

研究背景:工厂生产一批布料,将测试和记录布料的整个生产环境,包括机器张力、速度、温度、压力、机器速度等一些基本数据。所生产的布料测试机将记录布料的参数,包括布料的颜色、克重、裁剪、透光点等。
[En]
Research background: the factory produces a batch of cloth, which will test and record the entire production environment of the cloth, including some basic data such as machine tension, speed, temperature, pressure, machine speed and so on. The produced cloth testing machine will record the parameters of the cloth, including the color of the cloth, gram weight, cutting, light transmission point and so on.
所以有了这些数据,我们可以通过深入学习来预测面料是否合格,这应该是以下公式。
[En]
So with these data, we can predict whether the fabric is qualified through in-depth learning, which should be the following formula.

根据现场生产布料的老师傅的经验,他认为生产机的压力、张力和温度可能对布料的透光点有很大影响,这是凭经验判断的。显然,我们需要数据支持。我们需要一台机器模型来验证情况是否如此。
[En]
According to the experience of the old master who produces the cloth on the spot, he thinks that the pressure, tension and temperature of the production machine may have a great influence on the light transmission point of the cloth, which is judged by experience. Obviously, we need data support. We need a machine model to verify whether this is the case.
开搞
1.第一步 我们需要把检测机器记录的历史数据 整理归纳,导出到 csv 文件,方便 我们下一步处理,记录数据用的mongodb 数据库。我们 用python 导出到 csv文件,我们需要 一个透光点值和 对应的张力,压力,温度值。
import pymongo
import json
import csv
import os
from dateutil.parser import *
#################
stime = '2022-03-02 00:00:00' #开始时间
etime = '2022-03-10 00:00:00' #结束时间
b_path = 'b_train.csv'; #写入的文件
mongo_name = 'tensorflow' # 数据库名称
line_name = '三号产线DeviceHisData' #产线名称
line_code = 'U306' #产线code
cut_code = 'A302' #cut code
#####################
client = pymongo.MongoClient(host='localhost', port=27017)
db = client[mongo_name]
#写入数据
if os.path.exists('b_path'):
os.makedirs(b_path)
#时间范围 先生成数据
myDatetime = parse(stime)
myDatetime2 = parse(etime)
lin306 = db[line_name].find({'code':line_code,'TimeData': {'$gte':myDatetime,'$lt':myDatetime2}},{"_id": 0,'line':1,'value':1,'code':1,'TimeData':1}).sort("TimeData") #查询全部
cuts = db['cutscreendataHis'].find({'type': 'Data','code':cut_code,'Begintime': {'$gte':myDatetime,'$lt':myDatetime2}},{"_id": 0,'type':1,'code':1,'dataCnc':1,'data':1,'Begintime':1}).sort("Begintime") #查询全部
dianshu = []
for line in lin306: #循环打印
value = json.loads(line['value'])
TimeData = line['TimeData'].strftime("%Y-%m-%d %H:%M:%S")
dianshu.append(value)
#print("dianshu==",dianshu)
colors_len = len(dianshu)
print("colors_len",colors_len)
### 中间省略 for循环处理数据
with open(b_path, 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(lists)
print("-----------导出csv完成------------")
导出的csv 文件数据如下,总共5000多数据:
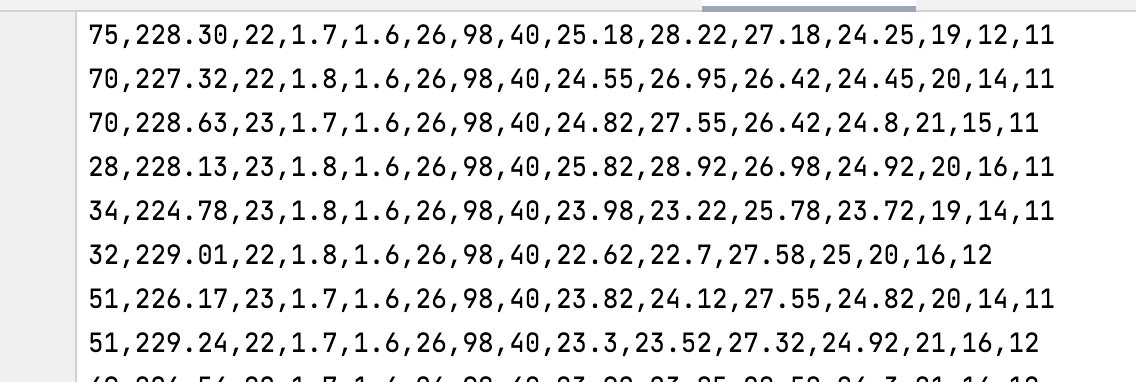
2.第二步 数据预处理,通过 pandas 读取 b_train.csv文件。
dataset_path = 'b_train.csv'
column_names = ['dianshu','a','b','c','d','e','f']
#'o','p','q','r','s','t','u','v','w','x','y','z',
#'ab','ac','ad','ae','af','ag']
raw_dataset = pd.read_csv(dataset_path,
na_values = "?", comment='\t', names=column_names,
sep=",", skipinitialspace=True)
dataset = raw_dataset.copy()
#数据清洗 去掉没用值
dataset.isna().sum()
dataset = dataset.dropna()
#打印数据详情
print("dataset.tail() ",dataset.tail());
3.第三步 分出训练数据80%和测试数据20% 并把数据 归一化处理。
#分离数据 80% 训练, 20%测试
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
#sns.pairplot(train_dataset[['dianshu', 'a', 'b']], diag_kind="kde")
#plt.show() #生存图片
#总体的数据统计:
train_stats = train_dataset.describe()
train_stats.pop("dianshu")
train_stats = train_stats.transpose()
#数据详情
test_result = test_dataset['dianshu']
train_labels = train_dataset.pop('dianshu')
test_labels = test_dataset.pop('dianshu')
#归一化处理
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
- 开始建模,我们损失函数需要用到 loss = ‘mae’这个,即平均绝对误差它表示预测值和观测值之间绝对误差的平均值。这个适用于我们的研究对象。
#开始建模训练
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mae', #均方误差(mae)Mean Absolute Error,即平均绝对误差:它表示预测值和观测值之间绝对误差的平均值。
optimizer=optimizer,#adam
metrics=['mae', 'mse'])
return model
model = build_model() #建立模型
model.summary() #方法来打印该模型的简单描述。
让我们来看看这个模型的描述信息,总共四层,包括8833个参数,足以训练5000个数据。
[En]
Let’s take a look at the description information of this model, a total of four layers, including 8833 parameters are enough for us to train 5000 data.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 448
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 64) 4160
_________________________________________________________________
dense_3 (Dense) (None, 1) 65
=================================================================
Total params: 8,833
Trainable params: 8,833
Non-trainable params: 0
_________________________________________________________________
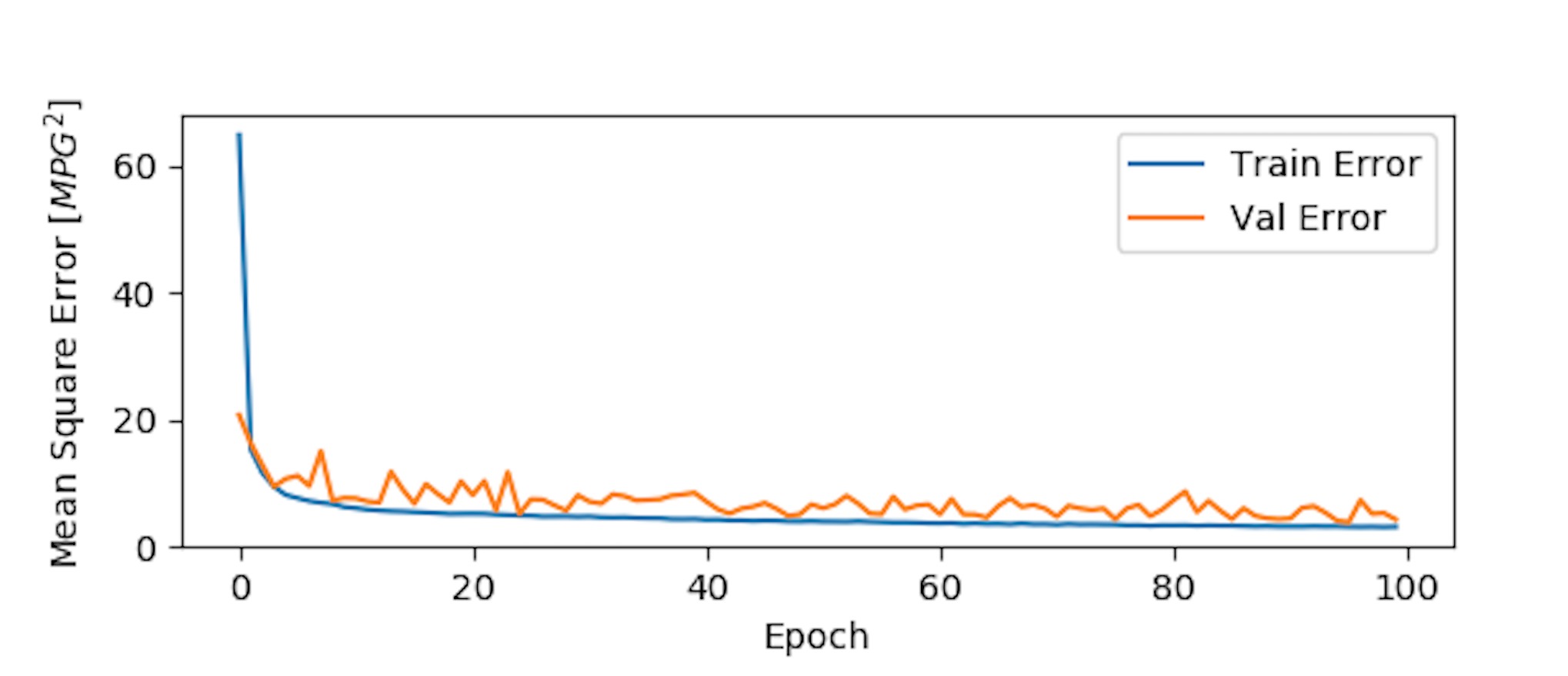
5.开始训练100次,并画出训练时mean走向统计图
通过为每个完成的时期打印一个点来显示训练进度
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 50 == 0: print('')
print('.', end='')
EPOCHS = 100
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure(1)
plt.subplot(211)
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error') #平均绝对值误差
plt.plot(hist['epoch'], hist['mae'],label='Train Error') #训练错误
plt.plot(hist['epoch'], hist['val_mae'],label = 'Val Error') #实际错误
plt.legend()
plt.figure(2)
plt.subplot(212)
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]') #均方误差
plt.plot(hist['epoch'], hist['mse'],label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'], label = 'Val Error')
plt.legend()
plt.show()
plt.figure(1)
plt.subplot(222)
plt.xlabel('Epoch')
plt.ylabel('loss and val_loss ') #错误率
plt.plot(hist['epoch'], hist['loss'],label='loss Error')
plt.plot(hist['epoch'], hist['val_loss'], label = 'val_loss Error')
plt.legend()
plt.show()
plot_history(history)
这个图描述了实际值方差和训练值方差走势图,训练到100次时mean 基本在10以下了。
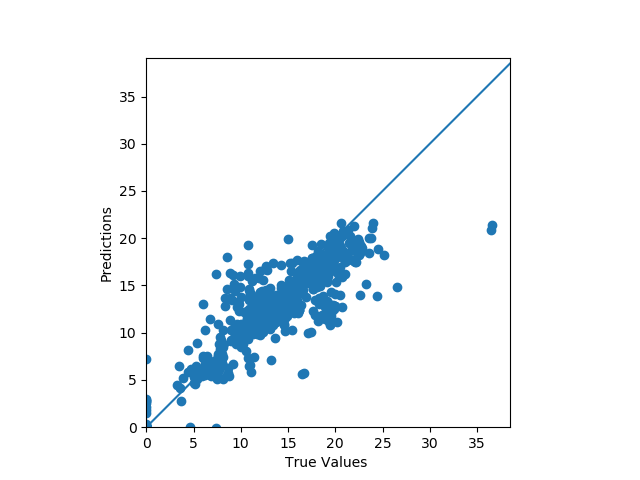
让我们使用训练好的模型来预测测试数据的实际值和预测值的拟合度。是线性回归吗?
[En]
Let’s use the trained model to predict the fitting degree of the actual and predicted values of the test data. is it linear regression?
#预测 的结果 打印
test_predictions = model.predict(normed_test_data).flatten()
#新图 查看拟合效果图
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values ')
plt.ylabel('Predictions')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
plt.plot([-100, 100], [-100, 100])
plt.show()
如图基本在一条线上。
将机器学习后的预测值和实际记录值打印出来,我们发现两个数据非常接近。
[En]
Printing out the predicted value and the actual recorded value after machine learning, we find that the two data are very close.
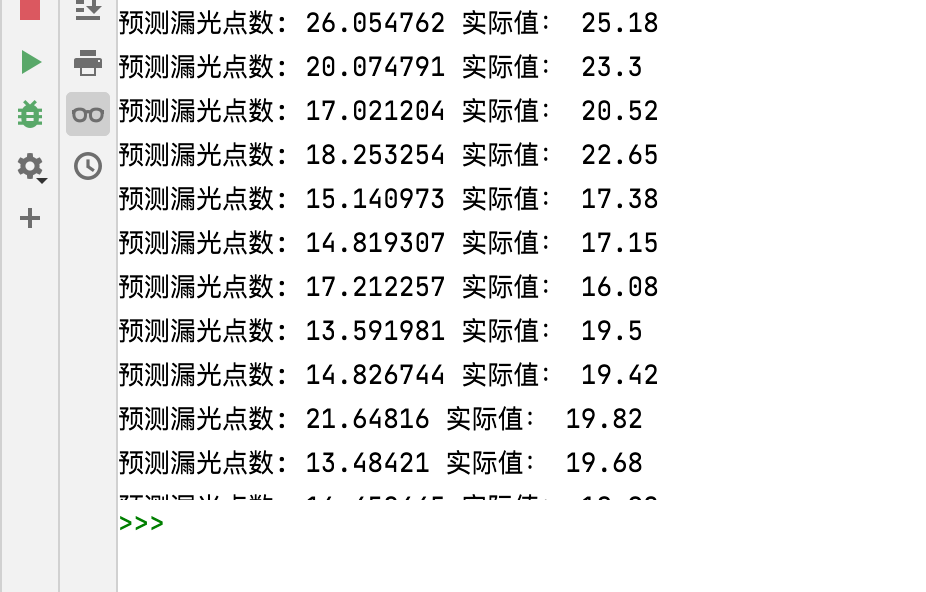
让我们看看机型预测的平均绝对差值为1.64,这是很低的。结果表明,张力、压力和温度与织物的透光点有很大的相关性。老师傅经验是对的,机器学习加强了验证。
[En]
Let’s take a look at the machine model predicts that the average absolute difference is 1.64, which is very low. It shows that the tension, pressure and temperature have a great correlation with the light transmission points of the cloth. The experience of the old master is correct, and machine learning strengthens the verification.
30/30 - 0s - loss: 1.6414 - mae: 1.6414 - mse: 6.5162
Testing set Mean Abs Error:  1.64 
Original: https://blog.csdn.net/u012997396/article/details/124131121
Author: 悟空大师
Title: Tensorflow深度学习-对布料工艺参数的预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/508903/
转载文章受原作者版权保护。转载请注明原作者出处!