

背景
我们的埋点数据上传到S3,大概是每天10亿条的数据量级别。最近花了一些时间思考和学习如何将每天如此大量的数据从S3导入到Clickhouse,为后续的实时查询做准备。
方案一
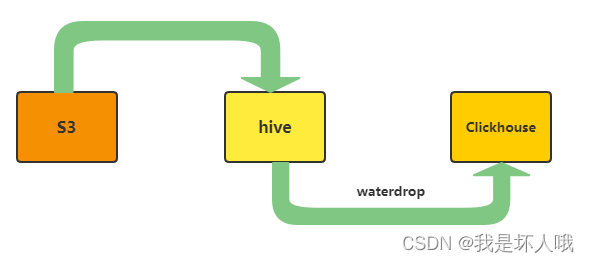

- 先将S3的数据导入到hive,这一步操作比较简单,创建一个外部表即可,按日期字段进行分区。
CREATE TABLE s3_to_hive_test(
id ,
aaa ,
bbb ,
ccc ,
ddd ,
...... )
PARTITIONED BY (
ingestion_date string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://host/bucket/path'
TBLPROPERTIES (
'last_modified_by'='hadoop',
'last_modified_time'='1625729438',
'parquet.column.index.access'='true',
'spark.sql.create.version'='2.2 or prior',
'spark.sql.sources.schema.numPartCols'='1',
'spark.sql.sources.schema.numParts'='1',
'spark.sql.sources.schema.part.0'='{......}',
'spark.sql.sources.schema.partCol.0'='ingestion_date')
- 每天定时从hive把前一天的数据导入到Clickhouse,这里可以借助waterdrop(现改名为seatunnel)工具进行导入,定时调度可以自己写一个shell脚本,如果导入后还需要进行数据清洗、聚合等,推荐DolphinScheduler。
#waterdrop的config文件
spark {
spark.app.name = "Waterdrop"
spark.executor.cores = 1
spark.executor.memory = "2g" // 这个配置必需填写,否则会使用 sparksql 内置元数据库
spark.default.parallelism = 12
spark.driver.memory = "64g"
spark.sql.catalogImplementation = "hive"
}
input {
hive {
pre_sql = "select id,aaa,bbb,ccc,ddd,...... from default.s3_to_hive_test where ......"
table_name = "waterdrop_tmp"
}
}
filter {
}
output {
clickhouse {
host = "ch_host:ch_port"
database = "default"
username = "***"
password = "******"
table = "ch_mergetree_test"
bulk_size = 200000
retry = 3
fields =
[ id ,
aaa ,
bbb ,
ccc ,
ddd ,
...... ]
}
}
- 导入后的清洗、聚合等操作。
适用场景:
绝大多数的场景都适用,之前我们项目也是采用此方案。目前由于引入K8S进行管理,hive、Spark、waterdrop、DolphinScheduler分属不同容器,要处理太多网络通信的问题,故改用更为简单的方案三。
方案二
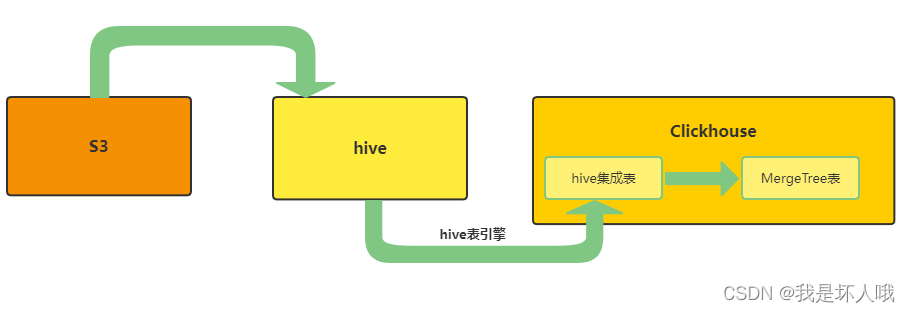
- 如方案一,先将S3的数据以外部表的方式导入到hive中并按日期分区。
CREATE TABLE s3_to_hive_test(
id ,
aaa ,
bbb ,
ccc ,
ddd ,
...... )
PARTITIONED BY (
ingestion_date string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://host/bucket/path'
TBLPROPERTIES (
'last_modified_by'='hadoop',
'last_modified_time'='1625729438',
'parquet.column.index.access'='true',
'spark.sql.create.version'='2.2 or prior',
'spark.sql.sources.schema.numPartCols'='1',
'spark.sql.sources.schema.numParts'='1',
'spark.sql.sources.schema.part.0'='{......}',
'spark.sql.sources.schema.partCol.0'='ingestion_date')
- Clickhouse建立hive集成表
CREATE TABLE IF NOT EXISTS hive_to_ch_test
(
id String NULL,
aaa String NULL,
bbb String NULL,
ccc String NULL,
ddd String NULL,
......
) ENGINE = Hive('thrift://host:port', 'database', 'table');
PARTITION BY ingestion_date
- Clickhouse内部将hive集成表的数据导入到MergeTree表
insert into ch_mergetree_test(
id ,
aaa ,
bbb ,
ccc ,
ddd ,
...... )
SELECT
id,
ifNull(aaa, ''),
ifNull(bbb, ''),
ifNull(ccc, ''),
ifNull(ddd, ''),
......
FROM hive_to_ch_test
WHERE ......
- 后续的数据清洗、聚合等操作
在实测中,Clickhouse到22.4版本为止似乎还不支持hive集成表的底层存储为S3这种形式。具体表现为能建立hive集成表,但查询的时候报以下错误:
Query id: bfeb2774-eb2b-4b2c-9230-64bd6d35acfe
0 rows in set. Elapsed: 0.013 sec.
Received exception from server (version 22.4.5):
Code: 210. DB::Exception: Received from localhost:9000. DB::Exception: Unable to connect to HDFS: InvalidParameter: Cannot parse URI: hdfs://****, missing port or invalid HA configuration Caused by: HdfsConfigNotFound: Config key: dfs.ha.namenodes.**** not found. (NETWORK_ERROR)
但支持底层为HDFS,如下图所示。(注意:如HDFS是HA模式,需要参考官方文档进行一些额外的配置,否则也会报以上错误)
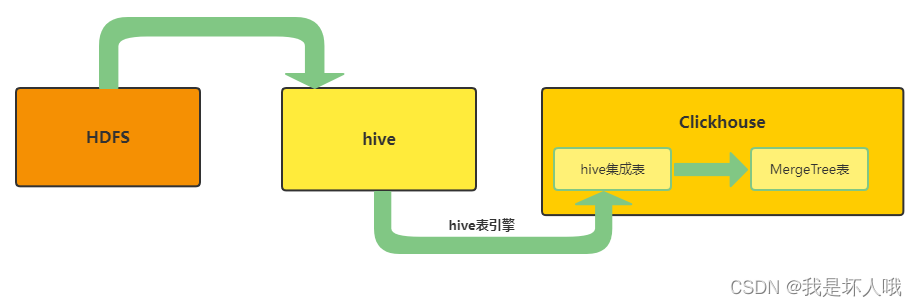 适用场景:
适用场景:
Clickhouse版本必须高于22.1,因为hive集成表引擎是在22.1版本才发布的。详见Clickhouse ChangeLog
方案三
大道至简,直接省略S3导入到Hive这个步骤。

- 建立S3集成表
DROP TABLE IF EXISTS s3_to_ch_test ;
CREATE TABLE s3_to_ch_test (
id String NULL,
aaa String NULL,
bbb String NULL,
ccc String NULL,
ddd String NULL,
...... )
ENGINE=S3(concat('https://s3_host/bucket/path/*' ),'accessKey','secretKey', 'Parquet')
SETTINGS input_format_parquet_allow_missing_columns=true ;
- Clickhouse内部将数据从S3集成表导入MergeTree表
insert into ch_mergetree_test(
id ,
aaa ,
bbb ,
ccc ,
ddd ,
...... )
SELECT
id,
ifNull(aaa, ''),
ifNull(bbb, ''),
ifNull(ccc, ''),
ifNull(ddd, ''),
......
FROM s3_to_ch_test
WHERE ......
- 后续的数据清洗、集成等操作
当然,在具体实施过程,还是会遇到一些坑。
坑一、超出内存限制
由于我们在S3中存储的文件格式是Parquet类型,Parquet是面向分析型业务的列式存储格式,Clickhouse在处理Parquet文件是内存密集型的。我尝试将output_format_parquet_row_group_size 参数调小,但没有任何作用,仍报上述异常。猜测Clickhouse在查询数据时并不是按文件一个个读取并插入的,而是将所有文件的列为单位装到内存中。因为我单个文件最大也才10G,分配了50G内存仍超出内存。
解决方案:调大内存限制 的值。
方式1. 临时设置(仅对当前session有效):
set max_memory_usage=150000000000;
select * from system.settings where name='max_memory_usage';
方式2. 修改/etc/clickhouse-server/users.xml文件(长期有效)
<max_memory_usage>150000000000</max_memory_usage>
坑二、效率问题
解决方案1:加大内存
内存100G的情况下,实测10亿条数据导入到MergeTree表消耗时间4300+ Sec,加到150G消耗时间3800+ Sec。
解决方案2:增加线程数
当内存150G,max_insert_threads=1时,耗时3837s


当内存150G,max_insert_threads=3时,耗时1407s

当内存150G,max_insert_threads=4时,超出内存限制!!

虽然增加线程数对导入效率会有明显提升,但不意味着线程数越多越好,因为高线程数是以高内存为代价的,需要根据服务器内存和导入数据量的情况,平衡好max_memory_usage和max_insert_threads的关系。
Original: https://blog.csdn.net/m0_37795099/article/details/125382402
Author: 我是坏人哦
Title: Clickhouse 从S3/Hive导入数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/818079/
转载文章受原作者版权保护。转载请注明原作者出处!