

目录
Hadoop部署
部署组件
一、VMware部署安装
安装VMware之后,才能进行Ubuntu虚拟机的安装和组件部署。
二、Ubuntu18.04.5版本的部署安装
虚拟机安装步骤
图文教程如下
1.,默认自定义
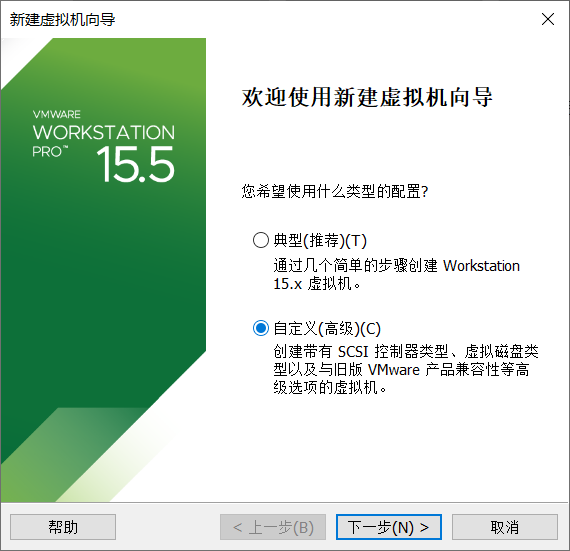

2.点击下一步

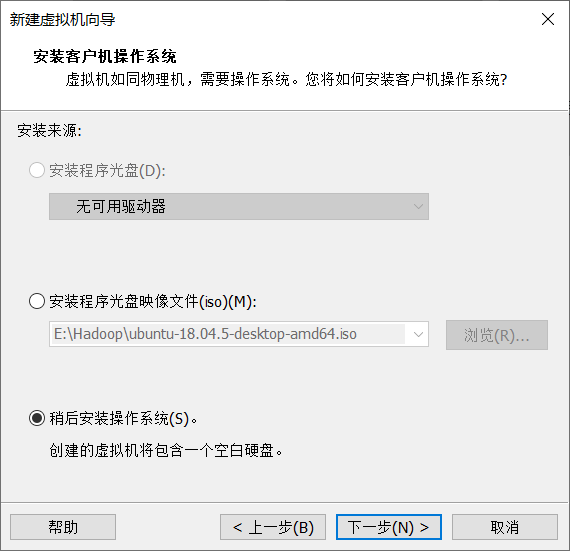
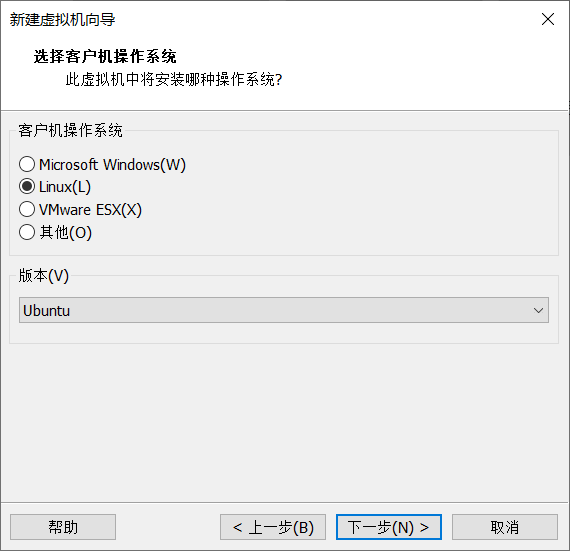
3.选择稍后安装操作系统
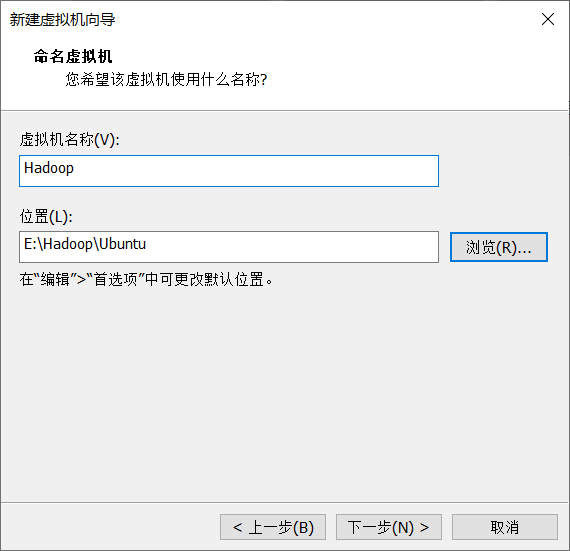
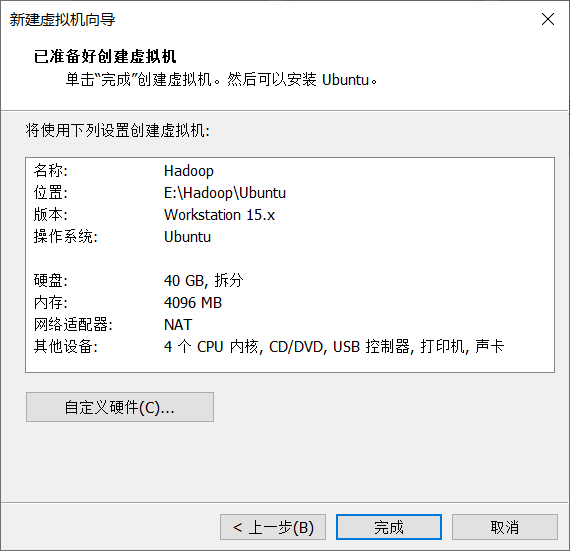
4.自定义虚拟机名称和位置(不要存放在C盘)
5.虚拟机的配置(磁盘空间和内存大小,根据你的电脑自行设计)
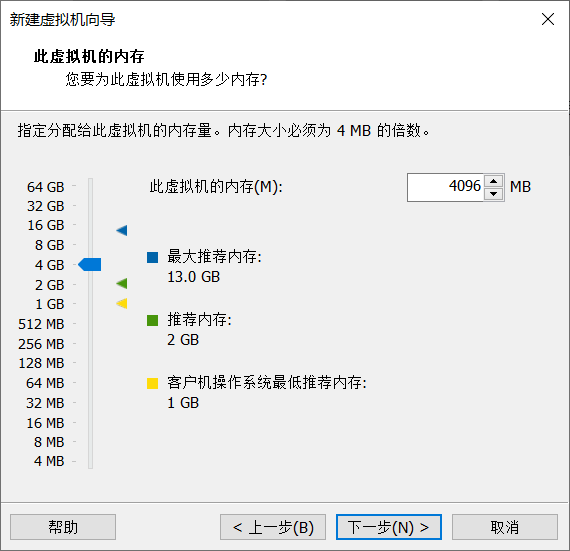
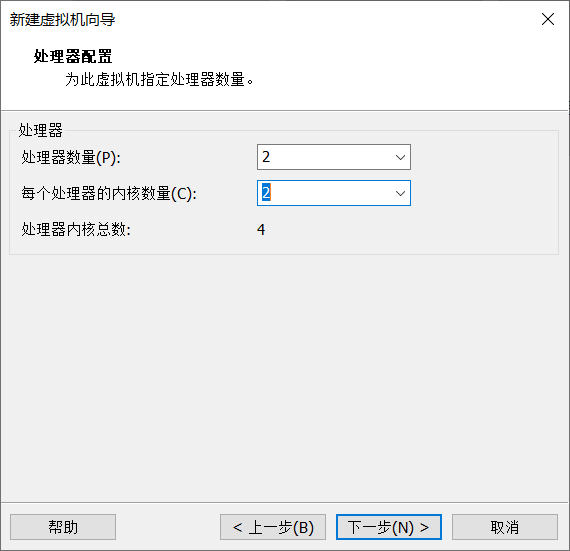
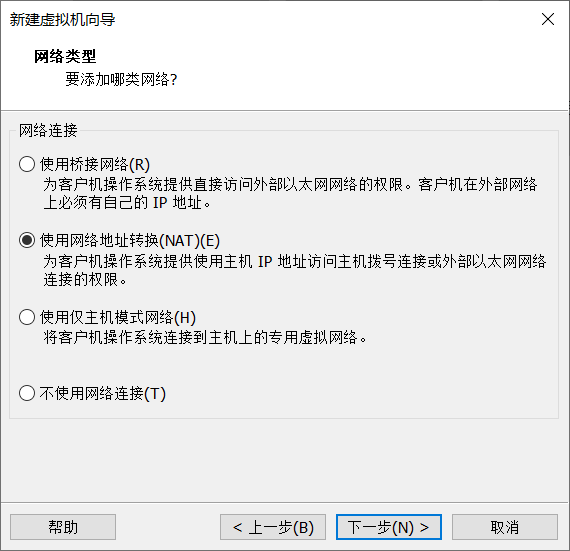
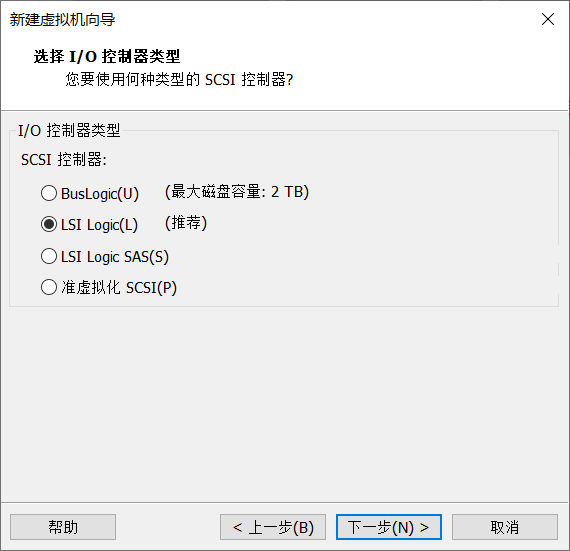

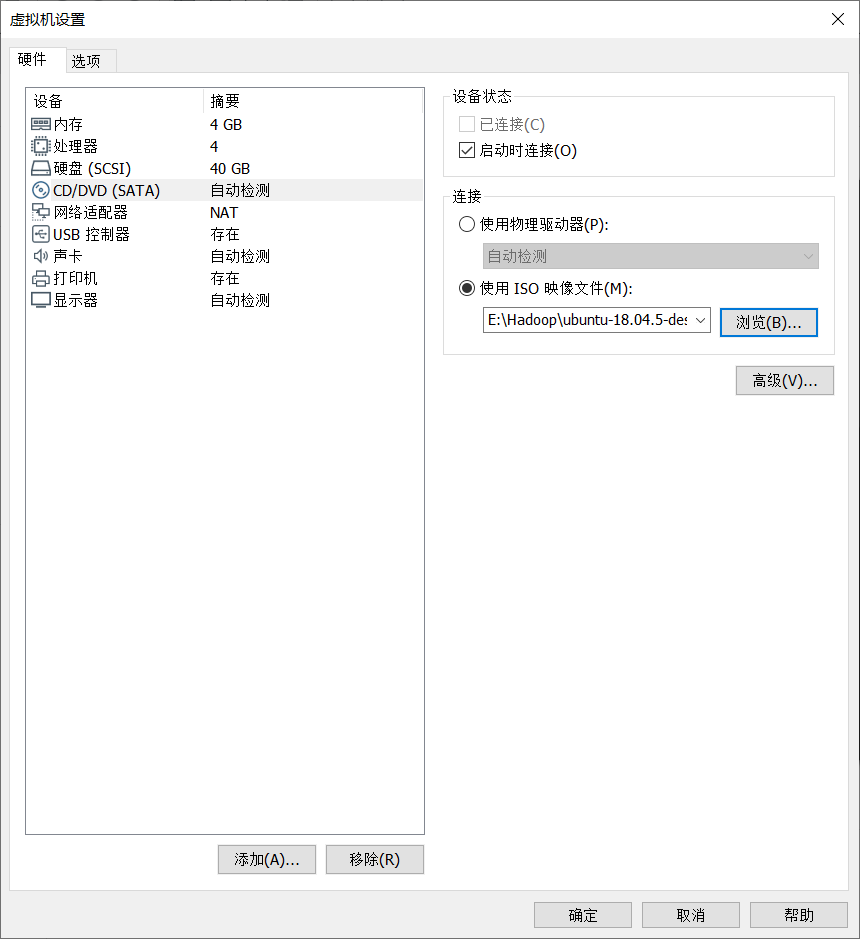
点击自定义硬件
点击开启

6.点击开启虚拟机
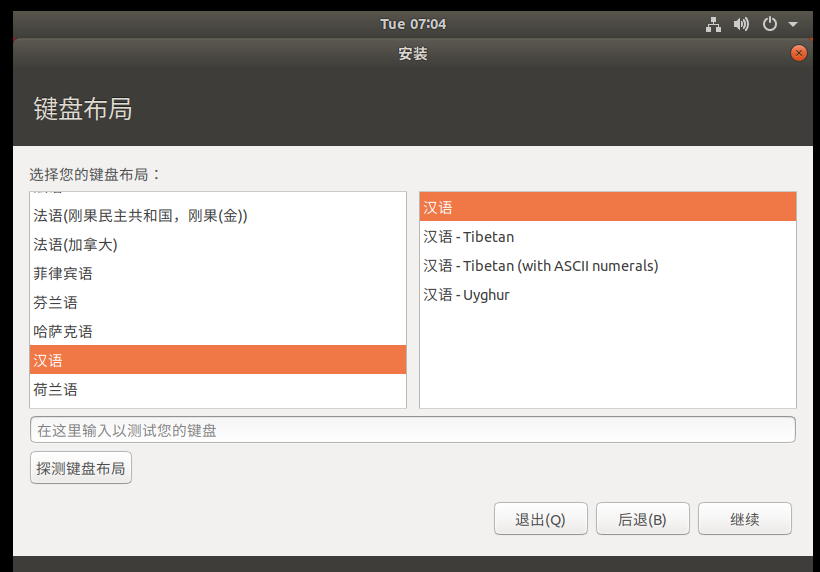
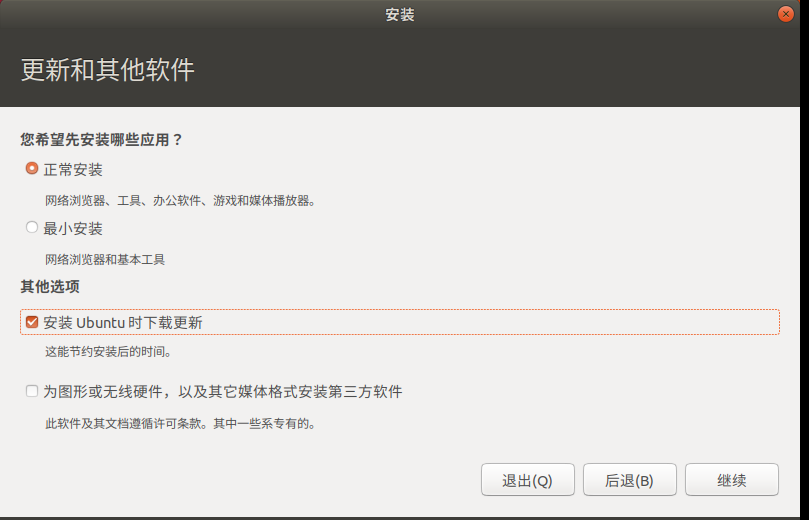
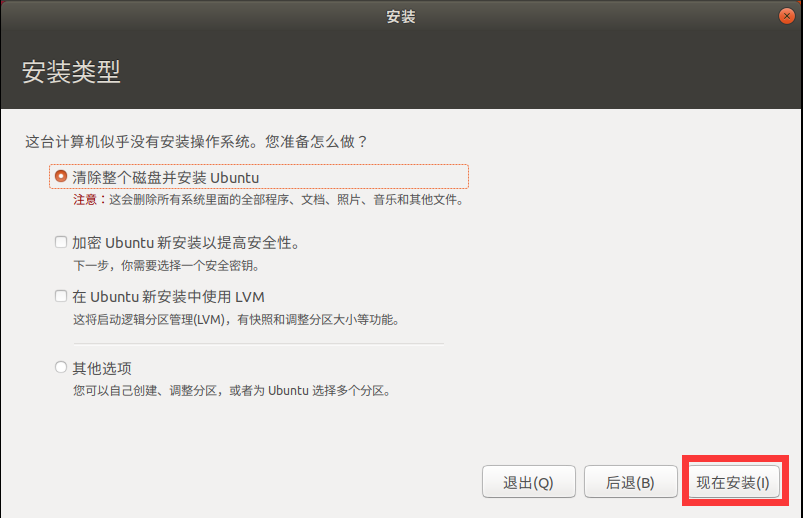
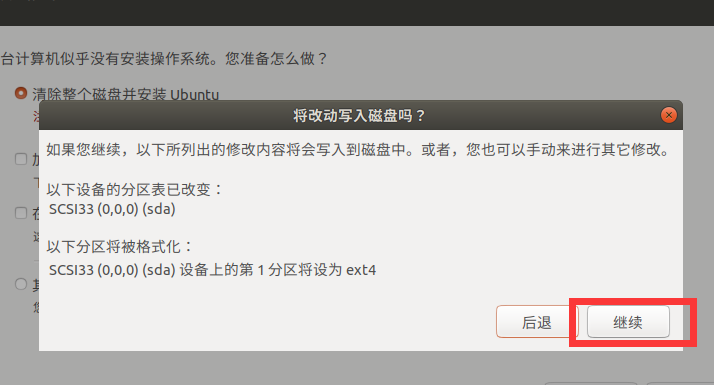
选择上海时区
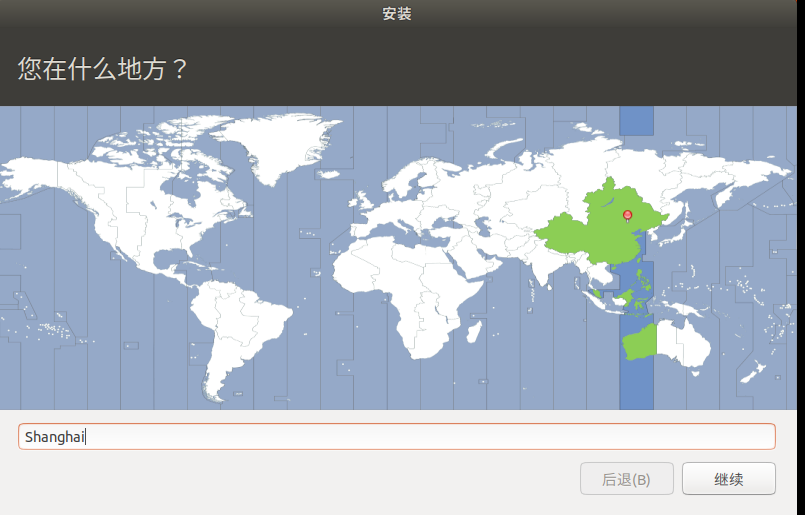
设置你的密码和登陆用户名
慢慢的等待……..接下来你可以去喝一杯咖啡,让它慢慢的安装吧
点击现在重启
三、安装VMware Tools
来解决我们的Ubuntu桌面不能显示全屏的问题

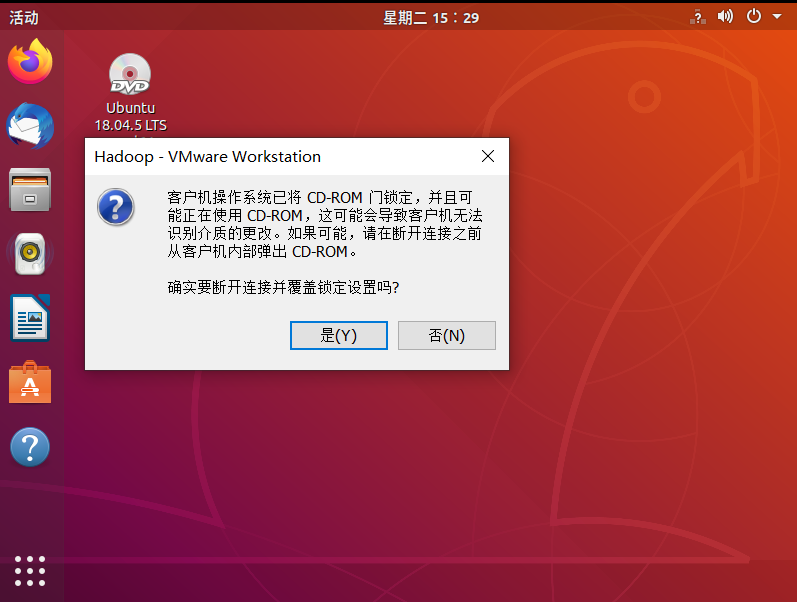
完成后进入Ubuntu,桌面会出现VMware Tools的光盘,点击进入其中
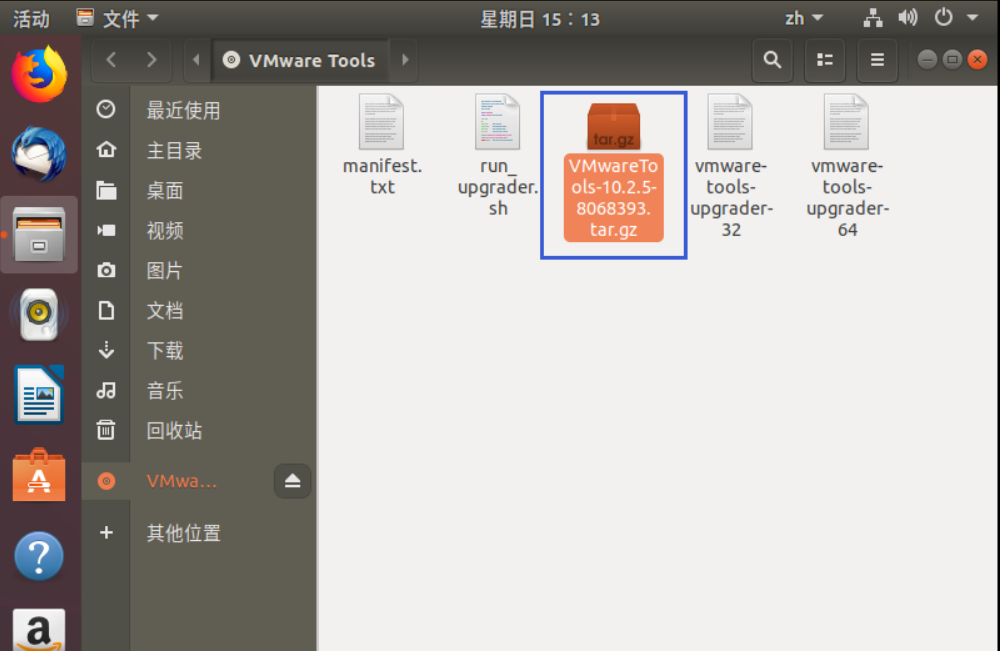
进入后看到一个压缩文件VMwareTools-10.25-8068393.tar.gz(中间数组不同的虚拟机版本可能会不同),复制文件到主目录下面(即home 个人用户名的目录下)
按住 Ctrl+Alt+enter调出终端即可:输入下面的命令:
根据你解压之后的具体版本具体操作:
tar -zxvf VMware Tools-10.25-8068393.tar.gz
cd vmware-tools-distrib
sudo ./vmware-install.pl
遇到yes 输入yes 其他都回车即可
四、配置ssh免密登陆
sudo apt update
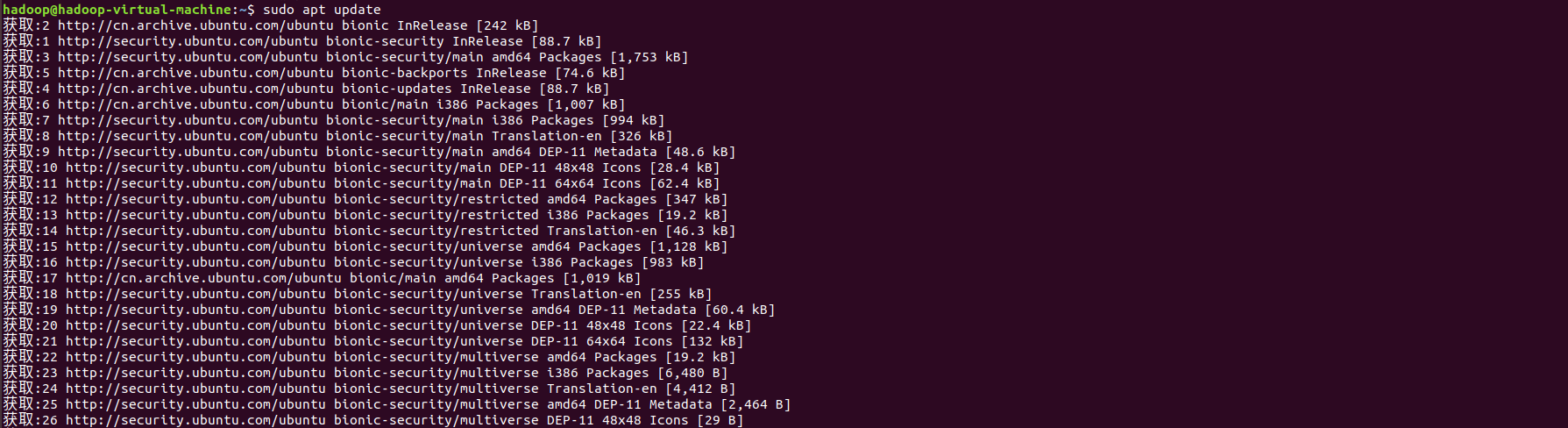
sudo apt install ssh
如果出现需要输入[y/n]的界面,就输入y即可
然后等待安装完成
ssh安装完成后,生成密钥,输入如下命令
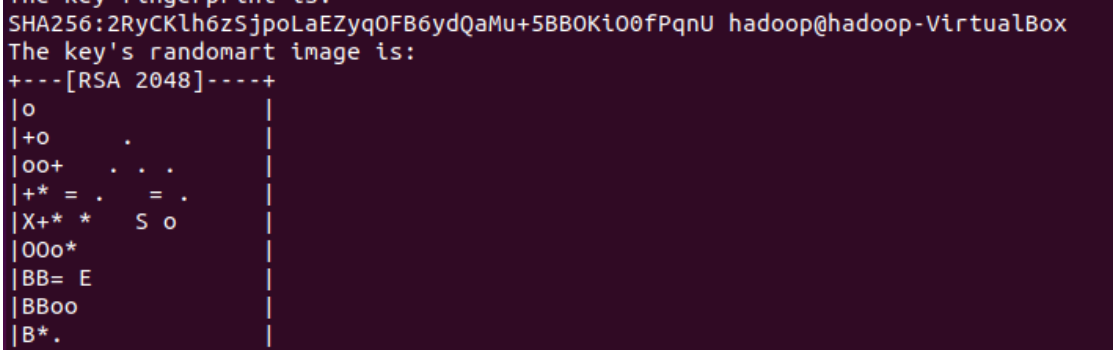
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
出现如下界面,表示这条命令执行成功了
把生成的公钥加到可信任的文件中去,输入如下命令
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
这条命令输入后,没有任何输出,不要以为没有执行成功
测试ssh配置成功没有,输入如下命令
ssh localhost
输入命令后,需要你输入yes/no,你直接输入yes
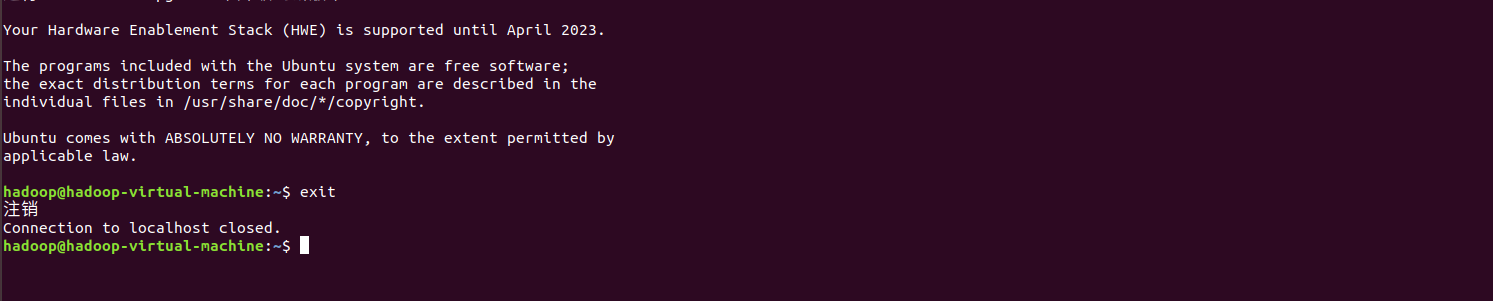
退出ssh连接,输入如下命令
exit
出现如下类似界面,表示退出了ssh连接
五、Java环境安装
卸载原版jdk,输入如下命令
sudo apt remove openjdk*
解压jdk压缩包,输入如下命令
tar -zxvf jdk-8u162-linux-x64.tar.gz
移动解压后的文件夹到/usr/local目录下,并改名为jdk,输入如下命令
sudo mv jdk1.8.0_162 /usr/local/jdk
这条命令如果执行成功,不会有任何提示
修改用户环境变量,使用gedit打开.bashrc文件, 输入如下命令
gedit .bashrc
在文件末尾加入下面的两行文字
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
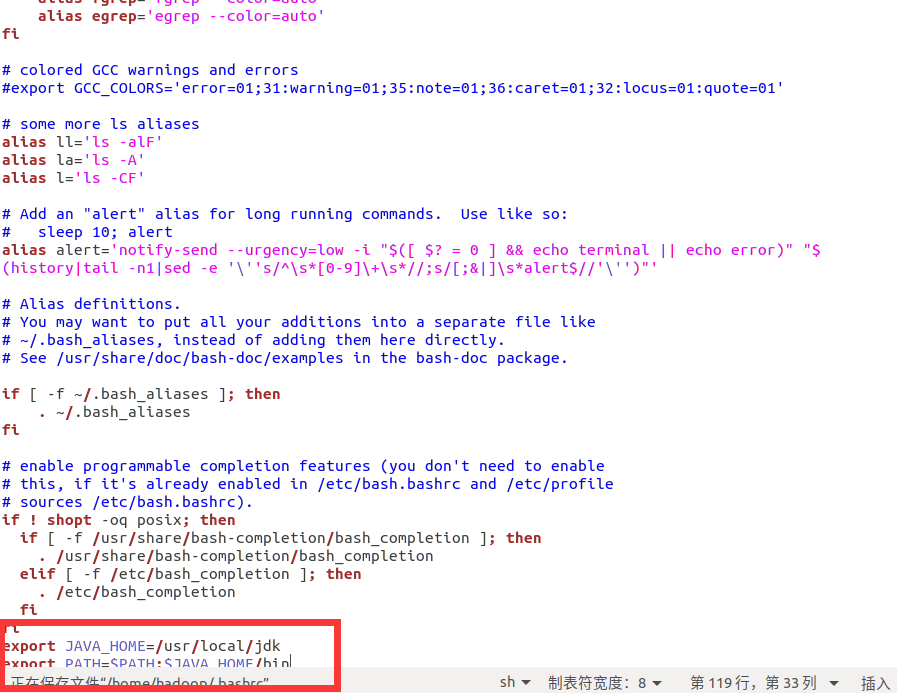
然后在终端里面输入如下命令,更新环境变量
source .bashrc
java -version
export JAVA_HOME=/home/hadoop/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export HADOOP_HOME=/home/hadoop
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
Hadoop安装
解压hadoop文件,输入如下命令
tar -xvf hadoop-2.7.3.tar.gz
移动解压后的hadoop到/usr/local目录下,并重命名为hadoop
sudo mv hadoop-2.7.3 /usr/local/hadoop
这条命令运行成功,没有任何提示,否则表示有错误
修改环境变量,使用gedit编辑.bashrc,输入如下命令
gedit .bashrc
末尾加上着两行代码
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
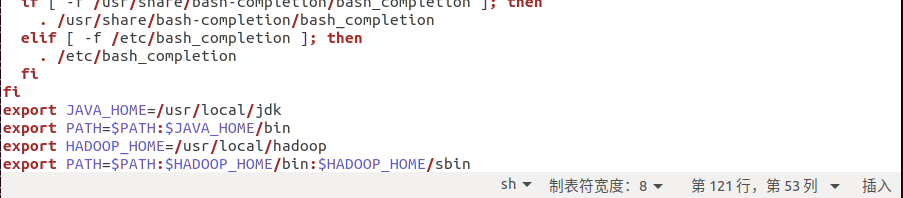
更新环境变量
source .bashrc
先进入Hadoop的目录,输入命令
cd /usr/local/hadoop/etc/hadoop
编辑core-site.xml文件,这个文件主要是对各种常用配置进行设置,输入如下命令
sudo gedit core-site.xml
然后把下面的内容整体替换掉当前文件的内容
<configuration>
<!--- global properties -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
</configuration>
sudo gedit hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
</configuration>
sudo gedit mapred-site.xml
将下面的内容直接粘贴进去即可
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>The runtime framework for executing MapReduce jobs.
Can be one of local, classic or yarn.
</description>
</property>
</configuration>
sudo gedit yarn-site.xml
<configuration>
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<description>A comma separated list of services where service name should
only
contain a-zA-Z0-9_ and can not start with numbers</description>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
sudo gedit hadoop-env.sh
然后使用Ctrl+F,调出查找界面,输入JAVA_HOME,我们需要修改的就是红色方框里面
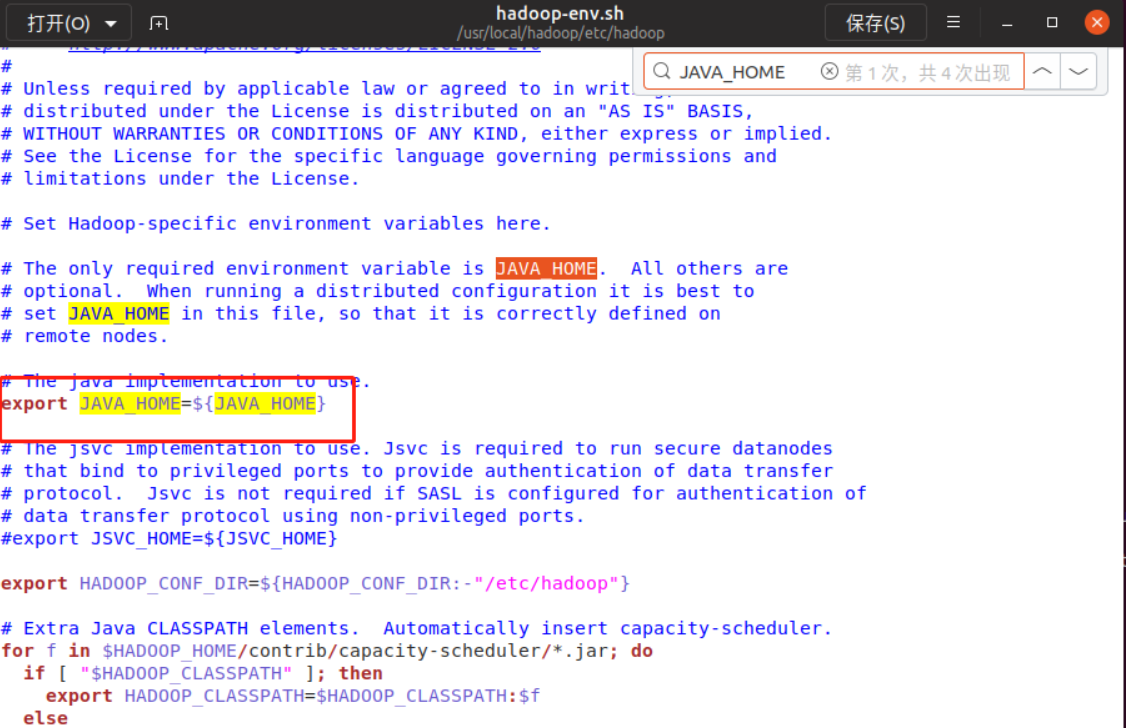
把 ${JAVA_HOME}改成/usr/local/jdk,改好后,点击Ctrl+s保存,然后点击右上角小叉叉关闭界面
新建/opt/home目录,并修改权限(依次执行下面的命令)
sudo mkdir /opt/hadoop
sudo chmod -R a+w /opt/hadoop
格式化文件系统,只有格式化后才能使用hadoop集群,输入如下命令
hdfs namenode -format
弹出如下界面,表示格式化成功

启动hdfs,输入如下命令
start-dfs.sh
第一次启动会提示是否需要继续连接,输入yes就行
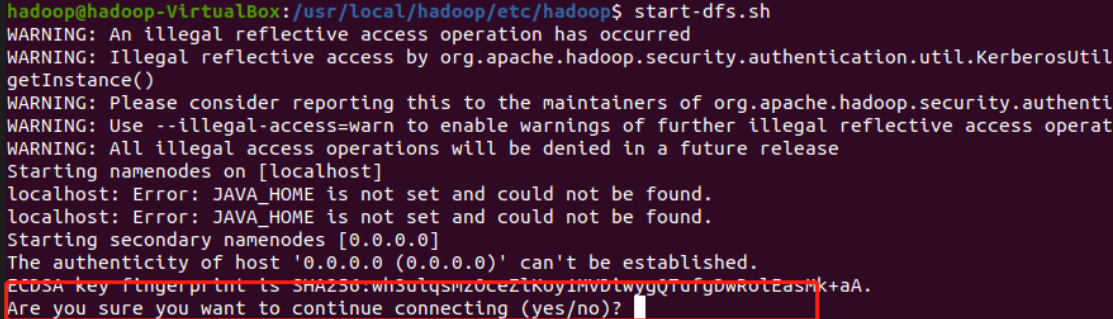
启动成功会出现,下面这个界面中的几行输出
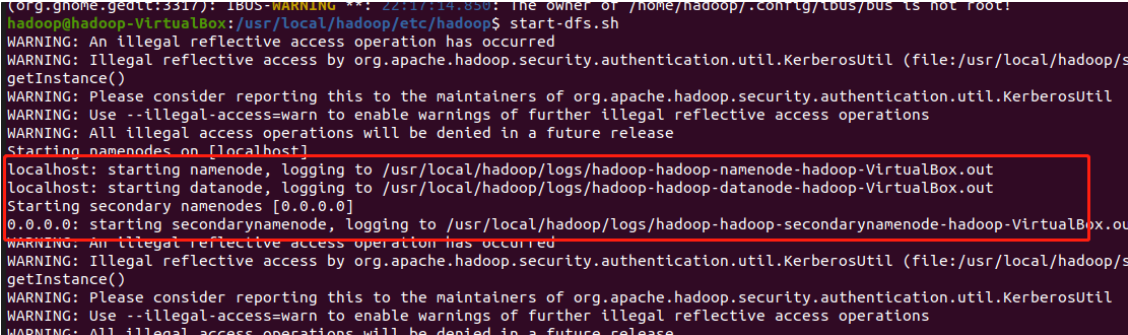
启动yarn,输入如下命令
start-yarn.sh

启动历史服务器,输入如下命令
mr-jobhistory-daemon.sh start historyserver
启动成功,会有如下输出

输入: jps
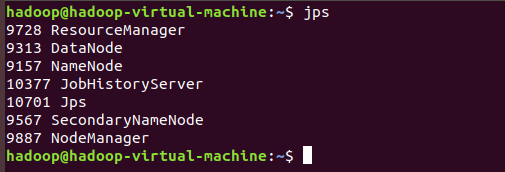
至此Hadoop就安装好了
MySQL安装部署
注意:保证处于联网状态
然后输入如下指令进行安装
sudo apt-get install mysql-server
初始情况下 root 账户没有密码,这时普通用户并不能直接使用 mysql 命令直接控制台登录 。 主要是由于 mysql.user 这张表中 root 用户的 plugin 字段值为 auth_socket,改为 mysql_native_password 即可。同时为了方便之后使用,我们在接下来的操作中顺带给 root 账户设置密码
首先使用root用户连接数据库,输入如下指令
sudo mysql
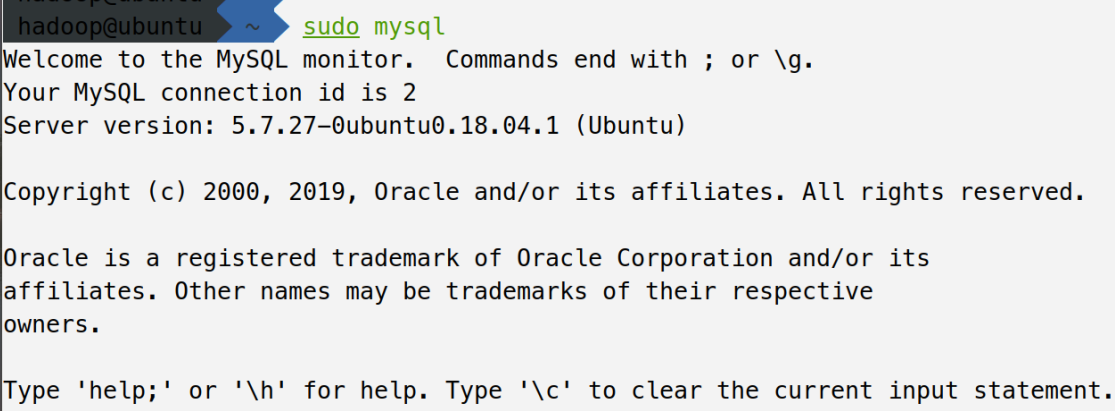
首先使用root用户连接数据库,输入如下指令
use mysql
然后输入下面的指令,改变root用户的验证途径为密码,更改密码为2211,并且把host改为%,表示可以远程使用root进行登录
UPDATE user SET plugin="mysql_native_password",
authentication_string=PASSWORD("2211"), host="%" WHERE user="root";
然后刷新权限,输入如下指令
FLUSH PRIVILEGES;
然后退出mysql
exit;
更新配置文件
sudo gedit /etc/mysql/mysql.conf.d/mysqld.cnf
然后输入Ctrl+F进行搜索,输入bind-address
如果bind-address后面是127.0.0.1改成0.0.0.0 。保存后退出

首先启用防火墙,输入如下命令
sudo ufw enable
允许3306端口进行访问(因为mysql默认是在3306端口监听)
sudo ufw allow 3306/tcp
查看状态,输入如下命令
sudo ufw status
重启mysql数据库
sudo service mysql restart
hive安装部署
首先把apache-hive-2.3.6-bin.tar.gz上传到Ubuntu的家目录下,然后输入如下指令进行解压
tar -xvf apache-hive-2.3.5-bin.tar.gz
把hive程序移动到/usr/local目录下,然后重命名为hive
sudo mv apache-hive-2.3.5-bin /usr/local/hive
把hive的可执行程序的路径加到环境变量PATH中
gedit .zshrc
export HIVE_HOME=/usr/local/hive
export PATH=$HIVE_HOME/bin:$PATH
source .zshrc
首先输入如下命令,在hdfs上创建/user/hive/warehouse目录
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -chmod g+w /tmp
hdfs dfs -chmod g+w /user/hive/warehouse
hive需要使用mysql数据库进行元数据的存储,所以我们得让Hive和mysql数据库连接,要连接这两者,我们就得使用mysql connector
移动mysql connector到hive的lib目录
mv mysql-connector-java-5.1.24-bin.jar /usr/local/hive/lib
mysql -u root -p
create database metastore;
grant all on metastore.* to hive@'%' identified by 'hive';
grant all on metastore.* to hive@'localhost' identified by 'hive';
flush privileges;
exit;
cd $HIVE_HOME/conf
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
sudo gedit hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<configuration>
<property>
<name>hive.exec.script.wrapper</name>
<value>/opt/hadoop/hive/tmp</value>
<description>
</description></property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/hadoop/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hadoop/hive/log</value>
</property>
<!-- 配置 MySQL 数据库连接信息 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
</configuration>
schematool -dbType mysql -initSchema hive hive
hive
Sqoop 安装
依次执行下面的命令参数
sudo tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
sudo mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha /usr/local/sqoop
sudo chown -R hadoop:hadoop /usr/local/sqoop
cd /usr/local/sqoop/conf/
cat sqoop-env-template.sh >> sqoop-env.sh
vi sqoop-env.sh
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
vi ~/.bashrc
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SBT_HOME/bin:$SQOOP_HOME/bin
export CLASSPATH=$CLASSPATH:$SQOOP_HOME/lib
source ~/.bashrc
sudo tar -zxvf mysql-connector-java-5.1.24.tar.gz
cp ./mysql-connector-java-5.1.24/mysql-connector-java-5.1.24-bin.jar /usr/local/sqoop/lib
service mysql start
sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root -P
HBASE部署安装
上传解压HBase
首先把hbase-2.2.1-bin.tar.gz上传到Ubuntu系统中(拖动文件到家目录下)

解压hbase-2.2.1-bin.tar.gz,输入如下命令
tar -xvf hbase-2.2.1-bin.tar.gz
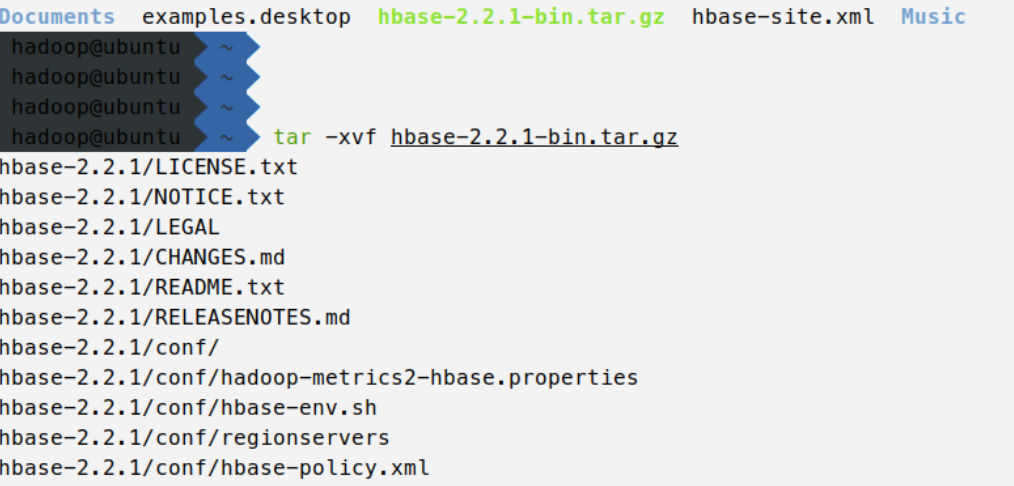
sudo mv hbase-2.2.1 /usr/local/hbase
更新环境变量
把bin目录添加到PATH变量中
gedit .zshrc
在这个文件末尾添加如下语句:
export HBASE_HOME=/usr/local/hbase
export PATH=$HBASE_HOME/bin:$PATH
保存后退出。然后更新环境变量输入如下命令:
source .zshrc
修改配置文件
首先进入hbase的配置文件目录,输入如下命令
cd /usr/local/hbase/conf
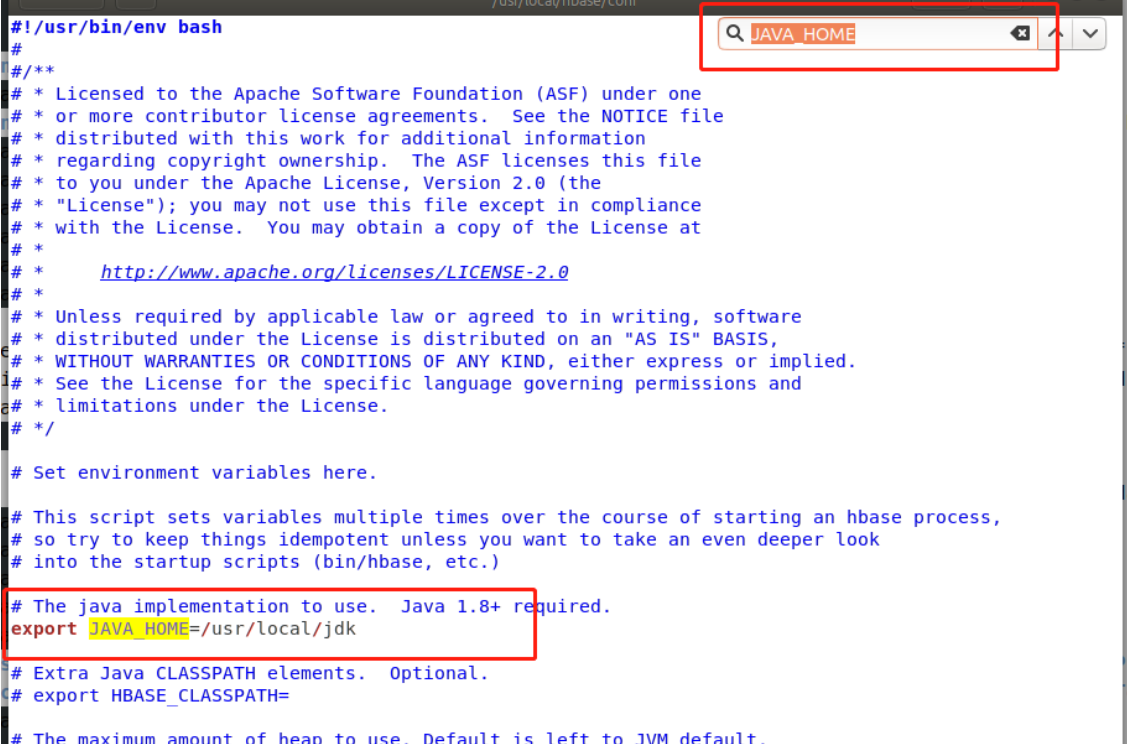
sudo gedit hbase-env.sh
**按Ctrl+F键进入查找模式,在输入框输入JAVA_HOME,以便快速查找到这一行
sudo gedit hbase-site.xml
打开文件后把如下内容,直接替换掉原来内容
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
sudo gedit regionservers
如果文件内容如下(有localhost),那就不用修改,如果没有那就添加一条localhost
启动Hasee
start-hbase.sh
至此我们的各类组件就已经安装OK了!
安装资源包已经上传!!!
需要的可以私信我!!!!
每文一语
我为了输出,需要不停地学习,学到知识后,就立马输出变成我自己的作品——有效学习
Original: https://blog.csdn.net/weixin_47723732/article/details/118095004
Author: 王小王-123
Title: 《力荐收藏》Hadoop全套组件安装详解——带你走进大数据的深渊
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/817262/
转载文章受原作者版权保护。转载请注明原作者出处!