

简介
YAMNet模型是在 AudioSet 数据集(一个大型音频、视频数据集)上训练的音频事件分类器。
模型输入
该模型接收包含任意长度波形的float32一维张量或 NumPy数组,且满足范围[-1.0, +1.0]内的单声道16kHz样本。在内部,该算法将波形划分为长度为0.96秒和跳跃0.48秒的滑动窗口,然后在一批这些帧上运行模型。
模型输出
该模型返回一个 3 元组(scores, embeddings, log_mel_spectrogram),其中
(1)Scores是一个float32的形状为(N, 521)的张量,N为批大小,521列代表521个对应声音事件的评分。
(2)Embeddings是一个float32的形状为(N, 1024)的张量,这个张量是模型最后的全链接神经网络前的平均池化层输出,我们可以把YAMNet当做一个特征提取器(Embedding)来构建其他模型。
(3)log_mel_spectrogram是一个float32的形状为(num_spectrogram_frames, 64)的张量,其中num_spectrogram_frames是通过滑动长度为 0.025 秒的频谱图分析窗口以 0.01 秒的跳跃从波形产生的帧数。
模型使用
该模型提供了三种使用场景。
[En]
The model provides three usage scenarios.
(1)在python中直接通过tensorflow_hub插件使用,可以直接通过调用API的方式使用。
model = hub.load(‘https://tfhub.dev/google/yamnet/1’)
可以直接在python代码中通过该语句直接加载模型。
(2)在Tensorflow的JS版本中使用
const modelUrl = ‘https://tfhub.dev/google/tfjs-model/yamnet/tfjs/1’;
const model = await tf.loadGraphModel(modelUrl, { fromTFHub: true });
可以在通过使用JavaScript开源库TensorFlow.js来使用该模型
(3)在TFLite中使用
TFLite是为了将深度学习模型部署在移动端和嵌入式设备的工具包,可以把训练好的TF模型通过转化、部署和优化三个步骤,达到提升运算速度,减少内存、显存占用的效果。
TFlite主要由Converter(左)和Interpreter(右)组成。Converter负责把TensorFlow训练好的模型转化,并输出为.tflite文件(FlatBuffer格式)。转化的同时,还完成了对网络的优化,如量化。Interpreter则负责把.tflite部署到移动端,嵌入式(embedded linux device)和microcontroller,并高效地执行推理过程,同时提供API接口给Python,Objective-C,Swift,Java等多种语言。简单来说,Converter负责打包优化模型,Interpreter负责高效易用地执行推理。
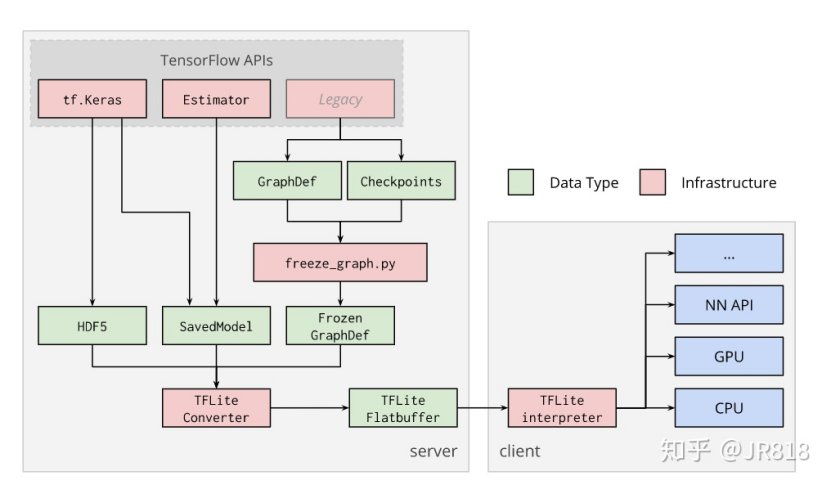

此外,TFLite提供了 Java、Python 和 C++ API 库,可以运行在 Android、iOS 和 Raspberry Pi 等设备上。
; 参考文献
[1] https://discuss.tf.wiki/t/topic/1337
Original: https://blog.csdn.net/search_129_hr/article/details/118660529
Author: HenrySmale
Title: 睡眠音频分割及识别问题(四)–YAMNet简介
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/512890/
转载文章受原作者版权保护。转载请注明原作者出处!