

一、目的
1.了解深度学习的基本原理;
2.能够使用PaddleHub 深度学习开源工具进行图像识别;
3.能够使用PaddlePaddle 训练神经网络模型;
4.能够使用Paddle 完成手写实验.
5.能够使用keras 训练神经网络模型。
二、环境配置:
Anaconda
PaddlePaddle (PaddlePaddle-gpu )
PaddleHub
Tensorflow2.0.0
Keras2.3.1
Pycharm
4.1 Tensorflow简介
TensorFlow 是 Google 开发的一款神经网络的 Python 外部的结构包,也是一个
采用数据流图来进行数值计算的开源软件库.TensorFlow 让我们可以先绘制计算
结构图,也可以称是一系列可人机交互的计算操作,然后把编辑好的Python 文件转
换成更高效的C++,并在后端进行计算。TensorFlow 无可厚非地能被认定为神经
网络上最好的图书馆之一。它擅长的任务是训练深度神经网络。通过使用
[En]
One of the best libraries in the network. The task it is good at is to train deep neural networks. By using the
TensorFlow 我们就可以快速的入门神经网络,大大降低了深度学习(也就是深度
神经网络)的开发成本和开发难度。TensorFlow 的开源性,让所有人都能使用
并保持和巩固它。这样才能快速更新和推广。
[En]
And maintain and consolidate it. So that it can be updated and promoted quickly.
因为TensorFlow 是采用数据流图(data flow graphs )来计算,所以首先我们
得创建一个数据流流图,然后再将我们的数据(数据以张量(tensor)的形式存在)
放在数据流图中计算。节点(Nodes )在图中表示数学操作,图中的线(edges )则
表示在节点间相互联系的多维数据数组,即张量(tensor)。训练模型时tensor 会不
断的从数据流图中的一个节点flow 到另一节点,这就是TensorFlow 名字的由来。
Tensor 张量意义:张量有很多种,零阶张量为纯量或者标量,一阶张量为向
量,二阶张量是一个矩阵,等等。
[En]
Quantity, the second-order tensor is a matrix, and so on.

4.2 Keras简介
4.2.1 Keras简单介绍
Keras 是一个开放源码的高级深度学习程序库,是一个用 Python 编写的高级
神经网络API ,能够运行在TensorFlow 或Theano 之上。其主要作者和维护者是
Google 公司的工程师,以MIT 开放源码方式授权。Keras 使用最少的程序代码、
在最短的时间内,我们可以建立一个深度学习模型,训练,评估精度,并做出预测。
[En]
In the least time, we can establish a deep learning model, train, evaluate the accuracy, and make predictions.
相对来说,使用 TensorFlow 这样低级的链接库虽然可以完全控制各种深度学习
模型的细节,但你需要写更多的程序代码,花更多的时间进行开发。
[En]
The details of the model, but you need to write more program code and spend more time developing.
Keras 的开发重点是支持快速的实验,能够把你的 idea 迅速转换为结果。

4.2.2为什么选择 Keras
1.Keras 被工业界和学术界广泛采用;
2.Keras 模型可以轻松部署在更广泛的平台;
3.Keras 支持多个后端引擎;
4.Keras 拥有强大的多 GPU 和分布式训练支持;
5.Keras 的发展得到深度学习生态系统中的关键公司的支持。
4.3 Tensorflow和 Keras的安装
在配置好 anaconda 环境,可以直接使用 pip 的情况下,这里注意激活了虚拟
环境。使用pip 下载TensorFlow2.0.0 库和Keras2.3.1 库。
4.3.1 Tensorflow的安装

4.3.2 Keras的安装

4.3.3 Tensorflow和 keras的安装测试
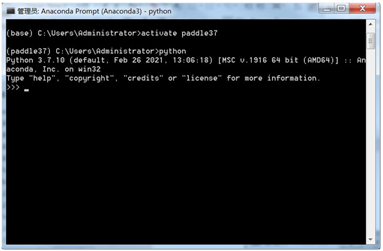
① 点击 开始,选择 运行 (也可以快捷键win+R ),进入cmd
或者进入anaconda prompt ,开始菜单进入,选择。
② 激活虚拟环境 paddle37
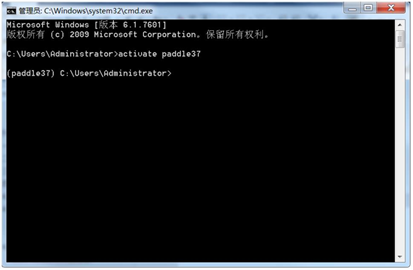
输入命令:activate paddle37
③ 进入python 环境
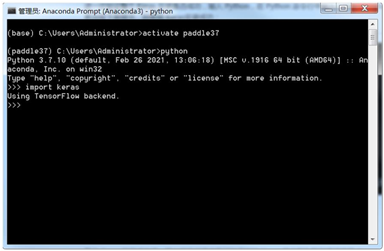
④ 导入keras 命令:import keras
出现如图所示,表示keras 安装运行成功。
利用 Keras进行一个程序的测试
使用 Keras 运行一个简单例子,用来对 IMDB 的正负电影评论进行分类。
import keras
from keras import models
from keras import layers
from keras.datasets import imdb
import numpy as np
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words =10000 )
def vectorize_sequences (sequences, dimension=10000 ):
# Create an all-zero matrix of shape (len(sequences), dimension)
results = np.zeros((len (sequences), dimension))
for i, sequence in enumerate (sequences):
results[i, sequence] =1. # set specific indices of results[i] to 1s
return results
# Our vectorized training data
x_train = vectorize_sequences(train_data)
# Our vectorized test data
x_test = vectorize_sequences(test_data)
# Our vectorized labels
y_train = np.asarray(train_labels).astype(‘float32’)
y_test = np.asarray(test_labels).astype(‘float32’)
model = models.Sequential()
model.add(layers.Dense(16 ,activation = ‘relu’,input_shape =(10000 ,)))
model.add(layers.Dense(16 ,activation = ‘relu’))
model.add(layers.Dense(1 ,activation = ‘sigmoid’))
model.compile(optimizer = ‘rmsprop’,
loss = ‘binary_crossentropy’,
metrics =[‘acc’])
model.fit(x_train, y_train,epochs =4 ,batch_size =512 )
result = model.evaluate(x_test, y_test)
print (result)
结果如下:
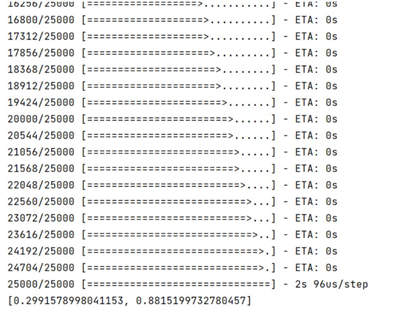
本文介绍的 Keras 的 CPU 版本的安装,推荐大家以后尽可能使用 GPU 版本,提高运算速度。
跑完本代码发现,CPU 版本下某些模型的训练时间还是比较长的。例如使
用 VGG 预训练模型,对 Kaggle 猫狗分类问题进行训练,并微调 VGG 顶层
参数方面,整个训练时间达到了5小时左右。
[En]
Parameters, the whole training time has reached about 5 hours.
如果安装 GPU 版本,需要额外安装 CUDA Toolkit + cuDNN 。需要特别注
意的是 CUDA+cuDNN 的版本。因为每个人的 GPU 显卡型号和安装版本不尽
这是相同的,所以我不会在本文中重复。
[En]
It is the same, so I will not repeat it in this article.
没有 GPU ,本代码基本也能跑得通,就是大型模型的训练速度比较慢。
2利用 Keras实现 CNN实现手写数字识别
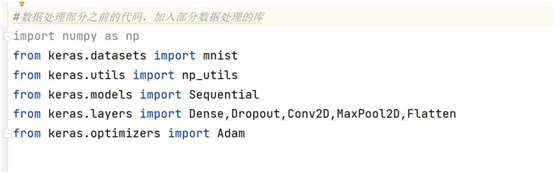
4.5.1加载 keras与 “手写数字识别 “实验相关的类库。
4.5.2加载数据集


本实验使用的 mnist 数据集可以使用Keras 直接加载。文件内容包括:训练数
据介绍,测试数据分两部分,分别包含60000条手写数字数据,每个样本
[En]
According to, test data two parts, respectively, contains 60000 pieces of handwritten digital data, each sample is
28*28 像素的。
4.5.3数据预处理
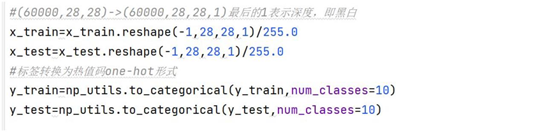
使用 keras 必须声明输入图像深度的尺寸,例如,具有所有 3 个 RGB 通道
的全色图像的深度为 3 。本实验中,我们将深度定为 1 ,将数据集从形状
(n,rows,cols )转换为(n,rows,cols,channels )。并将数据的大小除以 255 进行归
宜华。常态化的原因:在不同的评价指标中,维度单位往往不同,变化的幅度也不同。
[En]
Yihua. The reason for normalization: in different evaluation indicators, the dimensional units are often different, the range of changes.
在不同的量级,如果不归一化,一些指标会被忽略,从而影响数据。
[En]
In different orders of magnitude, if not normalized, some indicators will be ignored, thus affecting the data.
分析结果。归一化本身就是将需要的数据经过一定的处理后限制在一定的范围内。
[En]
Results of the analysis. Normalization itself is to limit the required data to a certain range after certain processing.
内。np_utils.to_categorical 是将标签转换为热值码,我们需要将 0-9 共十个数字
标签转化成onehot 标签,例如:数字标签”6″转化为onehot 标签就是[0 ,0 ,0 ,
0 ,0 ,0 ,1 ,0 ,0 ,0]。
4.5.4构建网络
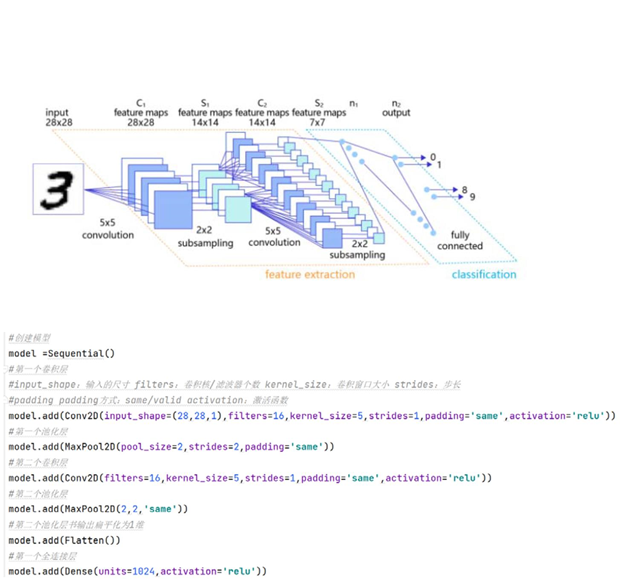

卷积神经网络由多个卷积层和汇聚层组成,如下所示。卷积层负责输入
[En]
The convolution neural network consists of multiple convolution layers and pooling layers, as shown below. The convolution layer is responsible for the input
行扫描生成更抽象的特征表示,这些特征被池化层过滤,而保留是最重要的。
[En]
Line scan to generate more abstract feature representations, which are filtered by the pooling layer, and retention is the most important.
的特征信息。
2.编译、训练、评估、保存模型
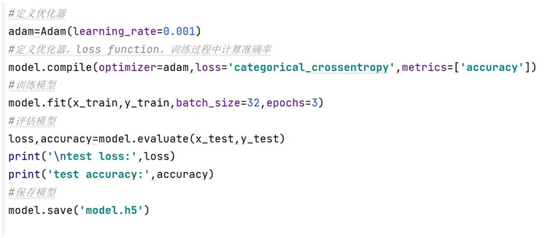
编译模型时,声明损失函数采用交叉熵和优化器(SGD,Adam 等),接着,
传入训练集数据进行训练,batch 大小设置为 32 ,训练周期设为 3 ,接下来,传
入测试集数据对模型进行评估,最后将训练好的模型保存为 h5 格式的模型文件。
3.训练结果 模型训练结果:
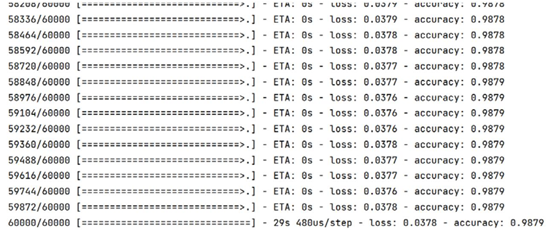
模型评估结果:
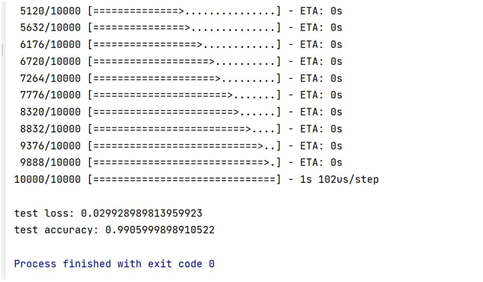
3利用 Paddle实现手写识别

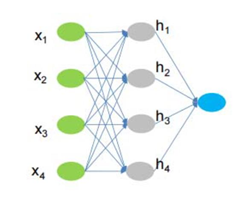
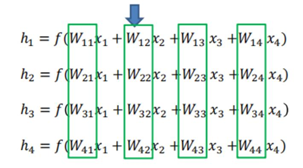
4.6.1神经网络
神经网络(Neural Network)是一种计算机模型或者数学模型,是存在于计算
计算机的神经系统由大量神经元连接并进行计算,根据外部信息发生变化。
[En]
The nervous system of a computer, connected by a large number of neurons and calculated, changes on the basis of external information.
内部结构经常被用来模拟投入和产出之间的复杂关系。
[En]
The internal structure is often used to model the complex relationship between input and output.
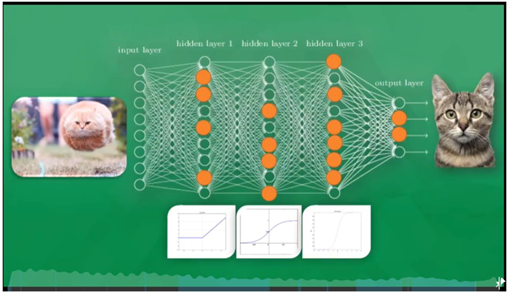
下图就是一个神经网络系统,它有很多层组成。输入层(Input Layer )负责
接受信息。输出层(Output Layer )是计算机对这个输入信息的判断结果。中间
的隐藏层(Hidden Layer)是对输入信息的传递和加工处理。
4.6.2如何训练神经网络
每个神经元都有属于它的激活函数(activation function),用这些函数给计
首先,需要大量的数据。例如,如果它想判断一张照片是不是猫,它必须进入数千万盘磁带。
[En]
First of all, a lot of data is needed. For example, if it wants to judge whether a picture is a cat, it has to enter tens of millions of tapes.
猫狗的照片贴上标签,然后训练数千万次。其次,错误的结果也会有所帮助
[En]
Pictures of cats and dogs with labels, and then train tens of millions of times. Second, the wrong results can also help
神经网络被训练,网络会比较正确答案和错误答案之间的差异,然后把这个
[En]
The neural network is trained, and the network will compare the difference between the right answer and the wrong answer, and then put this
这些差异被反向传递回来,每个相应的神经元在其努力的方向上做出一些小的改变。
[En]
The differences are passed back in reverse, with each corresponding neuron making a little change in the direction it strives for.
然后,改进后的神经元可以用来在下一次训练中获得稍微更精确的结构。
[En]
Then the improved neurons can be used to get a slightly more accurate structure in the next training.
每个神经元都有属于它的激活函数(activation function),用这些函数给计算
一种刺激的行为。当电脑第一次看到这只猫的照片时,只有部分神经元被激活
[En]
A stimulating behavior. When the computer was shown a picture of the cat for the first time, only some of the neurons were activated
被激活的神经元传递的信息是输出最有价值的信息。如果输出的结果为
[En]
The information transmitted by the activated neurons is the most valuable information for the output. If the result of the output is
如果它被判定为狗,也就是说它是错的,那么它会修改神经元,一些容易被激活的神经。
[En]
If it is judged to be a dog, that is to say, it is wrong, then it will modify the neurons, some nerves that are easy to be activated.
袁会变得迟钝,其他神经元会变得敏感,所以经过反复训练,所有的神经
[En]
Yuan will become dull, other neurons will become sensitive, so after training again and again, all nerves
元数据的参数正在发生变化,并且对重要信息变得越来越敏感。
[En]
The parameters of meta are being changed, and they become more and more sensitive to important information.
4.6.3梯度下降( Gradient Descent)
运用神经网络的时候,必然会用到误差方程(Cost Function ):
Cost=(predicted-real)^2=(Wx-y)^2,
用来计算预测出来的值和我们实际的值的差别.梯度是当前 Cost 的斜率,
Cost 误差最小的地方就是 cost 曲线最低的地方,而当前所知道的是自己所在位
如果你设置了一个下降的方向,你会继续沿着当前的方向下降,直到渐变线“平躺”,你会得到
[En]
If you set a descending direction, you will continue to descend in the current direction until the gradient line “lies flat”, and you will get
了 Wx-y 参数的最理想值。
4.6.4卷积神经网络 CNN
卷积神经网络(Convolutional Neural Networks,CNN )是一类包含卷积计算
具有深度结构的前馈神经网络是深度学习的代表算法之一。卷积神经网络仿真
[En]
The feedforward neural network with depth structure is one of the representative algorithms of deep learning. Convolution neural network imitation
造生物的视知觉(( visual perception )机制构建,能够进行平移不变分类。对卷
积神经网络的研究始于二十世纪 80 至 90 年代,LeNet-5 是较早出现的卷积神经
网络。
为图像分类添加全互联网络:
[En]
Add a fully connected network for image classification:
① CNN 特点之一:局部卷积
将卷积想象为作用于矩阵的滑动窗函数。滑动窗口也称为卷积
[En]
Think of convolution as a sliding window function acting on a matrix. Sliding window is also called convolution
内核、过滤器或特征检测器。
[En]
Kernel, filter or feature detector.
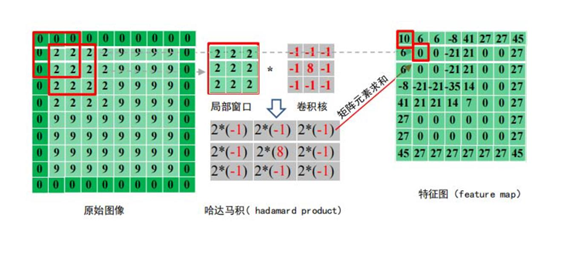
对于给定的输入图像,输出特征映射中的每个像素实际上是输入图像中的一个局部区域。
[En]
For a given input image, each pixel in the output feature map is actually a local area in the input image.
中像素的加权平均值,其权重由卷积核定义。
[En]
The weighted average of pixels in the, whose weight is defined by the convolution kernel.
卷积具体实例:
② CNN 特点之二:多卷积核
要完全提取特征,可以使用多个卷积核
[En]
To fully extract features, multiple convolution kernels can be used
每个卷积核对输入图像进行卷积以生成另一图像。不同卷积成核
[En]
Each convolution kernel convolutes the input image to generate another image. Different convolution nucleation
所得到的不同图像可以理解为输入图像的不同通道。
[En]
The resulting different images can be understood as different channels of the input image.
③ CNN 特点之三:池化处理
池化处理也叫作降采样处理(down-pooling),是对不同位置的特征进行聚合
统计数字。通常取相应位置的最大值(最大池)、平均池(平均值)等。
[En]
Statistics. Usually take the maximum value of the corresponding position (maximum pool), average average pool), and so on.
池化的优点:1.降维2.克服过拟合3.在图像识别领域,池化还能提供平移和
旋转不变性。
④ CNN 特点之四:多层处理
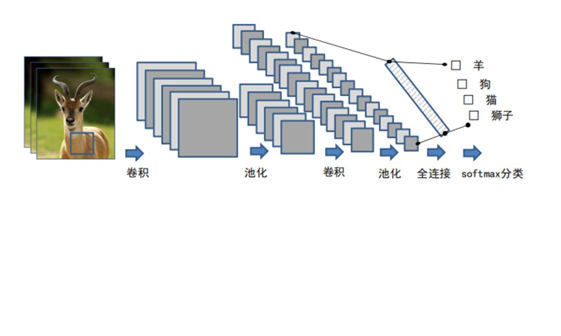
一般而言,在图像处理中,单层卷积和下采样往往只学习局部特征。图层
[En]
Generally speaking, in image processing, one-layer convolution and downsampling often learn only local features. Layer
数字越多,学习的功能就越全局。因此,通过这样的多层处理,形成了低层特征的组合。
[En]
The more the number, the more global the features learned. So through such multi-layer processing, the combination of low-level features is formed.
更高级的特征表示。
4.6.5 MNIST数据集
Mnist 数据集分为两部分,分别含有 50000 张训练图片和10000 张测试图片。
每一张图片包含 28*28 个像素。Mnist 数据集把代表一张图片的二维数据转
开成一个向量,长度为 28*28=784 。因此在 Mnist 的训练数据集中训练图片是一
个形状为[50000, 784]的张量,第一个维度数字用来索引图片,第二个维度数字
用于索引每张图片中的像素,图片中像素的强度值介于-1和1之间。
[En]
Used to index the pixels in each picture, the intensity value of a pixel in the picture is between-1 and 1.
4.6.6步骤
① 在配置好 anaconda 环境,可以直接使用 pip 的情况下,使用 pip 下载
paddlepaddle 库和paddlepaddle-hub 库。
② 加载飞浆平台与”手写数字识别”实验相关的类库。
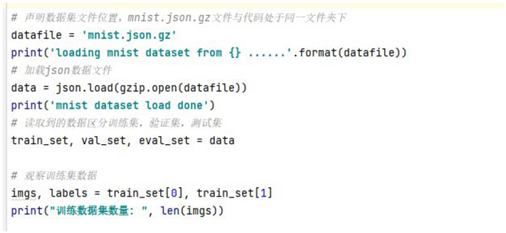
③ 数据读取与数据集划分
本实验使用的mnist 数据集以json 格式存储在本地。
在’./”目录下读取文件名称为’mnist.json.gz’的 MINST 手写数字识别数据,文
件格式是压缩后的 json 文件。文件内容包括:训练数据、验证数据、测试数据三
部分,分别包含 50000 、10000 、10000 条手写数字数据和两个元素列表。以训练
集数据为例,它为两个元素的列表为[traim_imgs, train_labels]。
train_imgs:一个维度为[50000,784]的二维列表,包含 50000 张图片。每张图
片用一个长度为784 的向量表示,内容是28*28 尺寸的像素灰度值(黑白图片)。
train_labels:一个维度为[50000,]的列表,表示这些图片对应的分类标签,即
0-9 之间的一个数字。
接下来将数据读取出来:

④ 定义数据读取函数
飞桨提供分批次读取数据函数paddle.batch ,该接口是一个 reader 的装饰器,
返回的 reader 将输入的 reader 的数据打包,成指定的 batch_size 大小的批处理数据
(batched.data)。
在定义数据读取函数时,我们需要做很多事情,包括但不限于:
[En]
There are many things we need to do in defining data reading functions, including, but not limited to:
打乱数据,确保每轮训练读取数据的顺序不同。
[En]
Disrupt the data to ensure that the order of data read in each round of training is different.
数据类型转换。
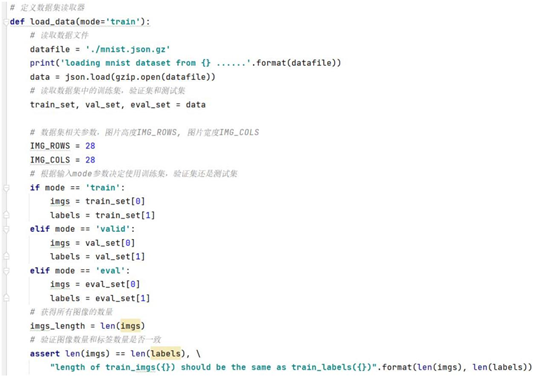
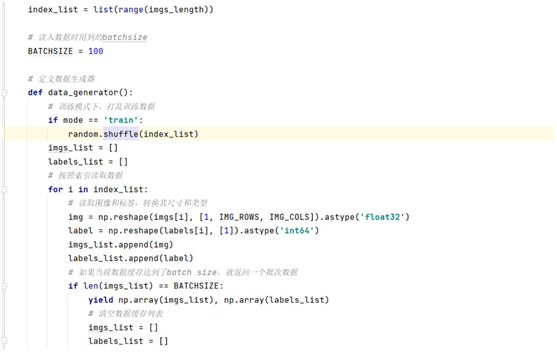

上面代码中 mode 参数可以取三个值中的一个,分别是 train 、valid 、eval ,
选择不同的模式,读取不同的数据集。为了与后面的代码兼容,读取的变量都是
[En]
Different modes are selected and different datasets are read. In order to be compatible with the later code, the read variables are all
相同,都是imgs 、labels;
在数据生成器中,只有在 mode 为train 的情况下我们才考虑把读取的数据打
乱;接下来是数据格式处理,目标类型是 shape[1,28,28],1 表示灰度图,数据类型
为 float32;通过 yield 关键字返回一个 batch 的数据;在最后一个 index_list 中,如
果 imgs_list 长度不满足一个 batch ,这时 imgs_list 长度不为零,会直接跳出 for
循环,被后面的len(imgs_list)拦截,形成一个小的 mini-batch 。
检查机器的代码。如果数据集中的图片和标签数量不同,请解释数据逻辑。
[En]
Check the code for the machine. If the number of pictures and tags in the dataset is different, explain the data logic.
存在问题。可以使用assert 语句校验图像数量和标签数据是否一致。
手动验证方法:首先打印输出的数据,看是否为设定的格式。然后从培训中
[En]
Manual verification method: first print the data output to see if it is the set format. Then from the training
实验结果验证了数据处理和读取的有效性。在实现数据处理和加载功能后,可以调整
[En]
The results verify the effectiveness of data processing and reading. After implementing the data processing and loading functions, we can adjust the
用它读取一次数据,观察数据的shape 和类型是否与函数中设置的一致。
⑤ 定义模型结构

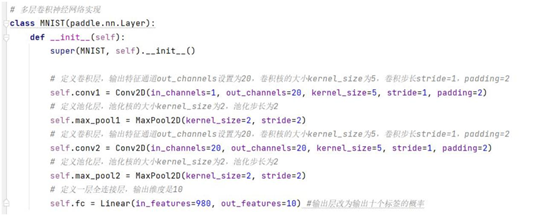

卷积神经网络由多个卷积层和汇聚层组成,如下所示。卷积层负责输入
[En]
The convolution neural network consists of multiple convolution layers and pooling layers, as shown below. The convolution layer is responsible for the input
行扫描生成更抽象的特征表示,这些特征被池化层过滤,而保留是最重要的。
[En]
Line scan to generate more abstract feature representations, which are filtered by the pooling layer, and retention is the most important.
的特征信息。
线性模型的局限性:完全连接的神经网络和仅通过线性变换的具有任意层的单层神经网络
[En]
Limitations of linear models: fully connected neural networks and single-layer neural networks with arbitrary layers only through linear transformation
网络的表达能力没有差别,线性模型所能解决的问题是有限的。激活功能的
[En]
There is no difference in the expressive ability of the network, and the problem that the linear model can solve is limited. Of the activation function
其目的是去线性化,如果每个神经元的输出通过一个非线性函数,那么整个上帝
[En]
The aim is to de-linearize, if the output of each neuron is passed through a nonlinear function, then the whole god
通过网络的模型不再是线性的,而这个非线性函数就是激活函数。
[En]
The model through the network is no longer linear, and this nonlinear function is the activation function.
在评估激活函数的有用性时,需要考虑以下因素:
[En]
When evaluating the usefulness of an activation function, the following factors need to be considered:
1)该函数应是单调的,这样输出便会随着输入的增长而增长,从而使利用梯度
用下降法求局部极值点是可能的。
[En]
It is possible to find the local extreme point by the descending method.
2)该函数应是可微分的,以保证该函数定义域内的任意一点上导数都存在,从
梯度下降法可以正常使用这种激活函数的输出。
[En]
The gradient descent method can use the output from this kind of activation function normally.
relu 函数
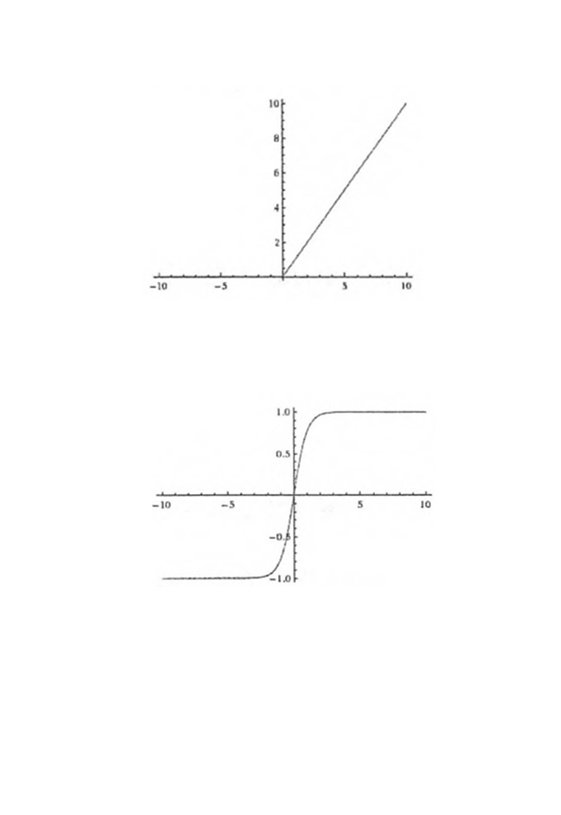
relu 函数是个非常常用的激活函数,其公式为:f(x) = max(0, x),即,大于0
的为其本身,否则为0
.
Tanh 函数
其公式为:y =(exp(x)-exp(-x))/(exp(x)+exp(-x)) = (1 – exp(-2x)) / (1 +
exp(-2x)),导数:df(x)/dx=1-f(x)^2
在具体的例子中,如卷积神经网络Convolutional neural networks 的卷积层
中,一般使用的激励函数是 relu.在循环神经网络中recurrent neural networks,一般
使用的是tanh 或者是relu 。
Softmax 函数
Softmax 函数,又称归一指数函数,多用于分类过程,它将多个神经元的输出,
映射到(0.1 )区间内。F.softmax 的作用是,输出每一个预测标签(0-9 )的的概
并且十个预测标签的概率之和为1。
[En]
And the sum of the probabilities of the ten prediction tags is 1.
⑥ 训练模型
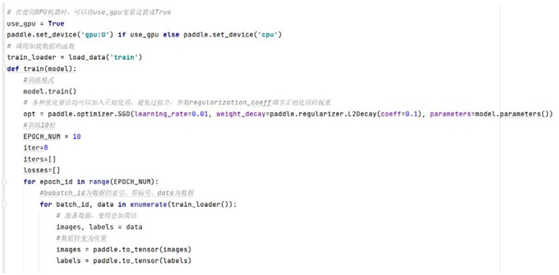
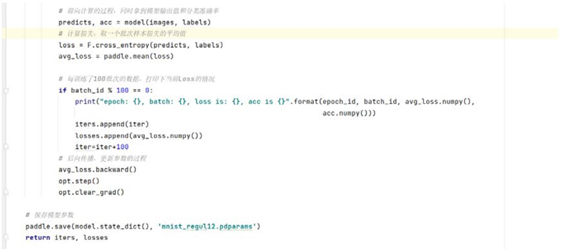
通过 paddle.set_device API ,设置在 GPU 上训练还是 CPU 上训练。参数
device (str):此参数确定特定的运行设备,可以是cpu 、gpu:x 或者是xpu:x 。其
中,x 是GPU 或XPU 的编号。当 device 是cpu 时,程序在CPU 上运行;当 device
是gpu:x 时,程序在GPU 上运行。
opt = paddle.optimizer.SGD(learning_rate =0.01 ,
weight_decay =paddle.regularizer.L2Decay(coeff =0.1 ),
parameters =model.parameters())
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法 SGD更新
参数,学习率 learning_rate代表参数更新幅度的大小,即步长。当学习率最优
模型的有效容量最大,最终效果最好。深度学习任务的学习速度和类型
[En]
The effective capacity of the model is the largest, and the final effect is the best. Learning rate and types of deep learning tasks
与此相关,合适的学习速度往往需要大量的实验和经验。探讨学习率的最佳值是十分必要的
[En]
Related, the appropriate learning rate often requires a lot of experiments and experience. It is necessary to explore the optimal value of learning rate
注意如下两点:
学习的速度不是越小越好。学习率越小,损失函数的变化率越慢,这意味着需要
[En]
The learning rate is not as small as possible. The smaller the learning rate, the slower the change rate of the loss function, which means that the need for
它需要更长的时间才能收敛。
[En]
It takes longer to converge.
学习率越高越好。梯度只根据总样本集中的一个批次计算,抽样误差为。
[En]
The greater the learning rate, the better. The gradient is calculated based on only one batch in the total sample set, and the sampling error will be.
因此,计算出的梯度不是全局最优方向,存在波动。当逼近最优解时,过大
[En]
As a result, the calculated gradient is not the global optimal direction, and there are fluctuations. When approaching the optimal solution, too large
学习速度会使参数在最优解附近振荡,损失难以收敛。
[En]
The learning rate will cause the parameters to oscillate near the optimal solution, and the loss is difficult to converge.
为了避免模型的过拟合,增加了正则化项。
[En]
Regularization term is added to avoid over-fitting of the model.
过拟合现象:对于样本量有限、但需要使用强大模型的复杂任务,模型很容
很容易表现出过拟合的表现,即训练集上的损失较小,而验证集或测试集上的损失较大。
[En]
It is easy to show the performance of over-fitting, that is, the loss on the training set is small, and the loss on the verification set or test set is larger.
过度拟合的原因:模型过于敏感,训练数据量太少或噪声太大。
[En]
The reason for over-fitting: the model is too sensitive, and the amount of training data is too little or there is too much noise.
正则项:为了防止模型过拟合,只能对模型进行缩减,不能扩大样本量。
[En]
Regularization term: in order to prevent the model from overfitting, the model can only be reduced without the possibility of expanding the sample size.
类型A的复杂性可以通过限制参数或可能的值(参数值越小越好)来实现。在模块中
[En]
The complexity of type A can be achieved by limiting the number of parameters or possible values (parameter values as small as possible). In the module
当参数越多或值越大时,将参数尺度的惩罚项人为地添加到类型A的优化目标(损失)中
[En]
The penalty term for the parameter scale is artificially added to the optimization goal (loss) of type A. When the more parameters or the larger the value
处罚就越重。该模型通过调整惩罚项的权重系数,尽可能地减少训练次数。
[En]
The greater the penalty is. By adjusting the weight coefficient of the penalty item, the model can reduce the training as much as possible.
练损失”和”保持模型的泛化能力”之间取得平衡。
正则化项的存在增加了模型在训练集中的损失。支持所有参数的飞行划桨
[En]
The existence of regularization term increases the loss of the model in the training set. Flying paddle support for all parameters plus
统一的正则化项,也支持添加特定参数的正则化项。前者的实施情况如下
[En]
A unified regularization term that also supports adding regularization terms for specific parameters. The implementation of the former is as follows
仅在优化器中设置 weight_decay参数即可实现。使用参数coeff 调节正则化项的
权重越大,对模型复杂性的惩罚就越大。
[En]
The greater the weight, the higher the penalty for the complexity of the model.
cross_entropy()为计算交差熵函数,常用于分类问题,神经网络的输出层为
“输出十个标签的概率”模式,因此,正确解标签对应的输出越大,交叉熵的值越
接近0 ;当输出为1 时,交叉熵误差为0 。反之,如果正确解标签对应的输出越
小,则交叉熵的值越大。
paddle.save(model.state_dict(), ‘mnist_regul12.pdparams’)为输出参数模型函 数,可以用于后续加载继续训练。
⑦ 结果可视化

可视化分析:
在对模型进行训练时,往往需要观察模型的评价指标,分析模型的优化过程,以确保
[En]
When training the model, it is often necessary to observe the evaluation index of the model and analyze the optimization process of the model to ensure that
训练是有效的。可选用这两种工具:Matplotlib 库和VisualDL 。在此处,仅展示
Matplotlib 的画法。
Matplotlib 库:Matplotlib 库是 Python 中使用的最多的 2D 图形绘图库,
它有一套完全仿照 MATLAB 的函数形式的绘图接口,使用轻量级的 PLT 库
(Matplotlib)作图是非常简单的。
VisualDL :如果期望使用更加专业的作图工具,可以尝试VisualDL ,飞桨
可视化分析工具。VisualDL 能够有效地展示飞桨在运行过程中的计算图、各种
指标和数据信息的变化趋势。
[En]
Change trend of indicators and data information.
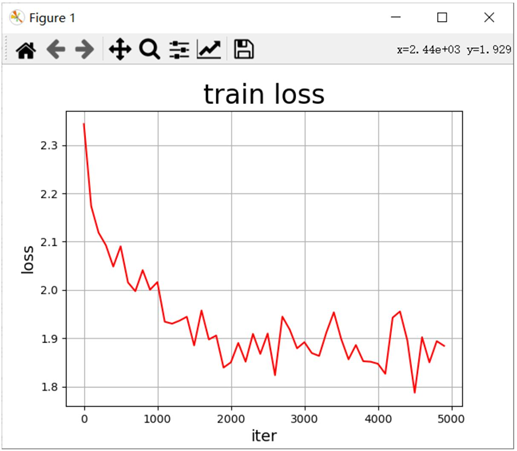
使用Matplotlib 库绘制损失随训练下降的曲线图。将训练的批次编号作为 X
轴坐标,该批次的训练损失作为Y 轴坐标。训练开始前,声明两个列表变量存
储对应的批次编号(iters=[])和训练损失(losses=[]),随着训练的进行,将iter 和
losses 两个列表填满。训练结束后,将两份数据以参数形式导入 PLT 的横纵坐标。
最后,调用plt.plot()函数即可完成作图。
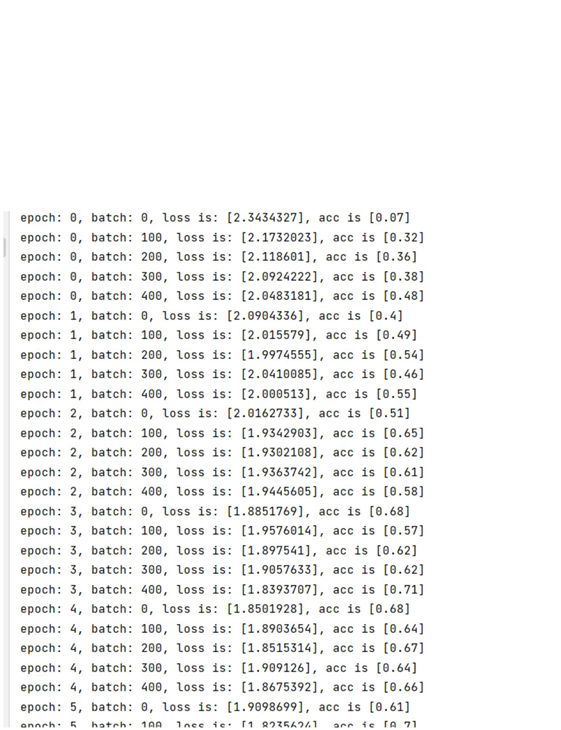
结果如下所示:
Original: https://blog.csdn.net/feiker666/article/details/122140426
Author: gaofeimax
Title: 基于神经网络的图像识别
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/509021/
转载文章受原作者版权保护。转载请注明原作者出处!