

pandas
为什么学习pandas
- numpy已经可以帮助我们进行数据的处理了,那么学习pandas的目的是什么呢?
- numpy能够帮助我们处理的是数值型的数据,当然在数据分析中除了数值型的数据还有好多其他类型的数据(字符串,时间序列), *那么pandas就可以帮我们很好的处理除了数值型的其他数据!
什么是pandas?
- 首先先来认识pandas中的两个常用的类
- Series
- DataFrame
Series
- Series是一种类似与 _一维数组_的对象,由下面两个部分组成:
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
- Series的创建
- 由列表或numpy数组创建
- 由字典创建
from pandas import Series
s = Series(data=[127,2,3,'regina'])



为什么需要有显示索引?
答:显示索引可以增强Series 的可读性
还可以直接引入字典:

Series的索引和切片
s[0] --> regina
s.姓名 --> regina
s[0:2] -->
姓名 regina
年龄 23
dtype: object
- Series的常用属性
- shape
- size
- index 返回索引
- values 返回值
s.shape
s.size
s.index #返回索引
s.values #返回值
s.dtype #元素的类型
- Series的常用方法
- head(),tail()
 这里的head和tail默认是5,tail显示最后n个数据
这里的head和tail默认是5,tail显示最后n个数据 - unique() 去重

- isnull(),notnull()
- add() sub() mul() div() 只有索引一致的数据才可以相加
 同时也只有数据类型一样的才能相加
同时也只有数据类型一样的才能相加
DataFrame
- DataFrame是一个 【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
- DataFrame的创建


- DataFrame的属性

============================================
练习:
根据以下考试成绩表,创建一个DataFrame,命名为df:
regina ivanlee
语文 150 0
数学 150 0
英语 150 0
理综 300 0
============================================

- DataFrame索引操作
df = DataFrame(data=np.random.randint(60,100,size=(5,5)),columns=['A','B','C','D','E'],index=[1,2,3,4,5])

– 对行进行索引
+ iloc: 通过隐式索引取行 (不根据所定义的index取值)
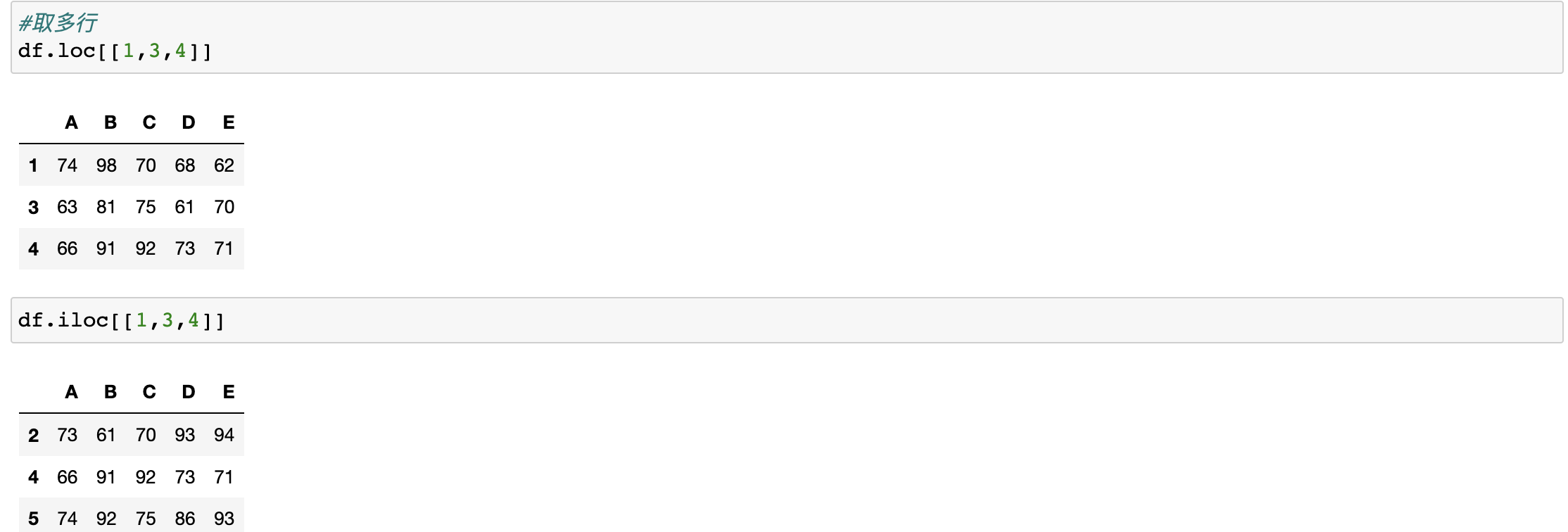 取单个元素:
取单个元素: df.iloc[,]


* DataFrame的切片操作
– 对行进行切片
– 对列进行切片
* df索引和切片操作
– 索引:
+ df[col]:取列
+ df.loc[index]:取行
+ df.iloc[index,col]:取元素
– 切片:


DataFrame的计算与Series一致
- 时间数据类型的转换
- pd.to_datetime(col)
dic = {
'time':['2010-10-10','2011-11-20','2020-01-10'],
'temp':[33,31,30]
}
df = DataFrame(data=dic) df['time'].dtype = 'O'
import pandas as pd
#将time列的数据类型转换成时间序列类型
df['time'] = pd.to_datetime(df['time'])
df['time']

* 将某一列设置为行索引
– df.set_index() 上图中的索引是隐式索引的012,如果要将time列作为行索引
#将time列作为源数据的行索引
df.set_index('time',inplace=True)

Original: https://www.cnblogs.com/ivanlee717/p/16987592.html
Author: ivanlee717
Title: 数据分析之pandas的使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/808105/
转载文章受原作者版权保护。转载请注明原作者出处!