

一、什么是分桶表
分桶表,比普通表或者分区表有着更为细粒度的数据划分。
举个例子,每天产生的日志可以建立分区表,每个分区在 hdfs 上就是一个目录,这个目录下包含了当天的所有日志记录。
而分桶表,可以进一步对当天的日志按用户划分成多个文件。划分的依据是用户 id 取 hash,然后对分桶数量求余,每个分桶文件在 hdfs 上是一个独立的文件。
二、什么时候可以使用分桶表
分桶表最主要的使用场景是优化大表和大表的 join,其主要原理如下:
(1)如果大表和大表使用 MapReduce 的普通模式,会在 reduce 端 shuffle,那就非常可怕,一个是慢,另一个是容易出异常;
(2)而分桶表将大表的数据划分成一个个小块,分别在 Map 端做 join。
之所以可以这样,是因为分桶表在建表的时候,需要指定分桶的字段,对这个字段值取 hash 后对桶的个数取余数获得一个值,根据这个值将数据放到不同的桶里去。
相同 key 的数据都在一个桶里,在表和表关联的时候就不需要去扫描整个表,只需要去扫描对应桶里的数据即可。
(3)由于不同的数据落到哪个桶是由分桶个数决定的,所以做 Join 的两个分桶表的桶个数必须是相等或者成倍数;
(4)分桶表的每个桶必须要排序,这样可以更高效的做 map join。
这样的 join 称为 SMB map join (Sort Merge Bucket Map Join),核心思想是大表化成小表,分而治之。
三、建立分桶表
分桶表的语法如下:
create table user_order_bucket (
id bigint,
name string,
order_date string,
goods string,
price double,
cnt bigint
)
CLUSTERED BY (name) SORTED BY (name)INTO 5 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS orc;
和普通建表语句不同的是,使用下面的语句来指定分桶字段和分桶个数:
CLUSTERED BY (name ) INTO 5 BUCKETS
建好之后,需要执行一个 insert into 语句,执行一个 MapReduce 把原始表的数据划分到分桶表的不同桶中。
下面 user_order 是原始表,是 orc 格式,有 250w 数据,只有一个文件,30M。
insert overwrite table user_order_bucket select * from user_order;
执行之后,分桶表的 hdfs 如下:


可以看到每个分桶是一个文件,每个文件大概 5-6M
四、使用分桶表来优化 join
下面的开关需要打开以支持分桶表
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
然后执行一个 join 的 SQL 来验证
select t1.name,
t1.order_date
from user_order_bucket t1
join user_order_bucket2 t2
on t1.name = t2.name
首先是未开启以上三个参数的执行计划,这里不贴执行计划了,是正常的 MapReduce;
开启了以上三个参数后,发现是走的 Sorted Merge Bucket Map Join 了。
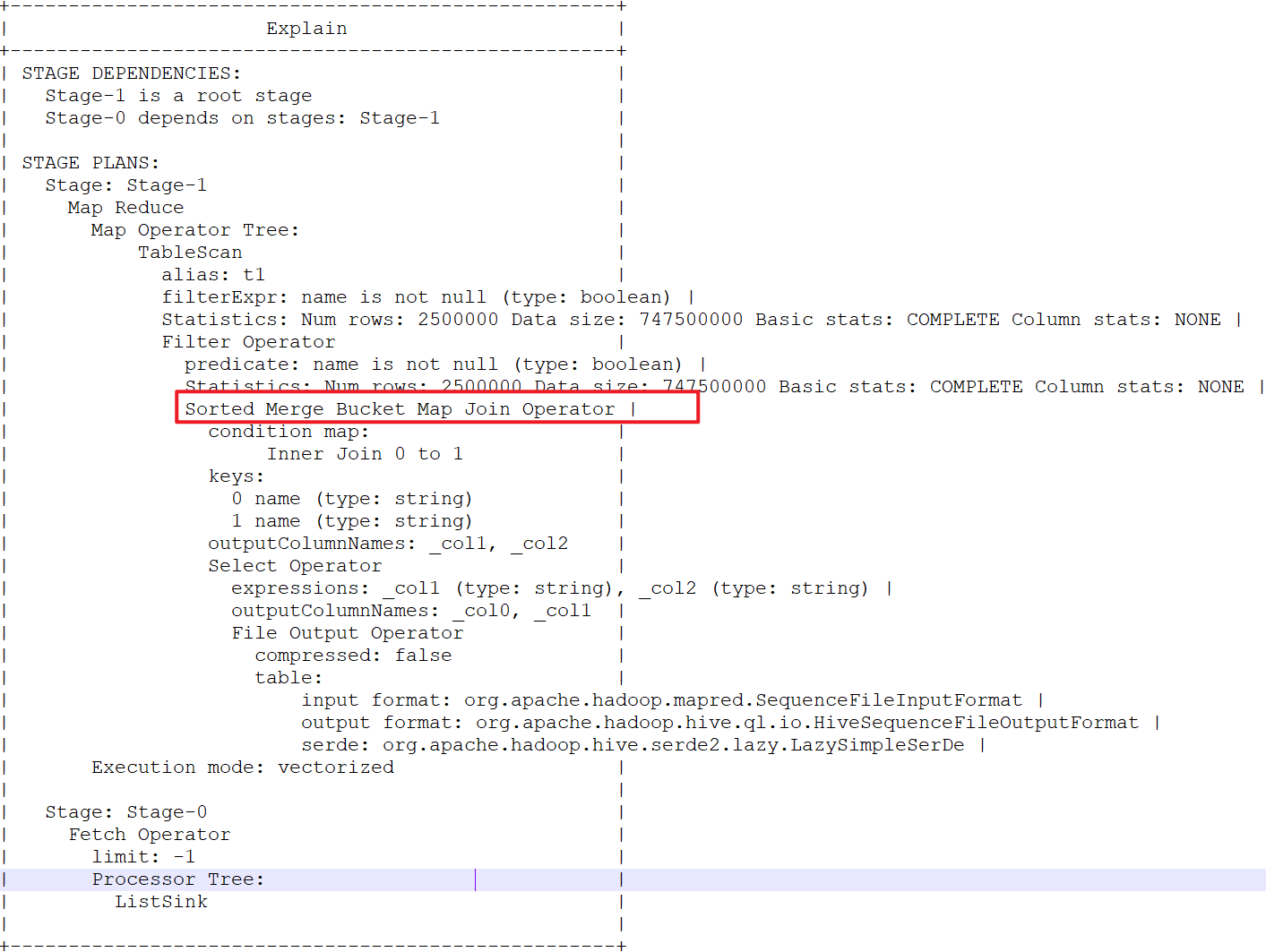
来执行一下看一下效果,把执行结果写入到另一个临时表中
insert overwrite table user_order_result
select t1.name,
t1.order_date
from user_order_bucket t1
join user_order_bucket2 t2
on t1.name = t2.name;
由于本人的集群比较low,一共就 3G内存,6个 cpu
直接跑 MapReduce 的耗时为:
568,967,965 rows affected (590.048 seconds)
使用分桶表 map join 的耗时为:
568,967,965 rows affected (425.187 seconds)
效果不是特别显著,数据量越大,使用分桶表 map join 的效果越好。
Original: https://blog.csdn.net/qq_24434251/article/details/124520049
Author: KK架构
Title: Hive 分桶表原理及优化大表 join 实战
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/818100/
转载文章受原作者版权保护。转载请注明原作者出处!