

- MySQL 5.6并行复制架构
- MySQL 5.7并行复制原理
- Master
- slave
- MySQL是如何做到将这些事务分组的?
- 从库多线程复制分发原理
- MySQL 5.7并行复制测试
-
在MySQL 5.7版本,官方称为enhanced multi-threaded slave(简称MTS),复制延迟问题已经得到了极大的改进,可以说在MySQL 5.7版本后,复制延迟问题永不存在。
- 5.7的MTS本身就是:master基于组提交(group commit)来实现的并发事务分组,再由slave通过SQL thread将一个组提交内的事务分发到各worker线程,实现并行应用。
MySQL 5.7并行复制原理
MySQL 5.6基于库的并行复制出来后,基本无人问津,在沉寂了一段时间之后,MySQL 5.7出来了,它的并行复制以一种全新的姿态出现在了DBA面前。
MySQL 5.7才可称为真正的并行复制,这其中最为主要的原因就是slave服务器的回放与master是一致的,即master服务器上是怎么并行执行的,那么slave上就怎样进行并行回放。不再有库的并行复制限制,对于二进制日志格式也无特殊的要求(基于库的并行复制也没有要求)。
从MySQL官方来看,其并行复制的原本计划是支持表级的并行复制和行级的并行复制,行级的并行复制通过解析ROW格式的二进制日志的方式来完成,WL#4648。但是最终出现给小伙伴的确是在开发计划中称为:MTS(Prepared transactions slave parallel applier),可见:WL#6314。该并行复制的思想最早是由MariaDB的Kristain提出,并已在MariaDB 10中出现,相信很多选择MariaDB的小伙伴最为看重的功能之一就是并行复制。MTS实现了事务的并行,从某种程度来说也实现了行的并行(事务对行处理)。
下面来看看MySQL 5.7中的并行复制究竟是如何实现的?
order commit (group commit) -> logical clock ->> MTS
Master
组提交(group commit)
组提交(group commit):通过对事务进行分组,优化减少了生成二进制日志所需的操作数。当事务同时提交时,它们将在单个操作中写入到二进制日志中。如果事务能同时提交成功,那么它们就不会共享任何锁,这意味着它们没有冲突,因此可以在Slave上并行执行。所以通过在主机上的二进制日志中添加组提交信息,这些Slave可以并行地安全地运行事务。
首先,MySQL 5.7的并行复制基于一个前提,即所有已经处于prepare阶段的事务,都是可以并行提交的。这些当然也可以在从库中并行提交,因为处理这个阶段的事务,都是没有冲突的,该获取的资源都已经获取了。反过来说,如果有冲突,则后来的会等已经获取资源的事务完成之后才能继续,故而不会进入prepare阶段。这是一种新的并行复制思路,完全摆脱了原来一直致力于为了防止冲突而做的分发算法,等待策略等复杂的而又效率底下的工作。
MySQL 5.7并行复制的思想一言以蔽之:一个组提交(group commit)的事务都是可以并行回放,因为这些事务都已进入到事务的prepare阶段,则说明事务之间没有任何冲突(否则就不可能提交)。
根据上面的描述,这里的重点是–
[En]
According to the above description, the point here is–
- 如何来定义哪些事务是处于prepare阶段的?
- 在生成的Binlog内容中该如何告诉Slave哪些事务是可以并行复制的?
——为了兼容MySQL 5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有:
- DATABASE(默认值,基于库的并行复制方式)
- LOGICAL_CLOCK(基于组提交的并行复制方式)
支持并行复制的GTID
那么如何知道事务是否在同一组中?原版的MySQL并没有提供这样的信息。
在MySQL 5.7版本中,其设计方式是将组提交的信息存放在GTID中。
那么如果参数gtid_mode设置为OFF,用户没有开启GTID功能呢?
MySQL 5.7又引入了称之为Anonymous_Gtid(ANONYMOUS_GTID_LOG_EVENT)的二进制日志event类型,
如:
mysql> SHOW BINLOG EVENTS in 'mysql-bin.000006';
+------------------+-----+----------------+-----------+-------------+-----------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+----------------+-----------+-------------+-----------------------------------------------+
| mysql-bin.000006 | 4 | Format_desc | 88 | 123 | Server ver: 5.7.7-rc-debug-log, Binlog ver: 4|
| mysql-bin.000006 | 123 | Previous_gtids | 88 | 194 | |
| mysql-bin.000006 | 194 | Anonymous_Gtid | 88 | 259 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| mysql-bin.000006 | 259 | Query | 88 | 330 | BEGIN |
| mysql-bin.000006 | 330 | Table_map | 88 | 373 | table_id: 108 (aaa.t) |
| mysql-bin.000006 | 373 | Write_rows | 88 | 413 | table_id: 108 flags: STMT_END_F |
......
这意味着在MySQL 5.7版本中即使不开启GTID,每个事务开始前也是会存在一个Anonymous_Gtid,而这个Anonymous_Gtid事件中就存在着组提交的信息。反之,如果开启了GTID后,就不会存在这个Anonymous_Gtid了,从而组提交信息就记录在非匿名GTID事件中。
- PREVIOUS_GTIDS_LOG_EVENT 用于表示上一个binlog最后一个gitd的位置,每个binlog只有一个,当没有开启GTID时此事件为空。
- GTID_LOG_EVENT
- 当开启GTID时,每一个操作语句(DML/DDL)执行前就会添加一个GTID事件,记录当前全局事务ID。
- 同时在MySQL 5.7版本中,组提交信息也存放在GTID事件中,有两个关键字段last_committed,sequence_number就是用来标识组提交信息的。
- 在InnoDB中有一个全局计数器(global counter),在每一次存储引擎提交之前,计数器值就会增加。在事务进入prepare阶段之前,全局计数器的当前值会被储存在事务中,这个值称为此事务的commit-parent(也就是last_committed)。
slave
LOGICAL_CLOCK(由order commit实现),实现的group commit目的
然而,通过上述的SHOW BINLOG EVENTS,我们并没有发现有关组提交的任何信息。但是通过mysqlbinlog工具,就能发现组提交的内部信息——
$ mysqlbinlog mysql-bin.0000006 | grep last_committed
#150520 14:23:11 server id 88 end_log_pos 259 CRC32 0x4ead9ad6 GTID last_committed=0 sequence_number=1
#150520 14:23:11 server id 88 end_log_pos 1483 CRC32 0xdf94bc85 GTID last_committed=0 sequence_number=2
#150520 14:23:11 server id 88 end_log_pos 2708 CRC32 0x0914697b GTID last_committed=0 sequence_number=3
#150520 14:23:11 server id 88 end_log_pos 3934 CRC32 0xd9cb4a43 GTID last_committed=0 sequence_number=4
#150520 14:23:11 server id 88 end_log_pos 5159 CRC32 0x06a6f531 GTID last_committed=0 sequence_number=5
#150520 14:23:11 server id 88 end_log_pos 6386 CRC32 0xd6cae930 GTID last_committed=0 sequence_number=6
#150520 14:23:11 server id 88 end_log_pos 7610 CRC32 0xa1ea531c GTID last_committed=6 sequence_number=7
#150520 14:23:11 server id 88 end_log_pos 8834 CRC32 0x96864e6b GTID last_committed=6 sequence_number=8
#150520 14:23:11 server id 88 end_log_pos 10057 CRC32 0x2de1ae55 GTID last_committed=6 sequence_number=9
#150520 14:23:11 server id 88 end_log_pos 11280 CRC32 0x5eb13091 GTID last_committed=6 sequence_number=10
#150520 14:23:11 server id 88 end_log_pos 12504 CRC32 0x16721011 GTID last_committed=6 sequence_number=11
#150520 14:23:11 server id 88 end_log_pos 13727 CRC32 0xe2210ab6 GTID last_committed=6 sequence_number=12
#150520 14:23:11 server id 88 end_log_pos 14952 CRC32 0xf41181d3 GTID last_committed=12 sequence_number=13
...
上述的last_committed和sequence_number代表的就是所谓的LOGICAL_CLOCK。
可以发现MySQL 5.7二进制日志较之原来的二进制日志内容多了last_committed和sequence_number。
- last_committed表示事务提交时上次事务提交的编号,事务在进入prepare阶段时会将上次事务的sequence_number记录为自己的last_committed,如果事务具有相同的last_committed,表示这些事务都在一组内,可以进行并行的回放。
- 例如上述last_committed为0的事务有6个,表示组提交时提交了6个事务,而这6个事务在slave是可以进行并行回放的。
- 而sequence_number是顺序增长的,每个事务对应一个序列号,当事务完成committed时便会得到这个sequence_number。
另外,还有一个细节,下一个事务组的last_committed和上一个事务的sequence_number是相等的。这也很容易理解,因为事物是顺序提交的,这么理解起来并不奇怪。 本组的 sequence_number 最小值肯定大于 last_committed 。(这一块描述不严谨,在5.7后续版本中,官方优化了slave进行并行apply的规则,但是这里为了便于理解,不做修改,理解这个思路后阅读后面基于锁的并行规则也很容易。)
这两个值的有效作用域都在文件内,只要换一个binlog文件(flush binary logs),这两个值就都会从0开始计数。
MySQL是如何做到将这些事务分组的?
还有一个重要的技术问题:MySQL是如何做到将这些事务分组的?
要搞清楚这个问题,首先需要了解一下MySQL事务提交方式。
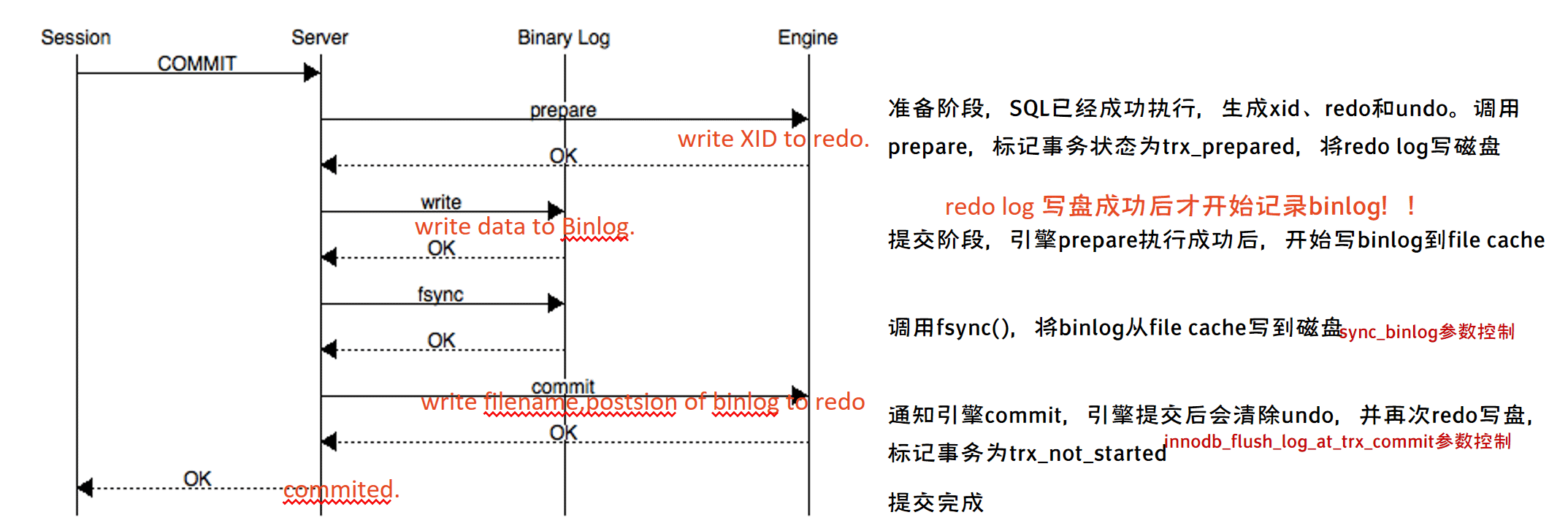

事务的提交分为两个主要步骤:
[En]
The commit of a transaction is divided into two main steps:
- 准备阶段(Storage Engine(InnoDB)Transaction Prepare Phase) 此时SQL已经成功执行,并生成xid信息及redo和undo的内存日志。然后调用prepare方法完成第一阶段,papare方法实际上什么也没做,将事务状态设为TRX_PREPARED,并将redo log刷磁盘。
- 提交阶段(Storage Engine(InnoDB)Commit Phase)
- 记录Binlog日志。 如果事务涉及的所有存储引擎的prepare都执行成功,则调用TC_LOG_BINLOG::log_xid方法将SQL语句写到binlog。 (write()将binary log内存日志数据写入文件系统缓存,fsync()将binary log文件系统缓存日志数据永久写入磁盘)。 此时,事务已经铁定要提交了。否则,调用ha_rollback_trans方法回滚事务,而SQL语句实际上也不会写到binlog。
- 告诉引擎做commit。 最后,调用引擎的commit完成事务的提交。会清除undo信息,刷redo日志,将事务设为TRX_NOT_STARTED状态。
这段话很难理解。看看上面的图表就知道了。)
[En]
It is difficult to understand this paragraph. Just look at the diagram above. )
2. Order Commit:是LOGICAL_CLOCK并行复制的基础
关于MySQL是如何提交的,内部使用ordered_commit函数来处理的。先看它的逻辑图,如下:
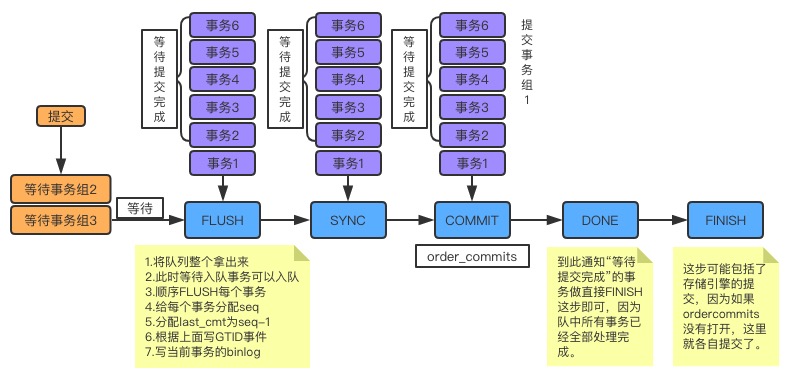
从图中可以看到,只要事务提交(调用ordered_commit),就都会先加入队列中。
提交有三个步骤,包括FLUSH、SYNC及COMMIT,相应地也有三个队列。
- 首先要加入的是FLUSH队列:
- 如果某个事务加入时,队列还是空的,则这个事务就担任队长,来代表其他事务执行提交操作。
- 而在其他事务继续加入时,就会发现此时队列已经不为空了,那么这些事务就会在队列中等待队长帮它们完成提交操作。在上图中,事务2-6都是这种坐享其成之辈,事务1就是队长了。
- 这里需要注意一点,不是说队长会一直等待要提交的事务不停地加入,而是有一个时限,这个时限就是从队长加入开始,到它去处理队列的时间——等待binlog_group_commit_sync_delay毫秒,便进行一次组提交,如果在等待事件范围内提前达到binlog_group_commit_sync_no_delay_count事务个数时,也会直接进行一次组提交。
- 只要队长将这个队列中的事务取出,其他事务就可以加入这个等待队列了。第一个加入的还是队长,但此时必须要等待。因为此时有事务正在做FLUSH,做完FLUSH之后,其他的队长才能带着队员做FLUSH。
- 在同一时刻,只能有一个组在做FLUSH。这就是上图中所示的等待事务组2和等待事务组3,此时队长会按照顺序依次做FLUSH。
-
做FLUSH的过程中,有一些重要的事务需要去做,如下:
- 要保证顺序必须是提交加入到队列的顺序。
- 如果有新的事务提交,此时队列为空,则可以加入到FLUSH队列中。不过,因为此时FLUSH临界区正在被占用,所以新事务组必须要等待。
-
给每个事务分配sequence_number,如果是第一个事务,则将这个组的last_committed设置为sequence_number-1.
-
将带着last_committed与sequence_number的GTID事件FLUSH到Binlog文件中。
- 将当前事务所产生的Binlog内容FLUSH到Binlog文件中。 这样,一个事务的FLUSH就完成了。接下来,依次做完组内所有事务的FLUSH。然后做SYNC。
做完FLUSH之后,FLUSH临界区会空闲出来,此时在等待这个临界区的组就可以做FLUSH操作了。 - SYNC队列
如果SYNC的临界区是空的,则直接做SYNC操作,而如果已经有事务组在做,则必须要等待。 - COMMIT队列
到COMMIT时,实际做的是存储引擎提交,参数binlog_order_commits会影响提交行为。 - 如果设置为ON,那么此时提交就变为串行操作了,就以队列的顺序为提交顺序。
- 如果设置为OFF,提交就不会在这里进行,而会在每个事务(包括队长和队员)做finish_commit(FINISH)时各自做存储引擎的提交操作。
- 组内每个事务做finish_commit是在队长完成COMMIT工序之后进行,到步骤DONE时,便会唤醒每个等待提交完成的事务,告诉他们可以继续了,那么每个事务就会去做finish_commit。
- 而后,队长自己再去做finish_commit。这样,一个组的事务就都按部就班地提交完成了。
现在应该搞明白关于order commit的原理了,而这也是LOGICAL_CLOCK并行复制的基础。
因为order commit使得所有的事务分了组,并且有了序列号,从库拿到这些信息之后,就可以根据序号放心大胆地做分发了。
探索:binlog_group_commit_sync_delay 、binlog_group_commit_sync_no_delay_count对group commit的影响:
从时间上看,从加入团队到拿到队列中的所有交易的时间都很短,所以这段时间交易不会很多。
[En]
In terms of time, the time between joining the team and getting all the transactions in the queue is very small, so there will not be many transactions during this period of time.
只有当压力很大,提交的事务数量很大时,并发程度才会增加(集团内的事务数量变大)。
[En]
Only when there is a lot of pressure and a large number of transactions committed will the degree of concurrency be increased (the number of transactions in the group becomes larger).
不过,这个问题也可以解释,在主库压力不大的情况下,为什么需要这么大的并发性?只有当主库压力较大时,才会延迟从库。
[En]
However, this problem can also be explained, when the pressure of the main library is small, why do you need such a large degree of concurrency? Only when the pressure on the master library is high, the slave library will be delayed.
这种情况下也可以通过调整主服务器上的参数 binlog_group_commit_sync_delay、 binlog_group_commit_sync_no_delay_count。
- binlog_group_commit_sync_delay表示事务延迟提交多少时间来加大整个组提交的事务数量,从而减少进行磁盘刷盘sync的次数,单位为1/1000000秒,最大值1000000也就是1秒;
- binlog_group_commit_sync_no_delay_count表示组提交的事务数量凑齐多少此值时就跳出等待,然后提交事务,而无需等待binlog_group_commit_sync_delay的延迟时间;但是binlog_group_commit_sync_no_delay_count也不会超过binlog_group_commit_sync_delay设置。
两个参数都是为了增加主服务器组提交的事务比例,从而增大从机MTS的并行度。
事务group commit,logical clock(order commit)示意图:
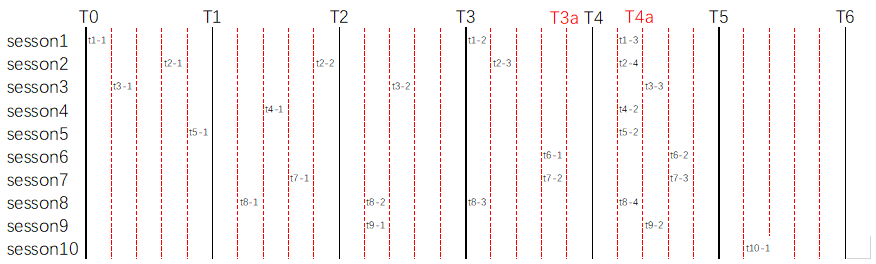
假设当前环境配置参数:
binlog_group_commit_sync_delay = 1000
binlog_group_commit_sync_no_delay_count = 5
图中:
T0->T1->..->T6,每一个区间表示一个 binlog_group_commit_sync_delay = 1000时间范围,红虚线将该时间范围5等分。
其中,T0为session1 – session10 十个会话同时开启事务的时间节点。
tn-m,为session-n在当前位置进行了第m次提交动作。
- 当时间进行到T1时,达到binlog_group_commit_sync_delay = 1000 的delay时间限制,本次group commit内容为:(不考虑队长顺序)
t1-1,last_committed=0, sequence_number=1
t2-1,last_committed=0, sequence_number=2
t3-1,last_committed=0, sequence_number=3
t5-1,last_committed=0, sequence_number=4
- 当时间进行到T2时,再一次达到binlog_group_commit_sync_delay = 1000 的delay时间限制,本次group commit内容为:(不考虑队长顺序)
t2-2,last_committed=4, sequence_number=5
t4-1,last_committed=4, sequence_number=6
t7-1,last_committed=4, sequence_number=7
t8-1,last_committed=4, sequence_number=8
- 当时间进行到T3时,再一次达到binlog_group_commit_sync_delay = 1000 的delay时间限制,本次group commit内容为:(不考虑队长顺序)
t3-2,last_committed=8, sequence_number=9
t8-2,last_committed=8, sequence_number=10
t9-1,last_committed=8, sequence_number=11
- 当时间进行到T3a时,尽管未达到binlog_group_commit_sync_delay = 1000 的delay时间限制,但是已经发生5次提交,达到binlog_group_commit_sync_no_delay_count = 5计数上限,将立即进行组提交,本次group commit内容为:(不考虑队长顺序)
t1-2,last_committed=11, sequence_number=12
t2-3,last_committed=11, sequence_number=13
t6-1,last_committed=11, sequence_number=14
t7-2,last_committed=11, sequence_number=15
t8-3,last_committed=11, sequence_number=16
- 当时间进行到T4a时,尽管未达到binlog_group_commit_sync_delay = 1000 的delay时间限制,但是已经发生5次提交,达到binlog_group_commit_sync_no_delay_count = 5计数上限,将立即进行组提交,本次group commit内容为:(不考虑队长顺序)
t1-3,last_committed=16, sequence_number=17
t2-4,last_committed=16, sequence_number=18
t4-2,last_committed=16, sequence_number=19
t5-2,last_committed=16, sequence_number=20
t8-4,last_committed=16, sequence_number=21
- 一个彩蛋。当t10-1事务提交后,将会立即执行组提交,为什么?
- 因为T4a时间点进行组提交后,delay 1000(5格时间单位)的提交时间点刚好在t10-1事务提交发生的同一时间。
- 也因为T4a时间点进行组提交后,截至t10-1事务提交,count刚好达到计数上限——5。
本次group commit内容为:(不考虑队长顺序)
t3-3,last_committed=21, sequence_number=22
t6-2,last_committed=21, sequence_number=23
t7-3,last_committed=21, sequence_number=24
t9-2,last_committed=21, sequence_number=25
t10-1,last_committed=21, sequence_number=26
从库多线程复制分发原理
知道了order commit原理之后,现在很容易可以想到在从库端是如何分发的:
从库以事务为单位做APPLY的,每个事务有一个GTID事件,因此都有一个last_committed及sequence_number值。
1. 基于last_committed分发原理如下:
因为last_committed值的记录方式是:master将上一组最后一个sequence_number记录为下一组的last_committed,因此 本组的sequence_number最小值肯定大于last_committed,下一组的last_committed肯定大于前一组sequence_number的最小值(因为等于sequence_number最大值)
- sql thread拿到一个新事务,取出该事务的last_committed及sequence_number值。
- 将已经执行的事务的sequence_number的最小值(low water mark,lwm),与取出事务的last_committed值进行比较。( 本组的sequence_number最小值肯定大于last_committed)
- 如果取出事务的last_committed小于已经执行的sequence(lwm),说明取出事务与当前执行组为同组,无需等待,直接由sql thread 分配事务到空闲worker线程。
- SQL线程通过统计,找到一个空闲的worker线程,如果没有空闲,则SQL线程转入等待状态,直到找到一个空闲worker线程为止。将当前事务打包,交给选定的worker,之后worker线程会去APPLY这个事务,此时的SQL线程就会处理下一个事务。
- 如果取出事务的last_committed大于等于已经执行的lwm,说明取出事务与当前不为一组,取出事务为新组,需等待。
- 等待lwm增长,当已经执行的sequence(lwm)等于取出事务的last_committed时,说明前一组已经执行完成。sql thread 开始将取出事务的last_committed组事务分发给worker线程进行并行apply。
原理示意参考:
- 事务示意参考:
t3-3,last_committed=21, sequence_number=22
t6-2,last_committed=21, sequence_number=23
t7-3,last_committed=21, sequence_number=24
t9-2,last_committed=21, sequence_number=25
t10-1,last_committed=21, sequence_number=26
new,last_committed=26, sequence_number=27
- 假设此时sql thread 刚刚将事务t3-3分发给worker线程:
- sql thread拿出事务(t6-2)的last_committed和sequence_number(21,23),
- 如果拿出事务的last_committed(21)小于当前已经执行的sequence_number的最小值(22),说明拿出的事务与正在执行的事务是同组,无需等待。
-
sql thread拿出事务(t7-3)的last_committed和sequence_number(21,24),
- 如果拿出事务的last_committed(21)小于当前已经执行的sequence_number的最小值(22),说明拿出的事务与正在执行的事务是同组,无需等待。 ……
-
sql thread拿出事务(new)的last_committed和sequence_number(26,27),
- 如果拿出事务的last_committed(26)大于等于当前已经执行的sequence_number的最小值(22),说明拿出的事务是新的一组,拿出的事务需等待。
- 当sql thread 判断已经执行的sequence _number 等于拿出事务的 last_committed 时,说明可以开始新一组的apply了。
- 当事务(t10-1)执行后,已经执行的sequence_number(26) = 拿出事务的last_committed(26),前一组已经执行完成,sql thread 开始将last_committed=26的组事务分发给worker线程进行并行apply。
Commit-Parent-Based Scheme简介(WL#7165)
- 在master上,有一个全局计数器(global counter)。在每一次存储引擎完成提交之前,计数器值就会增加。
- 在master上,在事务进入prepare阶段之前,全局计数器的当前值会被储存在事务中。这个值称为此事务的commit-parent(last_committed)。
- 在master上,commit-parent会在事务的开头被储存在binlog中。
- 在slave上,如果两个事务有同一个commit-parent,他们就可以并行被执行。
此commit-parent就是我们在binlog中看到的last_committed。如果commit-parent相同,即last_committed相同,则被视为同一组,可以并行回放。
基于last_committed分发(Commit-Parent-Based Scheme)存在的问题
一句话:Commit-Parent-Based Scheme会降低复制的并行程度。
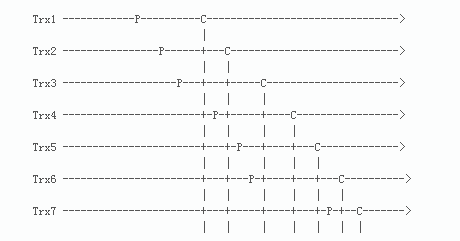
解释一下图:
- 水平虚线表明交易按时间顺序倒退
[En]
horizontal dotted lines indicate that transactions go backward in chronological order.*
- P表示事务在进入prepare阶段之前读到的commit-parent值的那个时间点(last_committed)。可以简单的视为加锁时间点。
- C表示事务增加了全局计数器(global counter)的值的那个时间点(sequence)。可以简单的视为释放锁的时间点
- P对应的commit-parent(last_commited)是取自所有已经执行完的事务的最大的C对应的sequence_number。
- 举例来说:
- Trx4的P对应的commit-parent(last_commited)取自所有已经执行完的事务的最大的C对应的sequence_number=1,也就是Trx1的C对应的sequence_number。因为这个时候Trx1已经执行完,但是Trx2还未执行完。
- Trx5的P对应的commit-parent(last_commited)取自所有已经执行完的事务的最大的C对应的sequence_number=2,也就是Trx2的C对应的sequence_number;
- Trx6的P对应的commit-parent(last_commited)取自所有已经执行完的事务的最大的C对应的sequence_number=2,也就是Trx2的C对应的sequence_number。所以Trx5和Trx6具有相同的commit-parent(last_commited),在进行回放的时候,Trx5和Trx6可以并行回放。
- 由图可见:
- Trx5 和Trx6可以并发执行,因为他们的commit-parent是相同的,都是由Trx2设定的。
- Trx4和Trx5不能并发执行,
- Trx6和Trx7也不能并发执行。 可以注意到,在同一时段,Trx4和Trx5、Trx6和Trx7分别持有他们各自的锁,事务互不冲突。如果在slave上并发执行,也是不会有问题的。
- 从上面的例子可以看出:
[En]
from the above examples, we can see that:*
- 在基于last_committed规则下,Trx4、Trx5和Trx6在同一时间持有各自的锁,但Trx4无法并发执行,因为Trx4取到的laste_committed和后两者不同。
- Trx6和Trx7在同一时间持有各自的锁,但Trx7无法并发执行,原因一样。 实际上,Trx4是可以和Trx5、Trx6并行执行,Trx6可以和Trx7并行执行。如果能实现这个,那么并行复制的效果会更好。 所以官方对并行复制的机制做了改进,提出了一种新的并行复制的方式:Lock-Based Scheme。# 5.7开始基于lock interval的并行规则(WL#7165)
说明:上面的步骤是以事务为单位介绍的,其实实际处理中还是一个事件一个事件地分发。如果一个事务已经选定了worker,而新的event还在那个事务中,则直接交给那个worker处理即可。
从上面的分发原理来看,同时执行的都是具有相同last_committed值的事务,不同的只是后面的需要等前面做完了才能执行,这样的执行方式有点如下图所示:
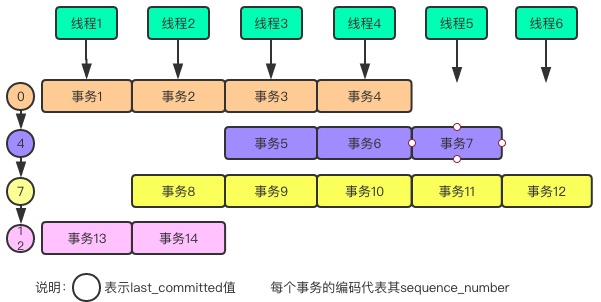
可以看出,事务都是随机分配到了worker线程中,但是执行的话,必须是一行一行地执行。一行事务个数越多,并行度越高,也说明主库瞬时压力越大。
2. MySQL 5.7开始基于lock interval的并行规则(WL#7165)
实现:如果两个事务同时持有自己的锁,则它们可以并发执行。
[En]
Implementation: if two transactions hold their own locks at the same time, they can be executed concurrently.
对前一个原理需要补充为:
因为last_committed值的记录方式是:master将上一组最后一个sequence_number记录为下一组的last_committed,master将MySQL全局变量global.max_committed_transaction(所有已经结束lock interval的事务的最大的sequence_number)记录为下一组的last_committed,因此本组的sequence_number最小值肯定大于last_committed,下一组的last_committed肯定大于前一组sequence_number的最小值(因为等于sequence_number最大值)
# 根据基于锁特性,实际上是与本组第一个Prepare存在时间间隙的上一组C的那个事务的sequence,也就是说,如果前一组的后几个事务与当前组的前几个事务存在lock interval重叠,那么前一组的这几个事务再向前一个事务的sequence才是当前组的last_committed
Lock-Based Scheme简介(WL#7165)
首先,定义了一个称为lock interval的概念,含义:一个事务持有锁的时间间隔。
- 当存储引擎提交,第一把锁释放,lock interval结束。
- 当最后一把锁获取,lock interval开始。
假定:最后一把锁获取是在binlog_prepare阶段。
假设有两个事务:Trx1、Trx2。Trx1先于Trx2。那么,
- 当且仅当Trx1、Trx2的lock interval有重叠,则可以并行执行。

- 换言之,如果Trx1的lock interval结束点与Trx2的lock interval开始点存在间隙,则不能并行执行。

- MySQL会获取全局变量global.max_committed_transaction,含义:所有已经结束lock interval的事务的最大的sequence_number。
- L表示lock interval的开始点
- 对于L(lock interval的开始点),MySQL会把
global.max_committed_timestamp分配给一个变量,并取名叫transaction.last_committed。 - C表示lock interval的结束
- 对于C(lock interval的结束点),MySQL会给每个事务分配一个逻辑时间戳(logical timestamp),命名为:
transaction.sequence_number。
transaction.sequence_number和 transaction.last_committed这两个时间戳都会存放在binlog中。
- 根据以上分析,我们可以得出在slave上执行事务的条件:
如果所有正在执行的事务的最小的sequence_number大于一个事务的transaction.last_committed,那么这个事务就可以并发执行。(这句话太绕,不用强求,看下面土味理解好了)
土味理解Lock-Based Scheme
在这先抛开writeset,不要混淆了,理解了这个会有助于理解writeset原理。
- 基于commit parent的方式, 事务的last_committed肯定等于前一组最后一个事务的sequence number。
- 但是在基于lock interval方式时,不是这样了,事务的last_committed不一定等于前一组最后一个事务的sequence number了,而是等于所有已经结束lock interval的事务的最大的sequence_number。
- 举例说明: Lock-Based Scheme例子
…
t1,last_committed=0, sequence_number=3
t2,last_committed=3, sequence_number=4
t3,last_committed=3, sequence_number=5
t4,last_committed=3, sequence_number=6
t5,last_committed=3, sequence_number=7
t6,last_committed=6, sequence_number=8
t7,last_committed=6, sequence_number=9
t8,last_committed=9, sequence_number=10
- 事务t1,last_committed=0,sequence_number=3。第一个work线程会接手这个事务并开始工作。
- 事务t2,last_committed=3, sequence_number=4。直到事务t1完成,事务t2才能开始。因为last_committed=3不小于正在执行执行事务的sequence_number=3。所以这两个事务只能串行。
- 虽然前2个事务可能会被分配到不同的work线程,但实际上他们是串行的,就像单线程复制那样。
- 当sequence_number=3的事务完成,last_committed=3的三个事务就可以并发执行。
t3,last_committed=3, sequence_number=5
t4,last_committed=3, sequence_number=6
t5,last_committed=3, sequence_number=7
- 一旦前两个(t3,t4)执行完成,下面这两个可以开始执行:
last_committed=6 sequence_number=8 last_committed=6 sequence_number=9
因为last_committed=6小于正在执行执行事务的sequence_number=7,可以并行。
- 也就是说,当t5,last_committed=3, sequence_number=7正在执行的时候,sequence_number=8和sequence_number=9这两个也可以并发执行。
- 完成这三笔交易没有顺序限制
[En]
there is no sequence restriction on the completion of these three transactions.*
- 因为这三个事务的lock interval有重叠,因此可以并发执行,所以事务之间并不会相互影响。
- 等待之前所有交易完成后,才能进行以下交易:
[En]
wait until all the previous transactions are completed before the following transaction can be carried out:*
t8,last_committed=9, sequence_number=10- 看完后头晕目眩?没关系,别担心,看看以下几点:[En] get more dizzy after reading it? It doesn’t matter, don’t worry about it, look at the following:

- 首先说明,图中事务Tx1作为参考事务,忽略它,它的意义就是为Tx2事务提供一个last_committed。
- Tx2–Tx5为第一组,Tx6~Tx7为第二组,用底色做了区分。
- 可以看到:
- 事务Tx2~Tx5都存在lock interval重叠,这4个事务可以并行apply,因此这4个事务在一个组。
- 事务Tx6因为和事务Tx4没有发生lock interval重叠,因此事务Tx6无法和Tx4并行,也就无法成为前一组的成员,只能自己成立新组。
- 第一组的最后一个事务Tx5和第二组的事务Tx6、Tx7三个事务存在lock interval重叠,虽然跨组,但是这3个事务是满足并行逻辑,可以并行进行的。
- 第二组的last值=6,并不是第一组最后一个事务的sequence_number=7。(为什么?↓)
实际上第二组的last_committed值是取自于这个规则:
-
几个关键的时间点:
- 第二组第一个事务开始prepare的时间点称为A点(last_committed)。
- A点发生时,第一组中所有已经结束lock interval的事务的最大的sequence_number称为B点。
- 第一组最后一个事务Tx5的commit时间称为C点(sequence_number)
- 在A点发生prepare时,B点和A点之间存在间隙(就是说,事务tx4和事务tx6不存在锁重叠),Tx4,Tx6无法并行,因此A点进行prepare的事务Tx6成为了新组的事务。
- A点取当时所有已经结束lock interval的事务的最大的sequence_number作为自己的last_committed。Tx6的last_committed=6。
总结一句话就是:last_committed值取自于前一组中,与本组事务不存在lock interval重叠的最后一个事务的sequence number
- 结论:
- 事务之间存在lock interval重叠便可以并行apply,但是只要任意两个事务之间存在gap(事务lock interval不重叠)便会导致分组。
- 分组只是避免锁冲突,并不意味着无法并行(不管有没有锁冲突,只要事务不重叠就悲观认为存在冲突,拒绝并行)。
- 能否并行的只根据一个情况判断,就是事务之间lock interval重叠。因此即使事务在不同的组中,只要存在lock interval重叠,就可能会并行apply。
MySQL 5.7并行复制测试
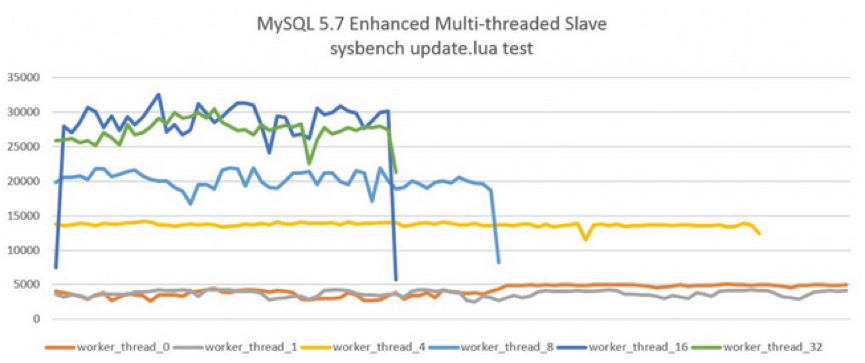
下图显示了开启MTS后,Slave服务器的QPS。测试的工具是sysbench的单表全update测试,测试结果显示在16个线程下的性能最好,从机的QPS可以达到25000以上,进一步增加并行执行的线程至32并没有带来更高的提升。而原单线程回放的QPS仅在4000左右,可见MySQL 5.7 MTS带来的性能提升,而由于测试的是单表,所以MySQL 5.6的MTS机制则完全无能为力了。
并行复制配置与调优
- master_info_repository 开启MTS功能后,务必将参数master_info_repostitory设置为TABLE,这样性能可以有50%~80%的提升。这是因为并行复制开启后对于master.info这个文件的更新将会大幅提升,资源的竞争也会变大。
- slave_parallel_workers 若将slave_parallel_workers设置为0,则MySQL 5.7退化为原单线程复制,但将slave_parallel_workers设置为1,则SQL线程功能转化为coordinator线程,但是只有1个worker线程进行回放,也是单线程复制。然而,这两种性能却又有一些的区别,因为多了一次coordinator线程的转发,因此slave_parallel_workers=1的性能反而比0还要差,测试下还有20%左右的性能下降,如下图所示:
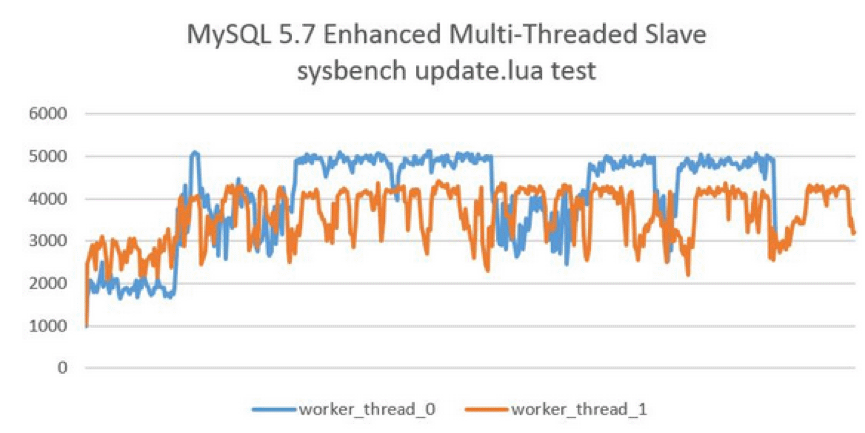
这里引入了另一个问题。如果主机上的负载不大,那么组提交的效率不高,而且很有可能每个组只有一个提交的事务,所以在从机回放过程中,虽然启用了并行复制,但性能会比原来的单线程还要差,也就是延迟会增加。聪明的朋友们,你们有没有想过优化这一点?
[En]
Another problem is introduced here. If the load on the host is not large, then the efficiency of group commit is not high, and it is very likely that there will be only one committed transaction per group, so during the playback of the slave, although parallel replication is enabled, however, the performance will be even worse than the original single thread, that is, the delay will increase. Smart friends, have you ever thought about optimizing this?
- slave_preserve_commit_order MySQL 5.7后的MTS可以实现更小粒度的并行复制,但需要将slave_parallel_type设置为LOGICAL_CLOCK,但仅仅设置为LOGICAL_CLOCK也会存在问题,因为此时在slave上应用事务的顺序是无序的,和relay log中记录的事务顺序不一样,这样数据一致性是无法保证的,为了保证事务是按照relay log中记录的顺序来回放,就需要开启参数slave_preserve_commit_order。 开启该参数后,执行线程将一直等待, 直到提交之前所有的事务。当sql thread正在等待其他worker提交其事务时, 其状态为等待前面的事务提交。 所以虽然MySQL 5.7添加MTS后,虽然slave可以并行应用relay log,但commit部分仍然是顺序提交,其中可能会有等待的情况。 当开启slave_preserve_commit_order参数后,slave_parallel_type只能是LOGICAL_CLOCK,如果你有使用级联复制,那LOGICAL_CLOCK可能会使离master越远的slave并行性越差。 但是经过测试,这个参数在MySQL 5.7.18中设置之后,也无法保证slave上事务提交的顺序与relay log一致。 在MySQL 5.7.19设置后,slave上事务的提交顺序与relay log中一致(所以生产要想使用MTS特性,版本大于等于MySQL 5.7.19才是安全的)。
说了这么多,要开启enhanced multi-threaded slave其实很简单,只需根据如下设置:
slave;
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
slave_pending_jobs_size_max = 2147483648
slave_preserve_commit_order=1
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
在使用了MTS后,复制的监控依旧可以通过SHOW SLAVE STATUS\G,但是MySQL 5.7在performance_schema架构下多了以下这些元数据表,用户可以更细力度的进行监控:
mysql> show tables like 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)
通过replication_applier_status_by_worker可以看到worker进程的工作情况:
mysql> select * from replication_applier_status_by_worker;
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
| CHANNEL_NAME | WORKER_ID | THREAD_ID | SERVICE_STATE | LAST_SEEN_TRANSACTION | LAST_ERROR_NUMBER | LAST_ERROR_MESSAGE | LAST_ERROR_TIMESTAMP |
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
| | 1 | 32 | ON | 0d8513d8-00a4-11e6-a510-f4ce46861268:96604 | 0 | | 0000-00-00 00:00:00 |
| | 2 | 33 | ON | 0d8513d8-00a4-11e6-a510-f4ce46861268:97760 | 0 | | 0000-00-00 00:00:00 |
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
2 rows in set (0.00 sec)
那么怎样知道从机MTS的并行程度又是一个难度不小。简单的一种方法(姜总给出的),可以使用performance_schema库来观察,比如下面这条SQL可以统计每个Worker Thread执行的事务数量,在此基础上再做一个聚合分析就可得出每个MTS的并行度:
SELECT thread_id,count_star FROM performance_schema.events_transactions_summary_by_thread_by_event_name
WHERE thread_id IN (SELECT thread_id FROM performance_schema.replication_applier_status_by_worker);
如果线程并行度太高,不够平均,其实并行效果并不会好,可以试着优化。这种场景下,可以通过调整主服务器上的参数binlog_group_commit_sync_delay、binlog_group_commit_sync_no_delay_count。前者表示延迟多少时间提交事务,后者表示组提交事务凑齐多少个事务再一起提交。总体来说,都是为了增加主服务器组提交的事务比例,从而增大从机MTS的并行度。
虽然MySQL 5.7推出的Enhanced Multi-Threaded Slave在一定程度上解决了困扰MySQL长达数十年的复制延迟问题。然而,目前MTS机制基于组提交实现,简单来说在主上是怎样并行执行的,从服务器上就怎么回放。这里存在一个可能,即若主服务器的并行度不够,则从机的并行机制效果就会大打折扣。MySQL 8.0最新的基于writeset的MTS才是最终的解决之道。即两个事务,只要更新的记录没有重叠(overlap),则在从机上就可并行执行,无需在一个组,即使主服务器单线程执行,从服务器依然可以并行回放。相信这是最完美的解决之道,MTS的最终形态。
最后,如果MySQL 5.7要使用MTS功能,必须使用最新版本,最少升级到5.7.19版本,修复了很多Bug。
参考信息
http://www.ywnds.com/?p=3894
运维内参书籍
姜总的公众号文章
http://mysql.taobao.org/monthly/2017/12/03/
https://mp.weixin.qq.com/s/XbWMdVTl9qz1nSwL3l56XQOriginal: https://www.cnblogs.com/konggg/p/16359474.html
Author: 孔个个
Title: MySQL并行复制(MTS)原理(完整版)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/505300/
转载文章受原作者版权保护。转载请注明原作者出处!