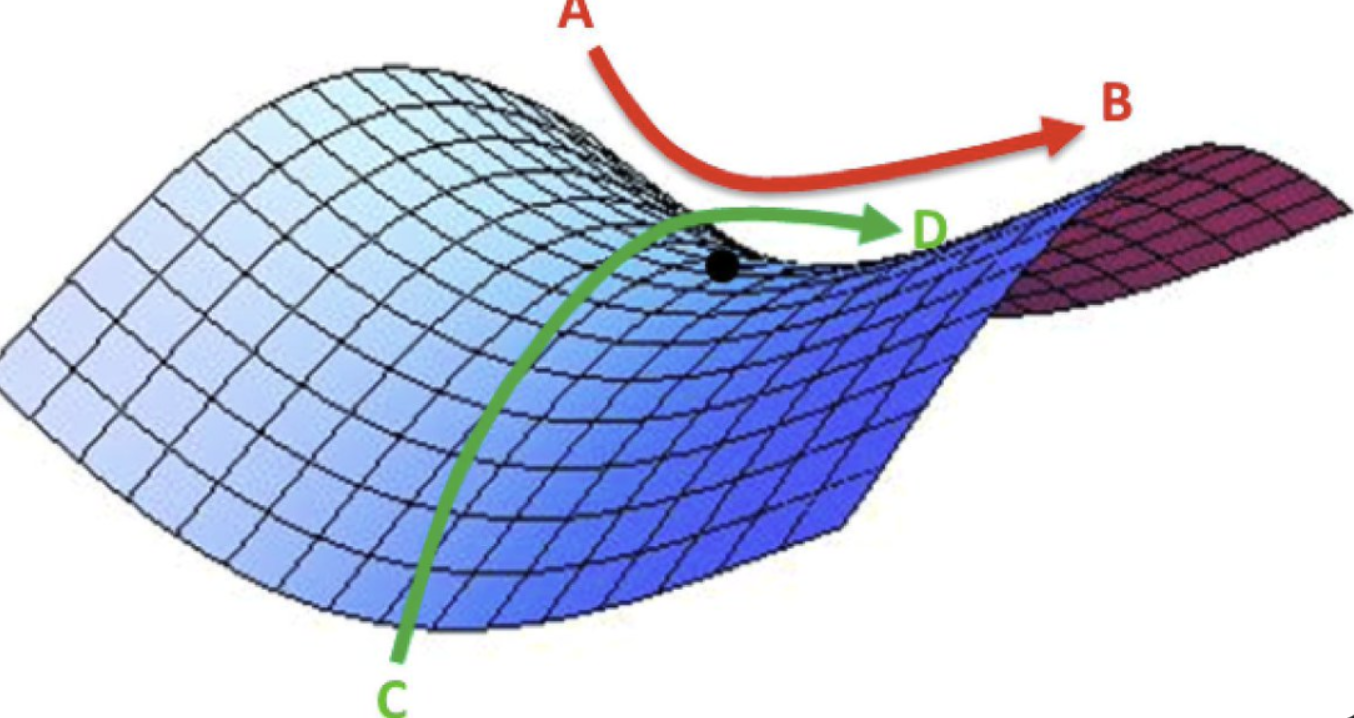
具体分析梯度更新过程中模型训练可能遇到的问题,见下图。
[En]
For a specific analysis of the problems that may be encountered in model training in the process of gradient update, please see the following figure.
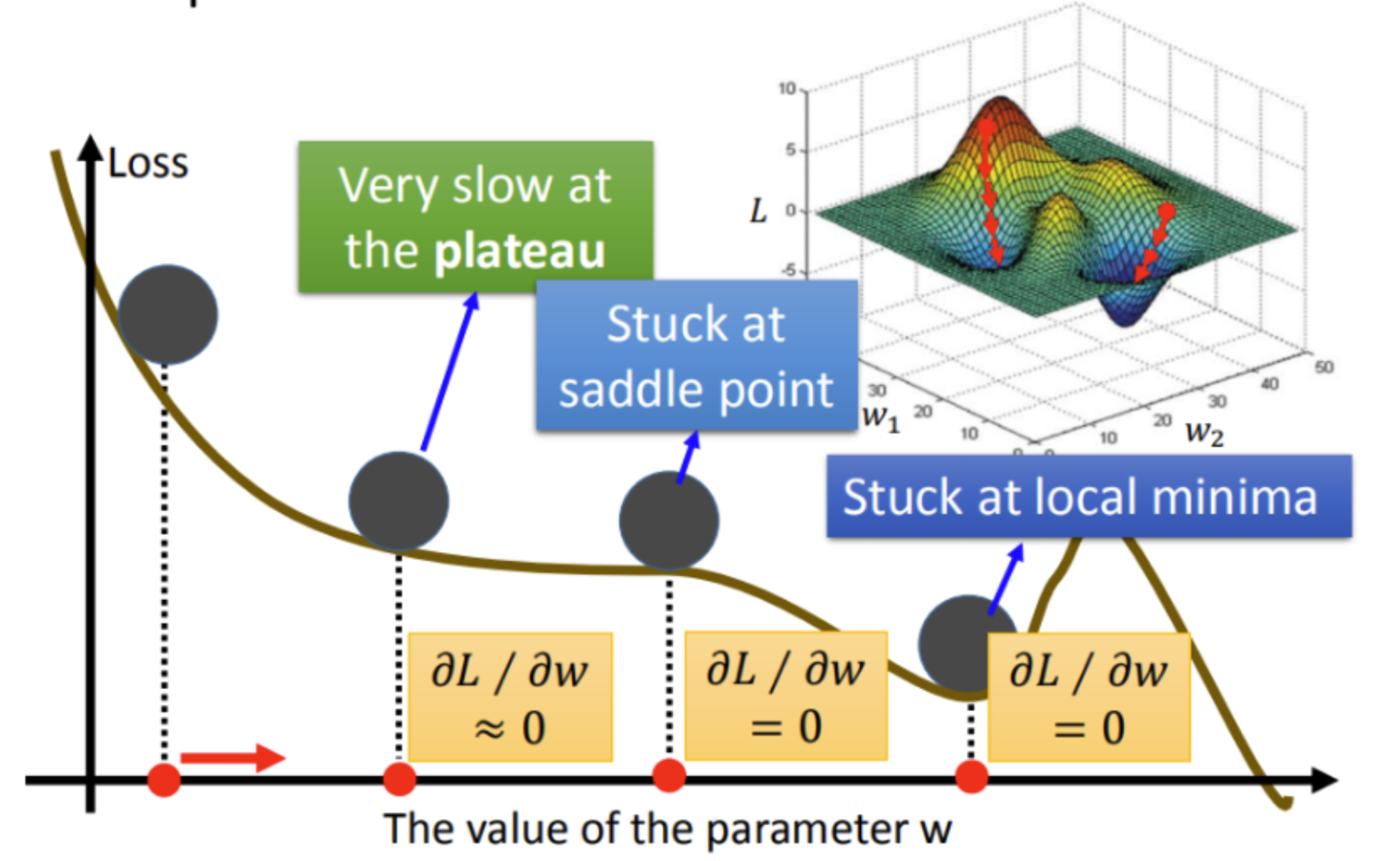
上图是基于回归模型的梯度更新示意图,从中我们可以看到几个关键点:
[En]
The above figure is a schematic diagram of a gradient update based on the regression model, in which we can see several key points:
- The Plateau:停滞点位,梯度值近乎于0,所以简单的梯度更新算法十分缓慢。
- Saddle Point:鞍点点位,梯度值等于0,所以简单的梯度更新算法基本无法跳出。
- Local Minima:局部最优解点位,相对于全局最优来说,所以简单的梯度更新算法。
让我们仔细分析这三种方法,看看是否有一种方法可以跳到全局最优,并确保收敛速度。
[En]
Let’s carefully analyze these three ways to see if there is a way to jump out to the global optimization and ensure the speed of convergence.
2.1 Local Minima – 局部最优解
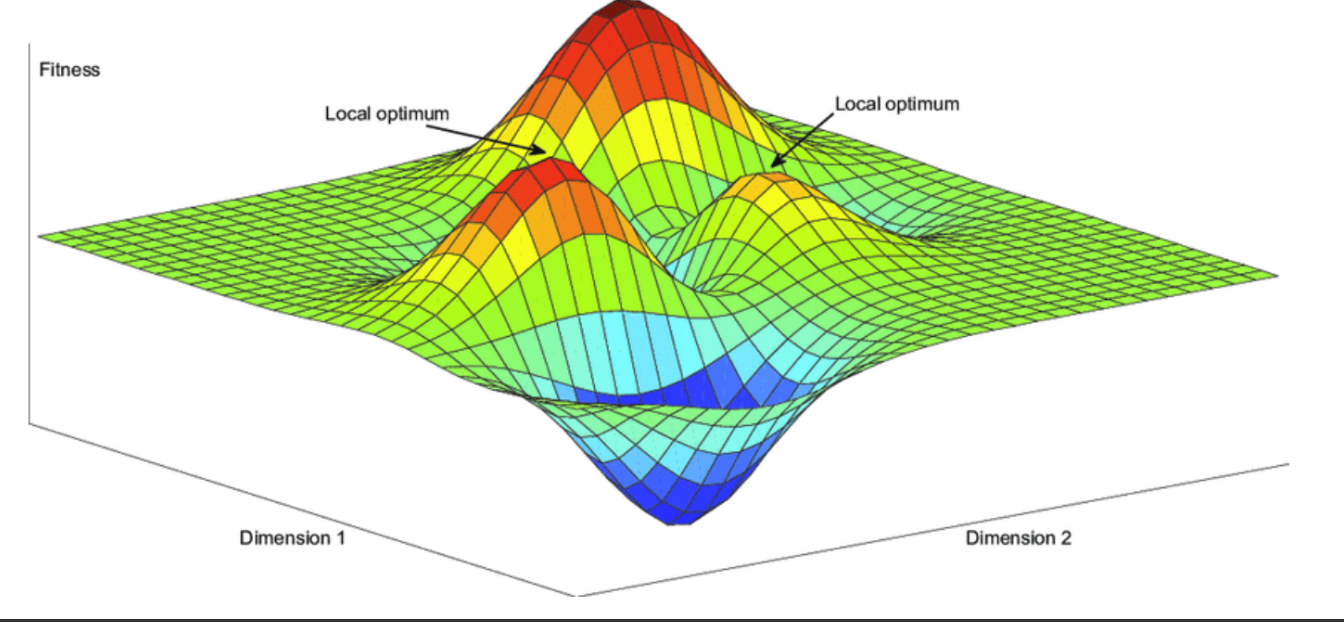
其实,工业界对于局部最优解的使用方式大抵如下(前提目前工业界都是比较大的深度神经网络):在需要吹牛的时候,会不断的鼓吹模型的局部最优解,并且进而夸大模型训练的难度,然后说自己采用了xxx高深的技术,跳出了局部最优,达到了全局最优的目标。其实吧,比较扯淡,大家做模型的时候其实根本很少考虑局部最优解的情况(而且很多人也没这个意识),默认都是达到了全局最优解,不收敛的话重新选特征改网络结构,重新再训一次。那么关于局部最优解与全局最优解有没有什么理论支撑呢,在什么情况下发生呢?在下不才,以自己浅薄的知识推导一番,如果不当之处,欢迎各位读者帮忙指正。
首先,无论是全局最优或者是局部最优我们统称为最优解(谷底),都是相对于所有的参数而言,需要在所有参数达到最优(谷底),那么我们假设目前的参数是N个,每个参数取得最优(谷底)的概率是P,则整体达到最优(谷底)的概率是P N P^N P N,以目前的工业界使用的深度学习模型为例,普遍都是百万级以上(SOTA模型动辄就达到千亿、万亿的参数),那么这个概率出现的是非常小的,所有当出现最优解的时候,很大程度上判断应该不是Local Minima,而是Global Minima。
所以,基本在工业界基本没有人费劲的去解所谓的”Local Minima”的问题,默认最优(谷底)就是全局的。我思故我在,我如果不思那就不在!基本就是不收敛改各种超参与网络重训,通过高级优化器与参数的配合改变梯度路径,上面说过所有参数一致的最优概率非常小,连续两次碰到的情况基本不太可能,进而重训会很大程度上会加快收敛速度与模型泛化能力。
但是,这个高级优化器的作用是解决局部优化的重点,引入冲量和自适应学习率,但很多人不理解,请继续前进。
[En]
However, what is in this advanced optimizer is to solve the focus of local optimization, introducing impulse and adaptive learning rate, but many people do not understand, please move on.
; 2.2 The Plateau & Saddle Point
对于停滞点和鞍点,我把两者放在一起,主要是因为有很多相似之处。
[En]
For the stagnation point and the saddle point, I put the two together, mainly because there are a lot of similarities.
上面的梯度下降图中,其实是一个参数的情况,而Local Minima是所有参数一致达到谷底的情况。但是这个The Plateau & Saddle Point其实是针对每个参数的特征而言的,所以有很大的不同。
针对一些参数的梯度更新很小或为零的情况,普通的梯度下降法此时无能为力,因为它只基于当前的梯度,基本很难走出去,导致模型不收敛。精确的模型是无法训练的。
[En]
In view of the situation that the gradient update of some parameters is very small or zero, the ordinary gradient descent method is powerless at this time, because it is only based on the current gradient, it is basically difficult to go out, resulting in the non-convergence of the model. An accurate model cannot be trained.
接下来,我们来看看如何解决这个问题。
[En]
Next, let’s see how to solve the problem.
2.3 解决办法
基于上述情况,我们有没有解决的办法?事实上,没有一门学科是孤立的。我们可以相互借鉴,融合自然界中的许多原则和规律,例如:
[En]
Based on the above situation, do we have some ways to solve it? in fact, no discipline is isolated. We can learn from each other and integrate many principles and laws in nature, such as:
我们很多人都有其自行车下坡的经验,这个过程和梯度下降非常类似,或者开车下陡坡的经验也是类似的,当我们从一个陡坡往下骑车的时候,我们基本不太需要去蹬车,同时车速也会越来越快,所以我们需要不断的捏闸,让车速慢下来。最终安全地到达坡底。
所以,总而言之,我们目前简单的坡度下降相对于骑自行车下陡坡的缺失部分。
[En]
So, to sum up, the missing part of our current simple gradient descent relative to cycling down a steep slope.
- 前进力-惯性:下坡时候的车速不仅仅取决于目前的力度,也取决于以前积累的加速;
- 回退力-闸:下坡的时候通过闸来调整车的加速比。
那么这两个要素在梯度下降里面,我们采用了两个新名词,动量(亦叫冲量)Momentum,动态自适应学习率 Learning Rate。下面就讲解下这两个技术点。
; 3 动量(冲量)
动量定义:在经典力学里,物体所受合外力的冲量等于它的动量的增量(即末动量减去初动量),叫做动量定理。 和动量是状态量不同,冲量是一个过程量;在DL中定义如下,在梯度下降算法中,结合以往参数梯度更新的惯性,予以累积,进而影响本次的梯度更新。
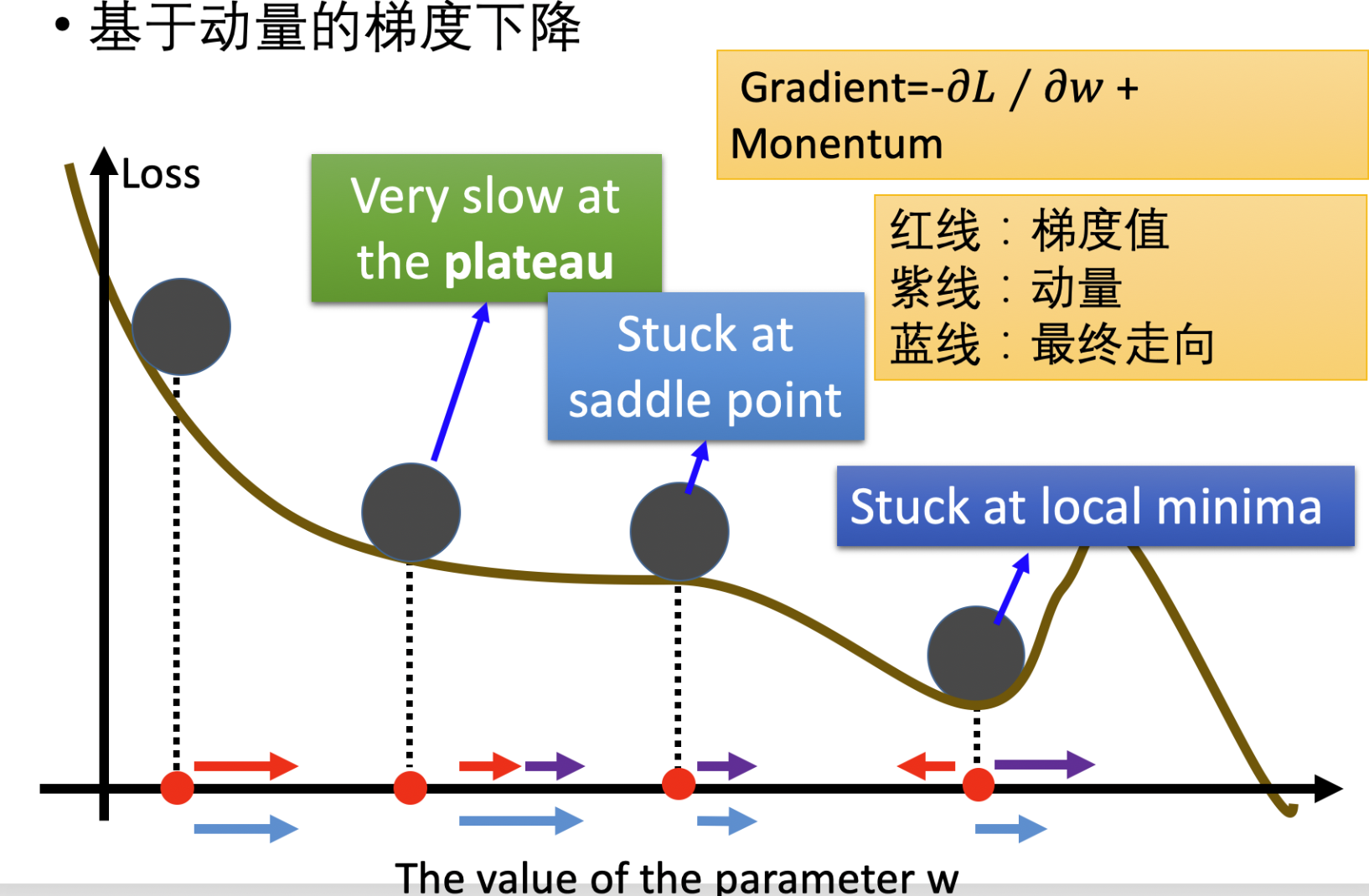
其实这里面有个逻辑问题,不是说使用了动量就一定可以达到最优解,只是有可能,提供了这么一种可能,具体怎么做,还需要算法人员来调参尝试。说实话,DL的数学严谨度是不够的,很多理论支撑是苍白的,不过行业目前就这样,经常在知乎看到学数学的吐槽这点,很多东西缺乏严谨的理论支撑,但是乱拳打死老师傅,就先这样来吧,配合上面的图,我们从理想态描述下:
- 点位一:梯度下降的红色箭头方向是往右的,假设其是起始点,此时没有冲量(惯性)。所以实际移动的方向就是梯度下降的方向,向右运动。
- 点位二:梯度下降的红色箭头方向是向右的(非常小的梯度),动量的紫色箭头方向也是向右的,所以向右运动。
- 点位三:此处是鞍点,梯度下降等于0,动量的紫色箭头方向也是向右的,所以向右运动。
- 点位四:此处是局部最优,此时我们的梯度下降的红色箭头方向是向左的,这个时候如果我们的动量值 > 梯度的值。就会继续向上走,如果值够大,可以跳出local minima。
从上面的描述,大家可以看到了冲量在梯度下降中的很多关键点位还是有很重要的作用的,如果应用的好,会极大的加快模型收敛的速度和模型的泛化性能。下面接着介绍下另外一个重点的内容Learning Rate。
4 Learning Rate – 学习率
学习率 Learning Rate定义::表示了每次参数更新的幅度大小。 学习率过大:会导致待优化的参数在最小值附近进行波动;
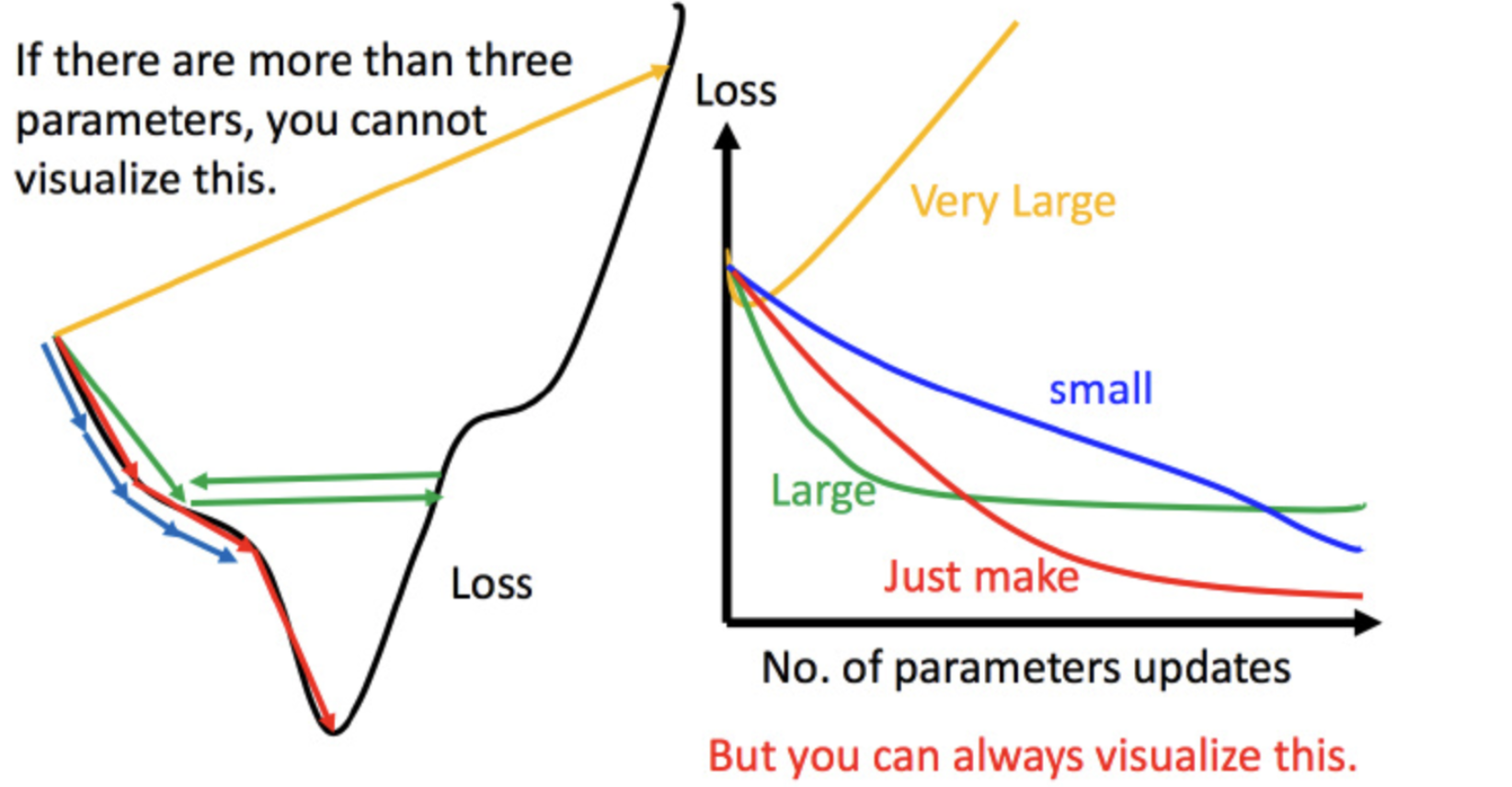
左边的黑色是损失函数的曲线,假设它从左边的最高点开始。
[En]
The black on the left is the curve of the loss function, assuming that it starts from the highest point on the left.
- 学习率调整恰到好处,如红线,即可成功找到最低点
[En]
if the learning rate is adjusted just right, such as the red line, you can successfully find the lowest point.*
- 若调整学习率过小,如蓝线,则走得太慢,虽然这种情况给了足够的时间寻找最低点,但实际情况可能不会等结果
[En]
if the learning rate is adjusted too small, such as the blue line, it will walk too slowly, although this situation gives enough time to find the lowest point, the actual situation may not wait for the result.*
- 如果学习率调整得有点过头,比如绿线,就会在上面震动,走不下去,永远也不会到最低点。
[En]
if the learning rate is adjusted a little too much, such as the green line, it will vibrate on it, can not go on, and will never reach the lowest point.*
- 如果学习率调整得很大,比如黄线,直接飞出来,更新参数时才会发现,损失函数更新越多,规模就越大。
[En]
if the learning rate is adjusted very large, such as the yellow line, it will fly out directly, and when you update the parameters, you will only find that the more the loss function is updated, the larger it will be.*
解决方案是上图右侧的解决方案,它直观地显示了参数变化对损失函数的影响。虽然可以直观地观察到这样的可视化,但只有当参数是一维或二维时才能进行可视化,更高维的情况不能再可视化。(你可以考虑子参数可视化,但这太难了,而且训练过程中不同样本的组合也很奇怪,很多都只是理论方案。)
[En]
The solution is the solution on the right side of the image above, which visualizes the impact of parameter changes on the loss function. Although such visualization can be intuitively observed, visualization can only be carried out when the parameters are one-dimensional or two-dimensional, and higher-dimensional cases can no longer be visualized. (you can consider sub-parameter visualization, but this is too hard, and the combination of different samples in the training process is strange, and many of them are just theoretical schemes.)
- 比如学习率太小(蓝线),损失函数下降很慢
[En]
for example, the learning rate is too small (blue line), and the loss function decreases very slowly.*
- 学习率过高(绿线),损失函数快速下降,但即刻陷入胶着
[En]
the learning rate is too high (green line), and the loss function decreases rapidly, but it immediately becomes stuck.*
- 若学习率很高(黄线),损失功能将飞出
[En]
if the learning rate is very high (yellow line), the loss function will fly out.*
- 红色的正好,可以得到不错的结果
[En]
the red one is just about right, and you can get a good result.*
如果它不现实,每次参数太多,那么我们想要把它应用到工业中,我们需要一个自适应的学习率,粒度可能是不同的参数,不同时期的不同参数。
[En]
If it is unrealistic and there are too many parameters every time, then if we want to apply it in industry, we need an adaptive learning rate, and the granularity may be different parameters, different parameters in different periods.
; 5 梯度下降的高级用法
从上面的描述和目前业界的主流实践可以看出,高级优化器算法对于动量和学习率(可能不是最优的,但相对原始的已经有了很大的进步)是智能的和自适应的,粒度可能是参数级别和不同时间的基本组合。这些措施包括:
[En]
From the above description and the current mainstream practices in the industry, we can know that advanced optimizer algorithms are intelligent and adaptive for momentum and learning rate (may not be optimal, but relatively primitive has been a great progress), granularity may be a basic combination of parameter levels and different times. These include:
- NAG
- Adagrad
- Adadelta
- RMSprop
- Adam
- AdaMax
- Nadam等
这些优化器将在随后的章节中进一步描述,也就是本章的结尾。
[En]
These optimizers will be further described in subsequent chapters, which is the end of this chapter.
6 番外篇
个人介绍:杜宝坤,隐私计算行业从业者,从0到1带领团队构建了京东的联邦学习解决方案9N-FL,同时主导了联邦学习框架与联邦开门红业务。
框架层面:实现了电商营销领域支持超大规模的工业化联邦学习解决方案,支持超大规模样本PSI隐私对齐、安全的树模型与神经网络模型等众多模型支持。
业务层面:实现了业务良好开局,打造了新的业务增长点,产生了显著的业务经济效益。[En]
Business level: it has achieved a good start to the business, created a new business growth point, and produced significant business economic benefits.
个人比较喜欢学习新东西,乐于钻研技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到机器学习算法与算法框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:baokun06@163.com
Original: https://blog.csdn.net/qq_22054285/article/details/122750535
Author: 秃顶的码农
Title: 深度学习框架TensorFlow系列之(五)优化器2
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/514912/
转载文章受原作者版权保护。转载请注明原作者出处!