

目录
实现结果如下:


百度API
这里实现语音翻译功能是结合上一遍的语音识别(https://blog.csdn.net/weixin_47292166/article/details/121273428)和新的百度API通用文本翻译去实现的。 所以我们仍需要在百度AI开放平台-全球领先的人工智能服务平台里去进行通用文本翻译的应用创建然后获取自己的ID、API key和Secre Key。

进入百度AI平台后选择开放能力下的语音技术–>自然语言处理–>通用文本翻译
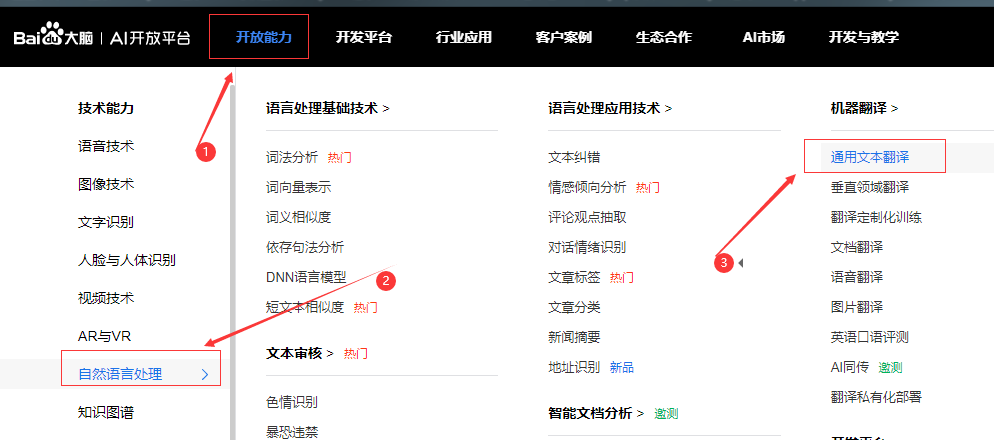
选择【立即使用】进入,然后选择【创建应用】,根据提示创建完成即可获得自己的ID、API key和Secre Key。
对百度API的调用和access_token的获取以及具体参数使用方法可以参考里面的【技术文档内容https://ai.baidu.com/ai-doc/MT/4kqryjku9】,这里只说在代码里具体用到的内容。(看代码部分)
tkineter界面设计
1.界面的初始化及布局:
def __init__(self):
self.api_key = '语音翻译的key'
self.secret_key = '语音翻译的secret'
self.token = self.get_token(self.api_key, self.secret_key)
self.ID = '语音识别的ID'
self.Key = '语音识别的key'
self.Secret = '语音识别的secret'
# 用语音类创建对象
self.client = AipSpeech(self.ID, self.Key, self.Secret) # 语音识别对象
#创建窗口
self.screen = Tk()# Toplevel() # Tk()
self.screen.resizable(width=False, height=False)
self.screen.title('语音翻译') #设置标题
self. screen. geometry('500x800') #设置窗口大小
# 打开图像,转为tkinter兼容的对象,
img = Image.open('3.jpg').resize([500,800])
self.img = ImageTk.PhotoImage(img)
#创建画布,将图像作为画布背景, 铺满整个窗口
self.canvas = Canvas(self.screen, width=500, height=800) #设置画布的宽、高
self.canvas.place(x=0, y=0)
self.canvas.create_image(250,400,image = self.img) #把图像放到画布,默认放置中心点
self.canvas.create_text(250, 100, text='语音翻译', font=('宋体', 40))
self.canvas.create_text(110, 170, text='原文:', font=('宋体', 20),fill = 'green')
self.canvas.create_text(110, 270, text='译文:', font=('宋体', 20),fill = 'blue')
# 创建标题标签
# Label(self.screen, bg='royalblue', text='语音翻译', font=('宋体', 40), fg='white').pack(pady=90) # 上下间隔100
# 创建原文标签
# Label(self.screen, bg='dodgerblue', text='原文:', font=('宋体', 20), fg='white').place(x=100, y=150)
# 创建原文文本框
self.original = Text(self.screen, width=22,height = 2, font=('宋体', 20))
self.original.place(x=100, y=200)
# 创建译文标签
# Label(self.screen, bg='dodgerblue', text='译文:', font=('宋体', 20), fg='white').place(x=100, y=250)
# 创建译文文本框
self.Translation = Text(self.screen, width=22,height = 2, font=('宋体', 20))
self.Translation.place(x=100, y=300)
# 创建按钮
Button(self.screen, width=10, text='文本翻译', font=('宋体', 20), fg='white',
command=lambda :self.text_run(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=80, y=600) # activebackground 设置按键按下有变化 activebforeground设置前景色
Button(self.screen, width=10, text='语音翻译', font=('宋体', 20), fg='white',
command=lambda :self.adio_run(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=280, y=600)
Button(self.screen, width=25, text='返回', font=('宋体', 20), fg='white',
command=lambda :self.jumpweb(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=80, y=650)
Button(self.screen, width=5, text='清空', font=('宋体', 20), fg='white',
command=lambda: self.delete_text(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=330, y=380)
self.screen.mainloop(0)
2.access_token的获取模块
def get_token(self,key,secret):
url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + key + '&client_secret=' + secret
response = requests.post(url)
result = response.json()
result = result['access_token']
return result
- 确定源语言和翻译的目标语言模块
def is_eng(self,text):
if ord(text[0]) in range(ord('a'), ord('z') + 1) or ord(text[0]) in range(ord('A'), ord('Z') + 1):
return 'en', 'zh'
else:
return 'zh', 'en'
4.语言翻译模块(这里就是调用百度文本翻译API实现的)
def translate(self,text,token):
url = 'https://aip.baidubce.com/rpc/2.0/mt/texttrans/v1'
# 参数:URL + access_token
# 请求参数:from 什么语音 to 什么语音,q 翻译什么内容
fr, tr = self.is_eng(text[0])
url = url + '?access_token=' + token + '&from=' + fr + '&to=' + tr + '&q=' + text
response = requests.post(url)
result = response.json()
result = result['result']['trans_result'][0]['dst']
return result
5.录音模块(根据声音的有无决定录音的结束):
def get_adio(self,sec=0):
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=1024)
wf = wave.open('test.wav', 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(16000)
print('开始说话')
stopflag = 0
conflag = 0
while True:
data = stream.read(1024)
rt_data = np.frombuffer(data, np.dtype(' 7000:
conflag += 1
else:
stopflag += 1
oneSecond = int(16000 / 1024)
if stopflag + conflag > oneSecond: # 如果两种情况的次数超过一帧的大小
if stopflag > oneSecond // 3 * 2: # 其中无声的部分超过一帧的2/3,则停止
break
else:
stopflag = 0
conflag = 0
wf.writeframes(data)
print('停止说话')
stream.stop_stream()
stream.close()
p.terminate()
wf.close()
return 'test.wav'
6.语音转文本模块(这里就是调用的百度API去语音识别)
def StoT(self):
file = self.get_adio()
# 调用对象进行识别,需要为对象传递参数:
# 识别三种格式:wav,pcm,amr
# 语音文件,语音格式,采样频率,识别ID(1573:中文普通话)
Format = file[-3:]
data = open(file, 'rb').read()
result = self.client.asr(data, Format, 16000, {'dev_pid': 1537})
result = result['result'][0]
# print(result)
return result
7.文本朗读模块(这里是调用python里的pyttsx3库去实现将文本语音播放出来)
def say(self,text):
engine = pyttsx3.init()
engine.say(text)
engine.runAndWait()
PS:这里5-7步骤其实跟语言识别的2-4是一样的
完整代码:
from tkinter import *
from PIL import Image,ImageTk
import requests
import pyttsx3
import pyaudio
from scipy import fftpack
import wave
import numpy as np
from aip import AipSpeech
#主界面面设计,创建类,在构造方法中没计界面
class TransPage():
def __init__(self):
self.api_key = '语音翻译的key'
self.secret_key = '语音翻译的secret'
self.token = self.get_token(self.api_key, self.secret_key)
self.ID = '语音识别的ID'
self.Key = '语音识别的key'
self.Secret = '语音识别的secret'
# 用语音类创建对象
self.client = AipSpeech(self.ID, self.Key, self.Secret) # 语音识别对象
#创建窗口
self.screen = Tk()# Toplevel() # Tk()
self.screen.resizable(width=False, height=False)
self.screen.title('语音翻译') #设置标题
self. screen. geometry('500x800') #设置窗口大小
# 打开图像,转为tkinter兼容的对象,
img = Image.open('3.jpg').resize([500,800])
self.img = ImageTk.PhotoImage(img)
#创建画布,将图像作为画布背景, 铺满整个窗口
self.canvas = Canvas(self.screen, width=500, height=800) #设置画布的宽、高
self.canvas.place(x=0, y=0)
self.canvas.create_image(250,400,image = self.img) #把图像放到画布,默认放置中心点
self.canvas.create_text(250, 100, text='语音翻译', font=('宋体', 40))
self.canvas.create_text(110, 170, text='原文:', font=('宋体', 20),fill = 'green')
self.canvas.create_text(110, 270, text='译文:', font=('宋体', 20),fill = 'blue')
# 创建标题标签
# Label(self.screen, bg='royalblue', text='语音翻译', font=('宋体', 40), fg='white').pack(pady=90) # 上下间隔100
# 创建原文标签
# Label(self.screen, bg='dodgerblue', text='原文:', font=('宋体', 20), fg='white').place(x=100, y=150)
# 创建原文文本框
self.original = Text(self.screen, width=22,height = 2, font=('宋体', 20))
self.original.place(x=100, y=200)
# 创建译文标签
# Label(self.screen, bg='dodgerblue', text='译文:', font=('宋体', 20), fg='white').place(x=100, y=250)
# 创建译文文本框
self.Translation = Text(self.screen, width=22,height = 2, font=('宋体', 20))
self.Translation.place(x=100, y=300)
# 创建按钮
Button(self.screen, width=10, text='文本翻译', font=('宋体', 20), fg='white',
command=lambda :self.text_run(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=80, y=600) # activebackground 设置按键按下有变化 activebforeground设置前景色
Button(self.screen, width=10, text='语音翻译', font=('宋体', 20), fg='white',
command=lambda :self.adio_run(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=280, y=600)
Button(self.screen, width=25, text='返回', font=('宋体', 20), fg='white',
command=lambda :self.jumpweb(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=80, y=650)
Button(self.screen, width=5, text='清空', font=('宋体', 20), fg='white',
command=lambda: self.delete_text(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=330, y=380)
self.screen.mainloop(0)
def delete_text(self):
self.original.delete(0.0,END)
self.Translation.delete(0.0,END)
def get_token(self,key,secret):
url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + key + '&client_secret=' + secret
response = requests.post(url)
result = response.json()
result = result['access_token']
return result
# print(get_token(api_key,secret_key))
# 确定源语言和翻译的目标语言
def is_eng(self,text):
if ord(text[0]) in range(ord('a'), ord('z') + 1) or ord(text[0]) in range(ord('A'), ord('Z') + 1):
return 'en', 'zh'
else:
return 'zh', 'en'
def translate(self,text,token):
url = 'https://aip.baidubce.com/rpc/2.0/mt/texttrans/v1'
# 参数:URL + access_token
# 请求参数:from 什么语音 to 什么语音,q 翻译什么内容
fr, tr = self.is_eng(text[0])
url = url + '?access_token=' + token + '&from=' + fr + '&to=' + tr + '&q=' + text
response = requests.post(url)
result = response.json()
result = result['result']['trans_result'][0]['dst']
return result
# print(result)
# 创建函数进行语音播放
def say(self,text):
engine = pyttsx3.init()
engine.say(text)
engine.runAndWait()
def text_run(self):
text = self.original.get(0.0,END)
self.Translation.insert('insert',self.translate(text, self.token))
# print('翻译内容:', self.translate(text, self.token))
self.say(self.translate(text, self.token))
def get_adio(self,sec=0):
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=1024)
wf = wave.open('test.wav', 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(16000)
print('开始说话')
stopflag = 0
conflag = 0
while True:
data = stream.read(1024)
rt_data = np.frombuffer(data, np.dtype(' 7000:
conflag += 1
else:
stopflag += 1
oneSecond = int(16000 / 1024)
if stopflag + conflag > oneSecond: # 如果两种情况的次数超过一帧的大小
if stopflag > oneSecond // 3 * 2: # 其中无声的部分超过一帧的2/3,则停止
break
else:
stopflag = 0
conflag = 0
wf.writeframes(data)
print('停止说话')
stream.stop_stream()
stream.close()
p.terminate()
wf.close()
return 'test.wav'
def StoT(self):
file = self.get_adio()
# 调用对象进行识别,需要为对象传递参数:
# 识别三种格式:wav,pcm,amr
# 语音文件,语音格式,采样频率,识别ID(1573:中文普通话)
Format = file[-3:]
data = open(file, 'rb').read()
result = self.client.asr(data, Format, 16000, {'dev_pid': 1537})
result = result['result'][0]
# print(result)
return result
def adio_run(self):
text = self.StoT()
self.original.insert('insert',text)
self.Translation.insert('insert',self.translate(text, self.token))
# print('原文:',text)
# print('翻译内容:', self.translate(text, self.token))
self.say(self.translate(text, self.token))
def jumpweb(self):
self.screen.destroy()
TransPage()
素材:

Original: https://blog.csdn.net/weixin_47292166/article/details/121316745
Author: 张顺财
Title: 【python】tkinter界面化+百度API—语音翻译(二)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/513138/
转载文章受原作者版权保护。转载请注明原作者出处!