

GenericUDAFEvaluator的方法:
文章目录
*
– GenericUDAFEvaluator的方法:
–
+ 一、介绍
+ 二、UDAF编写步骤
+
* 步骤1:
* 步骤2:
*
– init()方法:
– iterate()方法:
– merge()方法:
– terminate()方法:
– getNewAggregationBuffer()方法:
– reset()方法:
* 步骤3:
HIVE提供了丰富的内置函数,但是对于一些复杂逻辑还是需要自定义函数来实现,对此,HIVE也提供了一些自定义的接口和类。
UDF:一进一出,一对一的关系数据
UDTF:一进多处,一对多的关系数据
UDAF:多进一出,多对一的关系数据
一、介绍
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException;
abstract AggregationBuffer getNewAggregationBuffer() throws HiveException;
public void reset(AggregationBuffer agg) throws HiveException;
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException;
public Object terminatePartial(AggregationBuffer agg) throws HiveException;
public void merge(AggregationBuffer agg, Object partial) throws HiveException;
public Object terminate(AggregationBuffer agg) throws HiveException;
自定义的UDAF的执行逻辑如图:图片信息来自于:https://blog.csdn.net/zyz_home/article/details/79889519
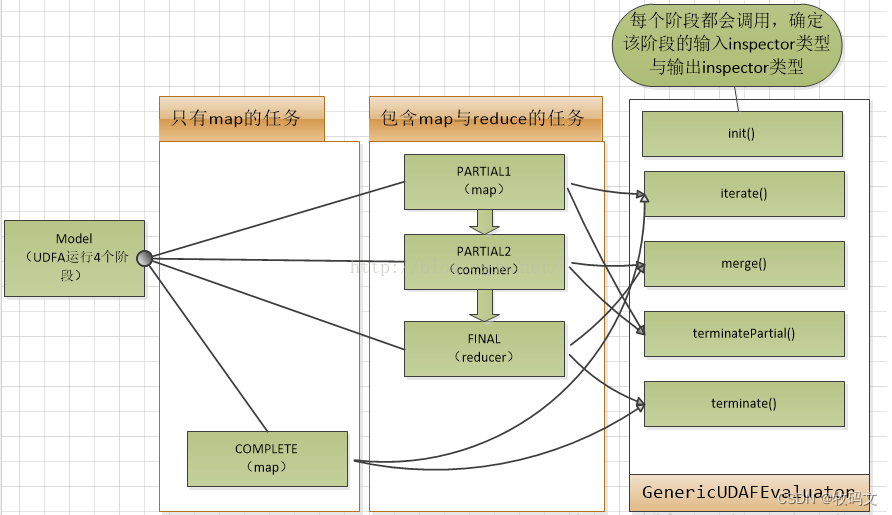

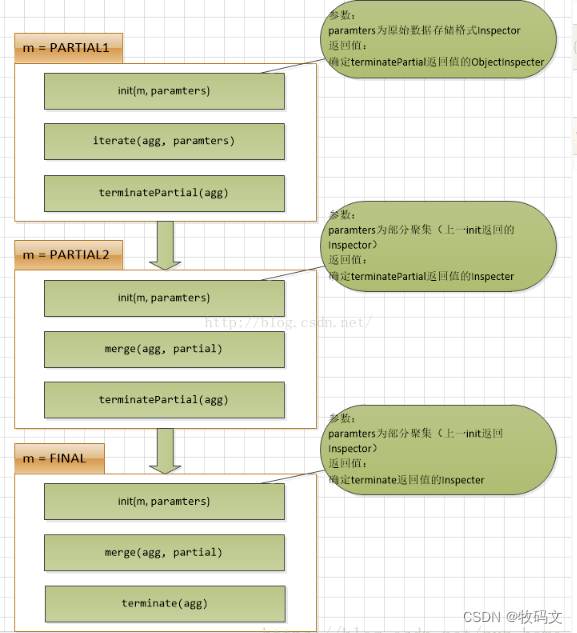
二、UDAF编写步骤
模拟max()函数
步骤1:
自定义缓冲类MaxBuffer,继承类GenericUDAFEvaluator.AbstractAggregationBuffer
public class MaxBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer {
private int ans;
public MaxBuffer(){}
public MaxBuffer(int ans){this.ans = ans;}
public int getAns(){
return ans;
}
public void setAns(int ans){
this.ans = ans;
}
public void add(int next){
ans = Math.max(this.ans, next);
}
}
步骤2:
自定义处理类MaxEvaluator,继承GenericUDAFEvaluator,重写方法
public class MaxEvaluator extends GenericUDAFEvaluator {}
创建三个变量,输入、输出、缓冲区
private PrimitiveObjectInspector in;
private ObjectInspector out;
private PrimitiveObjectInspector buffer;
init()方法:
根据不同的阶段,处理参数
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m,parameters);
if (Mode.PARTIAL1.equals(m) || Mode.COMPLETE.equals(m) ){
in = (PrimitiveObjectInspector) parameters[0];
}else{
buffer = (PrimitiveObjectInspector) parameters[0];
}
out = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
return out;
}
Mode共4个模式
iterate()方法:
每行数据调用一次
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
((MaxBuffer)agg).add((Integer) parameters[0]);
}
terminatePartial()方法:
Partial2阶段会调用,类似于map端的combine,预聚合
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
return terminate(agg);
}
merge()方法:
Partial2阶段和final阶段都会调用,聚合buffer中的数据
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
int in = (int) buffer.getPrimitiveJavaObject(partial);
int ans = ((MaxBuffer) agg).getAns();
((MaxBuffer)agg).add(in);
}
terminate()方法:
final阶段调用,会聚合最终结果
@Override
getNewAggregationBuffer()方法:
得到一个新的缓冲区,会对这一组数据做处理
@Override public AggregationBuffer getNewAggregationBuffer() throws HiveException { return new MaxBuffer(); }
reset()方法:
初始化缓冲区,可置空缓冲区
@Overridepublic void reset(AggregationBuffer agg) throws HiveException { ((MaxBuffer)agg).setAns(0);}
步骤3:
自定义类MaxFunc,继承类AbstractGenericUDAFResolver,重写getEvaluator方法
public class MaxBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer {
// 用于接收结果
private int ans;
public MaxBuffer(){}
public MaxBuffer(int ans){this.ans = ans;}
public int getAns(){
return ans;
}
public void setAns(int ans){
this.ans = ans;
}
public void add(int next){
ans = Math.max(this.ans, next);
}
}
public class MaxEvaluator extends GenericUDAFEvaluator {
private PrimitiveObjectInspector in;
private ObjectInspector out;
private PrimitiveObjectInspector buffer;
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
return new MaxBuffer();
}
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m,parameters);
if (Mode.PARTIAL1.equals(m) || Mode.COMPLETE.equals(m) ){
in = (PrimitiveObjectInspector) parameters[0];
}else{
buffer = (PrimitiveObjectInspector) parameters[0];
}
out = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class, ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
return out;
}
@Override
public void reset(AggregationBuffer agg) throws HiveException {
((MaxBuffer)agg).setAns(0);
}
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
((MaxBuffer)agg).add((Integer) parameters[0]);
}
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
return terminate(agg);
}
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
int in = (int) buffer.getPrimitiveJavaObject(partial);
int ans = ((MaxBuffer) agg).getAns();
((MaxBuffer)agg).add(in);
}
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
return ((MaxBuffer)agg).getAns();
}
}
public class MaxFunc extends AbstractGenericUDAFResolver {
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
return new MaxEvaluator();
}
@Override
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException {
return new MaxEvaluator();
}
}
打包上传集群,测试
create TEMPORARY FUNCTION self_max as 'com.lnnu.udaf.MaxFunc'using jar 'udafmaxv1.jar';with d as ( select 1 as num, 'key' as k union all select 2 as num, 'key' as k)select k, self_max(num)from d group by k
Original: https://blog.csdn.net/weixin_46429290/article/details/126634429
Author: 牧码文
Title: HIVE自定义UDAF函数
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/817356/
转载文章受原作者版权保护。转载请注明原作者出处!