

先大体看一下MySQL的SQL layer层的一个架构流程:
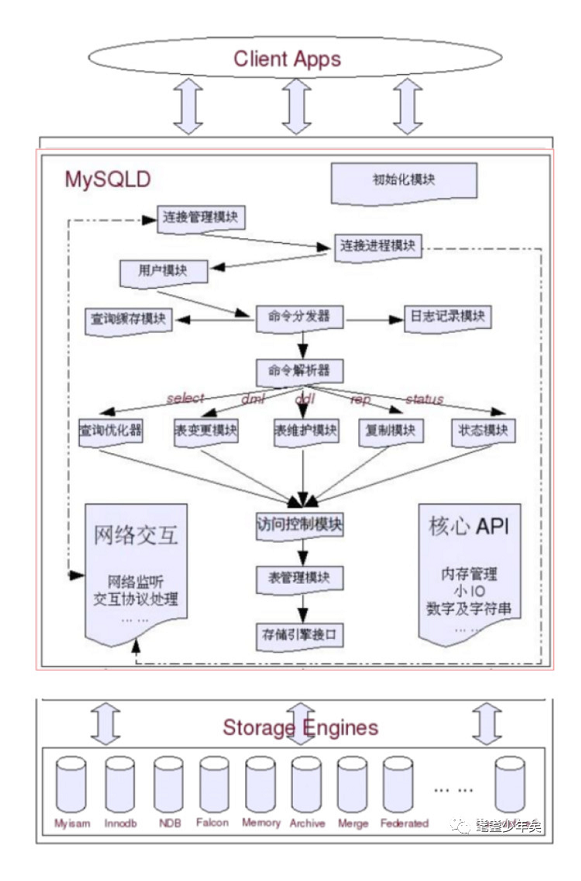

简要介绍一些关键模块:
[En]
Give a brief description of some key modules:
-
初始模块:初始一些参数,比如初始myinit配置文件(在安装的根目录下)里的一些参数。
-
连接管理模块:启动监听,监听连接请求
-
连接进程模块:可以理解为线程池
-
用户模块:检验用户,令牌和权限
-
命令分发器:处理不同类型的请求
-
查询缓存模块:做缓存处理,做查询的cache,可以理解为一个Map,查询语句为key,结果值为value
-
日志记录模块
-
命令解析器(parser):对于不同类型的sql语句进行处理分发,select:查询优化器,dml:表变更模块,ddl:表维护模块,rep:复制模块(主从复制),status:状态模块。
-
访问控制:
-
表管理模块:
-
存储引擎接口:和Storage Engines打交道
直接来到Storage Engines,这讲的最多的就是引擎了,如:
Myisam、Innodb、Faicon、Memory、Archive等等引擎
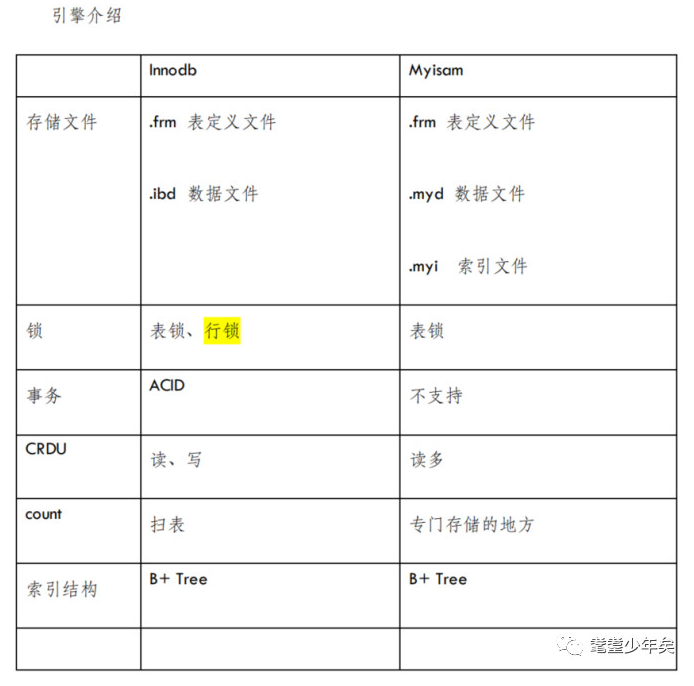
而我们常用的是Innodb和Myisam这两种,这两种索引最直接的区别,可以从采用对应引擎而生成的数据表文件,进行对比。比如:采用Innodb引擎生成表A,采用Myisam索引生成表B。
现在可以从Mysql安装目录/data/数据库名 ,这个目录下看到有5个文件:
A.frm : 表定义文件
A.ibd :数据和索引都存储在这个文件
B.frm :表定义文件
B.myd :数据文件
B.myi :索引文件
显然,两者从文件上体验出来的区别就是,Myisam是把数据和索引分开存储在两个不同的文件里。(那其本质里的区别是什么?急啥)
让我们来看看,衡量一个指数的标准是什么?
[En]
Let’s see, what are the criteria for measuring an index?
就是,IO渐进复杂度,翻译成人话就是:当数据越来越多的时候,索引是否依然高效,即查询依然那么快。
索引的效率在一定程度上取决于它使用的索引结构。
[En]
The efficiency of an index depends to some extent on the index structure it uses.
Hash索引:
对索引字段做Hash计算,落到不同槽里面,有个明显的缺点是,无法做范围查询,例如 select * from data where id >1
Fulltext索引:
全文搜索索引,比如字段的值是:abcdefghijk,它就会再生成一列abcde* ,用于前缀的模糊全文搜索。
R-Tree索引:
引用的场景主要是 空间索引,比如说,美团上订电影票,就可以选择3km范围内的影院,结果就搜出来了。
B-Tree索引:
这个索引就是我要重点讲的索引,因为Innodb和Myisam采用的是B+ Tree 索引,而B+ Tree是从B-Tree基础上演变而来。
那B-Tree是怎么样的呢?如图:
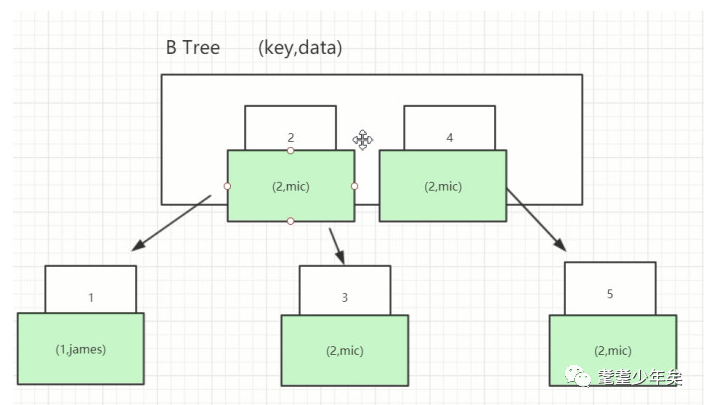
每个节点上有一个索引(上方的数字,id的值),和索引对应的数据(下方蓝色:id, name)
而B+Tree:
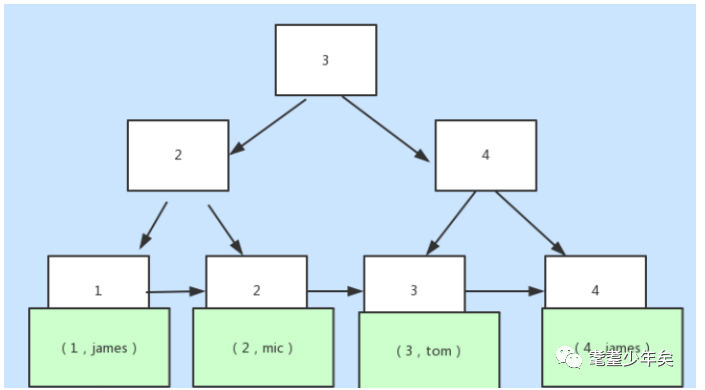
上方白色的数字都为索引的key,而data全放在下面。(居于此结构,如果想知道它是怎么根据key从上到下找到对应的data的,我提供一个非常好玩的web工具,去玩一下琢磨一下。https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)
虽然Innodb和Myisam都是采用B+Tree索引,但是它们是有区别的,如图:
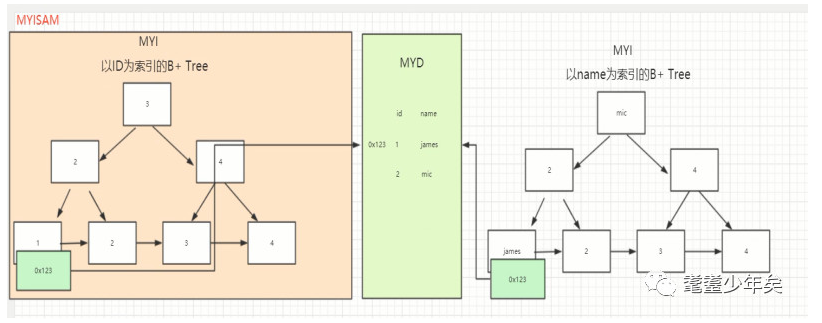

前面已经说了,Myisam引擎方式的,会把索引和数据分开存储在两个文件中,一个文件负责数据的插入、更新等,另一个负责索引的维护。如图,索引中白色的key为索引的值,下面浅绿色为data:对应数据的地址。如果多个索引就,就多个这种模式,如图,以name为索引,也是一样。
而Innodb:如图:
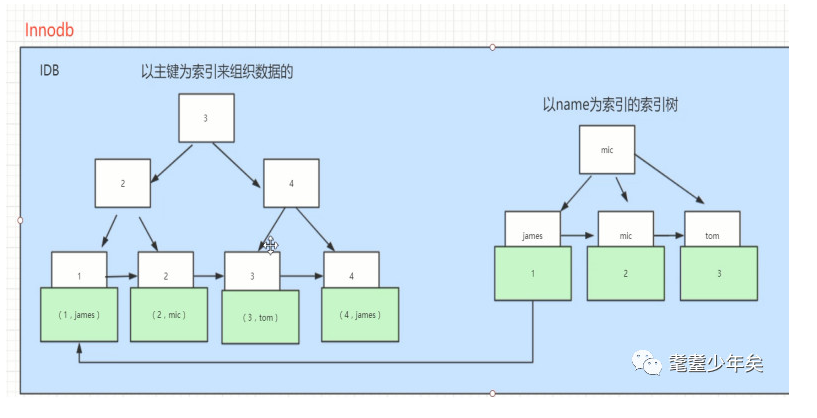
上面也提到,Innodb是把数据和索引都放在同一个文件里的,那索引和数据共存的形式是:如图,白色中的为key,即使索引,当从上到下找到对应的key之后,key下面存放的就是整条对应的数据了,而不是想Myisam那样存放的是数据对应的地址了。
那么问题来了,Innodb多个索引的话,是一种什么样的存在呢,还是如上图右方,增加字段name为索引:它就会建立一个副索引树,同样的结构,白色key索引存放的是name字段对应的值,而蓝色方的data存放的是主索引树的key。
举个例子,当id和name都作为索引的时候,执行select * from table where name = ‘james’ ,
第一步会先在副索引找到key为james的data为1,1是主索引的key。
第二步再到主索引找到key为对1的数据。(select * from table where id= 1)
多提一句,像这种索引的方式叫”聚集索引”,理解为key和data都绑定在一起了。
而Myisam的那种索引的方式叫做”非聚集索引”。
对于B+Tree这种索引,讨论一下uuid和自增id。
Uuid是32位的,毋庸置疑,相对于自增id,uuid的存储空间是较大的。而且uuid为索引时,其要进行较复杂的运算,最终确定索引的key要插入到哪个位置。
而自增id,它符合每次加1的规则,而且规矩已经确定了,它不要做过多的运算,直接从左到右进行横向的扩展(插入),这样性能就有了差别,如图(B+Tree树的高度是固定的,为4层):
即使是这样,uuid依然在一些项目依然有它市场:
自增id虽然有多个优点,但实际大型项目中却很少采用自增长id的,这是为什么呢?因为uuid几乎保证了不同数据库的不同表的id唯一,可以进行数据切分合并,而自增长id只能保证一个数据库中的一张表的id唯一,进行数据库合并的话并然会因主键冲突而失败,这是一个硬伤。
而且有博主说:分布式架构,意味着需要多个实例中保持一个表的主键的唯一性。这个时候普通的单表自增ID主键就不太合适,因为多个mysql实例上会遇到主键全局唯一性问题
让我们来谈谈组合指数的几个小问题。
[En]
Let’s talk about some minor problems of combinatorial index.
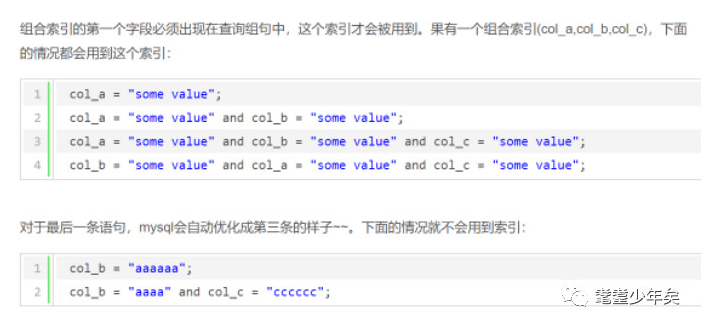
组合指数是有序的,称为最左原理。你什么意思。例如:
[En]
The combinatorial index is ordered, called the leftmost principle. What do you mean. For example:
name、age、weight 这3个字段组成组合索引,name排在第1位,那么查询语句where 后面必须要有name=”value”这个条件,否则此索引是不起作用的,这叫最左原则。
再引用网上的一个例子:
索引的好处就是:
-
提高检索效率
-
降低排序成本,索引对应的字段是会有一个自动排序功能的,默认是升序asc。
Every coin has two sides,它缺点是
- 更新索引的IO量。
也就是说,当插入一条数据时,除了插入数据本身之外,还需要插入该数据对应的索引信息的节点,如果对应的表是多个索引,则插入多个数据对应的索引信息节点。并且这些文件作为文件类型存储在硬盘上。
[En]
That is to say, when inserting a piece of data, in addition to inserting the data itself, it is also necessary to insert the node of the index information corresponding to the data, and if the corresponding table is of multiple indexes, the index information node corresponding to multiple data is inserted. And these are stored on the hard disk as file types.
- 调整索引所致的计算量,
这个又是怎么理解呢,举个例子,像B-tree索引,在插入索引之前,都要进行计算,该索引要申请多少的空间,插入到哪个位置。
- 占用存储空间。
指数可以是好的也可以是坏的。你什么时候需要,什么时候不需要?
[En]
The index can be bad or good. When do you need it and when you don’t?
适合:
- 较频繁的作为查询条件的字段应该创建索引
不适合:
-
字段值的唯一性太差不适合单独做索引
-
更新非常频繁的字段不是
-
不会出现在where句中的字段不适合。
Original: https://www.cnblogs.com/incognitor/p/16403979.html
Author: 無名之徒
Title: Mysql 的Innodb引擎和Myisam数据结构和区别
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/505276/
转载文章受原作者版权保护。转载请注明原作者出处!