

利用C++ ONNXruntime部署自己的模型,这里用Keras搭建好的一个网络模型来举例,转换为onnx的文件,在C++上进行部署,另外可以利用tensorRT加速。
Github地址:https://github.com/zouyuelin/SLAM_Learning_notes/tree/main/PoseEstimation
网盘地址
链接:https://pan.baidu.com/s/19ncKS8HhwDaYxe2WGlUmNQ?pwd=car0
提取码:car0
目录
- 一、模型的准备
- 二、配置ONNXruntime
- 三、模型的部署
* - 1. 模型的初始化设置
- 2. 构建推理
– - 四、示例应用
- 五、运行结果
* - 1.利用pnp的方式运行的结果
- 2.利用深度学习位姿估计的结果
- 总结
- 参考
一、模型的准备
搭建网络模型训练:
tensorflow keras 搭建相机位姿估计网络–例
网络的输入输出为:
网络的输入: [image_ref , image_cur]
网络的输出: [tx , ty , tz , roll , pitch , yaw]
训练的模型位置: kerasTempModel\,一定要用 model.save()的方式,不能用 model.save_model()
在onnxruntime调用需要onnx模型,这里需要将keras的模型转换为onnx模型;
安装转换的工具:
pip install tf2onnx
安装完后运行:
python -m tf2onnx.convert --saved-model kerasTempModel --output "model.onnx" --opset 14
tip:这里设置 opset 版本为14 的优化效率目前亲测是最好的,推理速度比版本 11 、12更快。
运行后,终端会在最后告诉您网络模型的输入和输出:
[En]
After running, the terminal will tell you the input and output of the network model at the end:
2022-01-21 15:48:00,766 - INFO -
2022-01-21 15:48:00,766 - INFO - Successfully converted TensorFlow model kerasTempModel to ONNX
2022-01-21 15:48:00,766 - INFO - Model inputs: ['input1', 'input2']
2022-01-21 15:48:00,766 - INFO - Model outputs: ['Output']
2022-01-21 15:48:00,766 - INFO - ONNX model is saved at model.onnx
模型有两个输入,输入节点名分别为 ['input1', 'input2'],输出节点名为 ['Output']。
当然也可以不用具体知道节点名,在onnxruntime中可以通过打印来查看模型的输入输出节点名。
二、配置ONNXruntime
CMakeLists.txt:
首先需要设置你的ONNXRUNTIME 的安装位置:
set(ONNXRUNTIME_ROOT_PATH /path to your onnxruntime-master)
set(ONNXRUNTIME_INCLUDE_DIRS ${ONNXRUNTIME_ROOT_PATH}/include/onnxruntime
${ONNXRUNTIME_ROOT_PATH}/onnxruntime
${ONNXRUNTIME_ROOT_PATH}/include/onnxruntime/core/session/)
set(ONNXRUNTIME_LIB ${ONNXRUNTIME_ROOT_PATH}/build/Linux/Release/libonnxruntime.so)
C++ main.cpp中
头文件:
#include
#include
#include
#include
三、模型的部署
1. 模型的初始化设置
string model_path = "../model.onnx";
Ort::Env env(OrtLoggingLevel::ORT_LOGGING_LEVEL_WARNING, "PoseEstimate");
Ort::SessionOptions session_options;
OrtSessionOptionsAppendExecutionProvider_Tensorrt(session_options, 0);
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
Ort::AllocatorWithDefaultOptions allocator;
Ort::Session session(env, model_path.c_str(), session_options);
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
打印模型信息: printModelInfo函数
void printModelInfo(Ort::Session &session, Ort::AllocatorWithDefaultOptions &allocator)
{
size_t num_input_nodes = session.GetInputCount();
size_t num_output_nodes = session.GetOutputCount();
cout<<"Number of input node is:"<<num_input_nodes<<endl;
cout<<"Number of output node is:"<<num_output_nodes<<endl;
for(auto i = 0; i<num_input_nodes;i++)
{
std::vector<int64_t> input_dims = session.GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
cout<<endl<<"input "<<i<<" dim is: ";
for(auto j=0; j<input_dims.size();j++)
cout<<input_dims[j]<<" ";
}
for(auto i = 0; i<num_output_nodes;i++)
{
std::vector<int64_t> output_dims = session.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
cout<<endl<<"output "<<i<<" dim is: ";
for(auto j=0; j<output_dims.size();j++)
cout<<output_dims[j]<<" ";
}
cout<<endl;
for(auto i = 0; i<num_input_nodes;i++)
cout<<"The input op-name "<<i<<" is:"<<session.GetInputName(i, allocator)<<endl;
for(auto i = 0; i<num_output_nodes;i++)
cout<<"The output op-name "<<i<<" is:"<<session.GetOutputName(i, allocator)<<endl;
}
函数应用:
printModelInfo(session,allocator);
输出结果:
Number of input node is:2
Number of output node is:1
input 0 dim is: -1 512 512 3
input 1 dim is: -1 512 512 3
output 0 dim is: -1 6
The input op-name 0 is:input1
The input op-name 1 is:input2
The output op-name 0 is:Output
如果事先不知道网络,可以通过打印信息来定义全局变量:
[En]
If you don’t know the network in advance, you can define global variables by printing information:
static constexpr const int width = 512;
static constexpr const int height = 512;
static constexpr const int channel = 3;
std::array<int64_t, 4> input_shape_{ 1,height, width,channel};
2. 构建推理
构建推理函数computPoseDNN()步骤:
- 对应用Opencv输入的Mat图像进行resize:
Mat Input_1,Input_2;
resize(img_1,Input_1,Size(512,512));
resize(img_2,Input_2,Size(512,512));
- 指定input和output的节点名,当然也可以定义在全局变量中,这里为了方便置入函数中
std::vector<const char*> input_node_names = {"input1","input2"};
std::vector<const char*> output_node_names = {"Output"};
- 分配image_ref和image_cur的内存,用指针数组存储,这里长度为 512 * 512 * 3,因为不能直接把Mat矩阵输入,所以需要数组来存储图像数据,然后再转ONNXRUNTIME专有的tensor类型即可:
std::array<float, width * height *channel> input_image_1{};
std::array<float, width * height *channel> input_image_2{};
float* input_1 = input_image_1.data();
float* input_2 = input_image_2.data();
这里float类型根据自己网络需要来,也有可能是double, 可以利用下面的代码输出网络类型:
cout<
上面的c++代码会输出索引,对应下面的数据类型:
typedef enum ONNXTensorElementDataType {
ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED,
ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT,
ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT8,
ONNX_TENSOR_ELEMENT_DATA_TYPE_INT8,
ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT16,
ONNX_TENSOR_ELEMENT_DATA_TYPE_INT16,
ONNX_TENSOR_ELEMENT_DATA_TYPE_INT32,
ONNX_TENSOR_ELEMENT_DATA_TYPE_INT64,
ONNX_TENSOR_ELEMENT_DATA_TYPE_STRING,
ONNX_TENSOR_ELEMENT_DATA_TYPE_BOOL,
ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT16,
ONNX_TENSOR_ELEMENT_DATA_TYPE_DOUBLE,
ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT32,
ONNX_TENSOR_ELEMENT_DATA_TYPE_UINT64,
ONNX_TENSOR_ELEMENT_DATA_TYPE_COMPLEX64,
ONNX_TENSOR_ELEMENT_DATA_TYPE_COMPLEX128,
ONNX_TENSOR_ELEMENT_DATA_TYPE_BFLOAT16
} ONNXTensorElementDataType;
例如,如果cout 输出 1,那么网络输出类型就是 float;
- 利用循环对float的数组进行赋值:这里可以是 CHW 或者 HWC 的格式:
您可能在培训期间对数据进行了标准化,例如,除以255.0,其中数据恢复需要除以255.0。[En]
You probably normalized the data during the training, for example, divided by 255.0, where the data restore needs to be divided by 255.0.
for (int i = 0; i < Input_1.rows; i++) { for (int j = 0; j < Input_1.cols; j++) { for (int c = 0; c < 3; c++) { if(c==0) input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+2]/255.0; if(c==1) input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+1]/255.0; if(c==2) input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+0]/255.0; } } } for (int i = 0; i < Input_2.rows; i++) { for (int j = 0; j < Input_2.cols; j++) { for (int c = 0; c < 3; c++) { if(c==0) input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+2]/255.0; if(c==1) input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+1]/255.0; if(c==2) input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+0]/255.0; } } }- 这里由于不同网络可能有多个输入节点和多个输出节点,这里需要用std::vector来定义Ort 的tensor;利用两个输入数据创建两个tensor:
其中 input_shape_就是输入的维度:
std::array<int64_t, 4> input_shape_{ 1,512, 512,3}; std::vector<Ort::Value> input_tensors; input_tensors.push_back(Ort::Value::CreateTensor<float>( memory_info, input_1, input_image_1.size(), input_shape_.data(), input_shape_.size())); input_tensors.push_back(Ort::Value::CreateTensor<float>( memory_info, input_2, input_image_2.size(), input_shape_.data(), input_shape_.size()));- 前向推理:
同样定义输出的tensor也为 vector,保证通用性
std::vector<Ort::Value> output_tensors; output_tensors = session.Run(Ort::RunOptions { nullptr }, input_node_names.data(), input_tensors.data(), input_tensors.size(), output_node_names.data(), output_node_names.size());- 输出结果获取:
由于本例输出只有一个维度,所以只需要output_tensors[0]即可取出结果:
float* output = output_tensors[0].GetTensorMutableData<float>();之后再进行位姿重构:
Eigen::Vector3d t(output[0],output[1],output[2]);
Eigen::Vector3d r(output[3],output[4],output[5]);
Eigen::AngleAxisd R_z(r[2], Eigen::Vector3d(0,0,1));
Eigen::AngleAxisd R_y(r[1], Eigen::Vector3d(0,1,0));
Eigen::AngleAxisd R_x(r[0], Eigen::Vector3d(1,0,0));
Eigen::Matrix3d R_matrix_xyz = R_z.toRotationMatrix()*R_y.toRotationMatrix()*R_x.toRotationMatrix();
return Sophus::SE3(R_matrix_xyz,t);
函数具体代码:
Sophus::SE3 computePoseDNN(Mat img_1, Mat img_2, Ort::Session &session,Ort::MemoryInfo &memory_info)
{
Mat Input_1,Input_2;
resize(img_1,Input_1,Size(512,512));
resize(img_2,Input_2,Size(512,512));
std::vector<const char*> input_node_names = {"input1","input2"};
std::vector<const char*> output_node_names = {"Output"};
std::array<float, width * height *channel> input_image_1{};
std::array<float, width * height *channel> input_image_2{};
float* input_1 = input_image_1.data();
float* input_2 = input_image_2.data();
for (int i = 0; i < Input_1.rows; i++) {
for (int j = 0; j < Input_1.cols; j++) {
for (int c = 0; c < 3; c++)
{
if(c==0)
input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+2]/255.0;
if(c==1)
input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+1]/255.0;
if(c==2)
input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+0]/255.0;
}
}
}
for (int i = 0; i < Input_2.rows; i++) {
for (int j = 0; j < Input_2.cols; j++) {
for (int c = 0; c < 3; c++)
{
if(c==0)
input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+2]/255.0;
if(c==1)
input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+1]/255.0;
if(c==2)
input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+0]/255.0;
}
}
}
std::vector<Ort::Value> input_tensors;
input_tensors.push_back(Ort::Value::CreateTensor<float>(
memory_info, input_1, input_image_1.size(), input_shape_.data(), input_shape_.size()));
input_tensors.push_back(Ort::Value::CreateTensor<float>(
memory_info, input_2, input_image_2.size(), input_shape_.data(), input_shape_.size()));
std::vector<Ort::Value> output_tensors;
output_tensors = session.Run(Ort::RunOptions { nullptr },
input_node_names.data(),
input_tensors.data(),
input_tensors.size(),
output_node_names.data(),
output_node_names.size());
float* output = output_tensors[0].GetTensorMutableData<float>();
Eigen::Vector3d t(output[0],output[1],output[2]);
Eigen::Vector3d r(output[3],output[4],output[5]);
Eigen::AngleAxisd R_z(r[2], Eigen::Vector3d(0,0,1));
Eigen::AngleAxisd R_y(r[1], Eigen::Vector3d(0,1,0));
Eigen::AngleAxisd R_x(r[0], Eigen::Vector3d(1,0,0));
Eigen::Matrix3d R_matrix_xyz = R_z.toRotationMatrix()*R_y.toRotationMatrix()*R_x.toRotationMatrix();
return Sophus::SE3(R_matrix_xyz,t);
四、示例应用
#include
#include
#include
#include
#include
#include
#include
Sophus::SE3 computePoseDNN(Mat img_1, Mat img_2, Ort::Session &session, Ort::MemoryInfo &memory_info);
static constexpr const int width = 512;
static constexpr const int height = 512;
static constexpr const int channel = 3;
std::array<int64_t, 4> input_shape_{ 1,height, width,channel};
using namespace cv;
using namespace std;
int main()
{
string model_path = "../model.onnx";
Ort::Env env(OrtLoggingLevel::ORT_LOGGING_LEVEL_WARNING, "PoseEstimate");
Ort::SessionOptions session_options;
OrtSessionOptionsAppendExecutionProvider_Tensorrt(session_options, 0);
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
Ort::AllocatorWithDefaultOptions allocator;
Ort::Session session(env, model_path.c_str(), session_options);
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
printModelInfo(session,allocator);
Mat img_1 = imread("/path_to_your_img1",IMREAD_COLOR);
Mat img_2 = imread("/path_to_your_img2",IMREAD_COLOR);
Sophus::SE3 pose = computePoseDNN(img_1,img_2,session,memory_info);
}
Sophus::SE3 computePoseDNN(Mat img_1, Mat img_2, Ort::Session &session,Ort::MemoryInfo &memory_info)
{
Mat Input_1,Input_2;
resize(img_1,Input_1,Size(512,512));
resize(img_2,Input_2,Size(512,512));
std::vector<const char*> input_node_names = {"input1","input2"};
std::vector<const char*> output_node_names = {"Output"};
std::array<float, width * height *channel> input_image_1{};
std::array<float, width * height *channel> input_image_2{};
float* input_1 = input_image_1.data();
float* input_2 = input_image_2.data();
for (int i = 0; i < Input_1.rows; i++) {
for (int j = 0; j < Input_1.cols; j++) {
for (int c = 0; c < 3; c++)
{
if(c==0)
input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+2]/255.0;
if(c==1)
input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+1]/255.0;
if(c==2)
input_1[i*Input_1.cols*3+j*3+c] = Input_1.ptr<uchar>(i)[j*3+0]/255.0;
}
}
}
for (int i = 0; i < Input_2.rows; i++) {
for (int j = 0; j < Input_2.cols; j++) {
for (int c = 0; c < 3; c++)
{
if(c==0)
input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+2]/255.0;
if(c==1)
input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+1]/255.0;
if(c==2)
input_2[i*Input_2.cols*3+j*3+c] = Input_2.ptr<uchar>(i)[j*3+0]/255.0;
}
}
}
std::vector<Ort::Value> input_tensors;
input_tensors.push_back(Ort::Value::CreateTensor<float>(
memory_info, input_1, input_image_1.size(), input_shape_.data(), input_shape_.size()));
input_tensors.push_back(Ort::Value::CreateTensor<float>(
memory_info, input_2, input_image_2.size(), input_shape_.data(), input_shape_.size()));
std::vector<Ort::Value> output_tensors;
output_tensors = session.Run(Ort::RunOptions { nullptr },
input_node_names.data(),
input_tensors.data(),
input_tensors.size(),
output_node_names.data(),
output_node_names.size());
float* output = output_tensors[0].GetTensorMutableData<float>();
Eigen::Vector3d t(output[0],output[1],output[2]);
Eigen::Vector3d r(output[3],output[4],output[5]);
Eigen::AngleAxisd R_z(r[2], Eigen::Vector3d(0,0,1));
Eigen::AngleAxisd R_y(r[1], Eigen::Vector3d(0,1,0));
Eigen::AngleAxisd R_x(r[0], Eigen::Vector3d(1,0,0));
Eigen::Matrix3d R_matrix_xyz = R_z.toRotationMatrix()*R_y.toRotationMatrix()*R_x.toRotationMatrix();
return Sophus::SE3(R_matrix_xyz,t);
}
void printModelInfo(Ort::Session &session, Ort::AllocatorWithDefaultOptions &allocator)
{
size_t num_input_nodes = session.GetInputCount();
size_t num_output_nodes = session.GetOutputCount();
cout<<"Number of input node is:"<<num_input_nodes<<endl;
cout<<"Number of output node is:"<<num_output_nodes<<endl;
for(auto i = 0; i<num_input_nodes;i++)
{
std::vector<int64_t> input_dims = session.GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
cout<<endl<<"input "<<i<<" dim is: ";
for(auto j=0; j<input_dims.size();j++)
cout<<input_dims[j]<<" ";
}
for(auto i = 0; i<num_output_nodes;i++)
{
std::vector<int64_t> output_dims = session.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
cout<<endl<<"output "<<i<<" dim is: ";
for(auto j=0; j<output_dims.size();j++)
cout<<output_dims[j]<<" ";
}
cout<<endl;
for(auto i = 0; i<num_input_nodes;i++)
cout<<"The input op-name "<<i<<" is:"<<session.GetInputName(i, allocator)<<endl;
for(auto i = 0; i<num_output_nodes;i++)
cout<<"The output op-name "<<i<<" is:"<<session.GetOutputName(i, allocator)<<endl;
}
五、运行结果
1.利用pnp的方式运行的结果
处理速度:43ms
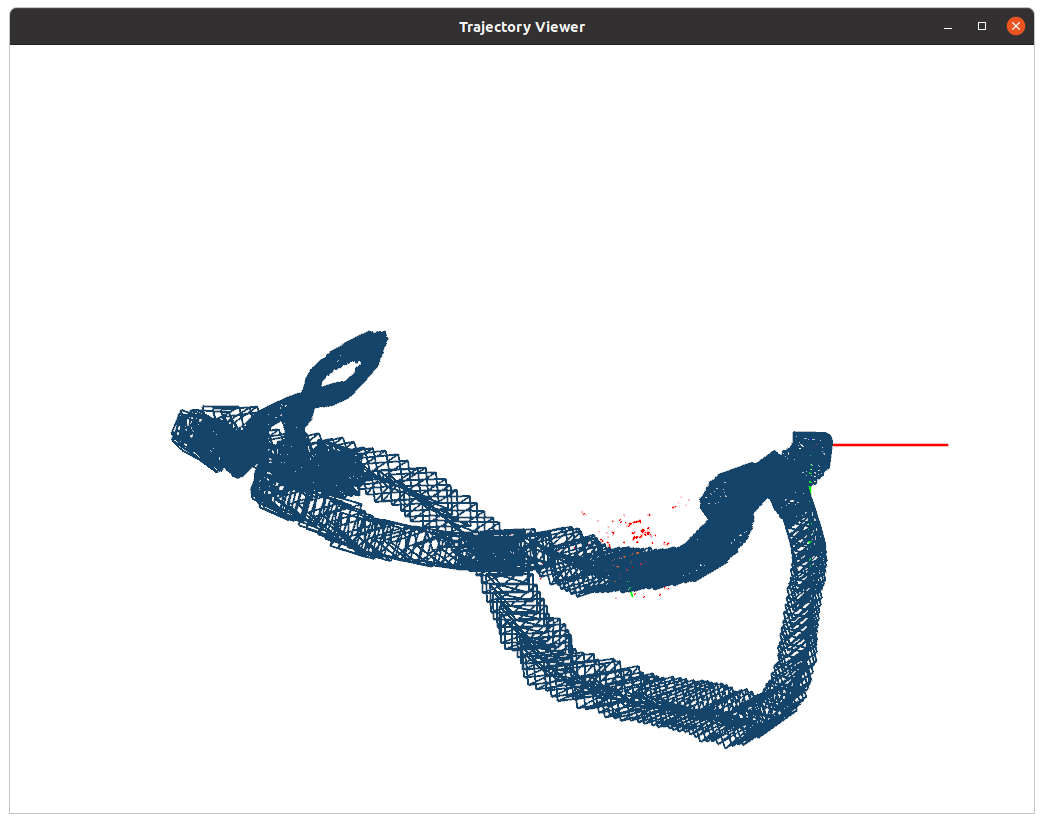

; 2.利用深度学习位姿估计的结果
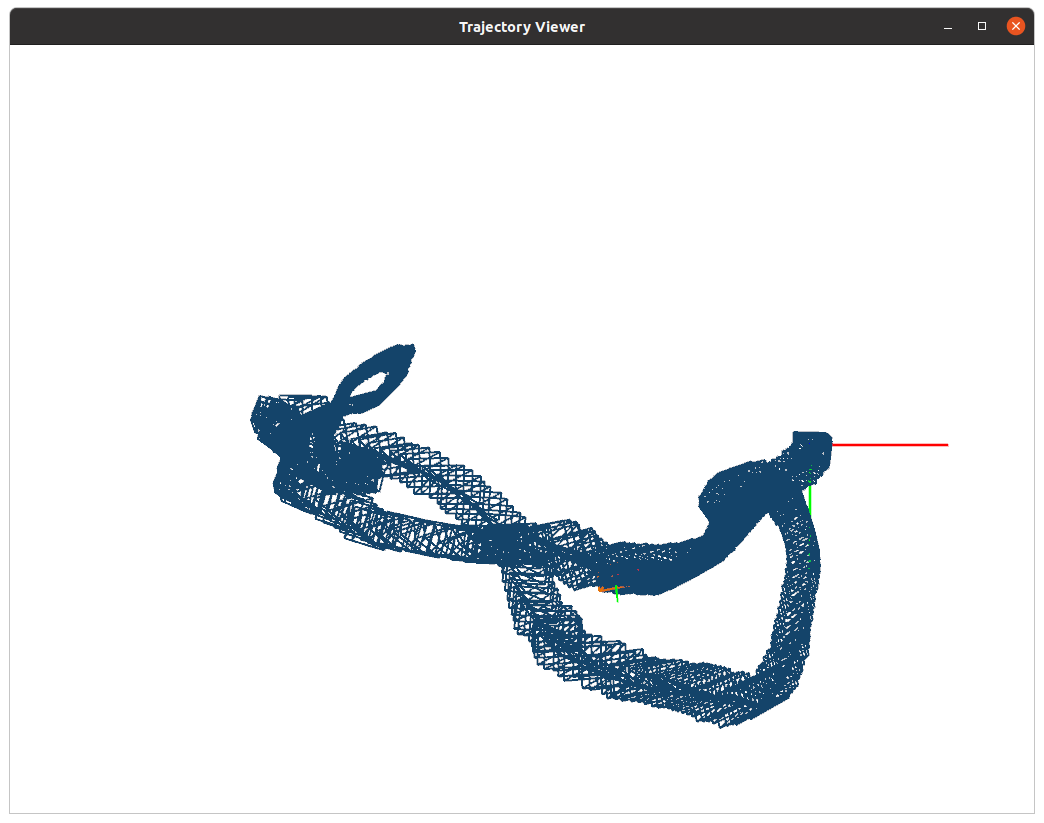
总结
很明显,快了!!
参考
在C++上利用onnxruntime (CUDA)和 opencv 部署模型onnx
Original: https://blog.csdn.net/qq_42995327/article/details/122622222
Author: 机器人学渣
Title: C++ 上用 ONNXruntime 部署自己的模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/496170/
转载文章受原作者版权保护。转载请注明原作者出处!