

B+树索引的正确使用
索引并不是越多越好,索引创建越多,MySQL维护的代价越高,如果SQL未能完全使用到索引,创建索引的意义是不大的。
适用条件
表x,创建索引a,b,c。主键y。
全值匹配
select * from x where a = '' and b = '' and c = ''
当我们创建的索引abc,此时我们有a,b,c字段的索引是可以匹配到的,不论你a,b,c字段顺序如何,优化器会自动优化为索引的顺序。
匹配左边的列
select * from x where a = '' and d = ''
我们在此情况可以用到a的索引,但是如果第一个为b或c字段就不行。
匹配列前缀
select * from x where a like 'aaa%' and b like 'bbb%' # 不行'%aaa'或'%aaa%'
我们可以利用建立的索引找到a和b字段,因为a索引和b索引按照前缀排序的。但是反过来不行
匹配范围值
select * from x where a between 5 and 10;
因为是索引按照大小排序的,所以可以使用到索引。但是我们不用a直接用b是不能用到索引的。
精准匹配到某一列并范围匹配到另外一列
select * from x where a = 'aaa' and b between 5 and 10;
当我们是这种情况会找到a,然后根据b的排序找到b的范围值,是可以用到索引的。
用于排序
select * from x order by a,b,c; # 可以使用索引
select * from x order by b,a,c; # 不能使用索引
创建了a,b,c的索引可以根据a,b,c 排序,否则不能使用。
用于分组
select * from x group by a,b # 可以使用索引,顺序不对可以,会自动优化,但是得从左边开始
回表代价
在辅助索引的末尾,为了找到主键值,我们需要将主键值聚集到索引以查询表。
[En]
At the end of the secondary index, to find the primary key value, we need to take the primary key value to cluster the index to query the table.
我们创建索引时可以尽量避免回表的出现,尽量使用索引的字段,否则回表会导致MySQL的性能下降。当然mysql对于大量数据需要回表的情况会直接优化成顺序查找,省的大量回表带来的开销。
这也是为什么我们不要用select * 的原因,如果我们只需要索引字段就select对应字段即可。当所需字段在索引中存在,会进行覆盖索引作为结果返回,不需要回表查值。
select * from x where a = '' and b = '' and c = ''; # 如果数据库中有其他字段除了abc和主键y。
select a,b,c,y from x where a = '' and b = '' and c = ''; # 不需要回表直接覆盖索引。
索引创建注意事项
- 不需要对查询字段创建索引,只需要对搜索、排序、分组的字段进行即可。
- 列的基数尽量大,基础小,即列的重复值较少的列创建索引
- 索引列的类型能小尽量小,int能用tinyint就用。
- 索引字符串的前缀,如果只需要前缀创建索引,但是如果前缀重复多可能会出现问题。
- 让索引列在比较表达式中占独立的一部分。where a * 2 > 6 是用不了索引的,where a > 6 /2 可以用索引。
- 主键插入顺序,如果主键插入不按顺序,是需要页分裂等操作的,所以建议主键自增。
- 重复索引。索引重复只会更多的MySQL性能开销,且毫无意义。
MySQL的数据目录
数据存储目录,独立于安装目录
[En]
Data storage directory, separate from installation directory
mysql> show variables like 'datadir';
+---------------+------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------+
| datadir | D:\mysql\mysql-8.0.22-winx64\data\ |
+---------------+------------------------------------+
1 row in set, 1 warning (0.00 sec)
文件中的数据库显示为与存储目录下的数据库同名的文件夹,系统数据库将直接存储在数据存储目录中。
[En]
The database in the file is shown as a folder with the same name as the database under the storage directory, and the system database will be directly stored in the data storage directory.
表在文件系统中的表示
InnoDB存储表数据
描述表结构的文件:表名.frm
描述表数据和索引的文件:表名.ibd
系统表空间:即数据存放目录下的一个12M的文件,如果系统中数据库数据多,会更大。即系统数据库文件ibdata1文件。
独立表空间:在数据存放目录下数据库名的子目录里面,表名.frm 和 表名.ibd 。不过现在8.0.22已经只有表名.ibd了。
MyISAM存储表数据
描述表结构的文件:表名.frm
描述表数据的文件:表名.MYD
描述表索引的文件:表名.MYI
独立的表空间由这三个文件组成。
[En]
Independent tablespaces are made up of these three files.
其他文件
服务器进程文件、日志文件、SSL和RSA证书和密钥。
MySQL系统数据库
- mysql
存储用户帐户和权限、一些存储过程、事件定义信息、一些运行时日志、帮助信息、时区信息。
[En]
Store user accounts and permissions, some stored procedures, event definition information, some runtime logs, help information, time zone information.
- information_schema
维护服务器具有哪些表、视图、触发器、列和索引
[En]
Maintain which tables, views, triggers, columns, and indexes the server has
- performance_schema
维护服务器运行的状态信息,对MySQL的监控
- sys
通过视图的形式把前两个表结合起来,让程序员监控MySQL。
InnoDB 表空间
我们提到了行格式和页面这两个概念。
[En]
We mentioned the two concepts of row format and page.
行格式指定将每条数据组成组,并将多个组存储在一页中。
[En]
The row format specifies that each piece of data is formed into groups, and multiple groups are stored in one page.
如果我们需要管理页面,我们需要节和段的概念。
[En]
If we need to manage pages, we need the concept of sections and segments.
一个16KB的页来说,连续64个页就是一个区,也就是说一个区的大小为1MB。
连续256个区,就形成了一个组,一个组256MB。
区概念
对于每个表空间的第一组,该组第一个区域的前三页是不同的。
[En]
For the first group of each tablespace, the first three pages of the first area of this group are different.
- FSP_HDR类型的页面。用来登记该组256个区的属性,但是还会存储表的基本属性。
- IBUF_BITMAP类型的页。存储INSERT_BUFFER
- INODE类型的页。存储INODE entry。
其他组的第一个方面是前两页不同。
[En]
The first area of the other groups is that the first two pages are different.
- XDES类型的页面。用来登记该组256个区的属性。
- IBUF_BITMAP类型的页面
提问:为什么要使用区来管理?
因为页面没有固定的存储位置,所以页面是随意存储的,但如果数据量已经很大,我们会插入一个非常小的主键值,这将创建一个在后面有物理存储位置的页面。但是页面会被插入到最前面,当我们阅读页面信息时会发生什么?[En]
Because there is no fixed storage location for the page, the page is stored at will, but if the amount of data is already large, we insert a very small primary key value, which will create a page with a physical storage location at the back. But the page will be inserted very front, what happens when we read the page information?
就是我们需要IO读取到最后,然后在回到当前继续读,是十分耗时的,也就是随机IO,与顺序IO性能差得多。
段概念
第一次,我看到这个概念直接被混淆了。
[En]
For the first time, I saw that the concept was directly confused.
InnoDB 中叶子节点存放的区和非叶子节点存放的区是分开的,这就是段的概念。一个为存放叶子节点区的段,和存放索引页区的段。
所以,把这件事搞清楚。每个聚集索引有两个段,一个段表示存储叶页的区域,一个段表示存储非叶页的区域。
[En]
So get this straight. Each clustered index has two segments, one segment represents the area where leaf pages are stored, and one segment represents the area where non-leaf pages are stored.
那按照这样的话,一个表开局就要2M的存储空间,对于几条数据的是不是太大了。
所以有了碎片页的概念,一个区不属于一个段,而是直接属于表空间。它可以存储每一段的页面,防止区域的浪费。当一个片段存储了32个片段时,其余的片段将直接创建一个附加的空闲区域来存储页面,而不是使用片段页面。
[En]
So there is the concept of fragmented pages, an extent does not belong to a segment, but directly belongs to the tablespace. It can store the pages of each segment and prevent the waste of the area. When a segment has stored 32 fragments, the rest will directly create an attached free area to store the page instead of using the fragment page.
所以区有如下状态:
- 空闲区(FREE)、
- 有剩余空间的碎片区(FREE_FRAG)、
- 满的碎片区(FULL_FRAG)、
- 附属于某个段的空闲区(FSEG)。
对于每个区来说都有一个XDES Entry的结构。
- Segment ID (8字节):如果状态为FSEG的话就是段的ID。否则没有意义
- List Node(12字节):用来存储前一个和后一个区的地址
- State(4字节):就是上述四种状态。
- Page State Bitmap(16字节): 描述当前64个页,每个页2比特,一比特表示是否空闲,还有一个比特没什么用。
寻找最近的有空间的或空闲区
当段中存储的区小于32时,是会利用隶属于表空间的碎片区进行存储的。
流程:
- 新插入的页面寻找空闲存储区域,如何快速找到表空间的空闲分片区域?
[En]
the newly inserted page looks for a free area for storage, how to quickly find the free fragment area of the tablespace?*
- 表空间会维护一个FREE状态的链表和FREE_FREG状态的链表以及FULL_FRAG状态的链表。
- 如果空闲的碎片区还存在就会找出链表中取出一个插入,如果满了就改变其状态将其放入FULL_FRAG的链表中。
- 如果没有空闲的碎片区,就会从FREE中取出一个来将其转变为空闲碎片区状态放入FREE_FREG状态的链表中。
当段中的碎片区存储超过32时,就会申请隶属于该段空间的区进行存储。
流程和之前差不多,但是段空间也会维护三个链表FREE和FULL以及NOT_FULL虽然有点区别就是非碎片区的,不过是申请的专属的区,所以流程是差不多的。
段的结构
我们前面没有提到,段不是实际的存储单元,它只是对区域的引用。
[En]
We didn’t mention earlier that the segment is not an actual storage unit, it’s just a reference to the zone.
所以需要有一个结构来定义段,就是INODE Entry 结构
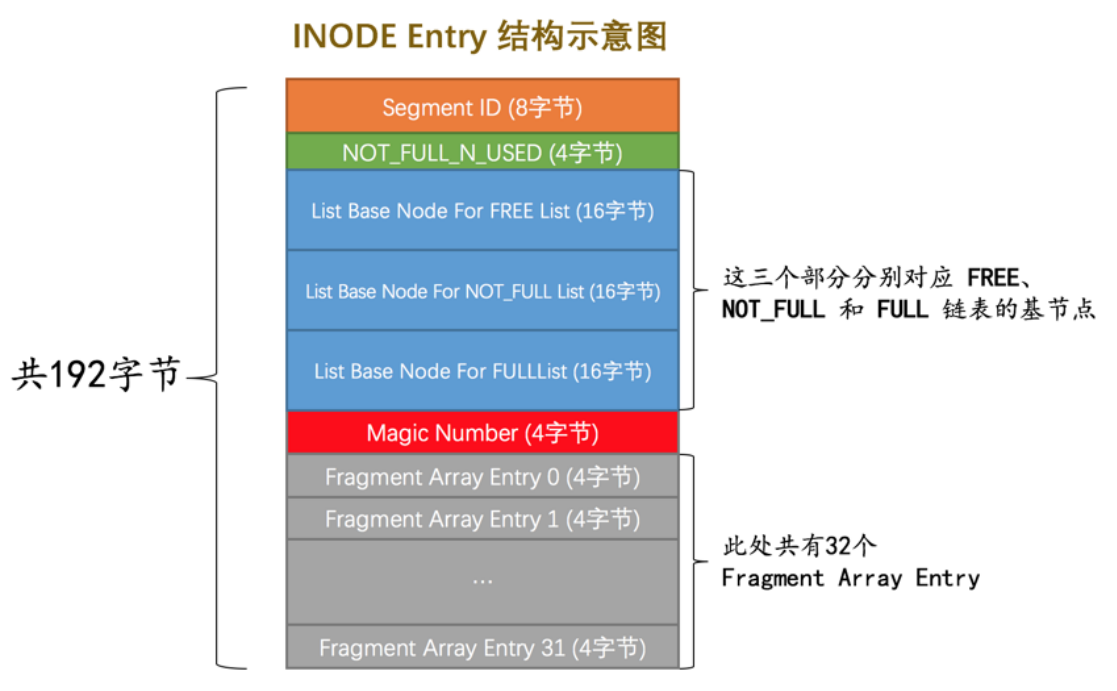

- Segment ID :就是段的唯一ID
- NOT_FULL_N_USED:表示已经使用的页的个数,然后下次直接分配直接找到。
- 三个链表:非常熟悉,这意味着属于该段的区域的自由、非完整和完整的链表。只有在分配了32个片段时才会分配它。
[En]
three linked lists: very familiar, which means free, not full, and full linked lists of areas belonging to the paragraph. It will only be allocated when 32 fragments are allocated.*
- Magic Number魔数
- 碎片区的引用刚好32个。
因此,在该段中,对片段区域的引用在底部,而对独占区域的引用在链接列表中链接。
[En]
So in the paragraph, the reference to the fragment area is at the bottom, while the reference to the exclusive area is linked in the linked list.
所以你废了吗?
接下来我们可以讲解一下INODE Entry放在哪里呢,就需要介绍之前提到过的每个表空间的第一个区中固定的三个页面,只介绍俩页面
FSP_HDR页面和XDES页面
FSP_HDR类型的页面,就是比其他的区的第一个XDES页多了File Space Header就是记录当前表空间的一些属性,其他都是一样的。

- File Header就是头中的一些信息还有和File Trailer的校验
- File Space Header

Space ID 表示表空间的ID
Size 表空间页的大小
Free Limit 就是当前已经使用的页到多少了,下次直接从这个地址开始分配页面
FRAG_N_USED 表示碎片区已经使用的页
接下来的for FREE List 和for FREE_FRAG List和for FULL_FRAG List 表示表空间维护的三个有关碎片区的链表
Next Unuser Segment ID 表示下一个未分配的段ID,方便分配一个新的段ID
for SEG_INODES_FULL 和 for SEG_INODES_FREE 表示已经放满了INODE Entry 的INODE节点和空闲的INODE节点。(记住是存放INODE Entry也就是段结构的INODE节点)
INODE页面
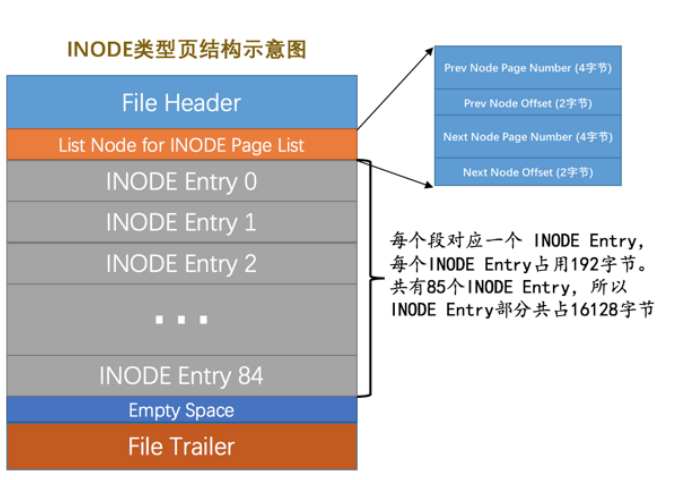
INODE类型结构就是为了存储INODE Entry节点的,最多存储85个段。
结构中List Node for INODE Page List 就是指向上一个INODE节点和下一个INODE节点。
我们就是在这个INODE中存储段的INODE Entry节点的。
如果该页存储满了,就会在上面提到的List Base Node for SEG_INODES_FREE 就是空闲INODE页的基节点的链表引用,取出一个,空的话从碎片区中申请一个页来存放。
因此,我们知道数据段是如何存储的以及它们存储在哪里。
[En]
So we know how segments are stored and where they are stored.
同时,我们已经知道一个索引将有两个部分,一个叶部分和一个非叶部分。
[En]
At the same time, we already know that an index will have two segments, one leaf segment and one non-leaf segment.
我们如何找到索引的页面?
[En]
How do we find the page of the index?
在此结构之前,我们提到了数据页面上的两个引用,但没有指定
[En]
Before this structure, we mentioned two references on the data page, but did not specify
在页结构的Page Header中有如下两个结构

这两个结构就是Segment Header这个结构

Space ID of the INODE Entry 就是INODE对应的表空间
Page Number of the INODE Entry 就是INODE对应的表空间下对应的页号
Byte Offset of the INODE Entry 就是INODE对应的页中对应段的偏移量。
我们就可以通过在索引的ROOT节点存储一个这样的结构,可以找到对应的段。包括叶子段和非叶子段,就是两个这个结构,然后去表空间中找到这两个段的地址即可。
系统表空间
介绍了数据字典在系统表空间中存储固定数据的概念,以及数据库中属于该表的表、表名、列、列等基本信息。
[En]
This paper introduces a concept that the data dictionary stores some fixed data in the system table space, as well as the basic information such as the table, the table name, the column, the column belonging to that table and so on in the database.
还有一些已经用了的最大的表ID,最大的索引ID,最大的表空间ID,就是方便下次创建表啊索引啊这一些更方便一点,直接将值进行增加等操作进行赋值即可。
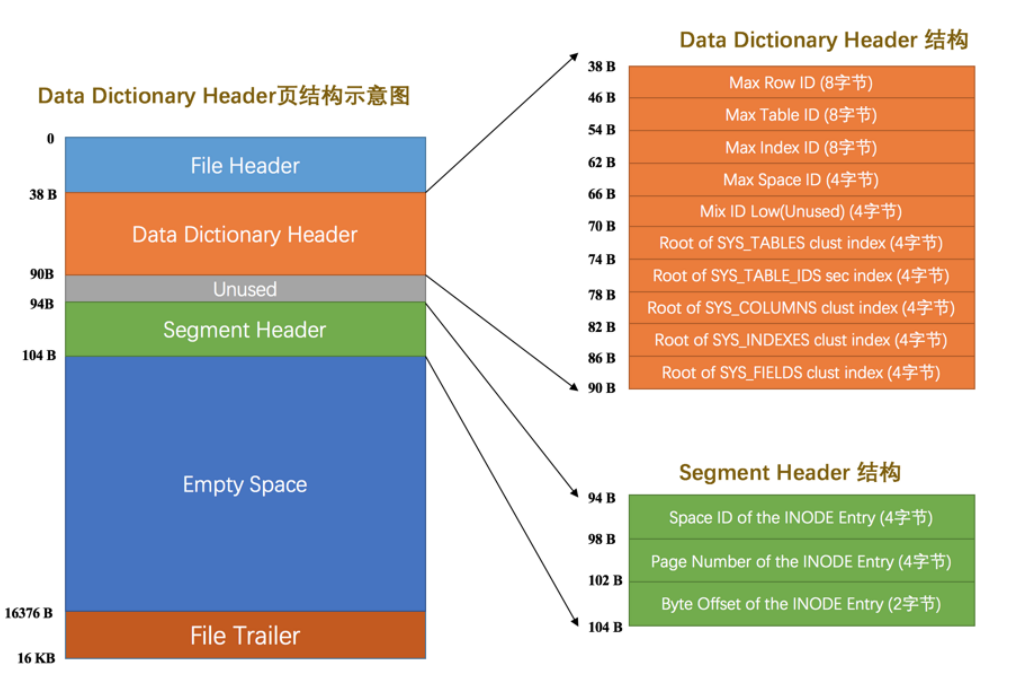
图片出自:《MySQL是怎样运行的:从根儿上理解MySQL》
对其进行总结,以及再一次阐述思路。[En]
Make a summary of it, as well as the train of thought again.
Original: https://www.cnblogs.com/duizhangz/p/16295520.html
Author: 大队长11
Title: MySQL索引使用方式以及段、区、页概念
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/505361/
转载文章受原作者版权保护。转载请注明原作者出处!