

一、Hudi与Hive集成架构
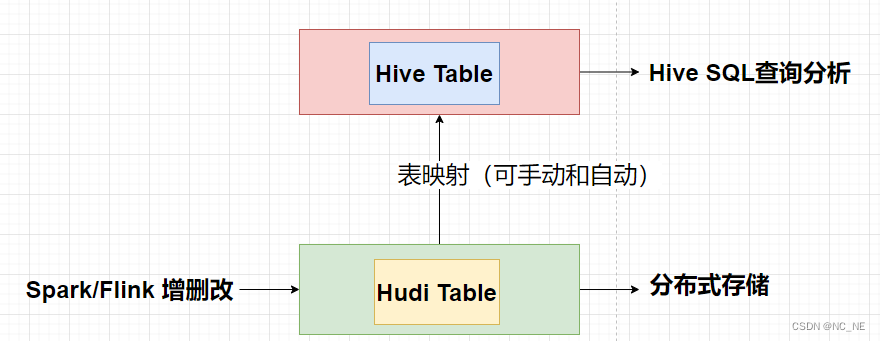

二、环境准备
1、Hive安装 ….(参考)
2、拷贝jar包
将编译好的Hudi目录(hudi-0.9.0/packaging/hudi-hadoop-mr-bundle/target/)下的JAR包: hudi-hadoop-mr-bundle-0.9.0.jar,放入hive安装文件的lib目录下
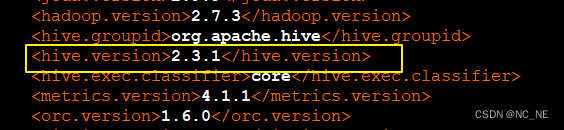
说明:我编译的hudi-0.9.0版本,里面的hive版本是2.3.1没有做修改
3、重启hive两个服务metastore和hiveserver2
bin/hive --service metastore
bin/hive --service hiveserver2
可以后台启动这两服务
nohup ./bin/hive --service metastore &
nohup ./bin/hive --service hiveserver2 &
三、手动将Huid表的数据同步到Hive
1、将外部数据写入hudi
1)、数据格式
order_id product_id city_id district county type combo_type traffic_type passenger_count driver_product_id start_dest_distance arrive_time departure_time pre_total_fee normal_time bubble_trace_id product_1level dest_lng dest_lat starting_lng starting_lat year month day
17592880231474 3 83 0898 460106 0 0 0 0 3 3806 2017-05-26 00:04:47 2017-05-26 00:02:43 11 14 d88a957f7f1ff9fae80a9791103f0303 3 110.3463 20.0226 110.3249 20.0212 2017 05 26
17592880435172 3 83 0898 460106 0 0 0 0 3 3557 2017-05-26 00:16:07 2017-05-26 00:13:12 11 8 a692221c507544783a0519b810390303 3 110.3285 20.0212 110.3133 20.0041 2017 05 26
17592880622846 3 83 0898 460108 0 0 0 0 3 3950 2017-05-26 01:05:53 2017-05-26 01:03:25 12 8 c0a80166cf3529b8a11ef1af10440303 3 110.3635 20.0061 110.3561 20.0219 2017 05 26
17592880665344 3 83 0898 460106 0 0 0 0 3 2265 2017-05-26 00:51:31 2017-05-26 00:48:24 9 6 6446aa1459270ad8255c9d6e26e5ff02 3 110.3172 19.9907 110.3064 20.0005 2017 05 26
17592880763217 3 83 0898 460106 0 0 0 0 3 7171 0000-00-00 00:00:00 2017-05-26 00:55:16 20 NULL 64469e3e59270c7308f066ae2187a102 3 110.3384 20.0622 110.3347 20.0269 2017 05 26
17592880885186 3 83 0898 460107 0 0 0 0 3 8368 2017-05-26 02:00:15 2017-05-26 01:54:26 24 15 6446a13459271a517a8435b41aa8a002 3 110.3397 20.0395 110.3541 19.9947 2017 05 26
17592881134529 3 83 0898 460106 0 0 0 0 3 4304 2017-05-26 03:38:13 2017-05-26 03:33:24 13 NULL 64469e3b59273182744d550020dd6f02 3 110.3608 20.027 110.3435 20.0444 2017 05 26
2)、将数据写入hudi表
object SparkOperatorHudiCOW {
def main(args: Array[String]): Unit = {
val spark = SparkUtils.createSparkSessionEnableHive(this.getClass)
//1、加载外部数据
val path: String = "file:///G:/bigdata-parent/bigdata-hudi/datas/dwv_order_make_haikou_1.txt"
val df: DataFrame = spark.read
.option("sep", "\\t") // 设置分隔符为制表符
.option("header", "true") // 文件首行为列名称
.option("inferSchema", "true") // 依据数值自动推断数据类型
.csv(path) // 指定文件路径
//2、对数据进行ETL转换操作:指定ts和partition_path列
val insertDF: DataFrame = df
.withColumn("partition_path", concat_ws("-", col("year"), col("month"), col("day"))) //将分区字段设置成yyyy-mm-dd格式
.drop("year", "month", "day") //删除单独的年月日三列数据
.withColumn("ts", unix_timestamp(col("departure_time"), "yyyy-MM-dd HH:mm:ss")) //设置数据合并时所依据主键字段
//3、将数据写入到Huid表,设置为COW模式
val hudiTableName: String = "didi_haikou_cow"
val hudiTablePath: String = "/datas/hudi-warehouse/didi_haikou_cow"
// 导入包
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
// 保存数据
insertDF.write
.mode(SaveMode.Overwrite)
.format("hudi")
.option(TABLE_TYPE.key(), COW_TABLE_TYPE_OPT_VAL) //设置表写出模式,默认cow模式
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的属性值设置
.option(RECORDKEY_FIELD.key(), "order_id")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(PARTITIONPATH_FIELD.key(), "partition_path")
.option(TBL_NAME.key(), hudiTableName)
.save(hudiTablePath)
spark.stop()
}
}
3)、查看HDFS上已经有数据写入了

1)、创建Hive分区外部表
(Hudi表是分区表,分区字段是partition_path,格式为yyyy-MM-dd,数据格式HoodieParquetInputFormat)
create external table didi_haikou_cow(
_hoodie_commit_time string,
_hoodie_commit_seqno string,
_hoodie_record_key string,
_hoodie_partition_path string,
_hoodie_file_name string,
order_id bigint,
product_id int,
city_id int,
district int,
county int,
type int,
combo_type int,
traffic_type int,
passenger_count int,
driver_product_id int,
start_dest_distance int,
arrive_time string,
departure_time string,
pre_total_fee int,
normal_time string,
bubble_trace_id string,
product_1level int,
dest_lng double,
dest_lat double,
starting_lng double,
starting_lat double,
ts bigint)
PARTITIONED BY (partition_path string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION '/datas/hudi-warehouse/didi_haikou_cow';
2)、手动添加分区
alter table hudi_hive.didi_haikou_cow add if not exists partition(partition_path='2017-5-26') location '/datas/hudi-warehouse/didi_haikou_cow/2017-5-26/';
3、查询数据
1)查询报错
这是你创建的Hive表字段类型和Hudi表的类型不匹配导致

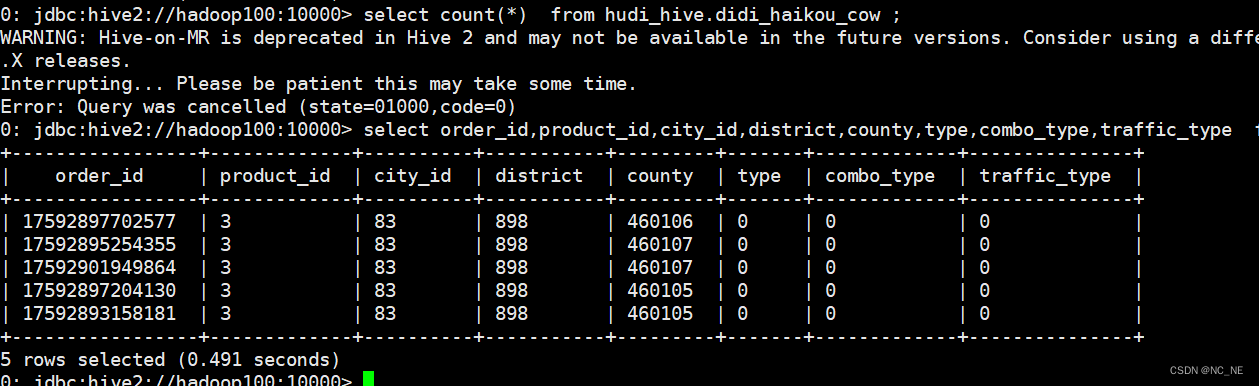
2)、正确查询结果
select order_id,product_id,city_id,district,county,type,combo_type,traffic_type from hudi_hive.didi_haikou_cow limit 5;
四、使用spark代码将数据写入Huid(cow模式)并同步到Hive
1、数据格式
{"ad_id":"9","birthday":"1997-11-16","dn":"webA","dt":"20190722","email":"test@126.com","fullname":"王0","iconurl":"-","lastlogin":"-","mailaddr":"-","memberlevel":"1","password":"123456","paymoney":"-","phone":"13711235451","qq":"10000","register":"2015-04-05","regupdatetime":"-","uid":"0","unitname":"-","userip":"222.42.116.199","zipcode":"-"}
{"ad_id":"5","birthday":"1997-03-08","dn":"webA","dt":"20190722","email":"test@126.com","fullname":"王1","iconurl":"-","lastlogin":"-","mailaddr":"-","memberlevel":"4","password":"123456","paymoney":"-","phone":"13711235451","qq":"10000","register":"2017-10-13","regupdatetime":"-","uid":"1","unitname":"-","userip":"106.92.133.13","zipcode":"-"}
{"ad_id":"1","birthday":"1998-10-18","dn":"webA","dt":"20190722","email":"test@126.com","fullname":"王2","iconurl":"-","lastlogin":"-","mailaddr":"-","memberlevel":"7","password":"123456","paymoney":"-","phone":"13711235451","qq":"10000","register":"2018-03-16","regupdatetime":"-","uid":"2","unitname":"-","userip":"139.200.218.184","zipcode":"-"}
{"ad_id":"2","birthday":"1970-10-27","dn":"webA","dt":"20190722","email":"test@126.com","fullname":"王3","iconurl":"-","lastlogin":"-","mailaddr":"-","memberlevel":"2","password":"123456","paymoney":"-","phone":"13711235451","qq":"10000","register":"2016-08-22","regupdatetime":"-","uid":"3","unitname":"-","userip":"121.77.205.103","zipcode":"-"}
{"ad_id":"3","birthday":"1975-06-16","dn":"webA","dt":"20190722","email":"test@126.com","fullname":"王4","iconurl":"-","lastlogin":"-","mailaddr":"-","memberlevel":"8","password":"123456","paymoney":"-","phone":"13711235451","qq":"10000","register":"2015-08-14","regupdatetime":"-","uid":"4","unitname":"-","userip":"121.77.66.4","zipcode":"-"}
{"ad_id":"9","birthday":"1982-08-17","dn":"webA","dt":"20190722","email":"test@126.com","fullname":"王5","iconurl":"-","lastlogin":"-","mailaddr":"-","memberlevel":"1","password":"123456","paymoney":"-","phone":"13711235451","qq":"10000","register":"2018-12-11","regupdatetime":"-","uid":"5","unitname":"-","userip":"121.77.232.117","zipcode":"-"}
{"ad_id":"0","birthday":"1979-01-07","dn":"webA","dt":"20190722","email":"test@126.com","fullname":"王6","iconurl":"-","lastlogin":"-","mailaddr":"-","memberlevel":"3","password":"123456","paymoney":"-","phone":"13711235451","qq":"10000","register":"2016-01-05","regupdatetime":"-","uid":"6","unitname":"-","userip":"182.80.12.221","zipcode":"-"}
2、代码
/**
* @author oyl
* @create 2022-06-12 21:12
* @Description spark操作cow模式的hudi表并将数据同步到hive
*/
object SparkOperatorHudiCOWSyncHive {
def insertData(sparkSession: SparkSession): Unit = {
import org.apache.spark.sql.functions._
val tableName = "hudi_cow_hive"
val basePath = "/datas/hudi-warehouse/hudi_cow_hive"
val commitTime = System.currentTimeMillis().toString //生成提交时间
val resultDF = sparkSession.read.json("/hudi_test_datas/member.log")
.withColumn("ts", lit(commitTime)) //添加ts时间戳
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn"))) //添加分区 两个字段组合分区
Class.forName("org.apache.hive.jdbc.HiveDriver")
resultDF.write.format("hudi")
.option(TABLE_TYPE.key(), COW_TABLE_TYPE_OPT_VAL) //选择表的类型 到底是MERGE_ON_READ 还是 COPY_ON_WRITE
.option(RECORDKEY_FIELD.key(), "uid") //设置主键
.option(PRECOMBINE_FIELD.key(), "ts") //数据更新时间戳的
.option(PARTITIONPATH_FIELD.key(), "hudipartition") //hudi分区列
.option("hoodie.table.name", tableName) //hudi表名
.option("hoodie.datasource.hive_sync.jdbcurl", "jdbc:hive2://hadoop100:10000") //hiveserver2地址
.option("hoodie.datasource.hive_sync.username","oyl") //登入hiveserver2的用户
.option("hoodie.datasource.hive_sync.password","123123") //登入hiveserver2的密码
.option("hoodie.datasource.hive_sync.database", "hudi_hive") //设置hudi与hive同步的数据库
.option("hoodie.datasource.hive_sync.table", tableName) //设置hudi与hive同步的表名
.option("hoodie.datasource.hive_sync.partition_fields", "dt,dn") //hive表同步的分区列
.option("hoodie.datasource.hive_sync.partition_extractor_class", classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option("hoodie.datasource.hive_sync.enable","true") //设置数据集注册并同步到hive
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.mode(SaveMode.Append)
.save(basePath)
}
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SparkOperatorHudiCOWSyncHive").setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
insertData(sparkSession);
println("将数据以COW模式写入hudi并同步到hive外部表............................")
sparkSession.stop()
}
}
3、执行报错
1)、错误一
Exception in thread "main" java.lang.ClassNotFoundException: org.apache.hive.jdbc.HiveDriver
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
解决:代码添加加载hive驱动,pom添加(对应Hive的版本)依赖
Class.forName("org.apache.hive.jdbc.HiveDriver")
org.apache.hive
hive-exec
2.3.6
org.apache.hive
hive-jdbc
2.3.6
2)、错误二
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.datanucleus.plugin.NonManagedPluginRegistry.createExecutableExtension(NonManagedPluginRegistry.java:606)
at org.datanucleus.plugin.PluginManager.createExecutableExtension(PluginManager.java:330)
at org.datanucleus.store.AbstractStoreManager.registerConnectionFactory(AbstractStoreManager.java:203)
... 99 more
Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BONECP" plugin to create a ConnectionPool gave an error : The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:232)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.initialiseDataSources(ConnectionFactoryImpl.java:117)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.(ConnectionFactoryImpl.java:82)
... 106 more
Caused by: org.datanucleus.store.rdbms.connectionpool.DatastoreDriverNotFoundException: The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
at org.datanucleus.store.rdbms.connectionpool.AbstractConnectionPoolFactory.loadDriver(AbstractConnectionPoolFactory.java:58)
at org.datanucleus.store.rdbms.connectionpool.BoneCPConnectionPoolFactory.createConnectionPool(BoneCPConnectionPoolFactory.java:54)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:213)
解决:pom文件添加mysql依赖
mysql
mysql-connector-java
5.1.27
4、插入数据执行结果
1)、Hdfs里面可以查看到数据
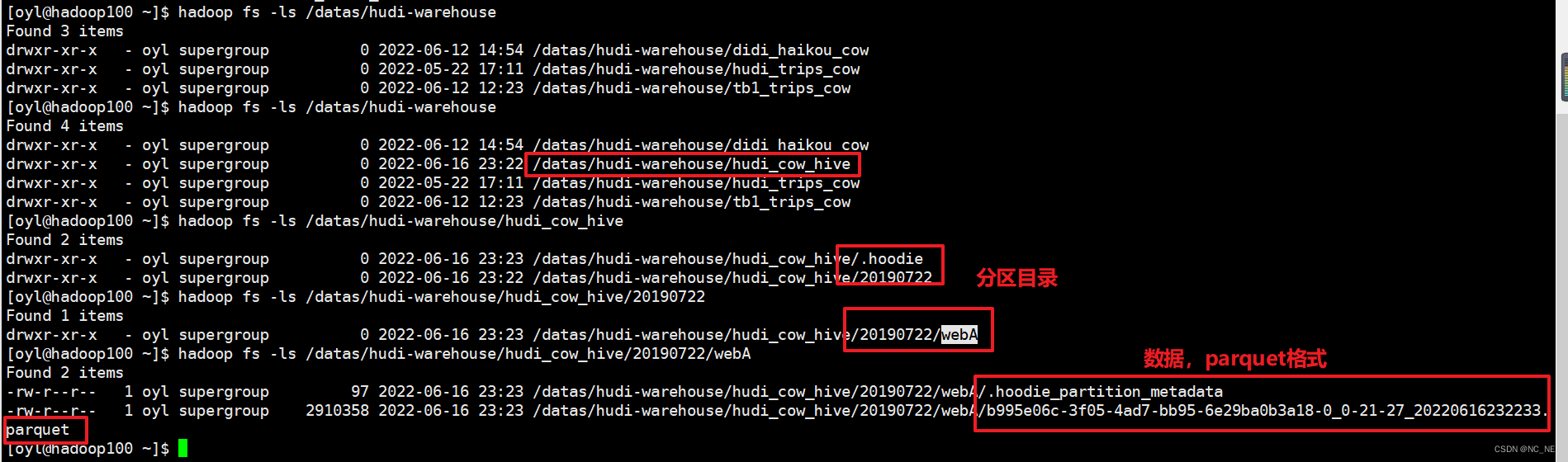
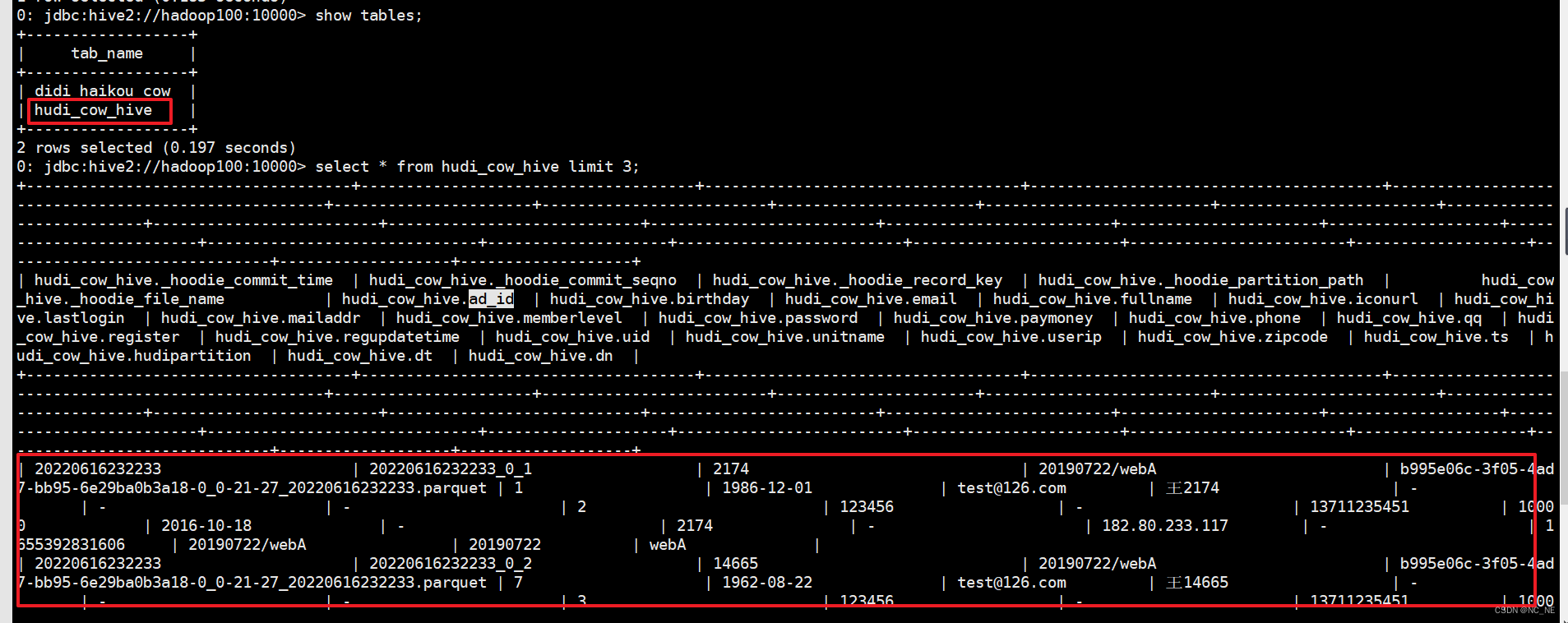
可以看到hive里的建表会采用HoodieParquetInputFormat 格式支持快照查询和增量查询
CREATE EXTERNAL TABLE hudi_cow_hive(
_hoodie_commit_time string,
_hoodie_commit_seqno string,
_hoodie_record_key string,
_hoodie_partition_path string,
_hoodie_file_name string,
ad_id string,
birthday string,
email string,
fullname string,
iconurl string,
lastlogin string,
mailaddr string,
memberlevel string,
password string,
paymoney string,
phone string,
qq string,
register string,
regupdatetime string,
uid string,
unitname string,
userip string,
zipcode string,
ts string,
hudipartition string)
PARTITIONED BY (
dt string,
dn string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'hoodie.query.as.ro.table'='false',
'path'='/datas/hudi-warehouse/hudi_cow_hive')
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://hadoop100:9000/datas/hudi-warehouse/hudi_cow_hive'
TBLPROPERTIES (
'last_commit_time_sync'='20220617224055',
'spark.sql.sources.provider'='hudi',
'spark.sql.sources.schema.numPartCols'='2',
'spark.sql.sources.schema.numParts'='1',
'transient_lastDdlTime'='1655393022')
5、修改数据
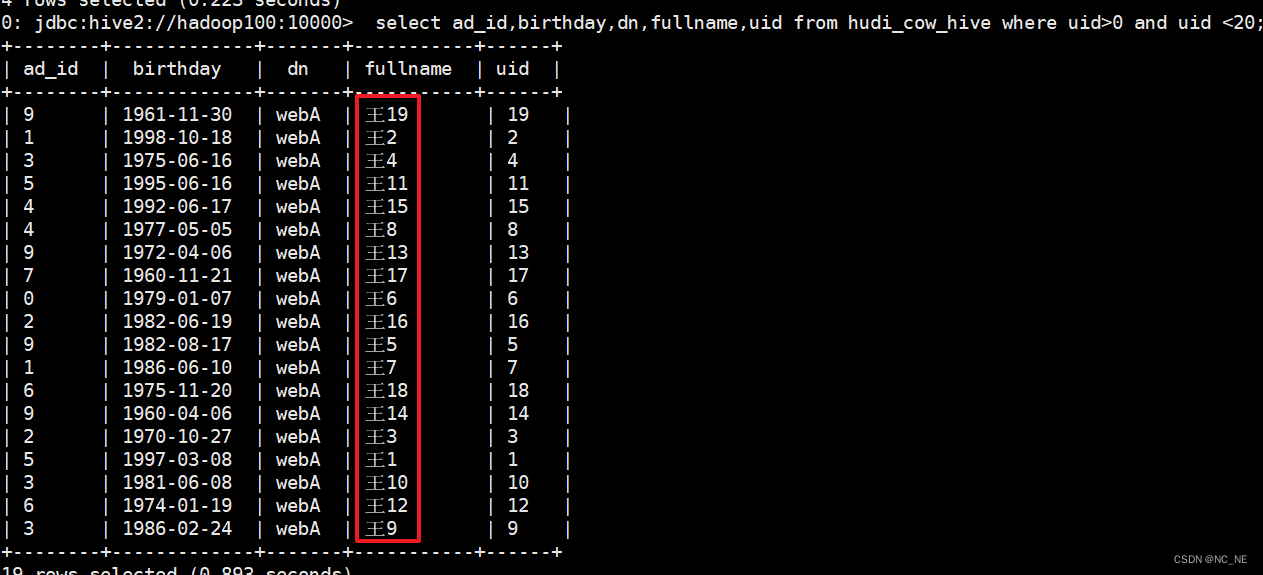
修改uid>0 and uid
1)、修改前的数据
2)、修改数据代码
3)、修改后结果
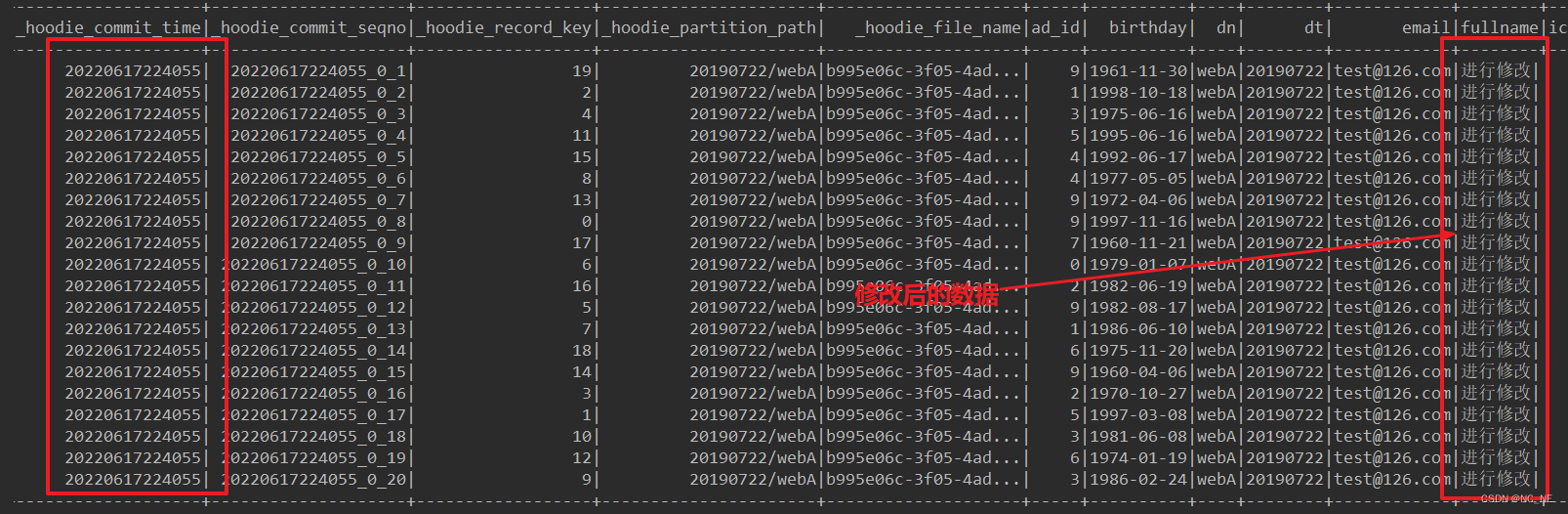
hive查询的是最新的修改数据
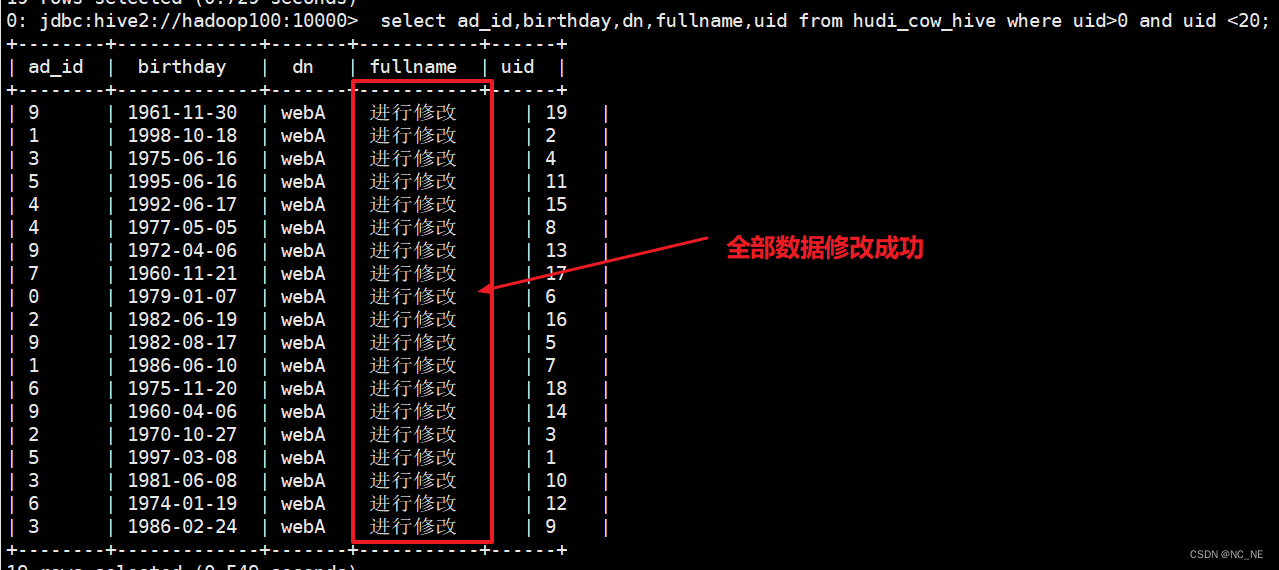
可以看到HDFS上数据成功写入到另一个文件,且文件大小都相同,所以Copy on Write表其实是和旧数据进行合并后再次写入全量数据。这也验证了官方所说的Copy on Write表写入数据延迟高,wa写入大。所以如果这张表是经常需要修改和写入的建议采纳哦使用Merge on Read表。

6、查询修改数据结果
1)、快照查询
/**
* 快照查询,展示uid
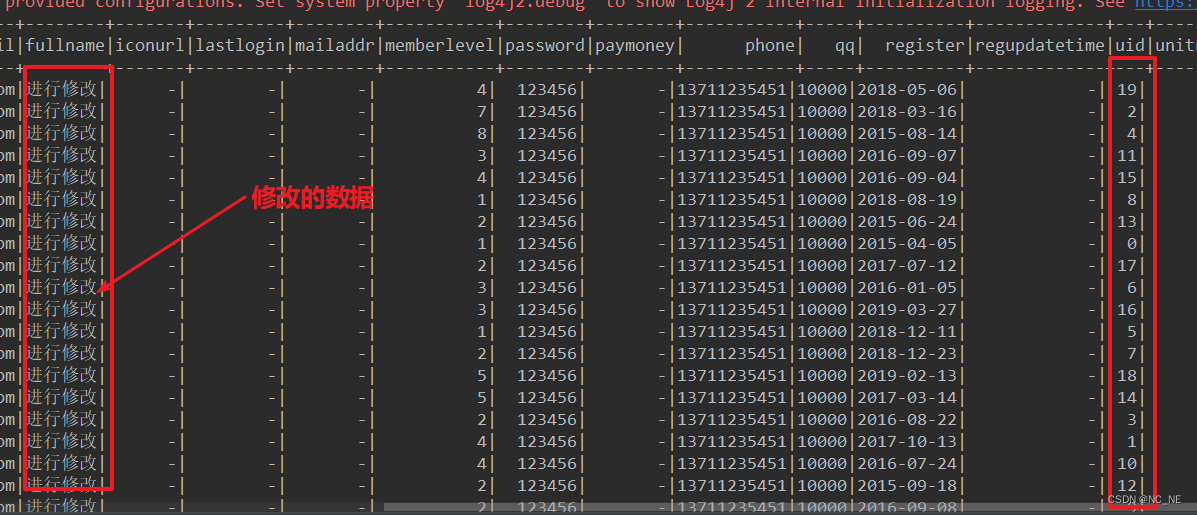
(1)查询前40条数据,分别包含修改的20条数据和未修改的20条数据
可以看到进行修改的数据和原来的数据commit时间戳是不一样的
/**
* 增量查询,查询前40条数据,分别包含修改的20条数据和未修改的20条数据
*/
def queryData2(sparkSession: SparkSession) = {
sparkSession.sql("set spark.sql.hive.convertMetastoreParquet=false")
sparkSession.sql("select _hoodie_commit_time,ad_id,birthday,dn,fullname,uid from hudi_hive.hudi_cow_hive where uid>=0 and uid

(2) 时间戳增量查询
指 定查询 类型为增量查询,并且传入时间戳,那么spark会查询时间戳以后的数据。
def queryData3(sparkSession: SparkSession) = {
val df = sparkSession.read.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL) //指定增量查询
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, "20220616232233") //开始时间
//.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY,"") //结束时间
.load("/datas/hudi-warehouse/hudi_cow_hive/")
df.show(20)
}
1、数据格式(同上)
2、代码
/**
* @author oyl
* @create 2022-06-12 21:12
* @Description spark操作mor模式的hudi表并将数据同步到hive
*/
object SparkOperatorHudiMORSyncHive {
def insertData(sparkSession: SparkSession): Unit = {
import org.apache.spark.sql.functions._
val tableName = "hudi_mor_hive"
val basePath = "/datas/hudi-warehouse/hudi_mor_hive"
val commitTime = System.currentTimeMillis().toString //生成提交时间
val resultDF = sparkSession.read.json("/hudi_test_datas/member.log")
.withColumn("ts", lit(commitTime)) //添加ts时间戳
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn"))) //添加分区 两个字段组合分区
Class.forName("org.apache.hive.jdbc.HiveDriver")
resultDF.write.format("hudi")
.option(TABLE_TYPE.key(), MOR_TABLE_TYPE_OPT_VAL) //选择表的类型 到底是MERGE_ON_READ 还是 COPY_ON_WRITE
.option(RECORDKEY_FIELD.key(), "uid") //设置主键
.option(PRECOMBINE_FIELD.key(), "ts") //数据更新时间戳的
.option(PARTITIONPATH_FIELD.key(), "hudipartition") //hudi分区列
.option("hoodie.table.name", tableName) //hudi表名
.option("hoodie.datasource.hive_sync.jdbcurl", "jdbc:hive2://hadoop100:10000") //hiveserver2地址
.option("hoodie.datasource.hive_sync.username","oyl") //登入hiveserver2的用户
.option("hoodie.datasource.hive_sync.password","123123") //登入hiveserver2的密码
.option("hoodie.datasource.hive_sync.database", "hudi_hive") //设置hudi与hive同步的数据库
.option("hoodie.datasource.hive_sync.table", tableName) //设置hudi与hive同步的表名
.option("hoodie.datasource.hive_sync.partition_fields", "dt,dn") //hive表同步的分区列
.option("hoodie.datasource.hive_sync.partition_extractor_class", classOf[MultiPartKeysValueExtractor].getName) // 分区提取器 按/ 提取分区
.option("hoodie.datasource.hive_sync.enable","true") //设置数据集注册并同步到hive
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.mode(SaveMode.Append)
.save(basePath)
}
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SparkOperatorHudiCOWSyncHive").setMaster("local[*]")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
insertData(sparkSession);
println("将数据以MOR模式写入hudi并同步到hive外部表............................")
sparkSession.stop()
}
}
3、插入数据执行结果
1)、hdfs数据
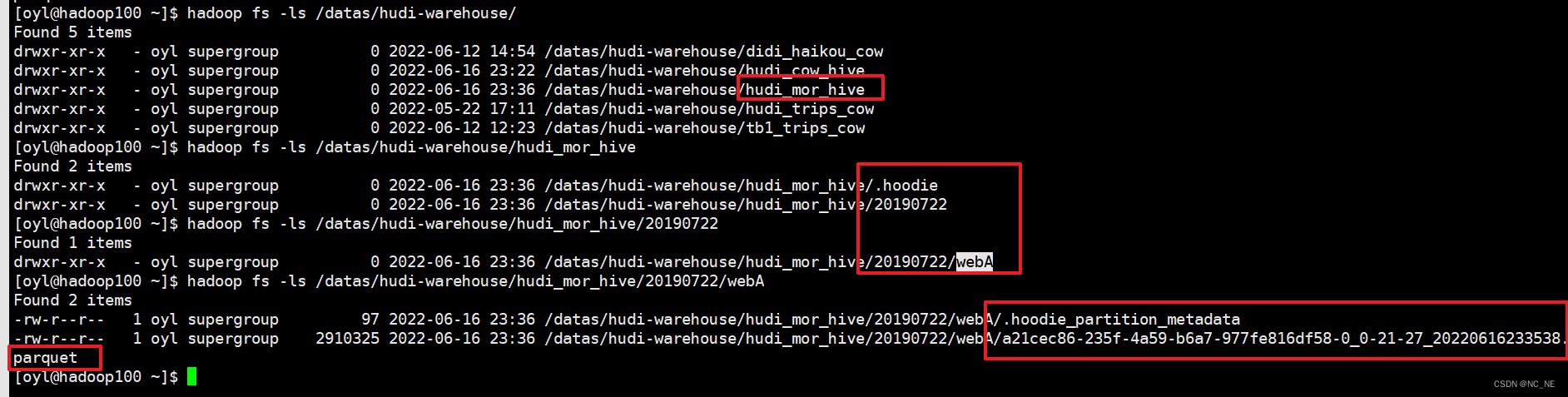
2)、查询hive数据
出现两张表 hudi_mor_hive_ro,hudi_mor_hive_rt
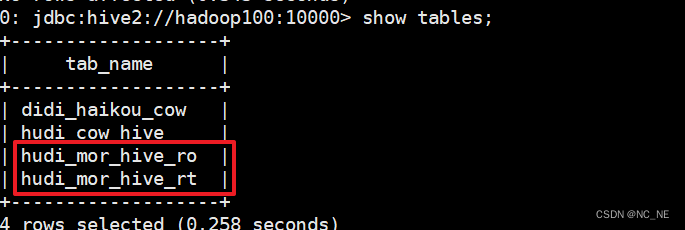
3)、查询hive表结构
rt结尾的表支持快照查询和增量查询,并且rt表将会查询表基本列数据和增量日志数据的合并视图,立马可以查询到修改后的数据。而ro表则只查询表中基本列数据并不会去查询增量日志里的数据。rt表采用HoodieParquetRealtimeInputFormat格式进行存储,ro表采用HoodieParquetInputFormat格式进行存储
CREATE EXTERNAL TABLE hudi_mor_hive_ro(
_hoodie_commit_time string,
_hoodie_commit_seqno string,
_hoodie_record_key string,
_hoodie_partition_path string,
_hoodie_file_name string,
ad_id string,
birthday string,
email string,
fullname string,
iconurl string,
lastlogin string,
mailaddr string,
memberlevel string,
password string,
paymoney string,
phone string,
qq string,
register string,
regupdatetime string,
uid string,
unitname string,
userip string,
zipcode string,
ts string,
hudipartition string)
PARTITIONED BY (
dt string,
dn string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'hoodie.query.as.ro.table'='true',
'path'='/datas/hudi-warehouse/hudi_mor_hive')
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://hadoop100:9000/datas/hudi-warehouse/hudi_mor_hive'
TBLPROPERTIES (
'last_commit_time_sync'='20220618000319',
'spark.sql.sources.provider'='hudi',
'spark.sql.sources.schema.numPartCols'='2',
'spark.sql.sources.schema.numParts'='1',
'transient_lastDdlTime'='1655393789')
CREATE EXTERNAL TABLE hudi_mor_hive_rt(
_hoodie_commit_time string,
_hoodie_commit_seqno string,
_hoodie_record_key string,
_hoodie_partition_path string,
_hoodie_file_name string,
ad_id string,
birthday string,
email string,
fullname string,
iconurl string,
lastlogin string,
mailaddr string,
memberlevel string,
password string,
paymoney string,
phone string,
qq string,
register string,
regupdatetime string,
uid string,
unitname string,
userip string,
zipcode string,
ts string,
hudipartition string)
PARTITIONED BY (
dt string,
dn string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'hoodie.query.as.ro.table'='false',
'path'='/datas/hudi-warehouse/hudi_mor_hive')
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://hadoop100:9000/datas/hudi-warehouse/hudi_mor_hive'
TBLPROPERTIES (
'last_commit_time_sync'='20220618000319',
'spark.sql.sources.provider'='hudi',
'spark.sql.sources.schema.numPartCols'='2',
'spark.sql.sources.schema.numParts'='1',
'transient_lastDdlTime'='1655393790')
4、修改数据
修改uid>0 and uid
1)、修改数据代码
/**
* 修改数据,hudi支持行级更新
*/
def updateData(sparkSession: SparkSession) = {
val tableName = "hudi_mor_hive"
val basePath = "/datas/hudi-warehouse/hudi_mor_hive"
//只查询20条数据,并进行修改,修改这20条数据的fullname值
import org.apache.spark.sql.functions._
val commitTime = System.currentTimeMillis().toString //生成提交时间
//这里修改数据相当于行级别修改
val resultDF = sparkSession.read.json("/hudi_test_datas/member.log")
.withColumn("ts", lit(commitTime)) //添加ts时间戳
.withColumn("hudipartition", concat_ws("/", col("dt"), col("dn")))
.where("uid >=0 and uid
2)、修改后
(1)HDFS文件对比,修改的数据都写入到log文件里面了, 所以Merge on Read发生修改操作,是将变化数据写入行式增量日志


(2)hive表对比
hudi_mor_hive_ro表数据没有变化, 其实or结尾的表对应是读取优化查询,只查询最基本列数据,并不会看到被修改的数据。
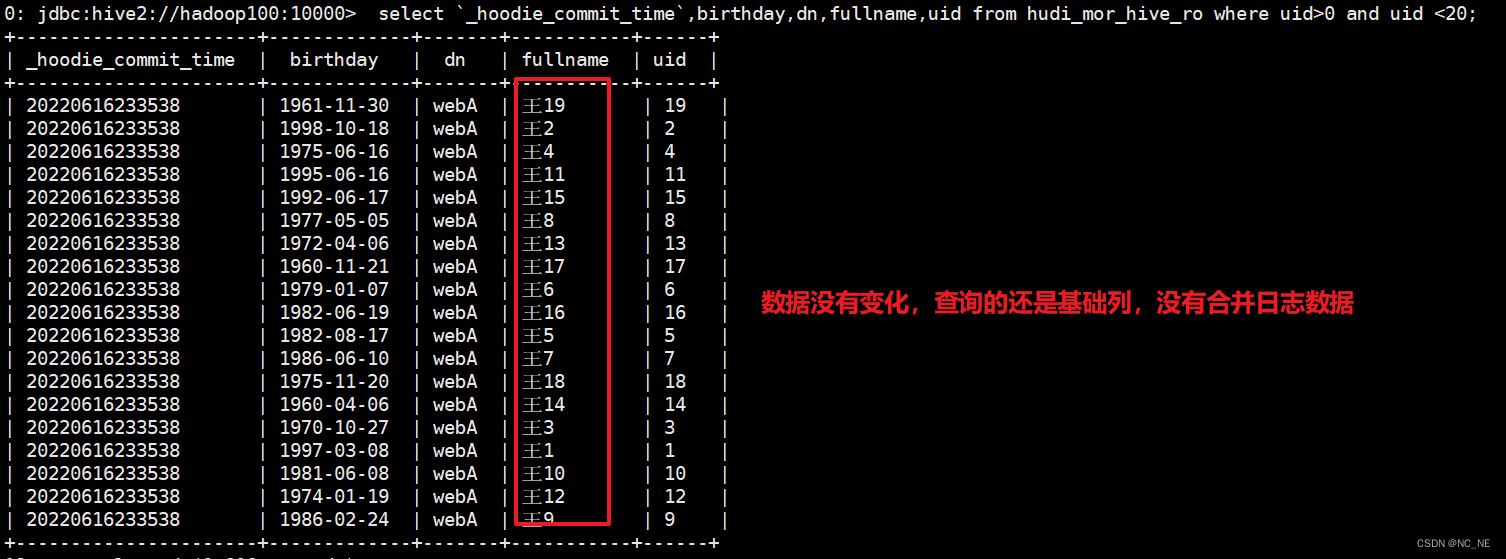
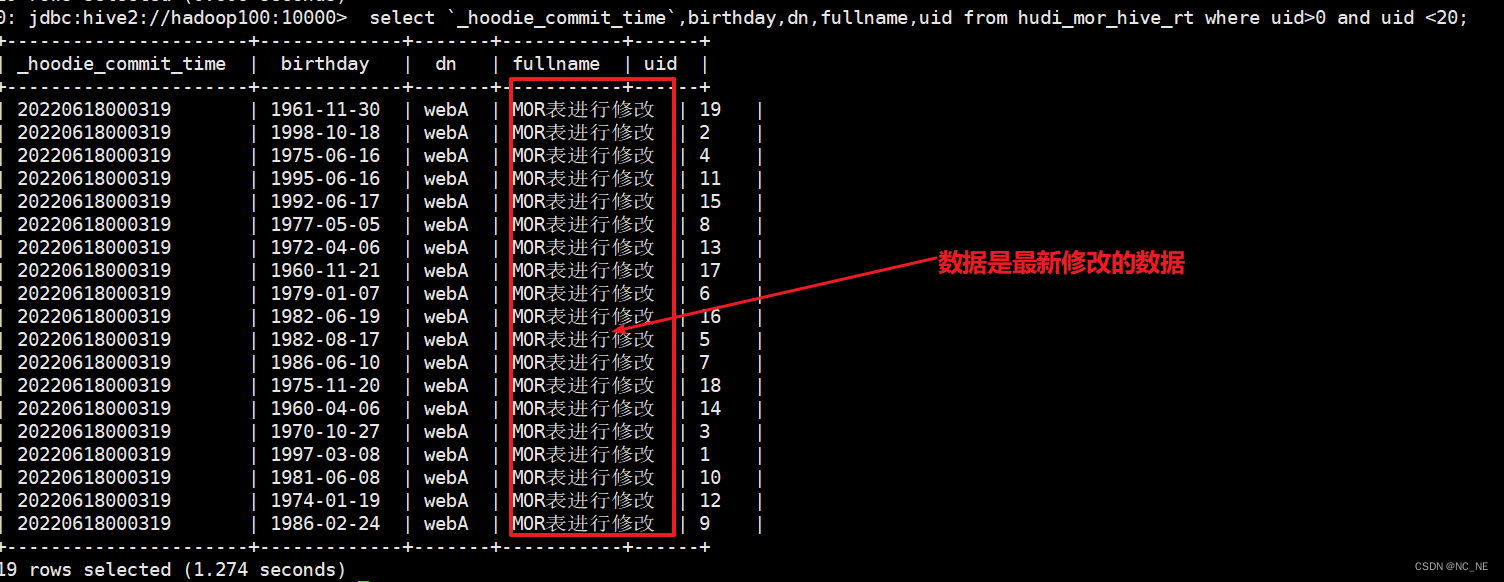
hudi_mor_hive_rt表数据是最新修改的数据(rt结尾的表为最新快照表)
六、代码的POM文件
bigdata-parent
com.ouyangl
1.0-SNAPSHOT
4.0.0
bigdata-hudi
2.12.10
2.12
3.0.0
2.7.3
0.9.0
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${scala.binary.version}
${spark.version}
org.apache.spark
spark-sql_${scala.binary.version}
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.codehaus.janino
janino
3.0.8
org.apache.hudi
hudi-spark3-bundle_2.12
${hudi.version}
org.apache.spark
spark-avro_2.12
${spark.version}
org.apache.hudi
hudi-hadoop-mr-bundle
jackson-databind
com.fasterxml.jackson.core
com.fasterxml.jackson.core
jackson-annotations
0.9.0
provided
org.apache.hive
hive-exec
2.3.6
org.apache.hive
hive-jdbc
2.3.6
org.apache.spark
spark-hive_2.12
3.0.0
mysql
mysql-connector-java
5.1.27
target/classes
target/test-classes
${project.basedir}/src/main/resources
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
Original: https://blog.csdn.net/NC_NE/article/details/125347370
Author: Hub-Link
Title: Hudi学习五:Hudi与Hive集成
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/817490/
转载文章受原作者版权保护。转载请注明原作者出处!