

时代在召唤: HTAP Is On The Way
近些年,HTAP 正在受到人们越来越多的关注,Gartner 在 2014 年提出了 HTAP 这个术语和它的定义:
Hybrid transaction/analytical processing (HTAP) is an emerging application architecture that “breaks the wall” between transaction processing and analytics. It enables more informed and “in business real time” decision making.
在此之前,市面上基本是 OLTP 和 OLAP 数据库的天下。
OLTP
第一个有效的面向事务的数据库在 1970 / 1980 年代开始广泛使用,它们后来被称为在线事务处理 (OLTP:Online Transaction Processing) 系统, 事务处理对单记录操作可靠性、准确性和速度要求非常高。
OLAP
随着数据量的增大,特别是互联网的发展,OLTP 数据库的工作负载越来越大,同时分析能力严重受限,我们需要一个能非常快速地在一个或多个数据库表中查找单个记录、多条记录或一种记录总数的数据库。OLAP 数据库同 OLTP 数据库在技术上也分道扬镳。
然而,针对不同数据场景选择对应的 TP / AP 系统也带来了相应的难题,因为 TP 和 AP 不是一套系统,在搭配使用时就会有数据传输的过程。在 一体化实时 HTAP 数据库 StoneDB,如何替换 MySQL 并实现近百倍性能提升的文章中,我们总结了业界通过 TP / ETL或数据迁移 / AP 结构来构建 HTAP 系统存在的一些问题:
- 实时性低(TP + AP 系统导致了数据孤岛,意味着 OLAP 数据库中的数据总是过时的,根据数据量的不同,数据延迟通常从几小时到一周)。
- 企业维护两套数据库系统,管理维护成本非常高
[En]
Enterprises maintain two sets of database systems, and the cost of management and maintenance is very high.*
Gartner 的最新报告表明,传统的 TP + AP 架构将事务和分析系统分开,业务实时响应的高需求意味着使用”过时”的数据已经不合时宜,商业时刻转瞬即逝。我们需要创建一套更简单的体系结构,让 TP + AP 及 ETL 过程被单个数据库所取代,消除数据副本,将数据存储在 OLTP 引擎中进行事务处理,然后将数据复制到 OLAP 引擎(可能多次)以进行分析。随着软硬件基础设施和数据库技术的不断进步,属于 HTAP 数据库系统的时代已经到来。
HTAP 数据库 StoneDB 为什么选择拥抱 MySQL 生态?
StoneDB 并不希望打造一个新的 StoneDB HTAP 生态。对于大部分数据库用户来说,最好的产品体验就是开箱即用,在一个黑盒系统中完成业务的平滑迁移,最大程度的降低用户学习成本和运维成本。而 MySQL 是世界上最流行的数据库,拥有庞大和成熟的生态。
从 DB-Engines 排名上看到,MySQL 稳居第二,仅次于 Oracle。(下图来自 DB-Engines)


Shadowserver Foundation 在 5 月 31 日发布了一份全网的 MySQL扫描报告,超过 360 万个 MySQL 实例暴露在公网。这只是暴露出来的,我们可以推断,实际的装机量要远远大于这个数字。
IPv4 扫描

IPv6 扫描

业界唯一开源的 HTAP
我们以存储架构为特征对业界最新的 HTAP 数据库做一个概览:
- 基于磁盘的行存储 + 分布式列存储:MySQL HeatWave
- 以行存储为主 + IMCS (内存列):Oracle Database In-Memory(A dual format in-memory database)、 SQL Server、DB2 BLU
- 分布式行存储 + 列存副本:SingleStore
- 以列存为主 + Delta Row Store:SAP HANA
从上述中可以看到,哪怕是最流行的开源数据库 MySQL,它的 HeatWave 也不开源。
StoneDB 就是希望打破这种局面,在开源这条道路上做一个探索,做一款由我们中国人主导的开源 HTAP 数据库。
MySQL 原生
StoneDB 沿用并适配 MySQL sql 层,原生 100% 兼容 MySQL 协议和语法,我们先看下 StoneDB 官网提供的 2.0 架构图:

架构图中相关术语介绍:
IMCDP:In Memory Column Data Pack 的缩写,存储在内存中的列数据包。
IMCDPI:In Memory Column Data Pack Index 的缩写,用于保存 IMCDP 的元数据,包括:
- 对象数量
- 列数量
- 映射行的信息
- 事务相关的数据
SMU:snapshot meta unit 的缩写。
在 StoneDB 2.0 的设计中,会推出类似 MySQL HeatWave 的 In-Memory Column Store 引擎:基于磁盘的 RDBMS (MySQL 8.0)和分布式内存列存储(IMCS)来实现 HTAP。
StoneDB 在不改变 MySQL 原生的 OLTP 工作负载的前提下,深度集成 IMCS 集群以加速查询处理,事务在原生 MySQL 工作负载中执行。另外 StoneDB 会自行判断复杂查询并将其下推到 IMCS 引擎进行加速处理,经常访问的列将被加载到 IMCS 中,列数据从行存储中提取(由 InnoDB 并行加载到 IMCS),热数据驻留在 IMCS,冷数据落盘。
基于 IMCS 引擎我们将实现 AP 负载的全内存计算:
- 内存中数据组织方式:IMCDP + IMCDPI 。
- 数据加载方式:由 InnoDB 并行加载至 IMCS 中。
- 数据的更新:当 TP 中的数据发生变化的时候,实时更新到 AP 引擎中。
- 内存中数据持久化及系统恢复:为了加速恢复的速度,我们将内存中的数据持久化到我们的 on-disk column store 中。
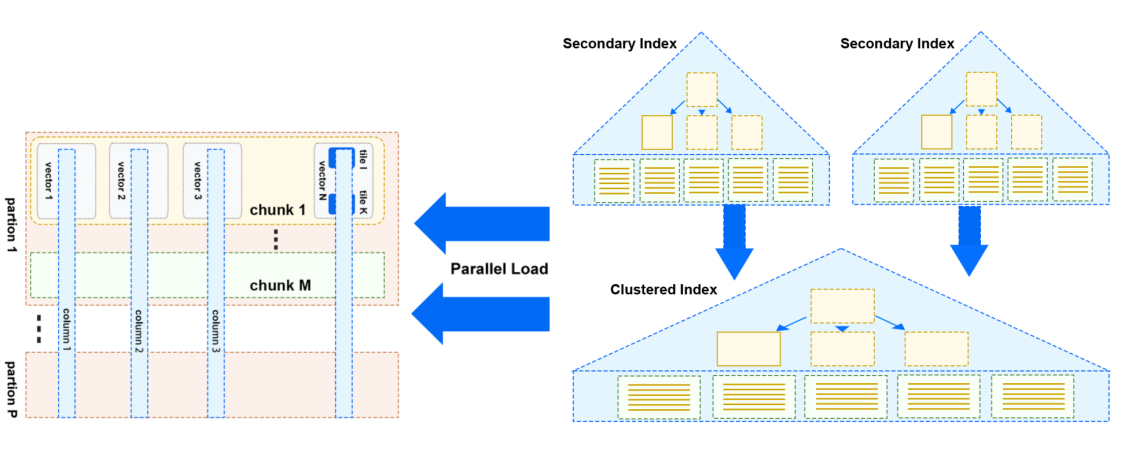
高效加载 TP 数据(From InnoDB)
上图是刚刚介绍了 StoneDB 2.0 架构中提到的从 InnoDB 并行加载数据的示意图。
与 HeatWave 采用的方案类似,通过并行扫描 TP 中的数据(主要是 InnoDB 表),将需要加载的数据按 partition ,chunk, vector, tile 的数据组织方式并行的加载至 IMCS 中,每个partion 中包括若干个 chunk,每个 chunk 中又包含若干个 vector,每个 vector 中包括了某列中的部分数据。同时,提供导入行为的监控能力,实时感知加载进度。在加载过程中通过非阻塞,无锁机制来实现高性能数据加载能力。

数据的更新
当 TP 中的数据发生变化后,将该项数据插入到 Population Buffer 中,并维护该数据的版本信息。当满足如下任一条件的时候,会将 Population Buffer 中的数据,依据版本信息依次与内存中的数据合并为最新的版本数据:
- 当我们的 Population Buffer 已经写满后,会执行一次 flush 动作,将 Population Buffer 中的数据更新到其对应的数据中。
- 指定 merge 的时间,例如:200ms。
-
当 AP 中的负载发现其引用到了 TP 中的数据,其会主动的检查 Population Buffer 是否有最新的版本。如果有则合并形成最新数据。

未来 2.0 其它的重点工作: -
新的基于代价的查询引擎:负载透明、更高效、更准确的代价模型将保证系统的性能;并行查询和向量化也将不断迭代。
[En]
A new cost-based query engine: a load transparent, more efficient and accurate cost model will guarantee the performance of our system; parallel query and vectorization will also be iterated continuously.*
- 分布式 Column Store AP 集群将在单机能力构建后,重点演进。
最后
除了 Gartner 的原始定义,我们对 HTAP 更多视为一个集硬件、TP、AP、内存、云原生数据库技术、可扩展事务管理等多种功能的 新兴架构,使事务处理和分析(HTAP)能够在同一套数据库上运行。
一个现代的 HTAP 数据库应该具备以下特性:
一致性:包含全面的 ACID 事务支持。数据密集型应用程序可以依靠它来保证数据一致性,从而提高开发人员的速度和用户体验。
高可用性:无论后端发生什么,用户都能进行 7×24 小时的访问。有一套内部机制来处理机器故障和网络问题等瞬时和永久性故障(比如宕机/脑裂),并且提供数据复制和细粒度数据放置功能,以确保数据高可用。并且提供滚动升级机制,避免集群扩展和架构升级等引发的停机对业务造成影响。
可扩展性:应用云原生技术,其计算和存储资源可以轻松扩展以应对业务的增长。按需且实时地添加新节点,以存储更多数据、处理更多读取和写入以及处理更复杂的查询。
实时性:数据库应支持任何实时更新,从而实现细粒度索引和并行查询执行。为了确保及时性,数据库架构必须同时利用行存储和列存储,并基于查询优化器选择最佳的数据访问路径。
Original: https://www.cnblogs.com/yangwilly/p/16580077.html
Author: 来来士
Title: StoneDB 为何敢称业界唯一开源的 MySQL 原生 HTAP 数据库
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/505046/
转载文章受原作者版权保护。转载请注明原作者出处!