

函数
概念:功能 (包裹一部分代码 实现某一个功能 达成某一个目的)
特点:可以反复调用,提高代码的复用性,提高开发效率,便于维护管理
1.函数基本格式
定义一个函数
def 函数名():
code1
code
调用函数
函数名()
"""
定义函数
def func():
print("我是一个函数 ... ")
调用函数
func()
2.函数的命名
字母数字下划线,首字符不能为数字
严格区分大小写,且不能使用关键字
函数命名有意义,且不能使用中文哦
驼峰命名法:
(1) 大驼峰命名法: 每个单词的首字符要大写 (类的命名)
mycar => MyCar
(2) 小驼峰命名法: 除了第一个单词首字符小写外,剩下单词首字符大写 (函数或者变量)
mycar => myCar
(3)_命名法:可以将不同的单词用_拼接在一起
mycar => my_car
symmetric_differencesymmetricDifference SymmetricDifference
函数定义
def cfb_99():
for i in range(1,10):
for j in range(1,i+1):
print("{:d}*{:d}={:2d} ".format(i,j,i*j) ,end="")
print()
调用函数
for i in range(5):
cfb_99()
函数的参数
参数: 函数运算时需要的值
参数种类:
(1)形参: 形式参数,在函数的定义处
(2)实参: 实际参数,在函数的调用处
形参的种类:
1.普通形参(位置形参) 2.默认形参 3普通收集形参 4.命名关键字形参 5.关键字收集形参
实参的种类:
1.普通实参 2.关键字实参
原则:
形参和实参要一一的对应
1.普通形参(位置形参)
定义函数
"""hang,lie普通形参,在函数定义处"""
def small_star(hang,lie):
i = 0
while i < hang:
j = 0
while j < lie:
print("*",end="")
j +=1
print()
i += 1
调用函数
"""10,10普通实参,在函数的调用处"""
small_star(10,10)
small_star(2,3)
2.默认形参
"""hang,lie默认形参,在函数定义处"""
"""
如果给予实参,那么使用实参
如果没有给予实参,那么使用参数身上的默认值
"""
def small_star(hang=10,lie=10):
i = 0
while i < hang:
j = 0
while j < lie:
print("*",end="")
j +=1
print()
i += 1
small_star(4,8)
small_star(8)
small_star()
3.普通形参 + 默认形参
"""普通形参必须写在默认形参的前面不能调换位置"""
def small_star(hang,lie=10):
i = 0
while i < hang:
j = 0
while j < lie:
print("*",end="")
j +=1
print()
i += 1
small_star(5,7)
small_star(5)
small_star() error
4.关键字实参
1.如果都是关键字实参,可以任意调整实参的顺序
2.普通实参必须写在关键字实参的前面
def small_star(hang,a,b,c,lie=10):
i = 0
while i < hang:
j = 0
while j < lie:
print("*",end="")
j +=1
print()
i += 1
hang a ... lie 具体指定参数的值叫做关键字实参,在函数的调用处;
small_star(hang=3,a=4,b=5,c=6,lie=7)
small_star(b=5,c=6,lie=7,a=4,hang=3)
small_star(3,4,b=5,c=6,lie=7)
small_star(3,4,b=5,lie=7,c=6)
small_star(b=5,c=6,lie=7,3,4) error
收集参数
(1) 普通收集形参
专门用来收集那些多余和不需要的普通参数,在收集之后,额外的参数将被打包到头部带有星号的元组参数中
[En]
Specially used to collect those extra and unwanted ordinary arguments, after the collection, the extra arguments will be packed into a tuple parameter with a star on the head
def func(*args):
pass
args => arguments
def func(a,b,c,*args):
print(a,b,c) # 1 2 3
print(args) # (4,5,6)
func(1,2,3,4,5,6)
任意个数值得累加和
def mysum(*args):
total = 0
for i in args:
total += i
print(total)
mysum(1,2,3,4,4,45,10,100)
(2) 关键字收集形参
专门用于收集多余的不需要的关键词,收集后,多余的关键词将被打包到参数头上有两个星号的词典中。
[En]
Specially used to collect those extra unwanted keywords, after the collection, the extra keywords will be packed into a dictionary with two stars on the parameter head.
def func(**kwargs):
pass
kwargs => keyword arguments
def func(a,b,c,**kwargs):
print(a,b,c)
print(kwargs) # {'f': 100, 'e': 200, 'z': 12}
func(c=1,a=3,b=10,f=100,e=200,z=12)
将任何数值连接成一个字符串
[En]
Concatenate any numerical value into a string
undefined
"""班长: 赵万里班花: 马春陪划水群众: 赵沈阳,李虎凌,刘子涛"""def func(**kwargs): strvar1 = "" strvar2 = "" # 定义职位信息 dic = {"monitor":"班长","classflower":"班花"} print(kwargs) # 共5次循环 for k,v in kwargs.items(): if k in dic: # 将2次循环的结果通过+= 拼接在一起 strvar1 += dic[k] + ":" + v + "\n" else: # 将3次循环的结果通过+= 拼接在一起 strvar2 += v + " , " print(strvar1.strip()) print("划水群众:",strvar2.strip(" , ")) """ # print(k,v) k v monitor 赵万里 classflower 马春陪 water1 赵沈阳 water2 李虎凌 water3 刘子涛 {'monitor': '赵万里', 'classflower': '马春陪', 'water1': '赵沈阳', 'water2': '李虎凌', 'water3': '刘子涛'} """func(monitor="赵万里",classflower="马春陪",water1="赵沈阳",water2="李虎凌",water3="刘子涛")
undefined
命名关键字参数
(1) def func(a,b,,c,d) 跟在号后面的c和d是命名关键字参数
(2) def func(args,e,kwargs) 加在args和**kwargs之间的参数都是命名关键字参数
命名关键字参数 : 在调用函数时,必须使用关键字实参的形式来进行调用;
定义方法一
def func(a,b,*,c,d):
print(a,b)
print(c,d)
必须指定关键字实参,才能对命名关键字形参进行赋值
func(1,2,c=3,d=4)
定义方法二
def func(*args,e,**kwargs):
print(args) # (1, 2, 3, 4)
print(e) # 3
print(kwargs) # {'a': 1, 'b': 2}
func(1,2,3,4,a=1,b=2,e=3)
星号的使用
-
和 如果在函数的定义处使用:* 把多余的普通实参打包成元组, 把多余的关键字实参打包成字典
-
和 如果在函数的调用处使用:* 把元组或者列表进行解包, 把字典进行解包
def func(a,b,*,c,d):
print(a,b)
print(c,d)
tup = (1,2)
函数的调用处 *号用法
func(*tup,c=3,d=4) # func(1,2,c=3,d=4)
函数的调用处 **号用法
dic={"c":3,"d":4}
func(1,2,**dic) # func(1,2,c=3,d=4)
综合写法
函数的调用处
tup = (1,2)
dic={"c":3,"d":4}
func(*tup,**dic)
定义成如下形式,可以收集所有的实参
def func(*args,**kwargs):
pass
总结:
当所有参数都放在一起时,排序原则是:通用参数->默认参数->通用采集参数->命名关键字参数->关键字采集参数
[En]
When all the parameters are put together, the order principle is: general parameter-> default parameter-> general collection parameter-> named key parameter-> keyword collection parameter
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
以上两个函数 打印结果
#(一)
f1(1, 2) # a =1 b=2 c=0 args=() kw={}
f1(1, 2, c=3) # a=1,b=2,c=3,args=() kw={}
f1(1, 2, 3, 'a', 'b') #a=1 b=2 c=3 args=(a,b) kw={}
f1(1, 2, 3, 'a', 'b', x=99) # a=1 b=2 c=3 args=(a,b) kw={x:99}
f2(1, 2, d=99, ext=None)#a=1 b=2 c=0 d=99 kw={ext:None}
#(二)
args = (1, 2, 3, 4)
kw = {'d': 99, 'x': '#'}
f1(1,2,3,4,d=99,x=#)
f1(*args, **kw) # a=1 b=2 c=3 args=(4,) kw={d:99,x:#}
#(三)
myargs = (1, 2, 3)
mykw = {'d': 88, 'x': '#'}
f2(1,2,3,d=88,x=#)
f2(*myargs, **mykw) # a=1,b=2,c=3 d=88 kw={x:#}
#(四)
def f1(a, b, c=0, *args,d,**kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
print(d)
f1(1,2,3, 'a', 'b',d=67, x=99,y=77) # a=1 b=2 c=3 args=(a,b) kw={x:99,y:77}
# d=67
return 自定义函数的返回值
概念:return 把函数内部的数据返回到函数的外面,返回到函数的调用处
1.return + 六大标准数据类型 , 除此之外还可以返回函数 或者 是类对象
2.return 在执行时,意味着终止函数,后面的代码不执行.
3.如果不定义return返回值,默认返回None
(1) return + 六大标准数据类型
def func():
# return 111
# return 6.89
# return "你好帅啊,我爱死你乐"
# return [1,2,3]
# return {"a":1,"b":2}
return 1,2,3 # 返回元组
res = func()
print(res)
(2) return 在执行时,意味着终止函数,后面的代码不执行.
def func():
print(1)
print(2)
return 3
print(4)
res = func()
print(res)
def func():
for i in range(5):
if i == 3:
return 4
print(i)
res = func()
print(res)
(3) 如果不定义return返回值,默认返回None
def func():
pass
res = func()
print(res) # None
注意点 打印的数据和返回的数据不是等价的,返回的数据是可以自定义的;
res = print(1234)
print(res) # None
模拟+-*/计算器
"""
功能: 完成计算
参数: 2个数字和运算符
返回值: 计算后的结果
"""
def calc(num1,num2,sign):
if sign == "+":
return num1 + num2
elif sign == "-":
return num1 - num2
elif sign == "*":
return num1 * num2
elif sign == "/":
if num2 == 0:
return "除数不能为零"
return num1 / num2
else:
return "抱歉,超出了我的运算范围."
res = calc(3,5,"+")
res = calc(3,5,"-")
res = calc(3,5,"*")
res = calc(3,0,"/")
res = calc(3,0,"&")
print(res)
全局变量和局部变量
1.概念
局部变量:在函数内部定义的变量就是局部变量
全局变量:在函数外部定义的变量或者在函数内部使用global关键字声明是全局变量
2.作用域:
局部变量的作用域仅在函数内部。
[En]
The scope of local variables is only inside the function.
全局变量的作用域覆盖整个文件
[En]
The scope of global variables spans the entire file
3.生命周期:该变量的作用时长
内置命名空间 -> 全局命名空间 -> 局部命名空间 (开辟空间顺序)
内置属性 > 全局属性 > 局部属性 (作用时长:长->短)
1 局部变量
def func():
定义一个局部变量
a = 1
获取当前的局部变量
print(a)
修改一个局部变量
a = 2
print(a)
func()
print(a) error
2.全局变量
定义一个全局变量
b = 10
获取当前的全局变量
print(b)
修改一个全局变量
b = 20
print(b)
def func():
print(b)
func()
3.函数内部定义全局变量
def func():
global c
c =30
func()
print(c)
4.函数内部修改全局变量
d = 50
def func():
global d
d = 51
func()
print(d)
总结:
global的使用如果当前不存在全局变量,可以在函数内部通过global关键字来定义全局变量,如果当前存在全局变量,可以在函数内部通过global关键字来修改全局变量
函数名的使用
python中的函数可以像变量一样,动态创建,销毁,当参数传递,作为值返回,叫第一类对象.其他语言功能有限
def func():
print( “我是func函数”)
(1)动态创建
a = 1
print(a)
a = func
a()
(2)动态销毁
del a
a()
func()
(3)当参数传递
def func2():
return "我是func2函数"
def func1(f):
return f() # "我是func2函数"
res = func1(func2)
print(res)
(4)作为值返回
def func3():
print( "我是func3函数" )
def func4(f):
return f
res = func4(func3)
print(res)
res()


(5)函数名可以作为容器类型数据的元素
lst = [func,func3]
for i in lst:
i()
doc 或者help查看文档
def big_chang_cishen(something):
"""
功能: 教你怎么吃大肠
参数: 吃的内容
返回值: 是否满意
"""
print("把{}洗一洗".format(something))
print("直接找肠子头,放嘴里,吸一下")
print("擦擦嘴,满意的放下肠子头")
return "吃完了,真好吃~"
big_chang_cishen("生肠子")
方法一
res = big_chang_cishen.__doc__
print(res)
方法二
help(big_chang_cishen)
函数的嵌套
互相嵌套的两个函数:包裹在外层的叫做外函数,内层的就是内函数
def outer():
# inner()
def inner():
print("我是inner函数")
(1)内部函数可以直接在函数外部调用么 不行
inner()
(2)调用外部函数后,内部函数可以在函数外部调用吗 不行
outer()
inner()
(3)内部函数可以在函数内部调用吗 可以
outer()
(4)内部函数在函数内部调用时,是否有先后顺序 有的
先定义在调用
在其他语言中,有一种预加载机制,它预先将函数驻留在内存中,然后编译脚本内容。
[En]
In other languages, there is a preloading mechanism that resides the function in memory in advance, and then compiles the script content.
python没有预加载函数的机制,只能先定义在调用;
外函数是outer 中间函数是inner 最里层是smaller ,调用smaller函数
def outer():
def inner():
def smaller():
print("我是smaller函数")
smaller()
inner()
outer()
LEGB 原则
def outer():
def inner():
def smaller():
print(a)
smaller()
inner()
outer()
LEGB原则(就近找变量原则)
找寻变量的调用顺序采用LEGB原则(即就近原则)
B —— Builtin(Python);Python内置模块的命名空间 (内建作用域)
G —— Global(module); 函数外部所在的命名空间 (全局作用域)
E —— Enclosing function locals;外部嵌套函数的作用域(嵌套作用域)
L —— Local(function);当前函数内的作用域 (局部作用域)
依据就近原则,从下往上 从里向外 依次寻找
nonlocal的使用 (用来修改局部变量)
nonlocal遵循LEGB原则
(1) 它会找当前空间上一层的变量进行修改
(2) 如果上一层空间没有,继续向上寻找
(3) 如果最后找不到,直接报错
(1)它会找当前空间上一层的变量进行修改
def outer():
a = 10
def inner():
nonlocal a
a = 20
print(a)
inner()
print(a)
outer()
(2)如果上一层空间没有,继续向上寻找
def outer():
a = 20
def inner():
a = 15
def smaller():
nonlocal a
a = 30
print(a)
smaller()
print(a)
inner()
print(a)
outer()
(3)如果最后找不到,直接报错
”’nonlocal 只能修改局部变量”’
a = 20
def outer():
def inner():
def smaller():
nonlocal a
a = 30
print(a)
smaller()
print(a)
inner()
print(a)
outer()
error
(4) 不通过nonlocal 是否可以修改局部变量呢?ok
def outer():
lst = [1,2,3]
def inner():
lst[-1] = 3000
inner()
print(lst)
outer()
闭包函数
互相嵌套的两个函数,如果内函数使用了外函数的局部变量,并且外函数把内函数返回出来的过程叫做闭包。
内部函数称为闭包函数。
[En]
The inner function inside is called the closure function.
是不是闭包?
1.内函数用了外函数的那个局部变量
2.外函数返回内函数
1.基本语法形式
def zhaoshenyang_family():
father = "马云"
def hobby():
print("我对钱没有一丝丝的兴趣,我不看重钱,这是我爸爸{}说的".format(father))
return hobby
func = zhaoshenyang_family()
func()

2.闭包的复杂形式
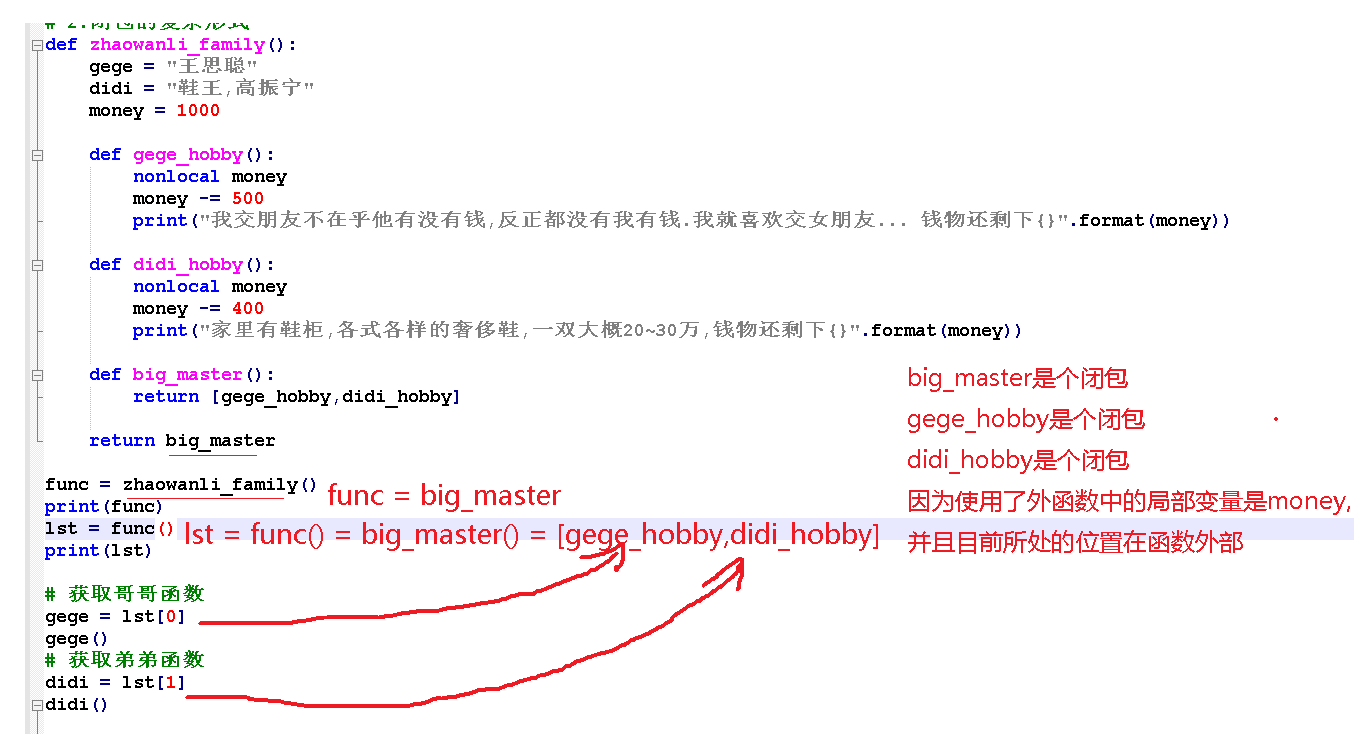
def zhaowanli_family():
gege = "王思聪"
didi = "鞋王,高振宁"
money = 1000
def gege_hobby():
nonlocal money
money -= 500
print("我交朋友不在乎他有没有钱,反正都没有我有钱.我就喜欢交女朋友... 钱物还剩下{}".format(money))
def didi_hobby():
nonlocal money
money -= 400
print("家里有鞋柜,各式各样的奢侈鞋,一双大概20~30万,钱物还剩下{}".format(money))
def big_master():
return [gege_hobby,didi_hobby]
return big_master
func = zhaowanli_family()
print(func)
lst = func()
print(lst)
获取哥哥函数
gege = lst[0]
gege()
获取弟弟函数
didi = lst[1]
didi()
3.使用 closure , cell_contents 判定闭包
"""如果返回的元组中有数据说明是闭包,谁的生命周期被延长就打印谁"""
tup = func.__closure__
print(tup)
先获取第一个单元格 cell_contents获取对象中的内容
func1 = tup[0].cell_contents
print("")
"""打印闭包函数didi_hobby中,生命周期被延长的属性"""
print(func1.__closure__[0].cell_contents)
func1()
在获取第二个单元格 cell_contents获取对象中的内容
func2 = tup[1].cell_contents
print("")
"""打印闭包函数gege_hobby中,生命周期被延长的属性"""
print(func2.__closure__[0].cell_contents)
func2()
闭包特点
特点:在闭包函数中,内函数使用了外函数的局部变量,该变量会与内函数发生绑定,延长该变量的生命周期,持续到脚本执行结束.(生命周期和全局变量一样长,但不是全局变量)
def outer(val):
def inner(num):
return val + num
return inner
func = outer(10)
res = func(15)
print(res)
闭包的意义
全局变量的作用域大,容易被篡改
num = 0
def click_num():
global num
num += 1 # num = num + 1
print(num)
click_num()
click_num()
click_num()
num = 100
click_num()
click_num()
改造,用闭包来实现
闭包的意义:闭包可以优先使用外函数中的变量,并对闭包中的值起到了封装保护的作用.
def outer():
x = 0
def click_num():
nonlocal x
x += 1
print(x)
return click_num
click_num = outer()
click_num()
click_num()
click_num()
x = 100
click_num()
click_num()
匿名函数 lambda表达式
用一句话来表示只返回值的函数。
[En]
Use one sentence to express a function that only returns a value.
语法: lambda 参数:返回值
特点: 简介,高效
(1)无参的lambda表达式
def func():
return "文哥是个帅哥"
改造
func = lambda : "文哥是个帅哥"
print( func() )
(2)有参的lambda表达式
def func(n):
return id(n)
改造
func = lambda n : id(n)
print( func(100) )
(3)带有判断条件的lambda表达式
def func(n):
if n % 2 == 0:
return "偶数"
else:
return "奇数"
改造
func = lambda n : "偶数" if n % 2 == 0 else "奇数"
print( func(44) )
三元运算符
只能表达双向分支 只有if else 比较固定 不灵活的语法
语法: 真值 if 条件表达式 else 假值
如果条件表达式成立为True , 返回if前面的真值,反之,返回else后面的假值
n = 13
res = "偶数" if n % 2 == 0 else "奇数"
print(res)
小练习 : 比较两者之间的最大值进行返回
def func(x,y):
if x > y:
return x
else:
return y
改造
func = lambda x,y : x if x>y else y
print( func(40,30) )
locals 与 globals 使用 (了解)
一.locals 获取当前作用域所有的变量
1.全局空间
locals 在函数外 , 获取的是打印之前所有的全局变量
locals 在函数内 , 获取的是调用之前所有的局部变量
def func():
a1 = 1
b2 = 2
a = 1
b = 2
res = locals()
c = 3
print(res)
d = 4
2.局部空间
a = 1
b = 2
def func():
a1 = 1
b2 = 2
res = locals()
c3 = 3
print(res)
d4 = 4
c = 3
func()
d = 4
二.globals 只获取全局空间的全局变量
globals 在函数外 , 获取的是打印之前所有的全局变量
globals 在函数内 , 获取的是调用之前所有的全局变量
1. 全局空间
def func():
a1 = 1
b2 = 2
a = 1
b = 2
res = globals()
c = 3
print(res)
d = 4
2.局部空间
a = 1
b = 2
def func():
a1 = 1
b2 = 2
res = globals()
c3 = 3
print(res)
d4 = 4
c = 3
func() #globals()
d = 4
globals 返回的是内置系统的全局字典
变量可以通过框架中通常使用的字符串来创建。
[En]
Variables can be created through strings, which are generally used in the framework.
def func():
dic = globals()
for i in range(1,5):
# 批量在dic当中添加键值对,以创建全局变量
dic[ "a%d" % (i) ] = i
"""
dic["a1"] = 1
dic["a2"] = 2
dic["a3"] = 3
dic["a4"] = 4
"""
func()
print(a1,a2,a3,a4)
迭代器
迭代器:
能被next()函数调用并不断返回下一个值的对象称为迭代器(Iterator 迭代器是对象)
概念:
迭代器是指用于迭代值的工具。迭代是一个重复的过程,每个迭代都基于先前的结果继续进行。
[En]
An iterator refers to a tool for iterating values. Iteration is a repetitive process, and each iteration continues based on the previous result.
单纯的重复并不是迭代
特征:
并不依赖索引,而通过next指针(内存地址寻址)迭代所有数据,一次只取一个值,
而不是将所有数据都放在内存中。大大节省空间
[En]
Instead of putting all the data in memory. Greatly save space
一.可迭代对象
如果”iter” 在列表里就是可迭代对象 ( iter in 一个列表 )
setvar = {"王同培","马春配","赵万里","赵沈阳"}
获取当前对象的内置成员
lst = dir(setvar)
print(lst)
判断是否是可迭代对象
res = "__iter__" in lst
print(res)
for i in setvar:
# print(i)
二.迭代器
for循环之所以可以遍历所有的数据,是因为底层使用了迭代器,通过地址寻址的方式,一个一个的找数据;
可迭代对象 -> 迭代器 实际上就是从不能够被next直接调用 -> 可以被next指针直接调用的过程
如果是可迭代对象 -> 不一定是迭代器
如果是迭代器 -> 一定是可迭代对象
1.如何创建一个迭代器
setvar = {"王同培","马春配","赵万里","赵沈阳"}
it = iter(setvar)
print(it)
2.如何判断一个迭代器
不仅要有_ iter _ 还要有 _ next _ 在这个it里面
print(dir(it))
res = "__iter__" in dir(it) and "__next__" in dir(it)
print(res)
3.如何调用一个迭代器
next是单向不可逆的过程,一条路走到黑
res = next(it)
print(res)
res = next(it)
print(res)
res = next(it)
print(res)
res = next(it)
print(res)
res = next(it)
print(res) # error 因为单向不可逆 一条路走到黑
4.重置迭代器
it = iter(setvar)
print( it.__next__() )
print( it.__next__() )
print( it.__next__() )
print( it.__next__() )
5.调用迭代器的其他方法
1.for
it = iter(setvar)
for i in it:
print(i)
2.for + next
it = iter(setvar)
for i in range(2):
print( next(it) )
print( next(it) )
print( next(it) )
print( next(it) ) error 超出了寻址范围
6.判断迭代器/可迭代对象的其他方法
从...模块 引入...内容
from collections import Iterator, Iterable
"""Iterator 迭代器 Iterable 可迭代的对象"""
res = isinstance(it,Iterator)
print(res)
res = isinstance(it,Iterable)
print(res)
7.range是迭代器么?
print(isinstance(range(10),Iterator)) # False
print(isinstance(range(10),Iterable)) # True
变成迭代器
it = range(10).__iter__()
print(isinstance(it,Iterator)) # True
print(isinstance(it,Iterable)) # True
调用it (next)
res = next(it)
print(res)
res = next(it)
print(res)
for + next
for i in range(3):
print(next(it)) # 2 3 4
for
for i in it:
print(i)
高阶函数 : 能够把函数当成参数传递的就是高阶函数 (map ,filter ,reduce , sorted)
map
map(func,iterable)
功能: 处理数据
把iterable中的数据一个一个拿出来,扔到func做处理,通过调用迭代器来获取返回值
参数:
func : 函数(内置函数,自定义函数)
iterable : 可迭代性对象 (容器类型数据,range对象,迭代器)
返回值:
迭代器
(1) 把列表中的元素都变成整型
lst = ["1","2","3","4"]
lst_new = []
for i in lst:
lst_new.append(int(i))
print(lst_new)
用map改写
from collections import Iterator,Iterable
it = map(int,lst)
print(isinstance(it,Iterator))
“””
代码解析:
第一次调用迭代器
先把列表中的第一个元素”1″拿出来扔到int中做强转,变成整型1返回出来
第二次调用迭代器
先把列表中的第一个元素”2″拿出来扔到int中做强转,变成整型2返回出来
第三次调用迭代器
先把列表中的第一个元素”3″拿出来扔到int中做强转,变成整型3返回出来
第四次调用迭代器
先把列表中的第一个元素”4″拿出来扔到int中做强转,变成整型4返回出来
“””
1.调用迭代器 next
print(next(it))
print(next(it))
print(next(it))
print(next(it))
print(next(it)) error
2.调用迭代器 for
it = map(int,lst)
for i in it:
print(i)
3.调用迭代器 for + next
it = map(int,lst)
for i in range(3):
print(next(it))
4.强转迭代器 => 列表
it = map(int,lst)
print(list(it)
(2) [1,2,3,4] => [2,8,24,64]
print(1 * 2 1)
print(2 * 2 2)
print(3 * 2 3)
print(4 * 2 4)
1 << 1
2 << 2
3 << 3
4 << 4
lst = [1,2,3,4]
lst_new = []
for i in lst:
lst_new.append(i << i)
print(lst_new)
map改写
def func(n):
print(1111)
return n << n
it = map(func,lst)
print(list(it))
“””
只有在调用迭代器的时候,才会真正触发map函数中的所有内容;不调用不触发;
强转迭代器时,把可以调用的所有数据都放到列表中
第一次调用时:
把1拿出来,扔func当中做处理,返回2,
第二次调用时:
把2拿出来,扔func当中做处理,返回8,
第三次调用时:
把3拿出来,扔func当中做处理,返回24,
第四次调用时:
把4拿出来,扔func当中做处理,返回64,
到此列表[2,8,24,64]
注意点:形参和返回值必须写;
“””
(3) 给你一个列表[“a”,”b”,”c”] => [97,98,99]
字典的键值翻转操作
dic = {97:"a",98:"b",99:"c"}
dic_new = {}
for k,v in dic.items():
# print(k,v) # 97 a | 98 b | 99 c
dic_new[v] = k # dic_new["a"] = 97
print(dic_new)
lst = ["a","b","c"]
lst_new = []
for i in lst:
lst_new.append(dic_new[i])
print(lst_new)
map改写
lst = ["a","b","c"]# func 实现字典的翻转,通过给与a,b,c三个键,得到对应的ascii码,通过list强转得到列表
def func(n):
print(n)
dic = {97:"a",98:"b",99:"c"}
dic_new = {}
for k,v in dic.items():
dic_new[v] = k
print(dic_new) # {'a': 97, 'b': 98, 'c': 99}
return dic_new[n]
it = map(func,lst)
print(list(it))
reduce
reduce(func,iterable)
功能: 计算数据
把iterable中的前两个数据扔到func函数中做计算,把计算的结果和iterable中第三个值在继续扔到func中做计算,以此类推 … 最后返回计算的结果
参数:
func: 自定义函数
iterable : 可迭代对象 (容器类型数据 range对象 迭代器)
返回值:
计算的结果
(1) [7,7,5,8] => 7758
lst = [7,7,5,8]
方法一
strvar = ""
for i in lst:
strvar += str(i)
res = int(strvar)
print(res , type(res))
方法二
"""
7 * 10 + 7 = 77
77 * 10 + 5 = 775
775 * 10 + 8 = 7758
"""
1.先变成迭代器
it = iter(lst)
2.取出两个值
num1 = next(it)
num2 = next(it)
print(num1,num2)
做计算
total = num1 * 10 + num2
print(total) # 77
3.把计算的结果在和剩下的数据做计算
for num in it:
total = total * 10 + num
4.返回最后的结果
print(total , type(total))
reduce改写
'''从...functools模块, 引入 .. reduce方法'''
from functools import reduce
lst = [7,7,5,8]
def func(x,y):
# print(x,y)
return x * 10 + y
res = reduce(func,lst)
print(res)
使用lambda 进行改造
print(reduce(lambda x,y: x*10 + y,lst))
(2) “123” => 123 不使用int的情况下实现该操作;
strvar = "123"
def func(x,y):
return x * 10 + y
把字符串"123" 处理成数字的123
def func2(n):
# dic = {"0":0,"1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9}
dic = {}
for i in range(10):
dic[str(i)] = i
return dic[n]
it = map(func2,strvar)
res = reduce(func,it)
print(res,type(res))
简写
print(reduce(lambda x,y: x*10 + y,it))
filter
filter(func,iterable)
功能: 过滤数据
在自定义的函数中,
如果返回True, 该数据保留
如果返回False,该数据舍弃
参数:
func: 自定义函数
iterable : 可迭代对象 (容器类型数据 range对象 迭代器)
返回值:
迭代器
1.只要列表中所有的偶数
lst = [1,2,34,5,65,6,56,7,56,756,7567,11]
lst_new = []
for i in lst:
if i % 2 == 0 :
lst_new.append(i)
print(lst_new)
filter改写
def func(n):
if n % 2 == 0:
return True
else:
return False
it = filter(func,lst)
print(list(it))
使用lambda 改写
it = filter(lambda n :True if n % 2 == 0 else False , lst)
print(list(it))
print(list(filter(lambda n :True if n % 2 == 0 else False , lst)))
sorted
sorted(iterable,key=函数,reverse=False)
功能:排序数据
参数:
iterable : 可迭代对象 (容器类型数据 range对象 迭代器)
key : 指定函数(自定义/内置)
reverse : 是否倒序
返回值:
列表
tup = (-90,89,78,3)
1.从小到大
res = sorted(tup)
print(res,type(res))
2.从大到小
res = sorted(tup,reverse = True)
print(res,type(res))
3.按照绝对值进行排序
tup = (-90,-100,1,2)
res = sorted(tup,key=abs)
print(res)
"""
1 => abs(1) => 1
2 => abs(2) => 2
-90 => abs(-90) => 90
-100 => abs(-100) => 100
"""
4.按照自定义函数进行排序
tup = (19,23,42,87)
"""
42 % 10 2 => 42
23 % 10 3 => 23
87 % 10 7 => 87
19 % 10 9 => 19
"""
def func(n):
print(n)
return n % 10
lst = sorted(tup,key = func)
print(lst)
5.任意的容器类型数据都可以通过sorted排序
container = "abc"
container = [1,2,3]
container = (1,2,3)
container = {"你好","王文","你真帅"}
container = {"caixukun","xiaozhan","zhaoshenyang","wangyibo"}
container = {"ww":"英俊帅气","zxy":"猥琐抠脚","zwl":"斯文败类"} # 排的是字典的键
print(sorted(container))
总结:
sorted (推荐使用sorted)
(1) 可以排序所有的容器类型数据
(2) 返回一个新的列表
sort
(1) 只能排序列表
(2) 基于原来的列表进行排序
Original: https://www.cnblogs.com/shuaiyao666/p/15894818.html
Author: 小帅同学啊
Title: python函数
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/509990/
转载文章受原作者版权保护。转载请注明原作者出处!