



一、原始GAN的缺点
生成的图像是随机的,不可预测的,无法控制网络输出特定的图片,生成目标不明确,可控性不强。针对原始GAN不能生成具有特定属性的图片的问题, Mehdi Mirza等人提出了cGAN,其核心在于将属性信息y 融入生成器G和判别器D中,属性y可以是任何标签信息, 例如图像的类别、人脸图像的面部表情等。
二、CGAN的基本原理
cGAN的中心思想是希望 可以控制 GAN 生成的图片,而不 是单纯的随机生成图片。 具体来说,Conditional GAN 在生成器和判别器的输入中 增加了额外的 条件信息,生成器生成的图片只有足够真实 且与条件相符,才能够通过判别器。
实际上 , 在无条件约束的生成模型中 , 没法控制数据生成的模式。然而,通过额外的信息对模型进行约束,有可能指导数据生成的过程。条件约束可以是类标签 , 可以是图像修补的部分数据, 甚至是来自不同模态的数据
cGAN将 无监督学习 转为 有监督学习 使得网络可以更好地在我们的掌控下进行学习!
从公式看,cgan相当于在原始GAN的基础上对生成器部分 和判别器部分都加了一个条件
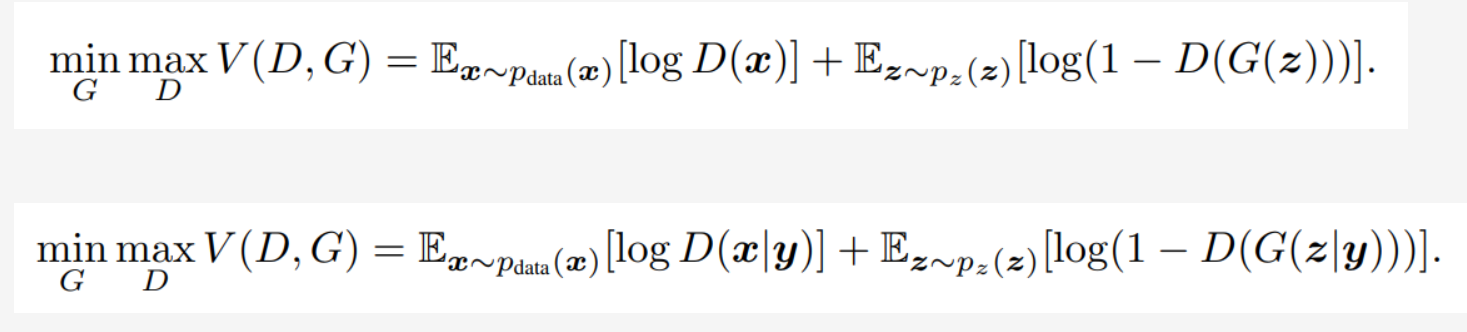
三、CGAN模型
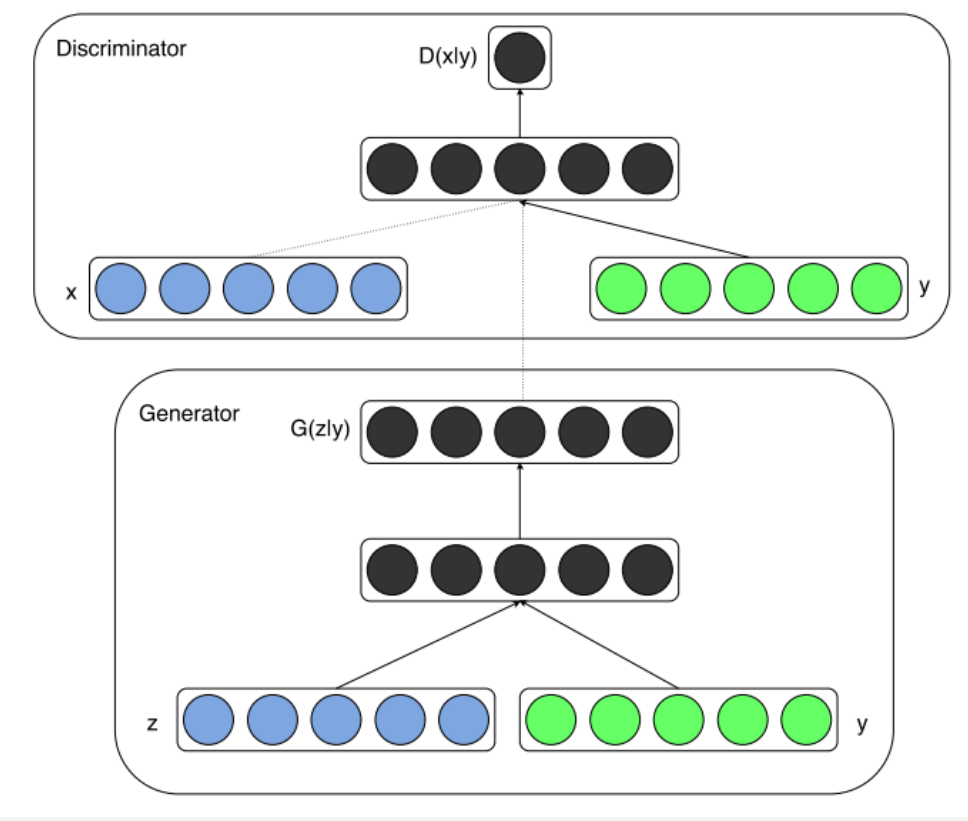
如果将上图绿色部分的y去掉,就是GAN的原理图。
四、CGAN结构
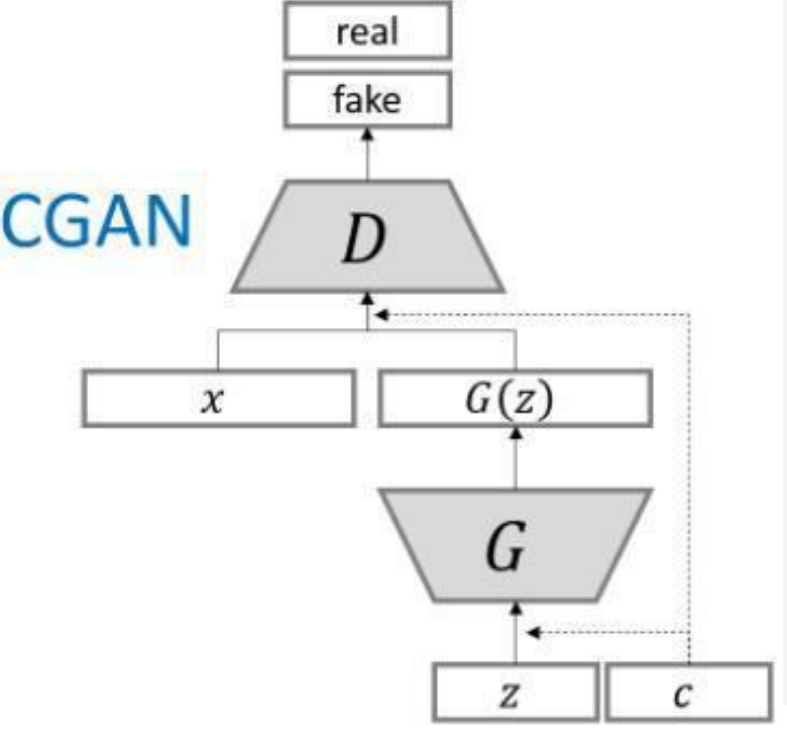
为了实现条件GAN的目的,生成网络和判别网络的原理和 训练方式均要有所改变。
模型部分,在判别器和生成器中
Original: https://blog.csdn.net/m0_62128864/article/details/123972758
Author: 码农男孩
Title: GANs系列:CGAN(条件GAN)原理简介以及项目代码实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/812300/
转载文章受原作者版权保护。转载请注明原作者出处!