

1 导引
我们在《Python中的随机采样和概率分布(二)》介绍了如何用Python现有的库对一个概率分布进行采样,其中的Dirichlet分布大家一定不会感到陌生,这篇博客我们来更详细地介绍Dirichlet分布的性质及其在联邦学习领域的应用。
2 Dirichlet分布及其性质
Dirichlet分布[1]是定义在(\mathbb{R}^N)上的概率密度。Dirichlet分布以度量(\bm{u})(所有系数(\bm{u}i>0)的一个向量)为参数,可将它写为(\bm{u}=\alpha \bm{m}),这里(\bm{m})是在(N)个分量上的归一化度量((\sum{i=1}^N m_i = 1), (m_i > 0)),且(\alpha)是一个正数。Dirichlet分布的概率密度函数由下式给出:
[f(\bm{x} | \alpha \bm{m}) \propto \prod_{i=1}^{N} x_{i}^{\alpha m_i -1} ]
注意,对(\bm{X} = (X_1, \cdots, X_N)\sim \text{Dir}(\alpha \bm{m})),有(X_i>0 , \sum_{i=1}^N X_i = 1)。
向量(\bm{m})是随机向量(\bm{X})的期望:
[\mathbb{E}(\bm{X}) = \int f(\bm{x} | \alpha \bm{m}) \bm{x} \mathrm{d} \bm{x} = \bm{m} ]
在物理意义上,Dirichlet分布中参数(\alpha)的作用主要体现在两个方面。首先,(\alpha)度量了这个分布的 锐度(sharpness),也即测量我们分布中的典型样本(\bm{X})与其均值(\bm{m})相差多远,就像高斯分布中精度(\tau=1/\sigma^2)度量了样本与它的均值偏差多远一样。 一个大的(\alpha) 值会使得(\bm{X}) 的分布在(\bm{m}) 附近急剧出现尖峰(后文我们会提到,在联邦数据划分中,这将导致不同标签在客户端的分布更为 同构)。下图就体现了(\alpha)对(\bm{X})分布的影响:
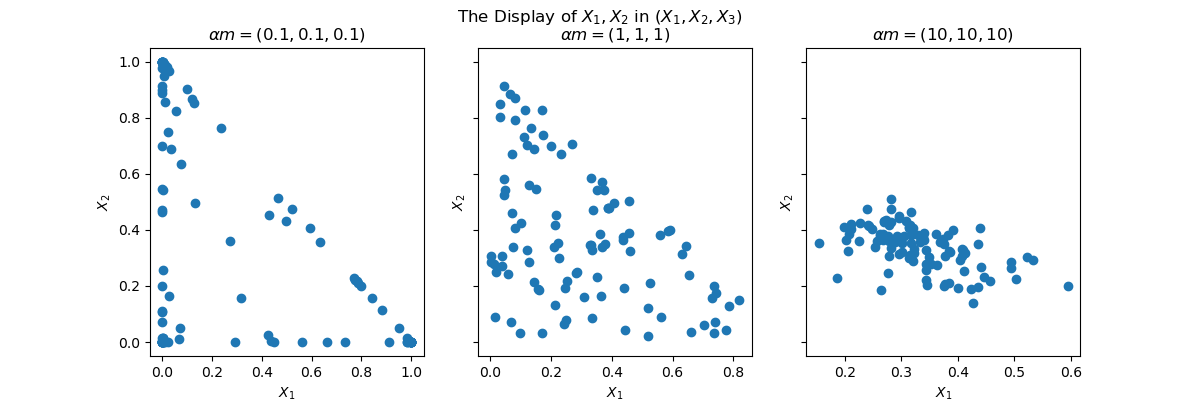

注意我们这里是从满足(N=3)的分布中采样1000个3维样本点,两个轴表示(X_1)和(X_2),(X_3)在可视化中并不使用。
这里附上可视化的代码,感兴趣的童鞋可下来自行尝试:
import numpy as np
import matplotlib.pyplot as plt
us = [(0.1, 0.1, 0.1), (1, 1, 1), (10, 10, 10)] # 3组不同的u=alpha*m参数
points = [[] for i in range(3)]
for i in range(3):
points[i] = np.random.dirichlet(us[i], size=100)
xs, ys = [[] for i in range(3)], [[] for i in range(3)]
for i in range(3):
xs[i], ys[i], _ = list(zip(*points[i]))
fig, axs = plt.subplots(1, 3, figsize=(12, 4), sharey=True)
for i in range(3):
axs[i].set_title(f"$αm={us[i]}$")
axs[i].scatter(xs[i], ys[i])
axs[i].set_xlabel("$X_1$")
axs[i].set_ylabel("$X_2$")
plt.suptitle(r"The Display of $X_1, X_2$ in $(X_1, X_2, X_3)$")
plt.show()
3 Dirichlet分布在联邦学习中的应用
3.1 划分不独立同分布(Non-IID)数据集
我们在联邦学习中,经常会假设不同client间的数据集不满足独立同分布(Non-IID)。那么我们如何将一个现有的数据集按照Non-IID划分呢?我们知道带标签样本的生成分布看可以表示为(p(\bm{x}, y)),我们进一步将其写作(p(\bm{x}, y)=p(\bm{x}|y)p(y))。其中如果要估计(p(\bm{x}|y))的计算开销非常大,但估计(p(y))的计算开销就很小。所有我们按照样本的标签分布来对样本进行Non-IID划分是一个非常高效、简便的做法。
总而言之,我们采取的算法思路是尽量让每个client上的样本标签分布不同。我们设有(K)个类别标签,(N)个client,每个类别标签的样本需要按照不同的比例划分在不同的client上。我们设矩阵(\bm{X}\in \mathbb{R}^{K*N})为类别标签分布矩阵,其行向量(\bm{x}_k\in \mathbb{R}^N)表示类别(k)在不同client上的概率分布向量(每一维表示(k)类别的样本划分到不同client上的比例),该随机向量就采样自Dirichlet分布(第一次采用Dirichlet分布来划分数据集的论文为《Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification》[2])。
据此,我们可以写出以下的划分算法:
def dirichlet_split_noniid(train_labels, alpha, n_clients):
'''
按照参数为alpha的Dirichlet分布将样本索引集合划分为n_clients个子集
'''
n_classes = train_labels.max()+1
# (K, N) 类别标签分布矩阵X,记录每个类别划分到每个client去的比例
label_distribution = np.random.dirichlet([alpha]*n_clients, n_classes)
# (K, ...) 记录K个类别对应的样本索引集合
class_idcs = [np.argwhere(train_labels == y).flatten()
for y in range(n_classes)]
# 记录N个client分别对应的样本索引集合
client_idcs = [[] for _ in range(n_clients)]
for k_idcs, fracs in zip(class_idcs, label_distribution):
# np.split按照比例fracs将类别为k的样本索引k_idcs划分为了N个子集
# i表示第i个client,idcs表示其对应的样本索引集合idcs
for i, idcs in enumerate(np.split(k_idcs,
(np.cumsum(fracs)[:-1]*len(k_idcs)).
astype(int))):
client_idcs[i] += [idcs]
client_idcs = [np.concatenate(idcs) for idcs in client_idcs]
return client_idcs
其中 np.random.dirichlet函数的具体用法大家可以参见我的上一篇博客《Python中的随机采样和概率分布(二)》和numpy文档《numpy.random.dirichlet函数》[3],此处不再赘述。
3.2 算法测试与可视化呈现
接下来我们在EMNIST数据集上调用该函数进行测试,并进行可视化呈现。我们设client数量(N=10),Dirichlet概率分布的参数(\alpha=1.0)(也是我们联邦学习常用的设置),(\bm{m}\in \mathbb{R}^N)在我们这里表示client的先验分布,我们规定是均匀分布(\bm{m}= (1, 1, \cdots, 1))。数据集划分的可视化呈现如下:
import numpy as np
import matplotlib.pyplot as plt
from torchvision import datasets
from torch.utils.data import ConcatDataset
n_clients = 10
dirichlet_alpha = 1.0
seed = 42
if __name__ == "__main__":
np.random.seed(seed)
train_data = datasets.EMNIST(
root=".", split="byclass", download=True, train=True)
test_data = datasets.EMNIST(
root=".", split="byclass", download=True, train=False)
classes = train_data.classes
n_classes = len(classes)
labels = np.concatenate(
[np.array(train_data.targets), np.array(test_data.targets)], axis=0)
dataset = ConcatDataset([train_data, test_data])
# 我们让每个client不同label的样本数量不同,以此做到Non-IID划分
client_idcs = dirichlet_split_noniid(
labels, alpha=dirichlet_alpha, n_clients=n_clients)
# 展示不同label划分到不同client的情况
plt.figure(figsize=(12, 8))
plt.hist([labels[idc]for idc in client_idcs], stacked=True,
bins=np.arange(min(labels)-0.5, max(labels) + 1.5, 1),
label=["Client {}".format(i) for i in range(n_clients)],
rwidth=0.5)
plt.xticks(np.arange(n_classes), train_data.classes)
plt.xlabel("Label type")
plt.ylabel("Number of samples")
plt.legend(loc="upper right")
plt.title("Display Label Distribution on Different Clients")
plt.show()
最终的可视化结果如下:
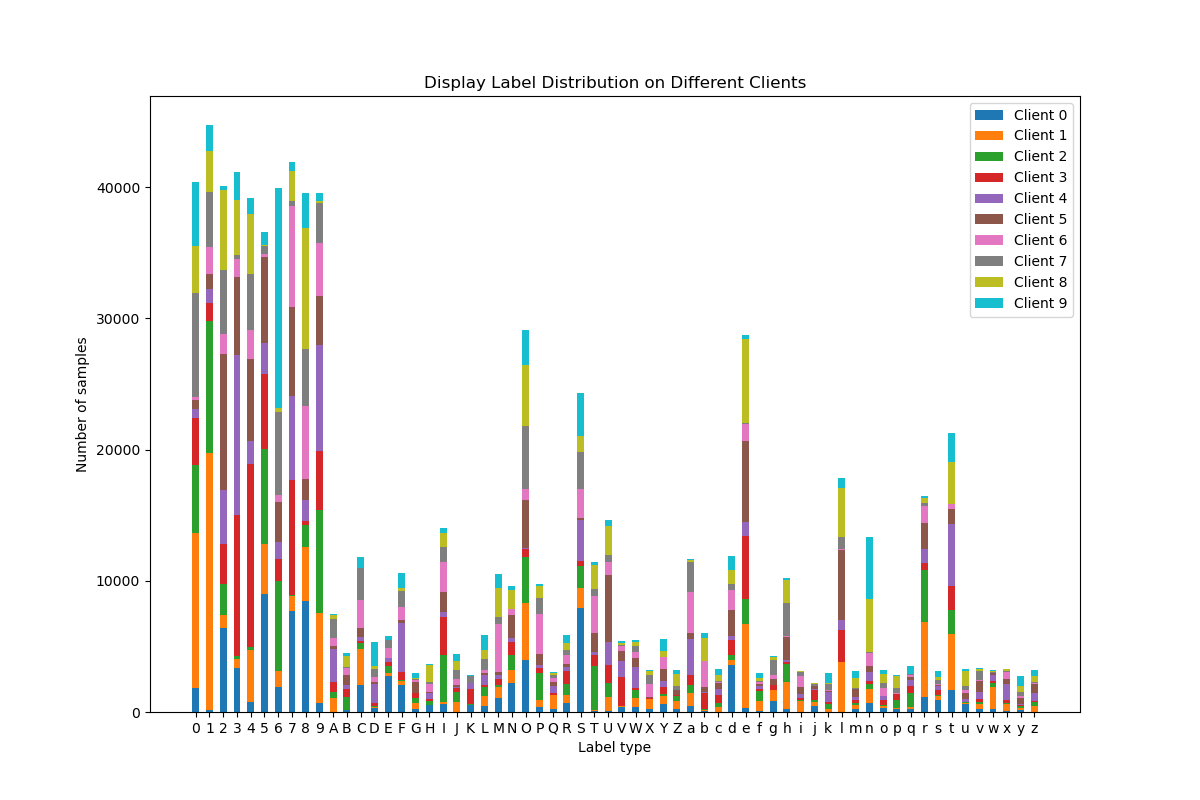
可以看到,62个类别标签在不同client上的分布确实不同,证明我们的样本划分算法是有效的。
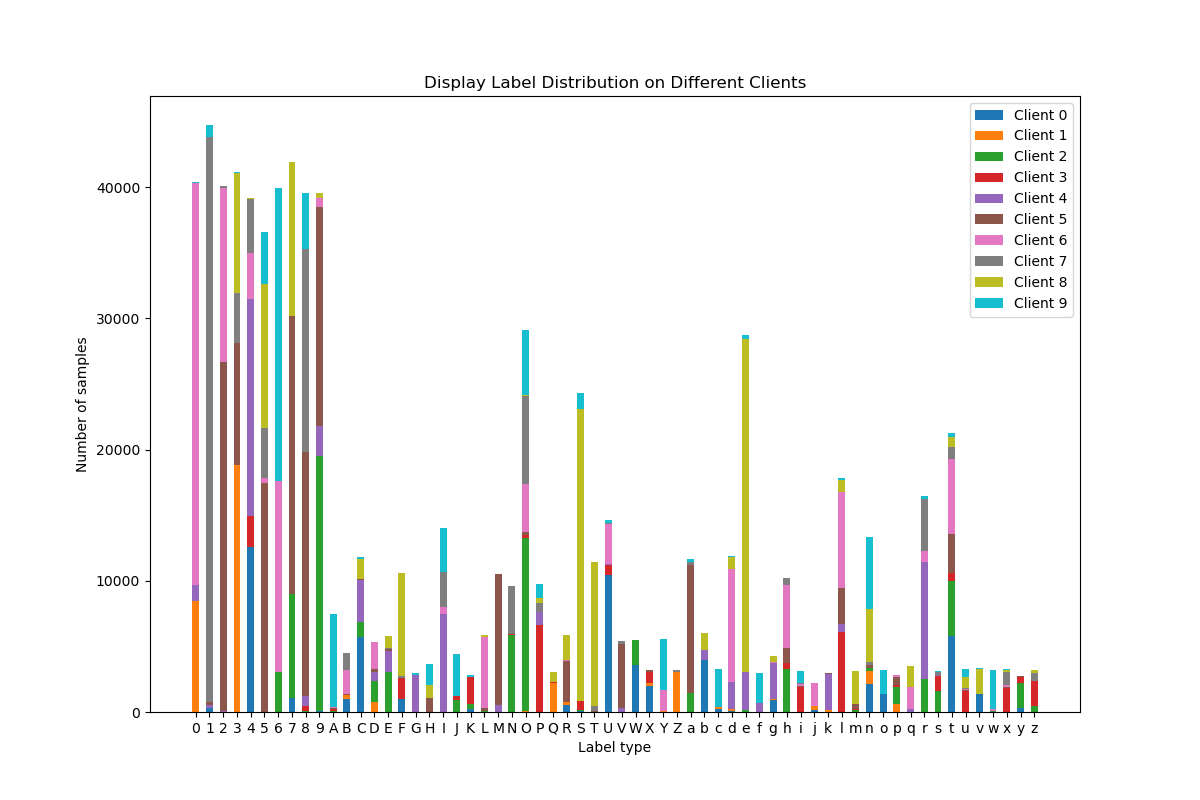
我们尝试将(\alpha)设置为(0.1),可以看到标签分布的异构程度确实有所加大(结合我们前面所讲的Dirichlet分布性质,也就是表示标签概率分布的样本点变得分散):
最后,如果我们想将(x)轴变为client,(y)轴变为标签类别,即更明确地可视化不同client上的标签分布情况,我们可以将数据可视化部分的代码修改如下:
展示不同client上的label分布
plt.figure(figsize=(12, 8))
label_distribution = [[] for _ in range(n_classes)]
for c_id, idc in enumerate(client_idcs):
for idx in idc:
label_distribution[labels[idx]].append(c_id)
plt.hist(label_distribution, stacked=True,
bins=np.arange(-0.5, n_clients + 1.5, 1),
label=classes, rwidth=0.5)
plt.xticks(np.arange(n_clients), ["Client %d" %
c_id for c_id in range(n_clients)])
plt.xlabel("Client ID")
plt.ylabel("Number of samples")
plt.legend()
plt.title("Display Label Distribution on Different Clients")
plt.show()
此时我们可以看到不同client上的标签分布情况如下图所示:
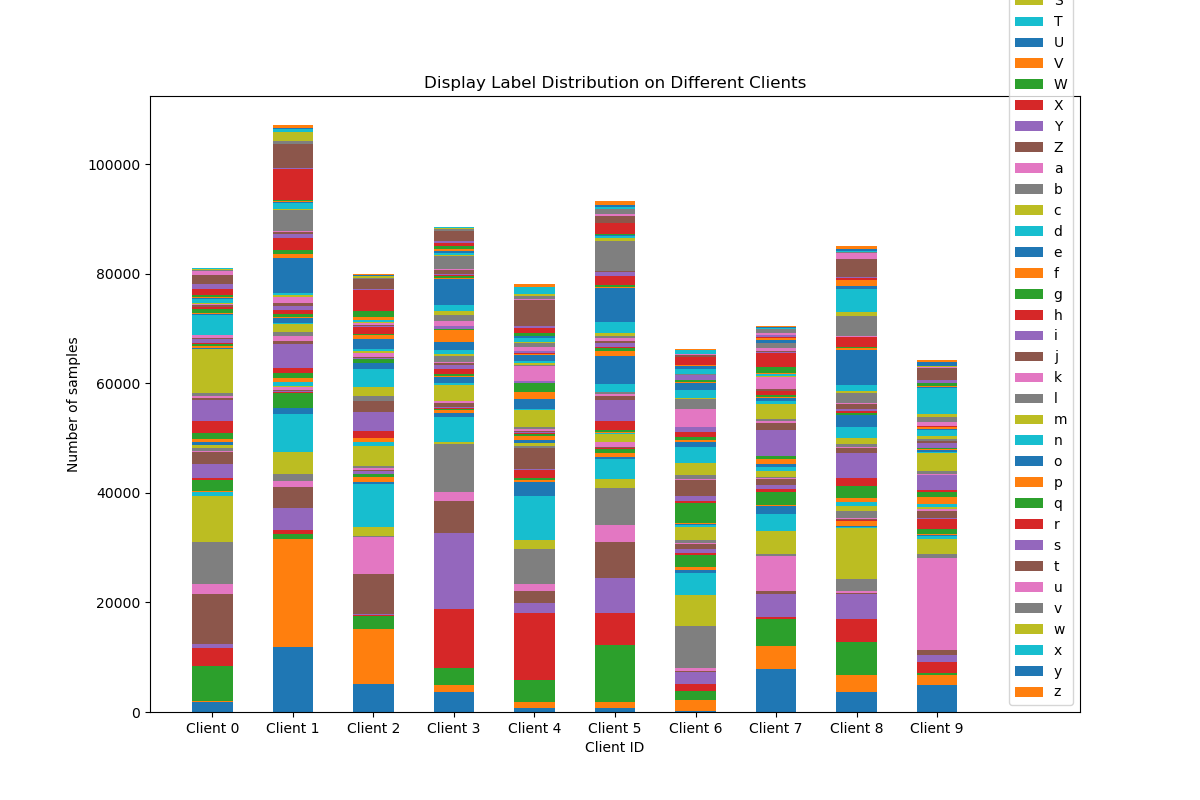
这里有个很尴尬问题:类别数量太多,导致图右边的图例放不下了。因此建议如果采用这种可视化方法的话最好选择类别数量少的数据集,比如CIFAR10。
参考
- [1] MacKay D J C, Mac Kay D J C. Information theory, inference and learning algorithms[M]. Cambridge university press, 2003.(chapter 23)
-
[2] Hsu T M H, Qi H, Brown M. Measuring the effects of non-identical data distribution for federated visual classification[J]. arXiv preprint arXiv:1909.06335, 2019.
Original: https://www.cnblogs.com/orion-orion/p/15897853.html
Author: orion-orion
Title: 联邦学习:按Dirichlet分布划分Non-IID样本
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/805420/
转载文章受原作者版权保护。转载请注明原作者出处!