

Mnist数据集是深度学习入门的数据集,昨天发现了Chinese-Mnist数据集,与Mnist数据集类似,只不过是汉字数字,例如’一’、’二’、’三’等,本次实验利用自己搭建的CNN网络实现Chinese版的手写数字识别。
1.导入库
import tensorflow as tf
import matplotlib.pyplot as plt
import os,PIL,pathlib
import numpy as np
import pandas as pd
import warnings
from tensorflow import keras
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
2.数据加载
原数据中包括15000张图片,如下所示:


原数据并没有将各类数据分开,而是给出了一个csv文件:
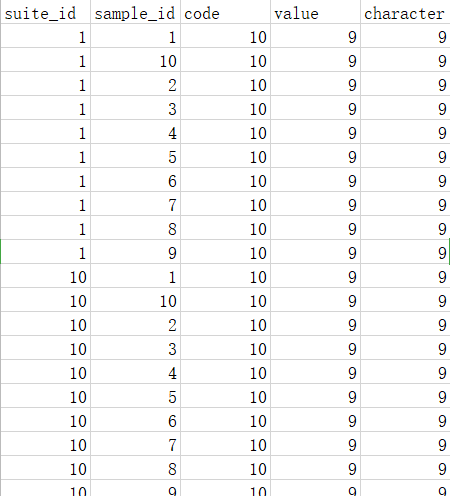
在进行训练之前将图片分类,首先对数据的标签进行切片
train = pd.read_csv("E:/tmp/.keras/datasets/chinese_mnist/chinese_mnist.csv")
train_image_label = [i for i in train["character"]]
train_label_ds = tf.data.Dataset.from_tensor_slices(train_image_label)
统计每张图片的具体路径:
img_dir = "E:/tmp/.keras/datasets/chinese_mnist/data/data/input"
train_image_paths = []
for row in train.itertuples():
suite_id = row[1]
sample_id = row[2]
code = row[3]
train_image_paths.append(img_dir+"_"+str(suite_id)+"_"+str(sample_id)+"_"+str(code)+".jpg")
train_path_ds = tf.data.Dataset.from_tensor_slices(train_image_paths)
train_image_paths结果如下:
E:/tmp/.keras/datasets/chinese_mnist/data/data/input_1_1_10.jpg
读取图片并进行预处理,然后切片
def preprocess_image(image):
image = tf.image.decode_jpeg(image,channels = 3)
image = tf.image.resize(image,[height,width])
return image / 255.0
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
train_image_ds = train_path_ds.map(load_and_preprocess_image,num_parallel_calls=tf.data.experimental.AUTOTUNE)
将train_image_ds与train_label_ds组合在一起
image_label_ds = tf.data.Dataset.zip((train_image_ds,train_label_ds))
显示图片:
for i in range(20):
plt.subplot(4, 5, i + 1)
num +=1
plt.xticks([])
plt.yticks([])
plt.grid(False)
images = plt.imread(train_image_paths[i])
plt.imshow(images)
plt.xlabel(train_image_label[i])
plt.show()
在并未对数据进行shuffle之前,如下所示:

原数据中一共15000张图片,分为15类,每类1000张,并按照顺序排列,因此需要对数据进行打乱。
image_label_ds = image_label_ds.shuffle(15000)
按照8:2的比例划分训练集与测试集
train_ds = image_label_ds.take(12000).shuffle(2000)
test_ds = image_label_ds.skip(12000).shuffle(3000)
超参数的设置
height = 64
width = 64
batch_size = 128
epochs = 50
对训练集与测试集进行batch_size 划分
train_ds = train_ds.batch(batch_size)
train_ds = train_ds.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
test_ds = test_ds.batch(batch_size)
test_ds = test_ds.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
再次检查图片,看看是否被打乱顺序:
plt.figure(figsize=(8, 8))
for images, labels in train_ds.take(1):
for i in range(12):
ax = plt.subplot(4, 3, i + 1)
plt.imshow(images[i])
plt.title(labels[i].numpy())
plt.axis("off")
break
plt.show()

顺序已被打乱,初始目标完成。
3.网络搭建&&编译
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32,kernel_size=(3,3),padding="same",activation="relu",input_shape=[64, 64, 3]),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),padding="same",activation="relu"),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),padding="same",activation="relu"),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(15, activation="softmax")
])
model.compile(optimizer="adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
history = model.fit(
train_ds,
validation_data=test_ds,
epochs = epochs
)
经过50次epochs,训练结果如下:
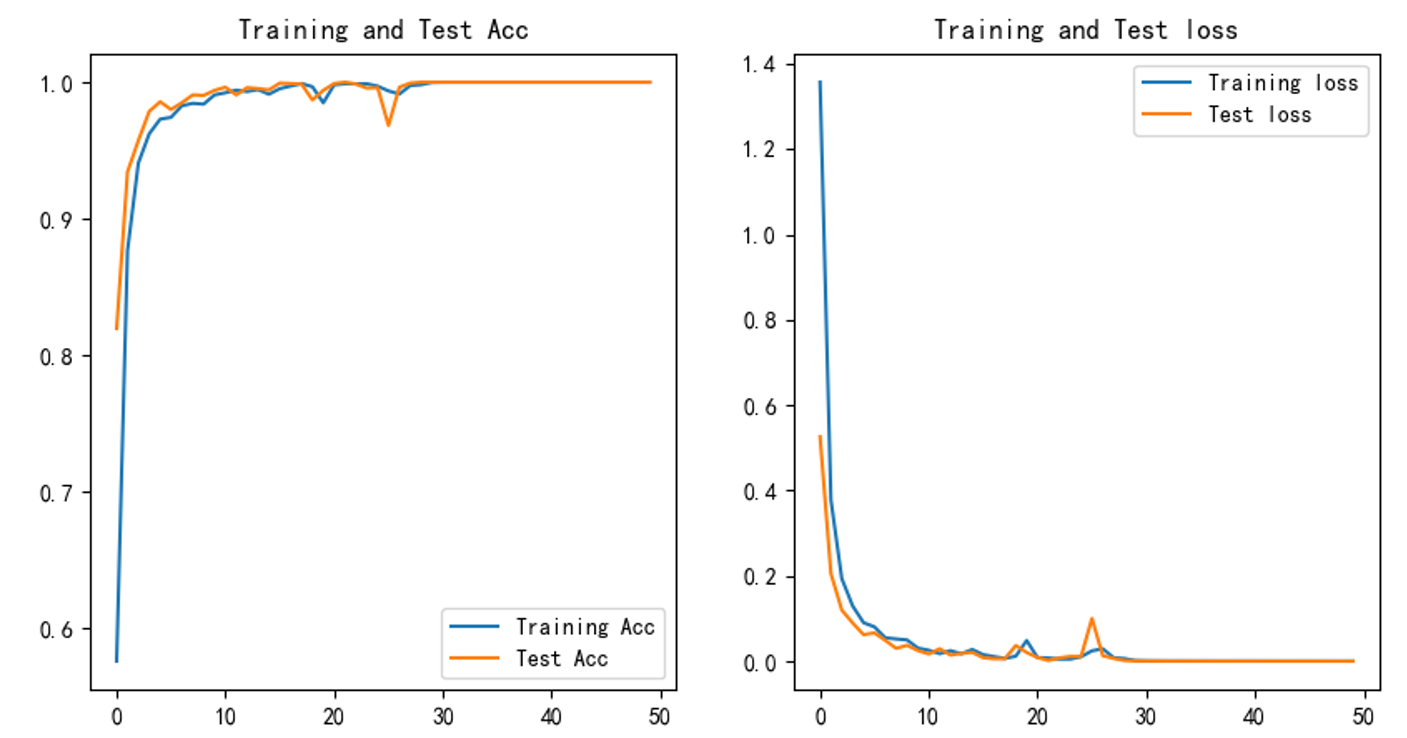
准确率达到了100%
4.混淆矩阵的绘制
模型加载:
model = tf.keras.models.load_model("E:/Users/yqx/PycharmProjects/chinese_mnist/model.h5")
标签列表如下所示:
all_label_names = ['零','一','二','三','四','五','六','七','八','九','十','百','千','万','亿']
绘制混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd
all_label_names = ['零','一','二','三','四','五','六','七','八','九','十','百','千','万','亿']
def plot_cm(labels, pre):
conf_numpy = confusion_matrix(labels, pre)
conf_df = pd.DataFrame(conf_numpy, index=all_label_names,
columns=all_label_names)
plt.figure(figsize=(8, 7))
sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")
plt.title('混淆矩阵', fontsize=15)
plt.ylabel('真实值', fontsize=14)
plt.xlabel('预测值', fontsize=14)
plt.show()
model = tf.keras.models.load_model("E:/Users/yqx/PycharmProjects/chinese_mnist/model.h5")
test_pre = []
test_label = []
for images, labels in test_ds:
for image, label in zip(images, labels):
img_array = tf.expand_dims(image, 0)
pre = model.predict(img_array)
test_pre.append(all_label_names[np.argmax(pre)])
test_label.append(all_label_names[label.numpy()])
plot_cm(test_label, test_pre)
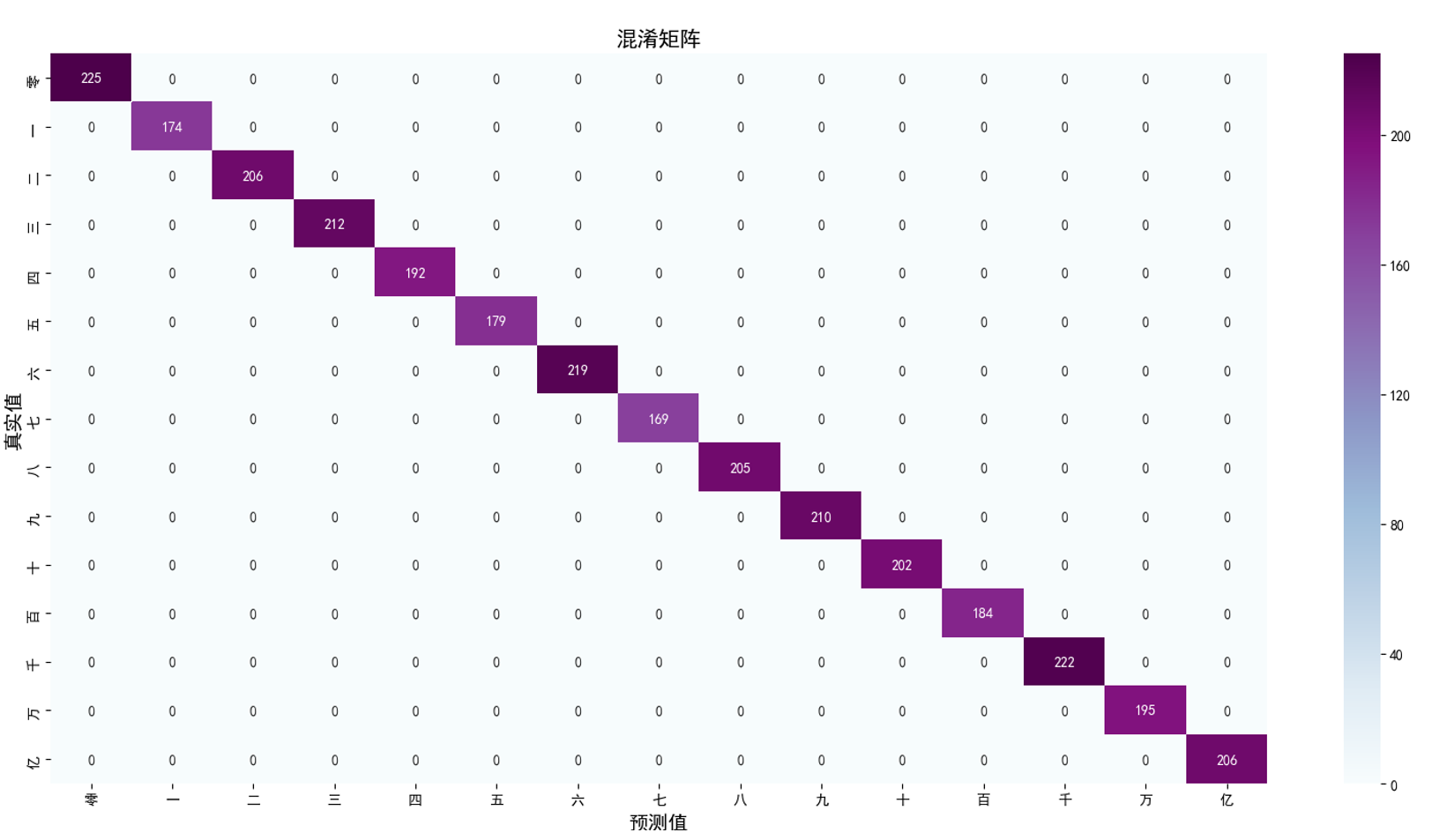
总结:本次实验最复杂的就是标签处理那一块,只有处理好这一步骤,才能正确的将图片和标签划分到一起。实验数据只有15000张,而Mnist数据集有70000张,虽然本次的模型准确率达到了100%,但是仍有可能在别的图片预测错误。
努力加油a啊
Original: https://blog.csdn.net/starlet_kiss/article/details/120086841
Author: starlet_kiss
Title: 深度学习之基于CNN实现汉字版手写数字识别(Chinese-Mnist)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/521712/
转载文章受原作者版权保护。转载请注明原作者出处!