

论文《黑匣子智能语音软件的对策样本生成方法》
[En]
The paper “countermeasure sample generation method for black box intelligent voice software”
一、论文中提到的相关名词解释
1.1什么是对抗样本?
所谓对抗样本就是指:在原始样本添加一些人眼无法察觉的扰动(这样的扰动不会影响人类的识别,但是却很容易愚弄模型),致使机器做出错误的判断。
例如,在原来的雪山图片中,添加干扰后,我们的人眼看起来仍然像一座雪山,但在模型中,它会被错误地识别为狗。
[En]
For example, in the original picture of a snowy mountain, after adding disturbance, our human eyes still look like a snowy mountain, but in the model, it will be mistakenly identified as a dog.
由于对抗性样本的存在,用于深度学习的各个领域的安全性很难得到保证。例如,在自动驾驶领域,车载语音识别系统在输入过程中受到微小干扰的攻击,语音识别系统会错误识别乘客的指令,这给自动驾驶系统带来了严重的安全风险。
[En]
Because of the existence of antagonistic samples, the security of various fields used in deep learning is difficult to be guaranteed. For example, in the field of autopilot, the on-board speech recognition system is attacked by minor disturbances during input, and the speech recognition system will mistakenly recognize the instructions of passengers, which brings serious security risks to the autopilot system.
在构建对抗样本的过程中,无论是图像识别系统还是语音识别系统,根据攻击者掌握机器学习模型信息量的多少,可以分为白盒攻击和黑盒攻击。
[En]
In the process of constructing confrontation samples, whether image recognition system or speech recognition system, according to how much information the attacker has mastered the machine learning model, it can be divided into white-box attack and black-box attack.
1.2白盒攻击与黑盒攻击
白盒攻击:攻击者可以了解机器学习中使用的算法以及算法使用的参数。攻击者可以在生成对抗性攻击数据的过程中与机器学习系统交互。
[En]
White-box attacks: attackers can learn about the algorithms used in machine learning and the parameters used by the algorithms. Attackers can interact with machine learning systems in the process of generating adversarial attack data.
黑盒攻击:攻击者不知道机器学习中使用的算法和参数,但攻击者仍然可以与机器学习系统交互,例如传入任何输入来观察输出并判断输出。
[En]
Black box attack: the attacker does not know the algorithms and parameters used in machine learning, but the attacker can still interact with the machine learning system, such as passing in any input to observe the output and judge the output.
1.3无目标攻击与有目标攻击
无目标攻击:被攻击模型的输出只要是不正确的就没有问题。如果原始图像是一只小猫,添加干扰形成一个对策样本输入到模型中,模型输出误差,输出结果可以是一只小狗,可以是一只小羊或其他,只有要求是错的。
[En]
Aimless attack: the output of the attacked model is fine as long as it is incorrect. If the original image is a kitten, add interference to form a countermeasure sample input into the model, the model output error, the output result can be a puppy, can be a lamb or other, only the requirement is wrong.
有目标攻击:被攻击模型的错误输出为特定类别。如原图像是小猫,生成的对抗样本使DNN模型错误分类为攻击者想要的小狗。
1.4研究对抗攻击的意义如下:
(1)能让机器学习模型处理大规模数据;
(2)以”计算机速度”处理攻击威胁;
(3)不依赖数据的明显特征,发现实际应用中的各种内在威胁;
(4)阻止已知和未知的恶意软件;
(5)阻止恶意软件的提前执行;
(6)优化模型,让分类模型达到更加高的分类准确率和更加低的错误率。
二、论文主要内容
在实际应用中,攻击者通常很难获得识别模型的结构信息,而攻击的目的是为了达到特定的目标(例如,将某一段语音识别变成特定的指令)。因此,黑匣子目标攻击在实际应用中更具攻击性和隐蔽性。
[En]
In practical applications, it is usually difficult for attackers to obtain the structural information of the recognition model, and the purpose of the attack is to achieve a specific target (for example, to make a certain section of speech recognition into specific instructions). Therefore, the black box target attack is more aggressive and hidden in practical applications.
为了实现语音识别系统的黑匣子目标攻击,提出了一种适用于黑匣子智能语音软件的目标对抗样本生成方法,即萤火虫-梯度对抗样本生成方法。
[En]
In order to realize the black box target attack for speech recognition system, this paper proposes a target countermeasure sample generation method for black box intelligent speech software, that is, firefly-gradient countermeasure sample generation method.
2.1论文贡献
以前用于黑盒语音识别系统的对抗样本生成方法的局限性:
[En]
The limitations of the previous countermeasure sample generation methods for black-box speech recognition systems:
- 多数侧重于非目标对抗样本的生成;
- 一些方法在实验评估时采用的语音数据集较为单一;
- 成功率比较低。
本文提出的黑匣子智能语音软件目标对抗样本生成方法–萤火虫-梯度对抗样本生成方法,其贡献点如下:
[En]
The target countermeasure sample generation method-firefly-gradient countermeasure sample generation method for black box intelligent voice software proposed in this paper, the contribution points are as follows:
- 属于更为实际更具研究价值的目标对抗样本生成方法(实际应用中,攻击者的攻击是为了达到特定目标);
- 更加适用于不同类型的语音数据集(实验中应用的数据集不止有简单单词、短语,还有中等句、长句);
- 成功率优于其他方法。
2.2实验环境:
(1)数据集:
实验选择公共语音数据集(中等长度)上的任意100个音频样本,谷歌命令语音数据集(单词)上的任意10种类型的共100个语音命令样本以及LibriSpeech语音数据集(长句)上的任意50个音频样本,来进行方法的效果评估。
(2)智能语音识别软件:
实验采用DeepSpeech作为待测试的智能语音识别软件。
(3)实验环境与衡量指标:
实验所用系统环境为Ubuntu16.04系统,使用Python语言作为实验的编程语言,使用的深度学习平台框架为TensorFlow1.12 。
实验使用语音相似度、生成对抗样本所需时间和生成对抗样本的成功率三个指标来衡量该方法的有效性。
[En]
The experiment uses three indicators: speech similarity, the time required to generate countermeasure samples and the success rate of generating antagonistic samples to measure the effectiveness of the method.
(4)实验对比方法:
实验选择了3种同类型的对抗样本生成方法:遗传-梯度评估方法、布谷鸟算法、没有调参优化的初试萤火虫算法。这些对比方法都属于群智能算法,算法之间具有可比性。
(5)算法:
萤火虫算法:在发光的种群中,每只萤火虫都会朝着比它本身更亮的位置移动。同时,不同亮度的萤火虫之间也存在一定程度的吸引力。在多次移动后,其他萤火虫聚集在最亮的萤火虫的位置周围。属于群体智能算法,即通过不同的方法构造具有多个个体的种群,然后不断地在种群中寻找最优个体。
[En]
Firefly algorithm: in a glowing population, each firefly moves toward the position of the firefly that is brighter than it is. At the same time, there is a certain degree of attraction between fireflies with different brightness. After moving many times, other fireflies gather around the position of the brightest firefly. Belongs to the swarm intelligence algorithm, that is, through different methods to construct a population with multiple individuals, and then constantly find the best individual in the population.
梯度评价法:是一种针对黑盒智能软件的对策样本生成方法。梯度评估公式的主要作用是生成梯度,将其与原始梯度函数值进行区分,对原始梯度函数值进行微小修改,并对其进行优化,从而生成更准确的对抗样本。
[En]
Gradient evaluation method: it is a countermeasure sample generation method for black box intelligent software. The main function of the gradient evaluation formula is to generate the gradient, make a difference between it and the original gradient function value, make minor changes to the original gradient function value, and optimize it, so as to generate more accurate confrontation samples.
2.3方法总体框架
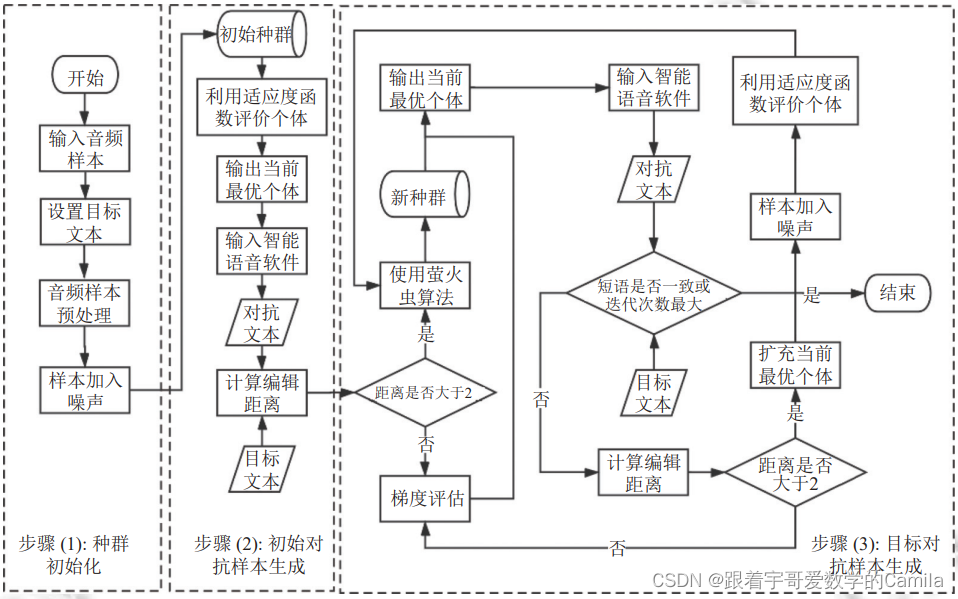

(1)种群初始化
对原始样本进行扩充,形成包含多个样本个体的种群。为了使个体间产生差异,还需要向种群中加入随机噪声,完成种群初始化操作。
(2)初始对抗样本生成
根据选择的适应度函数,给种群中所有个体进行评分,寻找到当前满足条件的最优个体,将其作为初始的对抗样本,并输入到语音软件中,得到样本对应的文本内容。使用编辑距离衡量对抗样本的文本内容转换到目标文本所需操作次数。
(3)目标对抗样本生成
使用萤火虫算法或梯度评估方法继续优化,如果生成的对抗性样本的文本内容与目标文本的编辑距离为0,则表示目标对抗性样本生成成功。样本优化算法的选择依赖于对抗样本文本内容与目标文本之间的编辑距离:采用萤火虫算法在大范围内寻找当前最优个体,采用梯度评估法进行局部关键扰动,不断迭代生成目标对抗样本。
[En]
Using the firefly algorithm or gradient evaluation method to continue the optimization, if the editing distance between the text content of the generated antagonistic sample and the target text is 0, it means that the target antagonistic sample is generated successfully. The selection of the sample optimization algorithm depends on the editing distance between the text content of the antagonistic sample and the target text: the firefly algorithm is used to find the current optimal individual in a large range, and the gradient evaluation method carries on the local key disturbance and iterates constantly to generate the target countermeasure sample.
2.4实验结果与分析
实验使用语音相似度、生成对抗样本所需时间和生成对抗样本的成功率三个指标来衡量该方法的有效性。
[En]
The experiment uses three indicators: speech similarity, the time required to generate countermeasure samples and the success rate of generating antagonistic samples to measure the effectiveness of the method.
(1)语音相似度分析
本文提出方法在3种不同类型的语音数据集上生成对抗样本的语音相似度都比较高,均在93%以上.这表明,采用提出方法,生成的目标对抗样本都和原始音频样本非常相似,具有很好的隐蔽性。
(2)生成时间分析
在3种语音数据集上,萤火虫-梯度评估方法生成对抗样本所需时间都不是最短,但是和其他3个方法所需的最短时间差距都不大,且优于布谷鸟算法与初始萤火虫算法所需时间。
(3)成功率分析
在3种语音数据集上,萤火虫-梯度评估方法生成对抗样本的成功率均优于对照组的遗传-梯度评估方法、布谷鸟算法以及初始萤火虫算法,在公共语音数据集和LibriSpeech语音数据集上,本方法的成功率优势则更为明显。例如在公共语音数据集上,相比遗传-梯度评估方法将成功率从35%提升至48%,成功率提升了13%。
(4)人工验证样本
实验寻找了30志愿者,从3 种语音数据集上分别任意挑选了1 0组原始样本以及成功生成的对应目标对抗样本。这些志愿者都是大学学生,此前并不了解对抗样本领域,对于本实验所做研究也并不了解。
结果表明,90%的志愿者表示听到对抗样本和原始样本的音频内容一致,只是前者存在一些细微噪声,但仍能听清原始音频的内容,并表示听不出任何有关目标文本的声音。只有10%的志愿者表示30条对抗样本里只有一两组对抗样本中的噪声比较明显,对原始的音频样本产生了干扰。
这表明,该方法生成的对峙样本可以使人检测不到与原始样本的明显差异。但仍有一小部分噪声对准样品,需要在以后的工作中进行降低。
[En]
This shows that the confrontation sample generated by the proposed method can make people can not detect the obvious difference from the original sample. However, there is still a small part of the noise against the sample, which needs to be reduced in the later work.
2.5结果分析
虽然萤火虫-梯度评估对抗样本生成方法在生成对抗样本所需时间和平均语音相似度上的表现不是最好,略低于遗传梯度评估方法的表现,然而,在生成对抗样本的成功率方面,提出的方法要优于其他3种对照方法,尤其对于中等长度语句和长句而言更具优势。实验还进行了人工验证,表明生成的语音对抗样本是有效的。
2.6总结
取得效果:
当语音相似度和对抗样本生成时间略差于对比方法时,在不同类型的数据集上,目标对抗样本生成的成功率要好于对比方法。
[En]
When the speech similarity and countermeasure sample generation time are slightly worse than the comparison method, the success rate of target countermeasure sample generation is better than that of the comparison method in different types of data sets.
有待改进:
成功率有所提高,但仍有很大提升空间;原音频与生成的反音频语音相似度较低。
[En]
The success rate has been improved, but there is still a lot of room for improvement; the speech similarity between the original audio and the generated anti-audio is relatively low.
Original: https://blog.csdn.net/qq_45502052/article/details/125469727
Author: 跟着宇哥爱数学的Camila
Title: 对抗样本生成方法论文阅读笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/512494/
转载文章受原作者版权保护。转载请注明原作者出处!