

知识点
- 爬虫基本流程
- json
- requests 爬虫当中 发送网络请求
- pandas 表格处理 / 保存数据
- pyecharts 可视化
开发环境
- python 3.8 比较稳定版本 解释器发行版 anaconda jupyter notebook 里面写数据分析代码 专业性
- pycharm 专业代码编辑器 按照年份与月份划分版本的
爬虫完整代码
导入模块
import requests # 发送网络请求模块
import json
import pprint # 格式化输出模块
import pandas as pd # 数据分析当中一个非常重要的模块
分析网站
首先找到今天要抓取的目标数据。
[En]
First find the target data to be crawled today.
https://news.qq.com/zt2020/page/feiyan.htm
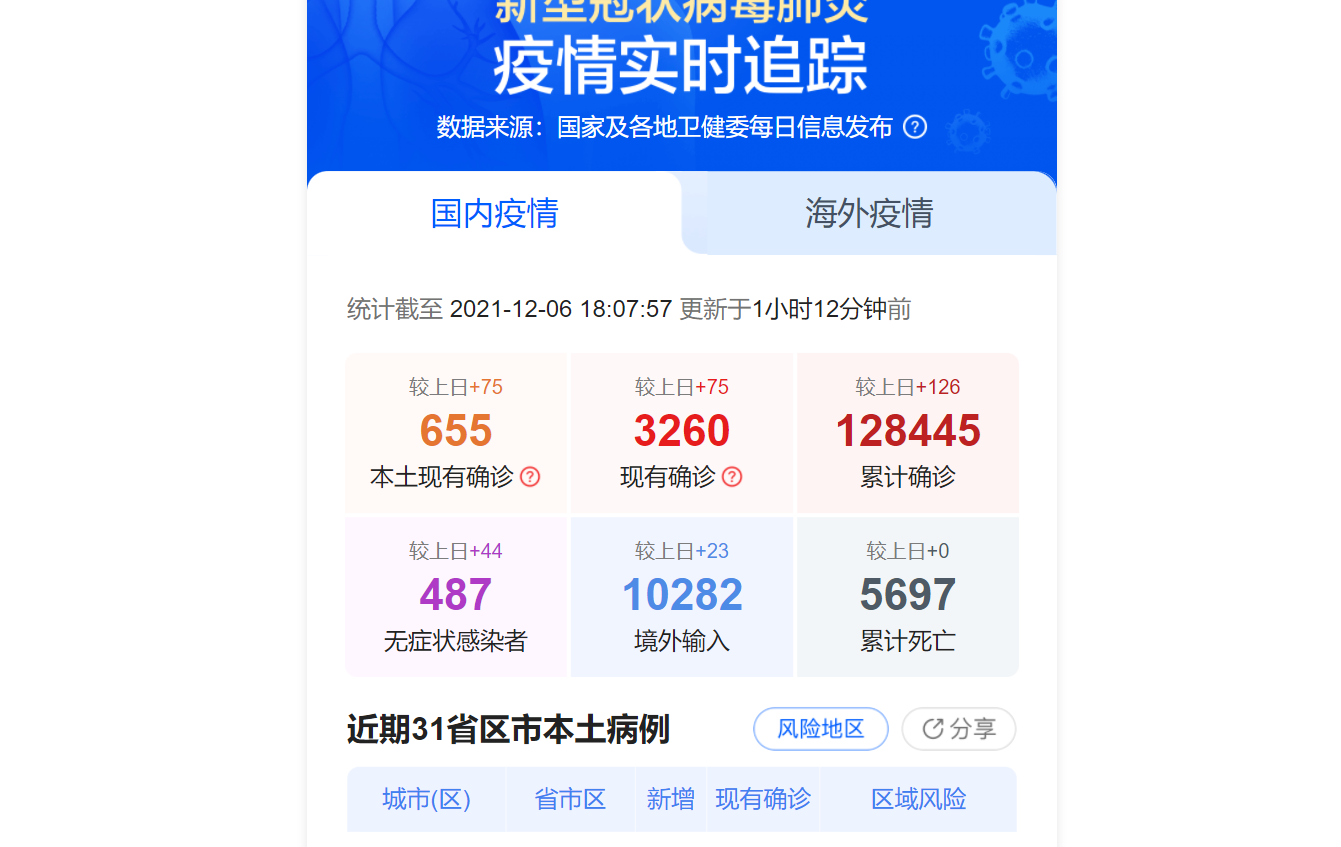

找到数据所在url
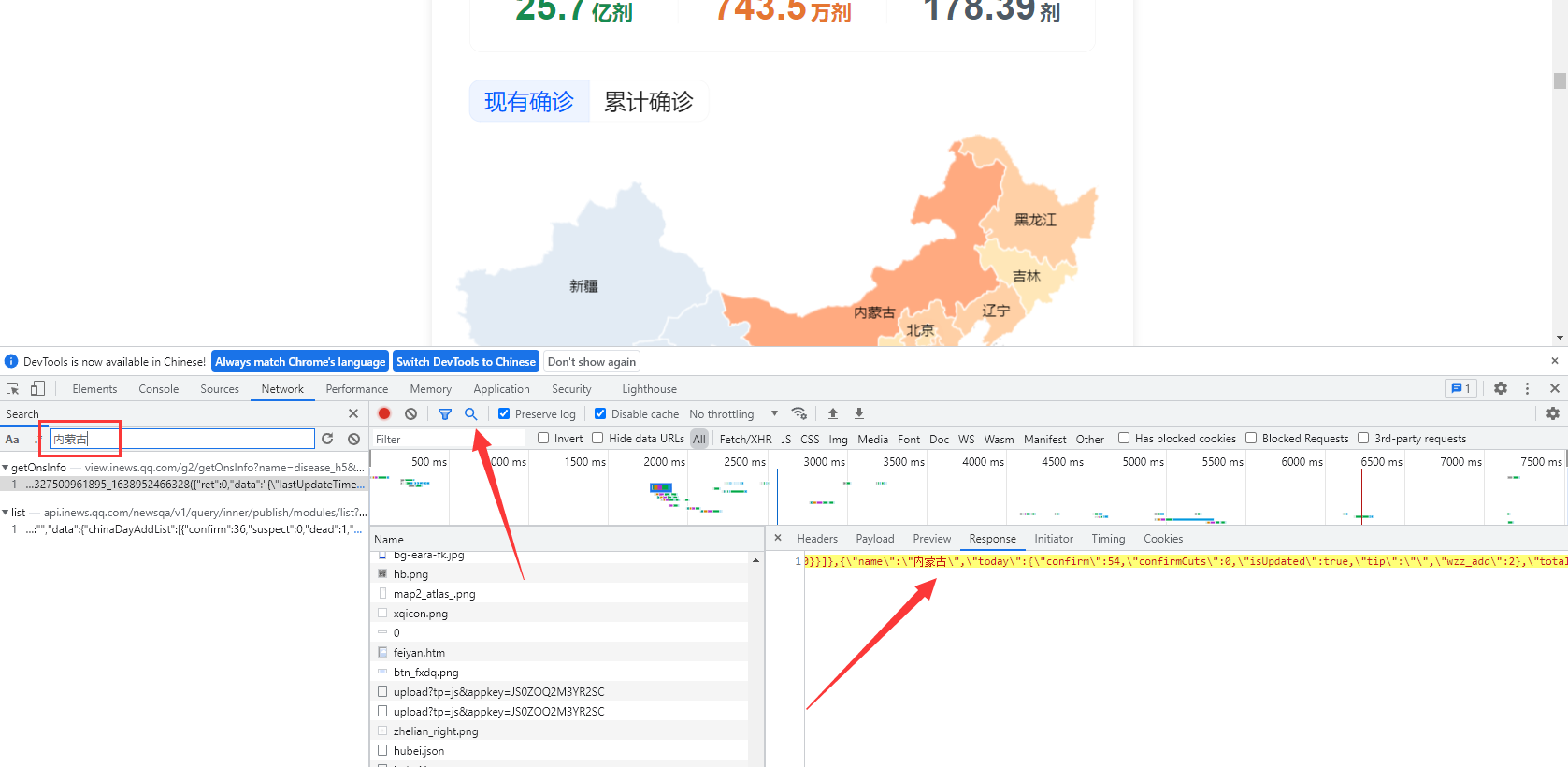

发送请求
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&_=1638361138568'
response = requests.get(url, verify=False)
获取数据
json_data = response.json()['data']
解析数据
json_data = json.loads(json_data)
china_data = json_data['areaTree'][0]['children'] # 列表
data_set = []
for i in china_data:
data_dict = {}
# 地区名称
data_dict['province'] = i['name']
# 新增确认
data_dict['nowConfirm'] = i['total']['nowConfirm']
# 死亡人数
data_dict['dead'] = i['total']['dead']
# 治愈人数
data_dict['heal'] = i['total']['heal']
# 死亡率
data_dict['deadRate'] = i['total']['deadRate']
# 治愈率
data_dict['healRate'] = i['total']['healRate']
data_set.append(data_dict)
保存数据
df = pd.DataFrame(data_set)
df.to_csv('data.csv')
数据可视化
导入模块
from pyecharts import options as opts
from pyecharts.charts import Bar,Line,Pie,Map,Grid
读取数据
df2 = df.sort_values(by=['nowConfirm'],ascending=False)[:9]
df2
死亡率与治愈率
line = (
Line()
.add_xaxis(list(df['province'].values))
.add_yaxis("治愈率", df['healRate'].values.tolist())
.add_yaxis("死亡率", df['deadRate'].values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="死亡率与治愈率"),
)
)
line.render_notebook()
各地区确诊人数与死亡人数情况
bar = (
Bar()
.add_xaxis(list(df['province'].values)[:6])
.add_yaxis("死亡", df['dead'].values.tolist()[:6])
.add_yaxis("治愈", df['heal'].values.tolist()[:6])
.set_global_opts(
title_opts=opts.TitleOpts(title="各地区确诊人数与死亡人数情况"),
datazoom_opts=[opts.DataZoomOpts()],
)
)
bar.render_notebook()
Original: https://www.cnblogs.com/qshhl/p/15668865.html
Author: 松鼠爱吃饼干
Title: 【爬虫+可视化】Python爬取疫情数据,并做可视化展示
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/510574/
转载文章受原作者版权保护。转载请注明原作者出处!