

什么是注意力?
我们观察事物时,之所以能够快速做出判断,是因为我们大脑能够将注意力能够以高分辨率接收于图片上的某个区域,并且以低分辨率感知其周边区域,并且视点能够随着时间而改变,换句话说就是人眼通过快速扫描全局图像,找到需要关注的目标区域(在阅读文本时就是快速扫描全文,然后找到关键段落、关键词),然后对这个区域分配更多注意,目的在于获取更多细节信息和抑制其他无用信息,从而快速作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果。
正是基于人类大脑这一特点,进行仿生,从而提出了深度学习中的注意力机制。在神经网络中,注意力机制可以认为是一种资源分配的机制,可以理解为对于原本平均分配的资源根据对象的重要程度重新分配资源,重要的单位就多分一点,不重要或者不好的单位就少分一点。
怎么将这种能力迁移到计算机上呢?
我们通过一个类比来说明:我们需要去定做一件衣服,想好需要的衣服后,我们去到服装店,把我们对衣服的关键性描述($query$,$Q$)告诉老板,例如”男士衬衫、格子衬衫、纯棉”,随后,老板在脑海里将我们的描述与店里所有衣服样品($value$,$V$)的描述($key$,$K$)进行对比,然后拿出相对更加匹配的样品给我们看,看了之后,我们就发现,有些衣服有50%(权重)符合我们的心意,有些衣服只有20%符合我们心意,难道我们选择最满意的一件吗?不是,我们告诉老板,这件样品,你取这50%的特点,那件样品,取另外20%的特点,直到凑成100%(加权平均的过程),也就是完整衣服的特征,最后那件凑成的衣服,就是我们想要的衣服(注意力值)。
Transformer算法中的注意力机制,跟这个定做衣服的过程是很类似的。这里有三个很关键的概念,也就是上面提到的$query$(来自源数据)、$key$(来自目标数据)、$value$(来自目标数据),这里用”来自”这个词有些不太准确,因为$query$、$key$、$value$是通过源数据、目标数据(都是矩阵)与不同的矩阵($W^Q$, $W^K$, $W^V$)相乘得到,放在神经网络中就是经过线性层变换。$query$、$key$、$value$三者之间是存在联系的,联系越紧密(越相似),那么权重就越大,最终获得的注意力就越多,所以,怎么来评判它们之间的相似度就很关键了。最简单的,就是使用余弦相似度,但是这里,我们更多的是使用点积的方式,两个向量越相似,点积就越大。获得点积之后,进行softmax操作,然后再与$value$矩阵进行加权求和,就获得了最终整个序列的注意力值。整个过程如图5所示。公式表示如下:
$$Attention(Q, K, V)=softmax(\frac{QK^T}{\sqrt[]{d_k}})$$
式中,$d_k$为输入样本维度数,除以$\sqrt[]{d_k}$是为了对最终注意力值大小进行规范化,使注意力得分贴近于正态分布,有助于后续梯度下降求解。
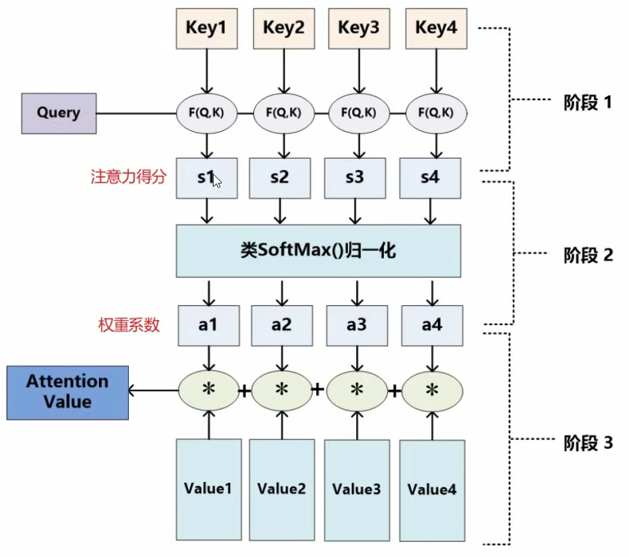

图5 注意力机制
Transformer中的注意力机制又不仅于此,Transformer还是用了一种自注意力机制,这种注意力机制中$query$、$key$、$value$三者都是同一矩阵经过变化得来,当然,再简化一点,直接使用初始数据矩阵作为$query$、$key$、$value$也不是不行。
这个过程很重要,是Transformer的核心,我们再用更加数学化的方式表述一遍。假设存在序列数据集$X={x_1, x_2, x_3, …, x_T}$(可以认为$x_1$是文本中的第一个词),$X$经过词嵌入和位置编码后,转为为${a_1, a_2, a_3, …, a_T}$,我们分别使用$W^Q$, $W^K$, $W^V$与之相乘,获得$q_i$,$k_i$,$v_i$,$i \in (1, 2, 3, …, T)$。以$x_1$为例,如何获得$x_1$的注意力值呢?
- 首先,我们用$x_1$对应的$query$即$q_1$与$k_1, k_2, k_3, …, k_T$计算向量点积, 得到$\alpha_{11}, \alpha_{12}, \alpha_{12}, …, \alpha_{1T}$。注意,这时候的,$\alpha_{11}, \alpha_{12}, \alpha_{12}, …, \alpha_{1T}$在取值范围上,可未必在[0, 1]之间,还需要经过softmax处理;
- 然后,将$\alpha_{11}, \alpha_{12}, \alpha_{12}, …, \alpha_{1T}$输入softmax层,从而获取值在[0, 1]之间的注意力权重值,即$\hat \alpha_{11}, \hat \alpha_{12}, \hat \alpha_{12}, …, \hat \alpha_{1T}$,这相当于一个概率分布矩阵;
- 最后,将$\hat \alpha_{11}, \hat \alpha_{12}, \hat \alpha_{12}, …, \hat \alpha_{1T}$分别与对应的$v_1, v_2, v_3, …, v_T$相乘,然后求和,这样便获得了与输入的$x_1$相对应的注意力值$b_1$。
经过注意力机制层后,输出矩阵中的每个词向量都含有当前这个句子中所有词的语义信息,这对提升模型性能是极为关键的。
注意力机制实现过程代码如下所示:
Original: https://www.cnblogs.com/chenhuabin/p/16453665.html
Author: 奥辰
Title: Transformer算法完全解读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/809976/
转载文章受原作者版权保护。转载请注明原作者出处!