

文章目录
*
– 一、摸鱼思路
– 二、阅读器实现思路
– 三、实现
–
+ 1、拆分章节
+ 2、翻页
+ 3、阅读主逻辑
+ 4、完整代码
– 四、效果展示 & 源码(测试数据——诡秘之主)获取
一、摸鱼思路
在命令行中进行小说阅读,可以通过我们IDE编码界面做掩护,通过IDE开启一个小的终端以命令行的方式进行阅读,这样可以表现得正在努力调试代码的样子。
二、阅读器实现思路
- 准备好测试数据(小说的txt文件)
- 将小说的源文档按章节进行拆分
– 按章节阅读,上下章翻页 - 每次打开时能紧接着上次阅读的内容
三、实现
基于上述的思路,我们的这个类就初始化出来了
class Reader:
def __init__(self, book_name, txt_path):
self.book_name = book_name
self.txt_path = txt_path
self.db = DbConfig(self.book_name, "./{}.sqlite3".format(self.book_name))
self.db.initial_table()
self.contents = []
self.book = self.split_book_chapter()
1、拆分章节
拆分章节我们可以直接使用 re.split()通过正在表达式作为分隔符进行拆分。
一般小说每一章的结构为 第***章 XXXXXX,基于此,我们可以通过两种正则表达式进行拆分
一个是 re.split('第,*章',mybook),
另一个是 re.split('\n第',mybook)
实现如下
def split_book_chapter(self):
"""
读取文本文件,并将文本按章节划分
:param txt_path:
:return:
"""
book_content = {}
with codecs.open(self.txt_path, "r", encoding="gbk") as f:
text = f.read().strip()
chapters = re.split("\n第", text)
for chapter in chapters:
text = chapter.split("\n")
title = text[0]
text = "\n".join(text)
book_content[title] = text
self.contents = list(book_content.keys())
return book_content
划分完成后存入字典(PS:python3.6以后的字典都变成了有序字典,所以在上述倒数第二行代码的位置,直接取字典的keys作为文本的目录。如果是python3.6以下的版本记得使用OrderDict进行操作)
2、翻页
翻页则是根据当前阅读的章节名称,从目录中获取当前章节前一章与后一章的名称
def get_index(self, key_name):
"""
根据书的章节名称,获取前一章与后一章
:param key_name:
:return:
"""
this_index = self.contents.index(key_name)
last_chapter = self.contents[this_index - 1]
next_chapter = self.contents[this_index + 1]
return last_chapter, next_chapter
3、阅读主逻辑
这里阅读的主逻辑,当每次开始阅读时,从数据库中获取历史记录(上一次退出脚本时,看到的章节),如果没有记录,则从第一章开始。
注意:python的版本需要达到3.6以及以上,因为3.6以后的字典为有序字典,低于这个版本的,需要把字典修改为OrderDict。
每次监听到翻页命令时,则对当前的章节名称进行存储。
def start_read(self, chapter_name=None):
"""
开始阅读, 章节名称为空,且数据库中没有历史记录时,从第一章开始
:param chapter_name: 章节名称
:return:
"""
last_chapter = self.db.get_params(["last_chapter"])
if not last_chapter:
self.db.add_one(["last_chapter"], [self.contents[0]])
if not chapter_name:
chapter_name = last_chapter[0] if last_chapter else self.contents[0]
chapter_name = chapter_name[0] if isinstance(chapter_name, tuple) else chapter_name
read_content = "".join(self.book.get(chapter_name,"当前章节不存在"))
print(read_content)
forward = ""
while forward not in ["n", "b", "q"]:
forward = input("""n、下一章\nb、上一章\nq、退出""")
last_chapter_name, next_chapter_name = self.get_index(chapter_name)
if forward == "q":
sys.exit(0)
if forward == "n":
self.db.update_one("last_chapter", next_chapter_name)
return next_chapter_name
if forward == "b":
self.db.update_one("last_chapter", last_chapter_name)
return last_chapter_name
4、完整代码
操作sqlite的工具类db.utils.py
import sqlite3
import traceback
class DbConfig:
"""
从数据库中获取小说的相关章节
"""
def __init__(self, table, db_path):
self.table = table
self.db_path = db_path
def initial_table(self):
"""
初始化数据以及库表
:return:
"""
conn = sqlite3.connect(self.db_path, check_same_thread=False)
cursor = conn.cursor()
cursor.execute("""
create table if not exists gmzz
(
chapter_name text,
chapter_content text,
last_chapter text,
update_time bigint
);
""")
conn.commit()
conn.close()
def get_params(self, *params):
"""
自定义获取参数
:param params:list: 想要获取的字段
:return:
"""
try:
conn = sqlite3.connect(self.db_path, check_same_thread=False)
cursor = conn.cursor()
sql = "select {} from {} ".format(",".join(list(params[0])), self.table)
rtn = cursor.execute(sql)
result = list(rtn)
conn.close()
return result
except Exception as e:
traceback.print_exc()
def simple_query(self, sql):
try:
conn = sqlite3.connect(self.db_path, check_same_thread=False)
cursor = conn.cursor()
rtn = cursor.execute(sql)
conn.close()
return list(rtn)
except Exception as e:
traceback.print_exc()
def add_one(self,fields, values):
try:
conn = sqlite3.connect(self.db_path, check_same_thread=False)
cursor = conn.cursor()
sql = "insert into {} ({}) values ('{}')".format(self.table, ",".join(fields), ",".join(values))
print(sql)
rtn = cursor.execute(sql)
conn.commit()
conn.close()
return rtn
except Exception as e:
traceback.print_exc()
def update_one(self, field_name, update_value):
"""
更新某个字段
:param field_name: 字段名称
:param update_value: 跟新值
:return:
"""
try:
sql = "update {table} set {field_name} = '{update_value}'".format(
table=self.table,
field_name=field_name,
update_value=update_value
)
conn = sqlite3.connect(self.db_path, check_same_thread=False)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
except Exception as e:
traceback.print_exc()
脚本主程序
import codecs
import os
import re
import sys
import platform
from db_utils import DbConfig
class Reader:
def __init__(self, book_name, txt_path):
self.book_name = book_name
self.txt_path = txt_path
self.db = DbConfig(self.book_name, "./{}.sqlite3".format(self.book_name))
self.db.initial_table()
self.contents = []
self.book = self.split_book_chapter()
def split_book_chapter(self):
"""
读取文本文件,并将文本按章节划分
:param txt_path:
:return:
"""
book_content = {}
with codecs.open(self.txt_path, "r", encoding="gbk") as f:
text = f.read().strip()
chapters = re.split("\n第", text)
for chapter in chapters:
text = chapter.split("\n")
title = text[0]
text = "\n".join(text)
book_content[title] = text
self.contents = list(book_content.keys())
return book_content
def get_index(self, key_name):
"""
根据书的章节名称,获取前一章与后一章
:param key_name:
:return:
"""
this_index = self.contents.index(key_name)
last_chapter = self.contents[this_index - 1]
next_chapter = self.contents[this_index + 1]
return last_chapter, next_chapter
def start_read(self, chapter_name=None):
"""
开始阅读, 章节名称为空,且数据库中没有历史记录时,从第一章开始
:param chapter_name: 章节名称
:return:
"""
last_chapter = self.db.get_params(["last_chapter"])
if not last_chapter:
self.db.add_one(["last_chapter"], [self.contents[0]])
if not chapter_name:
chapter_name = last_chapter[0] if last_chapter else self.contents[0]
chapter_name = chapter_name[0] if isinstance(chapter_name, tuple) else chapter_name
read_content = "".join(self.book.get(chapter_name,"当前章节不存在"))
print(read_content)
forward = ""
while forward not in ["n", "b", "q"]:
forward = input("""n、下一章\nb、上一章\nq、退出""")
last_chapter_name, next_chapter_name = self.get_index(chapter_name)
if forward == "q":
sys.exit(0)
if forward == "n":
self.db.update_one("last_chapter", next_chapter_name)
return next_chapter_name
if forward == "b":
self.db.update_one("last_chapter", last_chapter_name)
return last_chapter_name
if __name__ == '__main__':
mybook = Reader("gmzz", "test.txt")
chapter_name = None
while True:
if platform.system().lower() == "windows":
os.system('cls')
if platform.system().lower() == "linux":
os.system('clear')
chapter_name = mybook.start_read(chapter_name)
四、效果展示 & 源码(测试数据——诡秘之主)获取
最后运行的效果就如下图所示
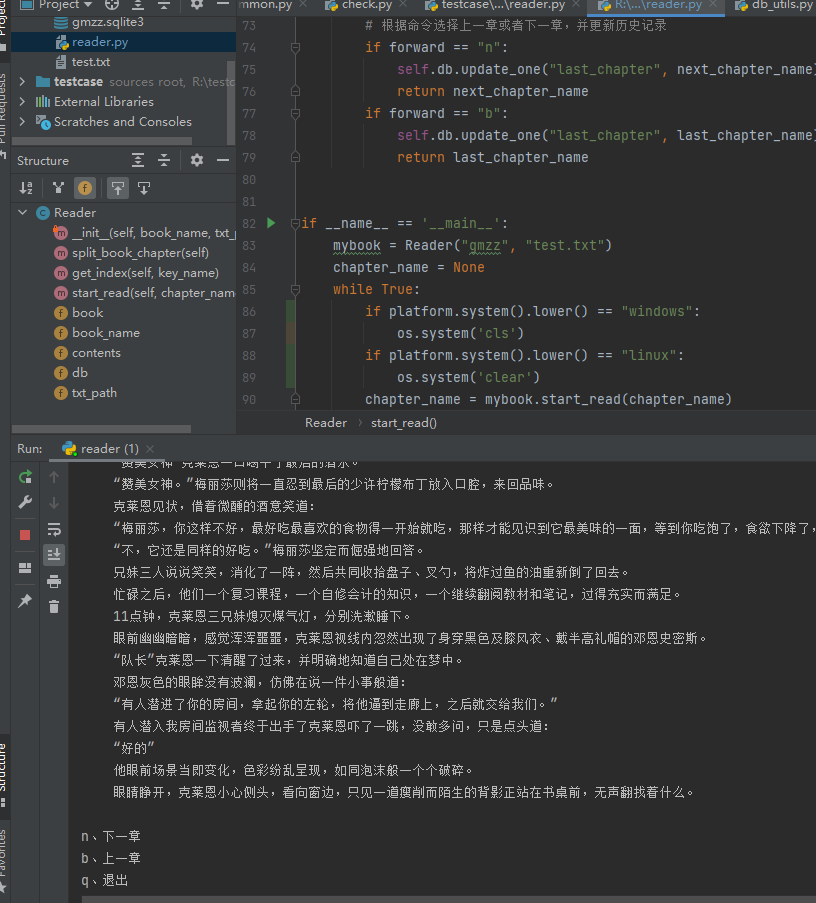

源码+测试数据获取,关注以下公众号,回复0070获取

Original: https://blog.csdn.net/Demonslzh/article/details/119240297
Author: Demonslzh
Title: 摸鱼神器——python命令行小说阅读器实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/816578/
转载文章受原作者版权保护。转载请注明原作者出处!