

随着业务的不断发展,数据库中的数据量会越来越大,相应地,单表中的数据量也会越来越大,达到临界值时,单表的查询性能会下降。
[En]
With the continuous development of business, there will be more and more data in the database, accordingly, the amount of data in a single table will become larger and larger, up to a critical value, the query performance of a single table will decline.
这一临界值不能一概而论,它与硬件能力和具体业务有关。
[En]
This critical value can not be generalized, it is related to hardware capability and specific business.
虽然在很多 MySQL 运维规范里,都建议单表不超过 500w、1000w。
但实际上,我在生产环境,也见过大小超过 2T,记录数过亿的表,同时,业务不受影响。
当一张表太大时,企业通常会考虑两种拆分方案:水平拆分和垂直拆分。
[En]
When a single table is too large, the business usually considers two split schemes: horizontal split and vertical split.
水平拆分 VS 垂直拆分
水平拆分,拆分维度为一行,表中的记录一般按照一定的规则或算法拆分成多个表。
[En]
Split horizontally, the split dimension is a row, and the records in the table are generally split into multiple tables according to a certain rule or algorithm.
拆分表可以位于一个实例中,也可以位于多个不同实例中。如果是后者,则涉及分布式事务。
[En]
The split table can be in either one instance or multiple different instances. If it is the latter, distributed transactions will be involved.
纵向拆分,拆分的维度为列,一般拆分为多个业务模块。这种拆分更多的是对上层业务的拆分。
[En]
Split vertically, the dimension of the split is the column, which is generally split into multiple business modules. This kind of split is more of a split of the upper business.
就转型的复杂性而言,前者小于后者。
[En]
In terms of the complexity of the transformation, the former is less than the latter.
因此,当单张表格的数据量太大时,行业中更常用的是水平拆分。
[En]
Therefore, when the amount of data in a single table is too large, horizontal splitting is more commonly used in the industry.
常见的水平拆分方案有:子库表和分区表。
[En]
The common horizontal splitting schemes are: sub-database table and partition table.
虽然子库、子表是比较彻底的横向拆分方案,但一方面其转化需要一定的时间;另一方面对开发能力也有一定的要求。相对而言,分区表相对简单,不需要业务转换。
[En]
Although the sub-library and sub-table is a relatively thorough horizontal split scheme, on the one hand, its transformation takes a certain amount of time; on the other hand, it also has certain requirements for the ability of development. Relatively speaking, partitioned tables are relatively simple and do not require business transformation.
分区表
很多人可能会认为 MySQL 的优势在于 OLTP 应用,对于 OLAP 应用就不太适合,所以,也不太推荐分区表这种偏 OLAP 的特性。
但实际上,对于某些类型的业务,更适合使用分区表,尤其是那些冷热数据差异明显、冷热数据与时间相关的数据。
[En]
But in fact, for some types of business, it is more suitable to use partition tables, especially those that have obvious differences between hot and cold data, and the hot and cold data are time-related.
接下来,让我们看看分区表的优势:
[En]
Next, let’s look at the advantages of partitioned tables:
- 提升查询性能 对于分区表的查询操作,如果查询条件中包含分区键,则这个查询操作就只会被下推到符合条件的分区内进行,无关分区将自动过滤掉。 在数据量比较大的情况下,能提升查询速度。
- 对业务透明 将表从一个非分区表转换为分区表,业务端无需做任何改造。
- 管理方便 在对单个分区进行删除、迁移和维护时,不会影响到其它分区。 尤其是针对单个分区的删除(DROP)操作,避免了针对这个分区所有记录的 DELETE 操作。
遗憾的是,MySQL 分区表不支持并行查询。理论上,当一个查询涉及到多个分区时,分区与分区之间应进行并行查询,这样才能充分利用多核 CPU 资源。
但 MySQL 并不支持,包括早期的官方文档,也提到了这个问题,也将这个功能的实现放到了优先级列表中。
These features are not currently implemented in MySQL Partitioning, but are high on our list of priorities.
- Queries involving aggregate functions such as SUM() and COUNT() can easily be parallelized. A simple example of such a query might be SELECT salesperson_id, COUNT(orders) as order_total FROM sales GROUP BY salesperson_id;. By "parallelized," we mean that the query can be run simultaneously on each partition, and the final result obtained merely by summing the results obtained for all partitions.
- Achieving greater query throughput in virtue of spreading data seeks over multiple disks.
MySQL 8.0 中分区表的变化
在 MySQL 5.7 中,对于分区表,有个很重大的更新,即 InnoDB 存储引擎原生支持了分区,无需再通过 ha_partition 接口来实现。
所以,在 MySQL 5.7 中,如果要创建基于 MyISAM 存储引擎的分区表,会提示 warning 。
The partition engine, used by table 'sbtest.t_range', is deprecated and will be removed in a future release. Please use native partitioning instead.
而在 MySQL 8.0 中,则更为彻底,server 层移除了 ha_partition 接口代码。
如果要使用分区表,只能使用支持原生分区的存储引擎。在 MySQL 8.0 中,就只有 InnoDB。
这就意味着,在 MySQL 8.0 中,如果要创建 MyISAM 分区表,基本上就不可能了。
这也从另外一个角度说明了为什么生产上不建议使用 MyISAM 表。
mysql> CREATE TABLE t_range (<br>    ->     id INT,<br>    ->     name VARCHAR(10)<br>    -> ) ENGINE = MyISAM<br>    -> PARTITION BY RANGE (id) (<br>    ->     PARTITION p0 VALUES LESS THAN (5),<br>    ->     PARTITION p1 VALUES LESS THAN (10)<br>    -> );<br>ERROR 1178 (42000): The storage engine for the table doesn't support native partitioning
为什么分区键必须是主键的一部分?
在使用分区表时,您经常会遇到以下错误。
[En]
When using partition tables, you often encounter the following error.
mysql> CREATE TABLE opr (<br>    ->     opr_no INT,<br>    ->     opr_date DATETIME,<br>    ->     description VARCHAR(30),<br>    ->     PRIMARY KEY (opr_no)<br>    -> )<br>    -> PARTITION BY RANGE COLUMNS (opr_date) (<br>    ->     PARTITION p0 VALUES LESS THAN ('20210101'),<br>    ->     PARTITION p1 VALUES LESS THAN ('20210102'),<br>    ->     PARTITION p2 VALUES LESS THAN MAXVALUE<br>    -> );<br>ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function (prefixed columns are not considered).
也就是说,分区键必须是主键的一部分。
[En]
That is, the partitioning key must be part of the primary key.
上面的 opr 是一张操作流水表。其中,opr_no 是操作流水号,一般都会被设置为主键,opr_date 是操作时间。基于操作时间来进行分区,是一个常见的分区场景。
为了突破这个限制,可将 opr_date 作为主键的一部分。
mysql> CREATE TABLE opr (<br>    ->     opr_no INT,<br>    ->     opr_date DATETIME,<br>    ->     description VARCHAR(30),<br>    ->     PRIMARY KEY (opr_no, opr_date)<br>    -> )<br>    -> PARTITION BY RANGE COLUMNS (opr_date) (<br>    ->     PARTITION p0 VALUES LESS THAN ('20210101'),<br>    ->     PARTITION p1 VALUES LESS THAN ('20210102'),<br>    ->     PARTITION p2 VALUES LESS THAN MAXVALUE<br>    -> );<br>Query OK, 0 rows affected (0.04 sec)
但是这么创建,又会带来一个新的问题,即对于同一个 opr_no ,可插入到不同分区中。如下所示:
mysql> insert into opr values(1,'2020-12-31 00:00:01','abc');<br>Query OK, 1 row affected (0.00 sec)<br><br>mysql> insert into opr values(1,'2021-01-01 00:00:01','abc');<br>Query OK, 1 row affected (0.00 sec)<br><br>mysql> select * from opr partition (p0);<br>+--------+---------------------+-------------+<br>| opr_no | opr_date            | description |<br>+--------+---------------------+-------------+<br>|      1 | 2020-12-31 00:00:01 | abc         |<br>+--------+---------------------+-------------+<br>1 row in set (0.00 sec)<br><br>mysql> select * from opr partition (p1);<br>+--------+---------------------+-------------+<br>| opr_no | opr_date            | description |<br>+--------+---------------------+-------------+<br>|      1 | 2021-01-01 00:00:01 | abc         |<br>+--------+---------------------+-------------+<br>1 row in set (0.00 sec)
这实际上违背了业务对于 opr_no 的唯一性要求。
既然这样,有的童鞋会建议给 opr_no 添加个唯一索引,But,现实是残酷的。
mysql> create unique index uk_opr_no on opr (opr_no);<br>ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning function (prefixed columns are not considered)
即使添加唯一索引,分区键也必须包含在唯一索引中。
[En]
Even if you add a unique index, the partitioning key must be included in the unique index.
总而言之,对于 MySQL 分区表,无法从数据库层面保证非分区列在表级别的唯一性,只能确保其在分区内的唯一性。
这也是 MySQL 分区表所为人诟病的地方之一。
但实际上,这个锅让 MySQL 背并不合适,对于 Oracle 索引组织表( InnoDB 即是索引组织表),同样也有这个限制。
Oracle 官方文档( http://docs.oracle.com/cd/E11882_01/server.112/e40540/schemaob.htm#CNCPT1514),在谈到索引组织表(Index-Organized Table,简称 IOT)的特性时,就明确提到了 “分区键必须是主键的一部分”。
Note the following characteristics of partitioned IOTs:<br><br>   - Partition columns must be a subset of primary key columns.<br>   - Secondary indexes can be partitioned locally and globally.<br>   - OVERFLOW data segments are always equipartitioned with the table partitions.
下面,我们看看刚开始的建表 SQL ,在 Oracle 中的执行效果。
SQL> CREATE TABLE opr_oracle (<br>  2      opr_no NUMBER,<br>  3      opr_date DATE,<br>  4      description VARCHAR2(30),<br>  5      PRIMARY KEY (opr_no)<br>  6  )<br>  7  ORGANIZATION INDEX<br>  8  PARTITION BY RANGE (opr_date) (<br>  9      PARTITION p0 VALUES LESS THAN (TO_DATE('20170713', 'yyyymmdd')),<br> 10      PARTITION p1 VALUES LESS THAN (TO_DATE('20170714', 'yyyymmdd')),<br> 11      PARTITION p2 VALUES LESS THAN (MAXVALUE)<br> 12  );<br>PARTITION BY RANGE (opr_date) (<br>                    *<br>ERROR at line 8:<br>ORA-25199: partitioning key of a index-organized table must be a subset of the<br>primary key
同样报错。
注意,这里指定了 ORGANIZATION INDEX ,创建的是索引组织表。
看来,分区键必须是主键的一部分并不是 MySQL 的限制,而是索引组织表的限制。
在我看来,索引组织表之所以有这样的限制,是基于性能考虑。
[En]
In my opinion, the reason why there is such a restriction on index organization tables is based on performance considerations.
假设分区键和主键是两个不同的列,尽管在插入操作期间也指定了分区键,但需要扫描所有分区以确定插入的主键值是否违反唯一性约束。这样效率会比较低,这与分区表的初衷是背道而驰的。
[En]
Assuming that the partition key and the primary key are two different columns, although the partition key is also specified during the insert operation, all partitions need to be scanned to determine whether the inserted primary key value violates the uniqueness constraint. In this way, the efficiency will be relatively low, which goes against the original intention of the partition table.
对于堆表没有这样的限制。
[En]
There is no such restriction for heap tables.
在堆表中,主键和表中的数据是分开存储的,只使用主键索引来确定插入的主键值是否违反唯一性约束。
[En]
In the heap table, the primary key and the data in the table are stored separately, and only the primary key index is used to determine whether the inserted primary key value violates the uniqueness constraint.
但与 MySQL 不一样的是,Oracle 实现了全局索引,所以针对上面的,同一个 opr_no,允许插入到不同分区中的问题,可通过全局唯一索引来规避。
SQL> CREATE TABLE opr_oracle (<br>  2      opr_no NUMBER,<br>  3      opr_date DATE,<br>  4      description VARCHAR2(30),<br>  5      PRIMARY KEY (opr_no, opr_date)<br>  6  )<br>  7  ORGANIZATION INDEX<br>  8  PARTITION BY RANGE (opr_date) (<br>  9      PARTITION p0 VALUES LESS THAN (TO_DATE('20170713', 'yyyymmdd')),<br> 10      PARTITION p1 VALUES LESS THAN (TO_DATE('20170714', 'yyyymmdd')),<br> 11      PARTITION p2 VALUES LESS THAN (MAXVALUE)<br> 12  );<br><br>Table created.<br><br>SQL> create unique index uk_opr_no on opr_oracle (opr_no);<br><br>Index created.<br><br>SQL> insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh24:mi:ss'),'abc');<br><br>1 row created.<br><br>SQL> insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh24:mi:ss'),'abc');<br>insert into opr_oracle values(1,to_date('2020-12-31 00:00:01','yyyy-mm-dd hh24:mi:ss'),'abc')<br>*<br>ERROR at line 1:<br>ORA-00001: unique constraint (SCOTT.SYS_IOT_TOP_87350) violated
但 MySQL 却无能为力,之所以会这样,是因为 MySQL 分区表只实现了本地分区索引(Local Partitioned Index),而没有实现 Oracle 中的全局索引(Global Index)。
本地分区索引 VS 全局索引
本地分区索引和全局索引示意图如下:
[En]
The schematic diagram of the local partition index and the global index is as follows:
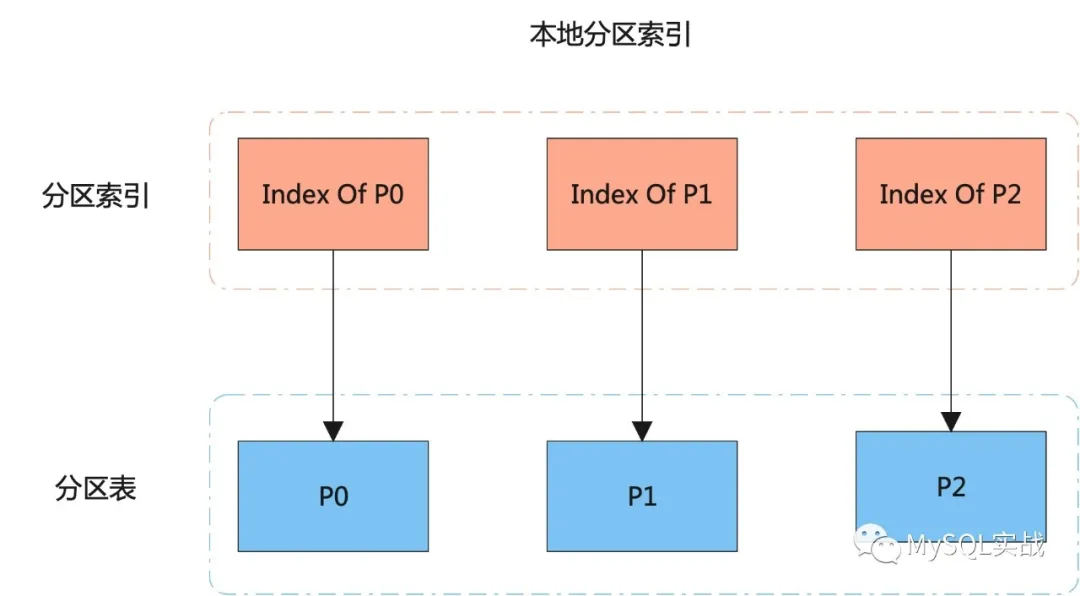

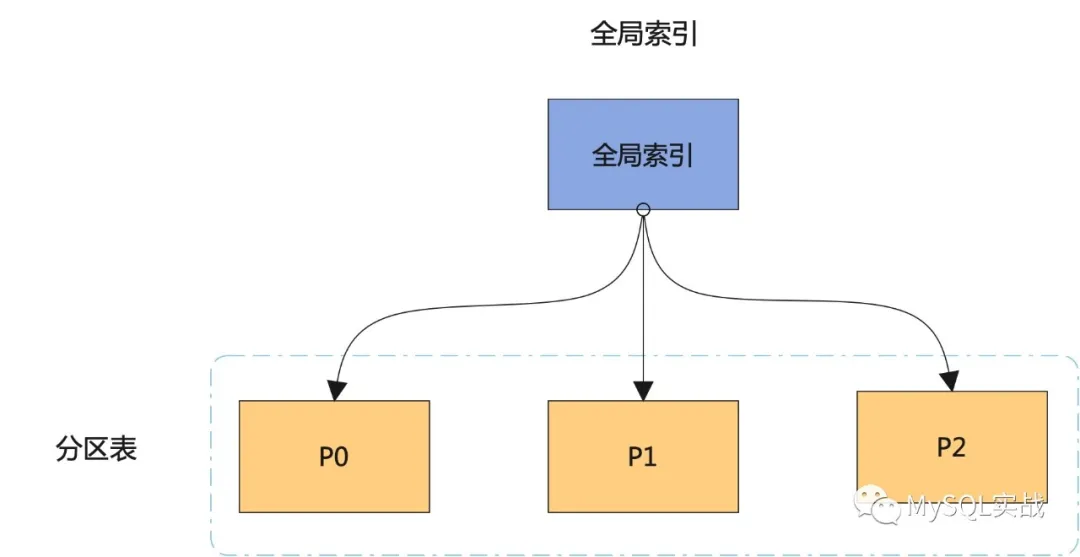
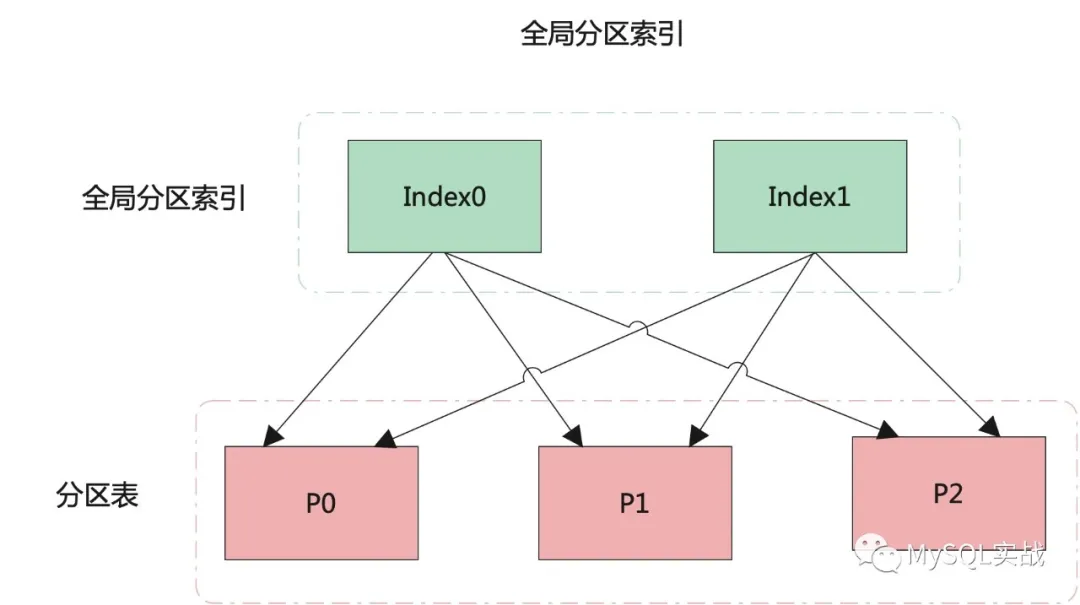
结合示意图,我们来看看这两个指数的区别:
[En]
Combined with the schematic, let’s look at the difference between the two indexes:
- 本地分区索引同时也是分区索引,分区索引和表分区之间是一一对应的。 而全局索引,既可以是分区的,也可以是不分区的。 如果是全局分区索引,一个分区索引可对应多个表分区,同样,一个表分区也可对应多个分区索引。
- 对本地分区索引的管理操作只会影响到单个分区,不会影响到其它分区。 而对全局分区索引的管理操作会造成整个索引的失效,当然,这一点可通过 UPDATE INDEXES 子句加以规避。
- 本地分区索引只能保证分区内的唯一性,无法保证表级别的唯一性,但全局分区可以。
- 在 Oracle 中,无论是索引组织表还是堆表,如果要创建本地唯一索引,同样也要求分区键必须是唯一键的一部分。
SQL> create unique index uk_opr_no_local on opr_oracle(opr_no) local;<br>create unique index uk_opr_no_local on opr_oracle(opr_no) local<br>                                       *<br>ERROR at line 1:<br>ORA-14039: partitioning columns must form a subset of key columns of a UNIQUE<br>index
总结
-
MySQL 分区表关于”分区键必须是唯一键(主键和唯一索引)的一部分”的限制,本质上是索引组织表的限制。
-
MySQL 分区表只实现了本地分区索引,没有实现全局索引,所以无法保证非分区列的全局唯一。
如果要保证非分区列的全局唯一性,只能依靠业务实现。
[En]
If you want to ensure the global uniqueness of non-partitioned columns, you can only rely on the business implementation.
- 不推荐使用 MyISAM 分区表。当然,任何场景都不推荐使用 MyISAM 表。
Original: https://www.cnblogs.com/ivictor/p/15713667.html
Author: iVictor
Title: MySQL 分区表,为什么分区键必须是主键的一部分?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/507942/
转载文章受原作者版权保护。转载请注明原作者出处!