

数据集介绍
数据集背景:
HRSC2016数据集
包含27种类型的遥感地物目标
提取自Google Earth
由西北工业大学于2016年发布
采用oriented bounding boxes(OBB)标注格式
HRSC2016 (Liu et al.,2016)是西北工业大学采集的用于轮船的检测的数据,包含4个大类19个小类共2976个船只实例信息。论文中特别指出他们的数据集是高分辨率数据集,分辨率介于0.4m和2m之间。数据集所有图像均来自六个著名的港口,包括海上航行的船只和靠近海岸的船只,船只图像的尺寸范围从300到1500,大多数图像大于1000×600。
数据集类别说明
本数据集中目标为航拍图像下的船只,包括海上船只与近岸船只。作者在对船只模型进行分类时采用 了高度为3的树形结构,L1层次为Class、L2层次为category、L3层次为Type,类似生物学的分类观点,具体表示如下:
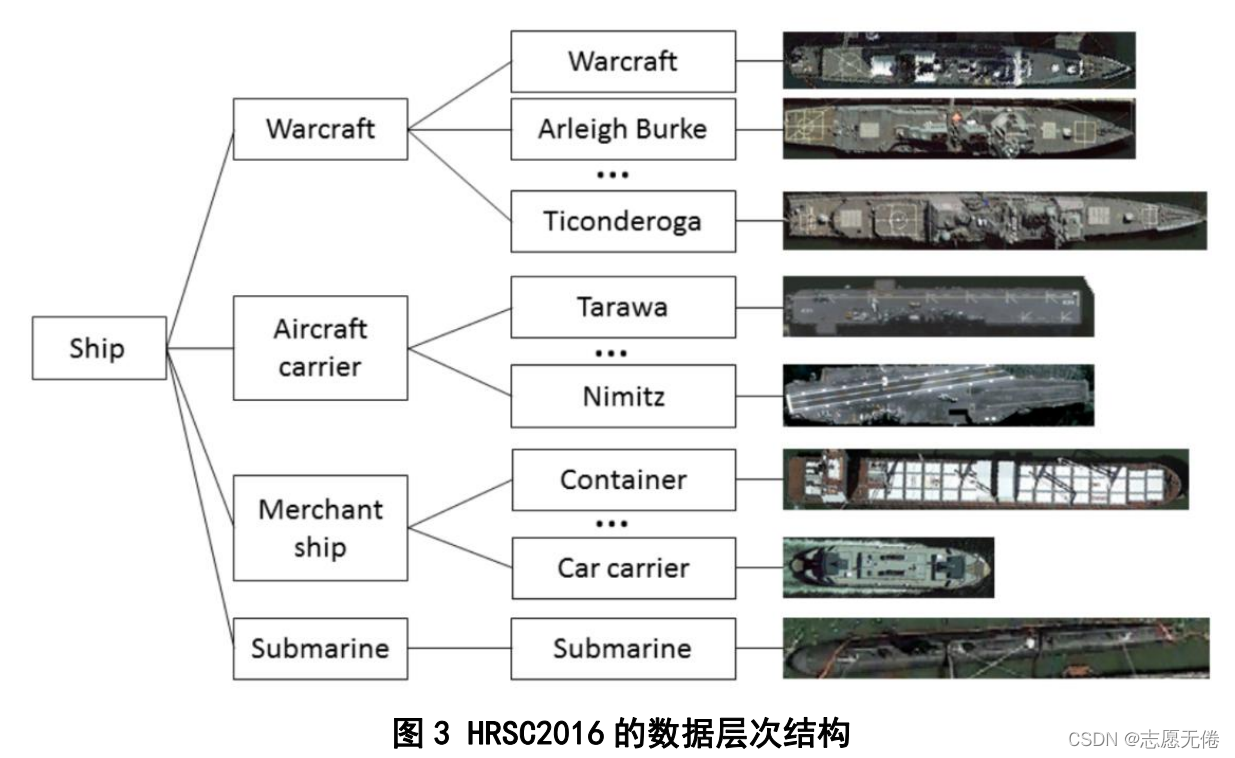

样本标注信息
HRSC2016采用OBB(oriented bounding box)的标注方法,提供了三类标注信息,包括bounding box、rotated bounding box和pixel-based segmentation,还包括港口、数据源、拍摄时间等额外信息,部分数据标注展示如下:
<hrsc_image>
<img_custype>sealand</img_custype>
<img_location>69.040297,33.070036</img_location>
<img_sizewidth>1138</img_sizewidth>
<img_sizeheight>833</img_sizeheight>
<img_sizedepth>3</img_sizedepth>
<img_resolution>1.07</img_resolution>
<img_resolution_layer>18</img_resolution_layer>
<img_scale>100</img_scale>
<segmented>0</segmented>
<img_havemask>0</img_havemask>
<img_rotation>274d</img_rotation>
<hrsc_objects>
<hrsc_object>
<object_id>100000008</object_id>
<class_id>100000013</class_id>
<object_no>100000008</object_no>
<truncated>0</truncated>
<difficult>0</difficult>
<box_xmin>628</box_xmin>//bounding box坐标点
<box_ymin>40</box_ymin>
<box_xmax>815</box_xmax>
<box_ymax>783</box_ymax>
<mbox_cx>719.9324</mbox_cx>//旋转后的左上角坐标
<mbox_cy>413.0048</mbox_cy>
<mbox_w>741.8246</mbox_w>
<mbox_h>172.6959</mbox_h>
<mbox_ang>1.499893</mbox_ang>//旋转角度
<segmented>0</segmented>
<seg_color>
</seg_color>
<header_x>713</header_x>//船头部信息
<header_y>777</header_y>
</hrsc_object>
</hrsc_objects>
</hrsc_image>
数据图像示例

这里先上代码
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[ ('2007', 'test')]
classes = ["ship"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
# 转换这一张图片的坐标表示方式(格式),即读取xml文件的内容,计算后存放在txt文件中
in_file = open('./data/VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('./data/VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
# size = root.find('size')
w = int(root.find('Img_SizeWidth').text)
h = int(root.find('Img_SizeHeight').text)
if root.find('HRSC_Objects'):
for obj in root.iter('HRSC_Object'):
difficult = obj.find('difficult').text
cls = 'ship'
# cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
if int(difficult) == 1:
continue
cls_id = classes.index(cls)
# xmlbox = obj.find('bndbox')
b = (float(obj.find('box_xmin').text), float(obj.find('box_xmax').text), float(obj.find('box_ymin').text), float(obj.find('box_ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('./data/VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('./data/VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('./data/VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('./data/%s/VOCdevkit/VOC%s/JPEGImages/%s.bmp\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
以上是hrsc2016数据集xml格式转换为yolo格式txt文件
注意路径问题
数据集3大类27小类,共2,976个目标
这里是讲数据集划分到只有一类 ship
image size:300 × 300 ~ 1500 × 900
image number:1061 在训练集、验证集和测试集中分别包含436、181和444张图像
object number:2976
数据集下载地址 附上链接
https://aistudio.baidu.com/aistudio/datasetdetail/54106
本文参考
CSDN博主「Marlowee」的原创文章,遵循CC 4.0 BY-SA版权协议,附上
原文链接:https://blog.csdn.net/weixin_43427721/article/details/122057389
Original: https://www.cnblogs.com/liyuanzhouye/p/16209294.html
Author: 李沅洲也
Title: hrsc2016数据集xml格式转换为yolo格式,附下载链接
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/805235/
转载文章受原作者版权保护。转载请注明原作者出处!