

11 | 怎么给字符串字段加索引?
Q:如何在邮箱这样的字段上建立合理的索引?
用户表的定义:
create table SUser(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
由于您将使用邮箱登录,因此业务代码中必须出现类似以下内容的语句:
[En]
Because you are going to log in using a mailbox, a statement similar to this must appear in the business code:
select f1, f2 from SUser where email='xxx';
如果 email 这个字段上没有索引,那么这个语句就只能做全表扫描。
A:
前缀索引
MySQL 是支持前缀索引的,也就是说,可以定义 字符串的一部分作为索引。
默认情况下,如果创建索引的语句没有指定前缀长度,则索引将包含整个字符串。
[En]
By default, if the statement in which you create the index does not specify a prefix length, the index will contain the entire string.
alter table SUser add index index1(email);
alter table SUser add index index2(email(6));
第一个语句创建的 index1 索引里面,包含了每个记录的整个字符串;
而第二个语句创建的 index2 索引里面,对于每个记录都是只取前 6 个字节。
数据结构和存储方面的差异:
[En]
Differences in data structure and storage:
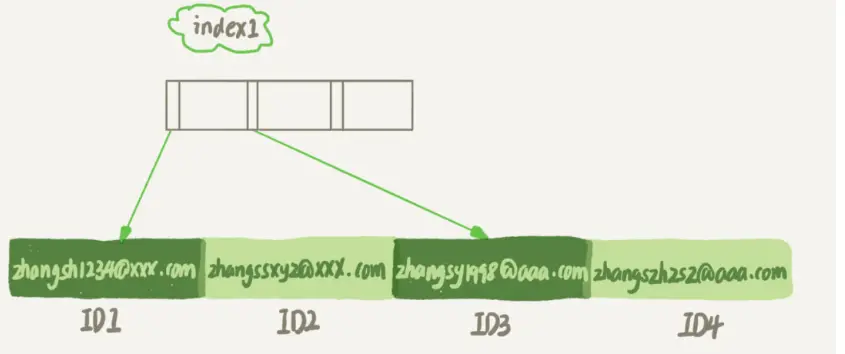

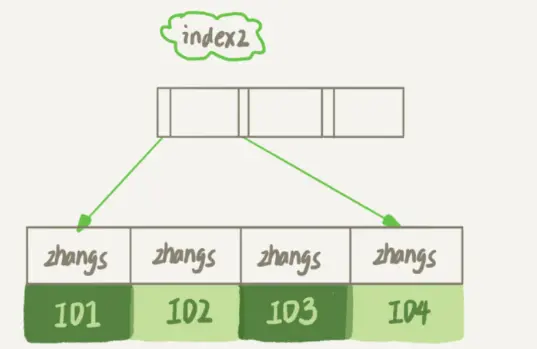
由于 email(6) 这个索引结构中每个邮箱字段都只取前 6 个字节(即:zhangs),所以 占用的空间会更小,这就是使用前缀索引的优势。
与此同时,损失在于它可能会增加额外的记录扫描次数。
[En]
At the same time, the loss is that it may increase the number of additional record scans.
执行上面的select时:
如果使用的是 index1(即 email 整个字符串的索引结构),执行顺序是这样的:
- 从 index1 索引树找到满足索引值是’zhangssxyz@xxx.com’的这条记录,取得 ID2 的值;
- 到主键上查到主键值是 ID2 的行,判断 email 的值是正确的,将这行记录加入结果集;
- 取 index1 索引树上刚刚查到的位置的下一条记录,发现 已经不满足 email=’zhangssxyz@xxx.com’的条件了,循环结束。
在此过程中,您只需要返回到主键检索数据一次,因此系统认为只扫描了一行。
[En]
In this process, you only need to go back to the primary key to retrieve the data once, so the system thinks that only one row has been scanned.
如果使用的是 index2(即 email(6) 索引结构),执行顺序是这样的:
- 从 index2 索引树找到满足索引值是’zhangs’的记录,找到的第一个是 ID1;
- 到主键上查到主键值是 ID1 的行,判断出 email 的值不是’zhangssxyz@xxx.com’,这行记录丢弃;
- 取 index2 上刚刚查到的位置的下一条记录,发现仍然是’zhangs’,取出 ID2,再到 ID 索引上取整行然后判断,这次值对了,将这行记录加入结果集;
- 重复上一步, 直到在 idxe2 上取到的值不是’zhangs’时,循环结束。
因此,使用前缀索引可能会导致查询语句读取数据的次数更多。
[En]
Therefore, the use of prefix indexes may result in more times for query statements to read data.
使用多长的前缀呢?
在建立指数时,要注意分化程度,分化程度越高越好。因为分化程度越高,重复键值就越少。
[En]
When establishing the index, we should pay attention to the degree of differentiation, and the higher the degree of differentiation, the better. Because the higher the degree of differentiation, the fewer repeated key values.
以通过 统计索引上有多少个不同的值来判断要使用多长的前缀。
首先计算出此列中有多少个不同的值:
[En]
First figure out how many different values there are on this column:
select count(distinct email) as L from SUser;
然后,选择不同长度的前缀以查看此值:
[En]
Then, select the prefixes of different lengths to look at this value:
select
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from SUser;
前缀索引对覆盖索引的影响
select id,email from SUser where email='zhangssxyz@xxx.com';
使用index1,由于通过email可以直接找到id,即覆盖索引,不需要回表。
使用index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
即使你将 index2 的定义修改为 email(18) 的前缀索引,这时候 虽然 index2 已经包含了所有的信息,但 InnoDB 还是要回到 id 索引再查一下,因为系统并 不确定前缀索引的定义是否截断了完整信息。
前缀索引就用不上覆盖索引对查询性能的优化
其他方式
Q:遇到前缀的区分度不够好的情况时,要怎么办?例如身份证号码?
我希望它不仅能占用更少的空间,还能达到同样的查询效率。
[En]
I hope it can not only occupy less space, but also achieve the same query efficiency.
A:
第一种方式是使用倒序存储。如果你存储身份证号的时候把它倒过来存,每次查询的时候,你可以这么写
select field_list from t where id_card = reverse('input_id_card_string');
由于身份证号的最后 6 位没有地址码这样的重复逻辑,所以最后这 6 位很可能就提供了足够的区分度
第二种方式是使用 hash 字段。你可以 在表上再创建一个整数字段,来保存身份证的校验码,同时 在这个字段上创建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
然后每次插入新记录的时候,都同时用 crc32() 这个函数得到校验码填到这个新字段。
crc32 – 计网数据库中常使用 返回字符串的 32 位循环冗余校验值。
由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
使用倒序存储和使用 hash 字段这两种方法的异同点
同样的事情是不支持范围查询。
[En]
The same thing is that range queries are not supported.
倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经 没有办法利用索引方式查出身份证号码在 [ID_X, ID_Y] 的所有市民。同样地,hash 字段的方式也只能支持 等值查询。
差异主要体现在以下三个方面:
[En]
The differences are mainly reflected in the following three aspects:
- 从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。
- 在 CPU 消耗方面,倒序方式 每次写和读的时候,都需要 额外调用一次 reverse 函数,而 hash 字段的方式需要 额外调用一次 crc32() 函数。
- 从查询效率上看, 使用 hash 字段方式的查询性能相对更稳定一些。因为 crc32 算出来的值虽然有冲突的概率,但是概率非常小,可以认为每次查询的平均扫描行数接近 1。而倒序存储方式毕竟还是用的前缀索引的方式,也就是说还是会增加扫描行数。
总结
- 直接创建完整索引,这样可能 比较占用空间;
- 创建前缀索引,节省空间,但会增加查询扫描次数,并且 不能使用覆盖索引;
- 倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题;
- 创建 hash 字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都 不支持范围扫描。
Q:如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是” 学号 @gmail.com“
学号规则为:15位,其中前三位为城市号,第四至第六位为校号,第七至第十位为入学年份,后五位为顺序号。
[En]
The rule of the student number is: fifteen digits, of which the first three are the city number, the fourth to the sixth is the school number, the seventh to the tenth is the year of admission, and the last five digits are sequential numbers.
当系统登录时,学生需要输入他们的登录名和密码,并验证他们是正确的,然后才能继续使用系统。如果只考虑登录身份验证的行为,如何设计登录名的索引?
[En]
When the system logs in, students are required to enter their login name and password and verify that they are correct before they can continue to use the system. If you only consider the behavior of login authentication, how do you design the index of the login name?
A:
因为维护的只是 一个学校的,因此前面 6 位(其中,前三位是所在城市编号、第四到第六位是学校编号)其实是 固定的,邮箱后缀都是 @gamil.com,因此可以 只存入学年份加顺序编号,它们的长度是 9 位。
而其实在此基础上,可以用 数字类型来存这 9 位数字。比如 201100001, 这样只需要占 4 个字节。其实这个就是一种 hash,只是它用了最简单的转换规则: 字符串转数字的规则,而刚好我们设定的这个背景,可以保证这个转换后结果的唯一性。
Original: https://www.cnblogs.com/ydssx7/p/16512781.html
Author: ydssx
Title: MySQL实战45讲 11
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/505164/
转载文章受原作者版权保护。转载请注明原作者出处!